
Le service d'agrégation fournit aux technologies publicitaires les insights sur les performances dont elles ont besoin pour améliorer l'efficacité des campagnes auprès des clients.
Ce document aborde les points suivants :
- Termes et concepts clés
- Fonctionnement du service d'agrégation pour vous fournir des données de conversion détaillées et des mesures de couverture à partir de rapports agrégables bruts
- Présentation conceptuelle du traitement par lot des rapports agrégables
- Présentation des concepts des composants cloud
À qui s'adresse ce document ?
Cette page aide les technologies publicitaires et les développeurs à comprendre comment nos API permettent de mesurer efficacement les publicités tout en préservant la confidentialité.
Ce document suppose que vous connaissez les API Private Aggregation, Attribution Reporting, Protected Audience, Shared Storage et les environnements d'exécution sécurisés.
Termes et concepts clés
Familiarisez-vous avec les termes clés avant de continuer :
Glossaire
- AdTech
-
Une plate-forme publicitaire est une entreprise qui fournit des services de diffusion d'annonces.
- Rapports agrégables
-
Les rapports agrégables sont des rapports chiffrés envoyés depuis les appareils de chaque utilisateur. Ces rapports contiennent des données sur le comportement et les conversions des utilisateurs sur plusieurs sites. Les conversions (parfois appelées "événements de déclencheur d'attribution") et les métriques associées sont définies par l'annonceur ou la technologie publicitaire. Chaque rapport est chiffré pour empêcher diverses parties d'accéder aux données sous-jacentes.
- Comptabilisation des rapports agrégables
-
Un registre distribué, situé dans les deux coordinateurs, qui suit le budget de confidentialité alloué et applique la règle "Pas de doublons". Il s'agit du mécanisme de protection de la confidentialité, situé et exécuté dans les coordinateurs, qui garantit qu'aucun rapport ne passe par le service d'agrégation au-delà du budget de confidentialité alloué.
En savoir plus sur les stratégies de traitement par lot et les rapports agrégables
- Budget de comptabilisation des rapports agrégables
-
Références au budget qui garantissent que les rapports individuels ne sont pas traités plusieurs fois.
- Service d'agrégation
-
Service géré par une technologie publicitaire qui traite les rapports agrégables pour créer un rapport récapitulatif.
Pour en savoir plus sur l'histoire du service d'agrégation, consultez notre explication et la liste complète des conditions d'utilisation.
- Attestation
-
Mécanisme permettant d'authentifier l'identité d'un logiciel, généralement à l'aide de hachages cryptographiques ou de signatures. Pour la proposition de service d'agrégation, l'attestation fait correspondre le code exécuté dans votre service d'agrégation géré par une technologie publicitaire au code open source.
- Contribution bonding
- Coordinateur
-
Entités responsables de la gestion des clés et de la comptabilité des rapports agrégables. Un coordinateur gère une liste de hachages des configurations de service d'agrégation approuvées et configure l'accès aux clés de déchiffrement.
- Bruit et scaling
-
Bruit statistique ajouté aux rapports récapitulatifs lors du processus d'agrégation pour préserver la confidentialité et s'assurer que les rapports finaux fournissent des informations de mesure anonymisées.
En savoir plus sur le mécanisme de bruit additif, qui est tiré de la distribution de Laplace
- Origine du signalement
-
Entité qui reçoit les rapports agrégables (en d'autres termes, vous ou une technologie publicitaire ayant appelé l'API Attribution Reporting). Les rapports agrégables sont envoyés depuis les appareils des utilisateurs vers une URL connue associée à l'origine des rapports. L'origine des rapports est désignée lors de l'enregistrement.
- ID partagé
-
Valeur calculée composée de
shared_info,reporting_origin,destination_site(pour l'API Attribution Reporting uniquement),source_registration-time(pour l'API Attribution Reporting uniquement),scheduled_report_timeet version.Plusieurs rapports qui partagent les mêmes attributs dans le champ
shared_infodoivent avoir le même ID partagé. Les ID partagés jouent un rôle important dans la comptabilité des rapports agrégables. - Rapport récapitulatif
-
Type de rapport pour l'API Attribution Reporting et l'API Private Aggregation. Un rapport récapitulatif inclut des données utilisateur agrégées et peut contenir des données de conversion détaillées avec du bruit ajouté. Les rapports de synthèse sont composés de rapports agrégables. Ils offrent une plus grande flexibilité et un modèle de données plus riche que les rapports au niveau des événements, en particulier pour certains cas d'utilisation tels que les valeurs de conversion.
