
Le service d'agrégation génère des rapports récapitulatifs sur les données de conversion détaillées et les mesures de couverture à partir de rapports agrégables bruts. Pour préserver la confidentialité et la sécurité des données utilisateur, le service d'agrégation utilise un framework compatible avec la confidentialité différentielle. Cette technique permet de quantifier et de limiter la quantité d'informations que ces rapports révèlent sur les utilisateurs individuels.
Ce guide présente des outils et des stratégies permettant de créer des rapports agrégables qui contribuent à protéger les données des utilisateurs individuels :
- Créer des rapports récapitulatifs avec du bruit ajouté
- Définir un budget de contribution
- Stratégies de regroupement des rapports
- Utiliser des clés d'agrégation prédéclarées
Rapports récapitulatifs avec bruit ajouté
Lorsque vous regroupez des rapports agrégables, le service d'agrégation crée un rapport récapitulatif. Ce rapport récapitulatif est une agrégation de toutes les contributions de toutes les clés de domaine prédéfinies, avec du bruit statistique ajouté.
Le bruit ajouté aux rapports ne dépend pas du nombre de rapports agrégés, des valeurs des rapports individuels ni des valeurs des rapports agrégés. Le bruit est tiré d'une version discrète de la distribution de Laplace et est mis à l'échelle du budget de contribution (sensibilité L1) appliqué par le client en fonction de l'API de mesure correspondante et du paramètre de confidentialité epsilon.
Pour en savoir plus sur le bruit et ses implications pour les données des rapports, consultez Comprendre le bruit dans les rapports récapitulatifs.
Budget de contribution
Pour contrôler la sensibilité d'un rapport récapitulatif, le nombre de contributions transmises dans un appel est lié à une limite de contribution spécifique, également appelée budget de contribution. Le budget de contribution varie selon que vous utilisez l'API Attribution Reporting ou l'API Private Aggregation.
Pour savoir comment définir des budgets de contribution pour chaque API, consultez les sections suivantes de la documentation de l'API :
- Limites et budgétisation des contributions de l'API Attribution Reporting
- Limites de contribution de l'API Private Aggregation
- Limites et budget de contribution de l'API Private Aggregation
Stratégies de regroupement des rapports
Lorsque vous regroupez des rapports agrégables, il est important d'optimiser les stratégies de regroupement afin de ne pas dépasser les limites de confidentialité. Deux concepts importants pour regrouper correctement les rapports sont la règle "sans doublons" et l'idée de lots disjoints.
Règle "Pas de doublons"
Le service d'agrégation applique une règle "sans doublons". Cette règle stipule qu'un rapport agrégable, identifié de manière unique par report_id, ne peut apparaître qu'une seule fois dans un même lot. Si un rapport agrégable apparaît plusieurs fois par lot, le premier rapport est inclus dans l'agrégation, les rapports suivants avec le même report_id sont ignorés et le lot se termine correctement.
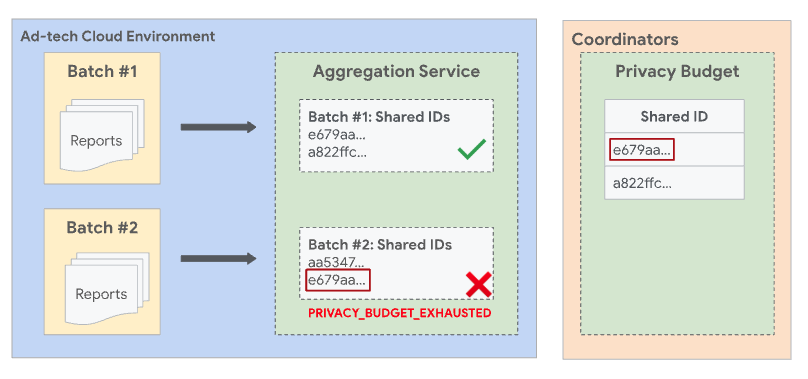
La règle stipule également que le même ID partagé ne peut pas apparaître dans plusieurs lots. Si un ID partagé a déjà été inclus dans un lot précédent réussi, un lot ultérieur qui inclut également le même ID partagé échouera.