- Environnement d'exécution sécurisé (TEE)
-
Configuration sécurisée du matériel et des logiciels informatiques qui permet aux parties externes de vérifier les versions exactes des logiciels exécutés sur la machine sans craindre d'être exposés. Les TEE permettent aux parties externes de vérifier que le logiciel fait exactement ce que le fabricant affirme qu'il fait, ni plus ni moins.
Pour en savoir plus sur les TEE utilisés pour les propositions de la Privacy Sandbox, consultez la présentation des services de l'API Protected Audience et la présentation du service d'agrégation.
Workflow du service d'agrégation
Le service d'agrégation génère des rapports récapitulatifs des données détaillées sur les conversions et la couverture à partir de rapports agrégables bruts. Le processus de génération de rapports comprend les étapes suivantes :
- Un navigateur récupère une clé publique pour générer des rapports chiffrés.
- Des rapports agrégables chiffrés sont envoyés aux serveurs de technologie publicitaire.
- Le serveur de technologie publicitaire regroupe les rapports (au format avro) et les envoie au service d'agrégation.
- Un nœud de calcul d'agrégation récupère les rapports agrégés à déchiffrer.
- Le nœud de calcul d'agrégation récupère les clés de déchiffrement auprès d'un coordinateur.
- Le nœud de calcul d'agrégation déchiffre les rapports pour l'agrégation et le bruitage.
- Le service de comptabilité des rapports agrégables vérifie si le budget de confidentialité est suffisant pour générer un rapport récapitulatif pour les rapports agrégables donnés.
- Le service d'agrégation envoie un rapport récapitulatif final.
Le schéma suivant montre le service d'agrégation en action, depuis la réception des rapports provenant d'appareils Web et mobiles jusqu'à la création d'un rapport récapitulatif par le service d'agrégation.
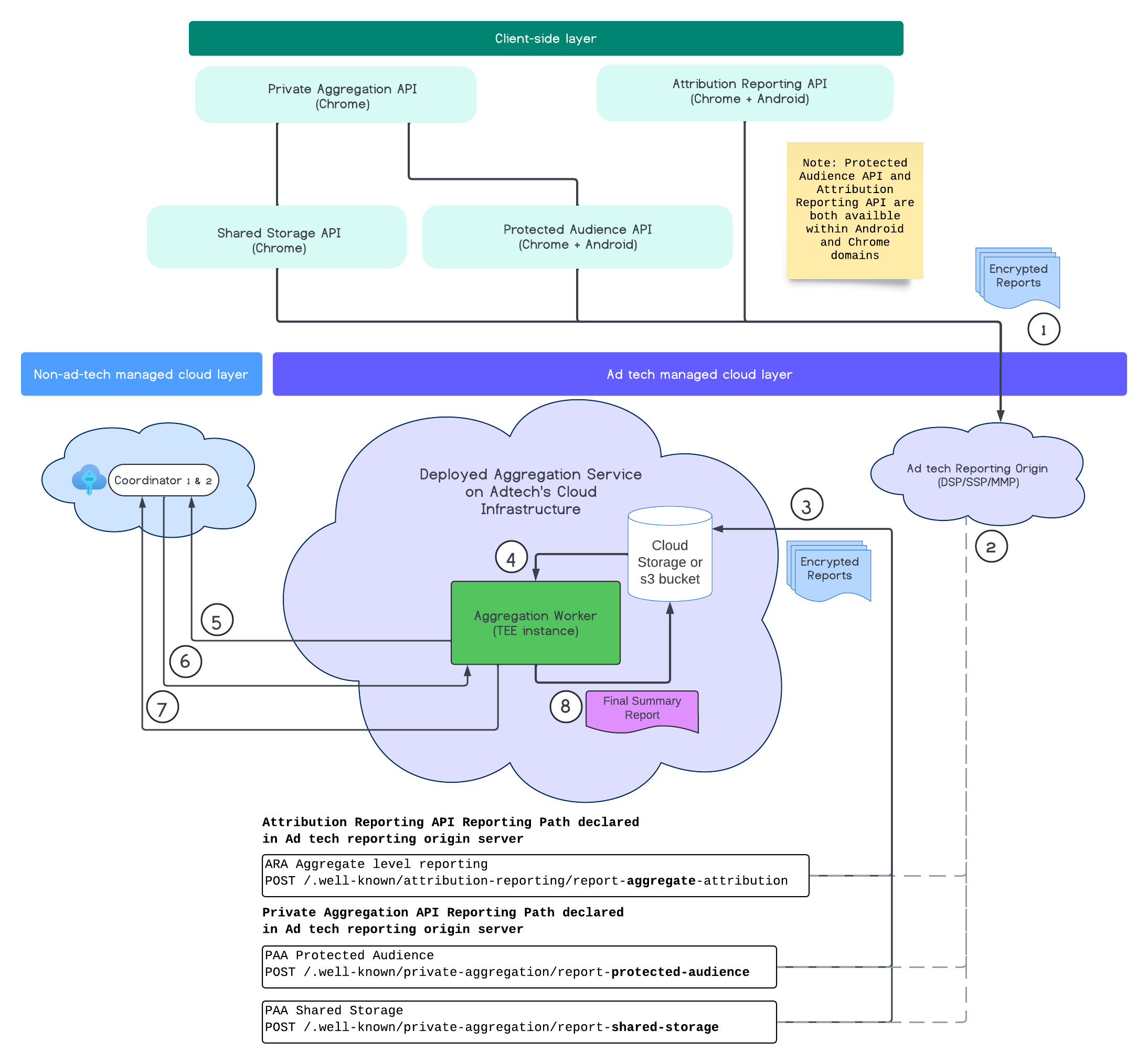
En résumé, l'API Attribution Reporting ou l'API Private Aggregation génèrent des rapports à partir de plusieurs instances de navigateur. Chrome obtient une clé publique, renouvelée tous les sept jours, auprès du service d'hébergement de clés du coordinateur, pour chiffrer les rapports avant de les envoyer à l'origine de création de rapports sur les technologies publicitaires. L'origine de création de rapports de la technologie publicitaire collecte les rapports entrants, les convertit au format Avro et les envoie au service d'agrégation. Lorsqu'une requête par lot est ensuite envoyée au service d'agrégation, celui-ci récupère les clés de déchiffrement auprès du service d'hébergement de clés, déchiffre les rapports, puis les agrège et les bruite pour créer un rapport récapitulatif, à condition qu'il dispose d'un budget de confidentialité suffisant.
Pour savoir comment préparer vos rapports agrégables, consultez la section sur l'implémentation.
Regroupement des rapports agrégables
Le flux de création de rapports ne serait pas complet sans l'aide du serveur d'origine des rapports désigné, que vous avez spécifié lors de la procédure d'inscription. L'origine du rapport est chargée de collecter, de transformer et de regrouper les rapports agrégables, et de les préparer à être envoyés à votre service d'agrégation dans Google Cloud ou Amazon Web Services. Découvrez comment préparer vos rapports agrégables.
Composants cloud
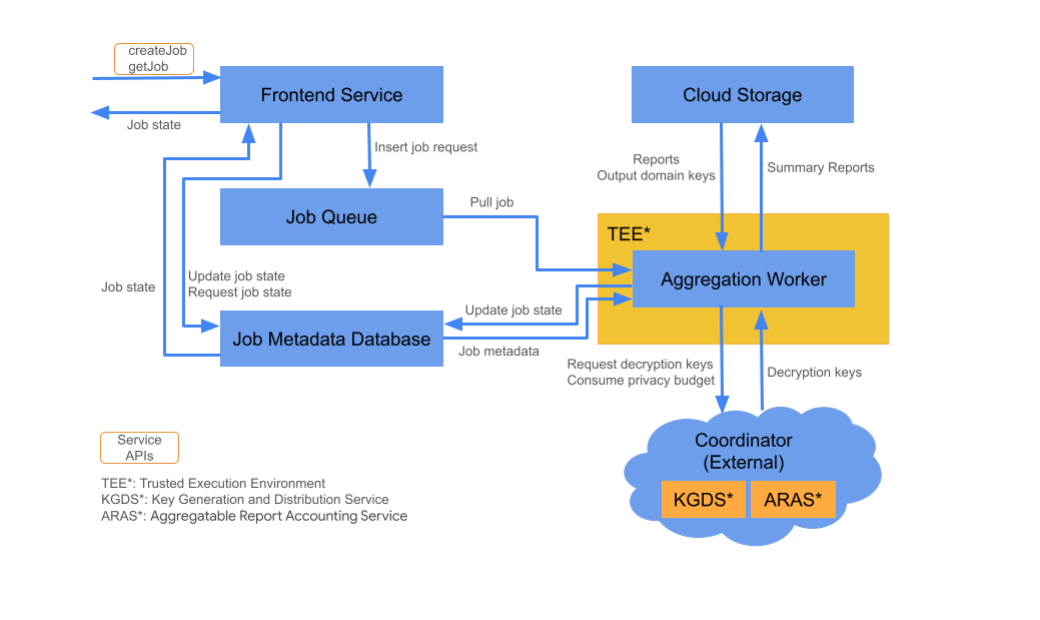
Le service d'agrégation se compose de plusieurs composants de service cloud. Vous utilisez les scripts Terraform fournis pour provisionner et configurer tous les composants de service cloud nécessaires.
Service frontend
Service cloud géré : Cloud Functions (Google Cloud) / API Gateway (Amazon Web Services)
Le service Frontend est une passerelle sans serveur qui constitue le point d'entrée principal pour les appels d'API d'agrégation pour la création de jobs et la récupération de l'état des jobs. Il est chargé de recevoir les requêtes des utilisateurs du service d'agrégation, de valider les paramètres d'entrée et de lancer le processus de planification des tâches d'agrégation.
Le service de frontend dispose de deux API :
| Point de terminaison | Description |
|---|---|
createJob |
Cette API déclenche un job Aggregation Service. Pour déclencher le job, vous devez fournir des informations telles que l'ID du job, les détails du stockage d'entrée, les détails du stockage de sortie et l'origine du rapport. |
getJob |
Cette API renvoie l'état du job ayant un ID de job spécifié. Il fournit des informations sur l'état du job, comme "Reçu", "En cours" ou "Terminé". Si la tâche est terminée, elle renvoie également le résultat de la tâche, y compris les messages d'erreur rencontrés lors de l'exécution de la tâche. |
Consultez la documentation de l'API Aggregation Service.
File d'attente des jobs
Service cloud géré : Pub/Sub (Google Cloud) / Amazon SQS (Amazon Web Services)
La file d'attente des jobs est une file d'attente de messages contenant des demandes de job pour le service d'agrégation. Le service Frontend insère les demandes de job dans la file d'attente, qui sont ensuite traitées par les nœuds de calcul d'agrégation.
Cloud Storage
Service cloud géré : Google Cloud Storage (Google Cloud) / Amazon S3 (Amazon Web Services)
Les fichiers d'entrée et de sortie utilisés par le service d'agrégation, tels que les fichiers de rapports chiffrés et les rapports récapitulatifs de sortie, sont conservés dans le stockage cloud.
Base de données des métadonnées de tâches
Service cloud géré : Spanner (Google Cloud) / DynamoDB (Amazon Web Services)
La base de données des métadonnées de job permet de stocker et de suivre l'état des jobs d'agrégation. Il enregistre des métadonnées telles que l'heure de création, l'heure de la demande, l'heure de mise à jour et l'état (par exemple, "Reçue", "En cours" ou "Terminée"). Les nœuds de calcul d'agrégation mettent à jour la base de données des métadonnées des jobs à mesure que les jobs progressent.
Nœud de calcul d'agrégation
Service cloud géré : Compute Engine avec espace confidentiel (Google Cloud) / Amazon Web Services EC2 avec Nitro Enclave (Amazon Web Services).
Un nœud de calcul d'agrégation traite les requêtes de job dans la file d'attente des jobs et déchiffre les entrées chiffrées à l'aide des clés qu'il récupère auprès du service de génération et de distribution de clés (KGDS) dans les coordinateurs. Pour minimiser la latence de traitement des jobs, les nœuds de calcul d'agrégation mettent en cache les clés de déchiffrement pendant huit heures et les utilisent pour tous les jobs qu'ils traitent.
Les nœuds de calcul d'agrégation fonctionnent dans une instance d'environnement d'exécution sécurisé (TEE). Un nœud de calcul ne traite qu'un seul job à la fois. Vous pouvez configurer plusieurs nœuds de calcul pour traiter les tâches en parallèle en définissant la configuration de l'autoscaling. Si l'autoscaling est utilisé, il ajuste dynamiquement le nombre de nœuds de calcul en fonction du nombre de messages dans la file d'attente des jobs. Vous pouvez configurer le nombre minimal et maximal de nœuds de calcul pour l'autoscaling à l'aide du fichier d'environnement Terraform. Pour en savoir plus sur l'autoscaling, consultez ces scripts Terraform : Amazon Web Services ou Google Cloud.
Les nœuds de calcul d'agrégation appellent le service de comptabilisation des rapports agrégables pour la comptabilisation des rapports agrégables. Ce service vérifie que les jobs ne sont exécutés que si la limite du budget lié à la confidentialité n'a pas été dépassée. (Consultez la règle"Pas de doublons".) Si le budget est disponible, un rapport récapitulatif est généré à l'aide des agrégats bruyants. En savoir plus sur la comptabilisation des rapports agrégables
Les nœuds de calcul d'agrégation mettent à jour les métadonnées des jobs dans la base de données des métadonnées des jobs. Ces informations incluent les codes de retour des tâches et les compteurs d'erreurs de rapport en cas d'échec partiel des rapports. Les utilisateurs peuvent récupérer l'état à l'aide de l'API de récupération de l'état du job getJob.
Pour obtenir une description plus détaillée d'Aggregation Service, consultez cette explication.
Étapes suivantes
Maintenant que vous savez comment fonctionne le service d'agrégation, suivez le guide de démarrage pour déployer votre propre instance via Google Cloud ou Amazon Web Services.