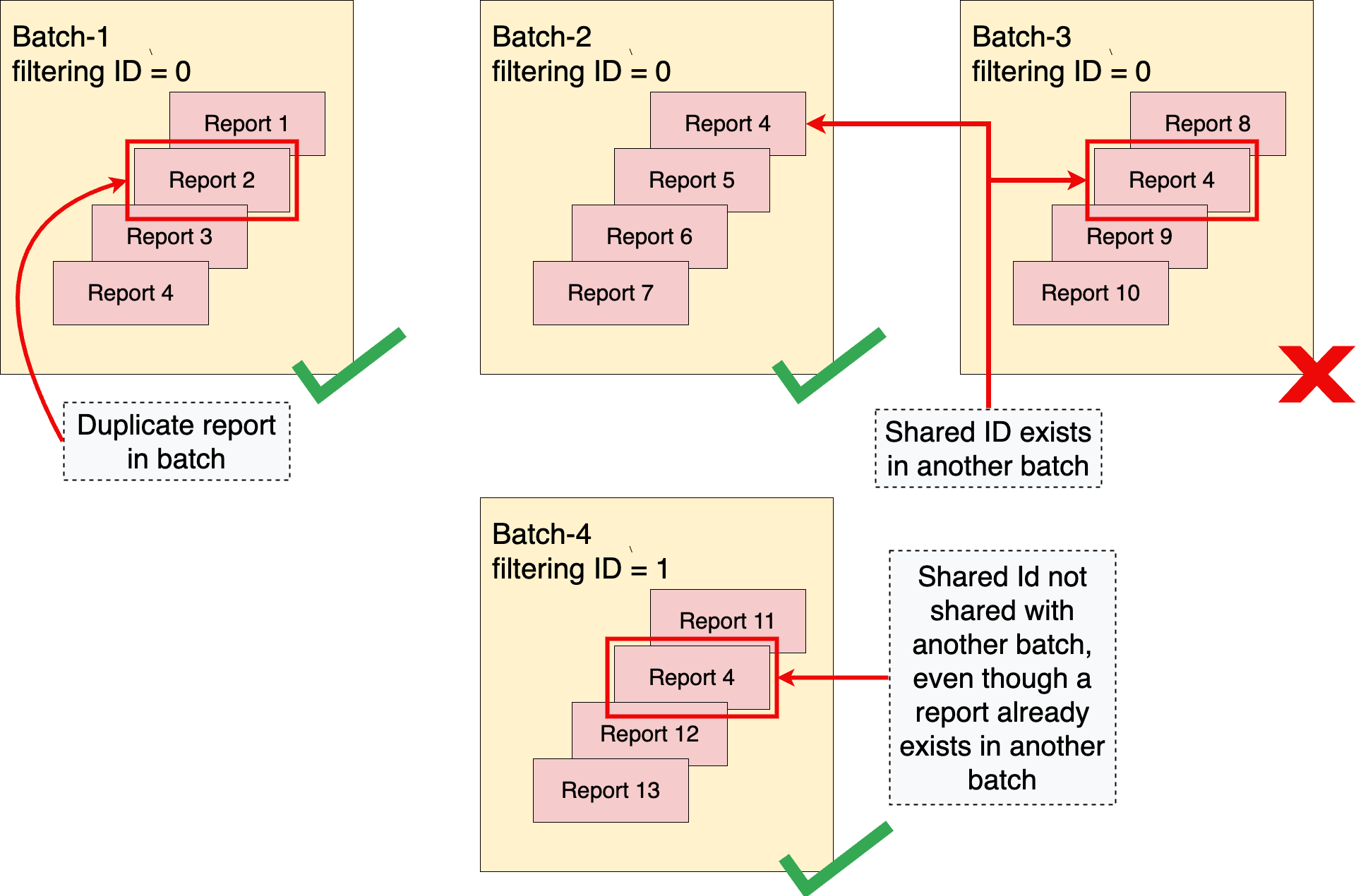
Sans la règle "pas de doublons", un pirate informatique pourrait obtenir des informations sur le contenu d'un lot spécifique en manipulant le contenu des lots (par exemple, en incluant des copies en double d'un rapport dans un ou plusieurs lots).
Pour en savoir plus sur l'application de la règle "Pas de doublons" dans un lot de rapports ou dans plusieurs lots, consultez Rapports en double dans les lots.
Lots disjoints
Pour éviter les situations dans lesquelles les lots se chevauchent, le service d'agrégation applique des lots disjoints. Cela signifie que deux lots ou plus ne peuvent pas contenir de rapports qui partagent un ID partagé commun. Un ID partagé est une combinaison de données collectées à partir du champ shared_info d'un rapport agrégable, ainsi que de l'ID de filtrage de la demande d'emploi. Si aucun ID de filtrage n'est spécifié, la valeur par défaut (0) est utilisée.
Dans l'exemple de champ shared_info suivant, vous pouvez voir l'API, attribution_destination (pour Attribution Reporting), reporting_origin, scheduled_report_time, source_registration_time (pour Attribution Reporting) et version. Ces champs, à l'exception de report_id, ainsi que l'ID de filtrage de la demande d'emploi, contribuent à l'ID partagé.
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://privacy-sandbox-demos-shop.dev",
"report_id": "5b052748-f5fb-4f14-b291-de03484ed59e",
"reporting_origin": "https://privacy-sandbox-demos-dsp.dev",
"scheduled_report_time": "1707786751",
"source_registration_time": "0",
"version": "0.1"
}
Comme source_registration_time est tronqué par jour et scheduled_report_time par heure, certains rapports ont le même ID partagé. Dans cet exemple, Rapport1 et Rapport2 partagent des champs d'informations. Les deux rapports ont la même API, la même version, le même attribution_destination, le même reporting_origin et le même source_registration_time. Étant donné que report_id ne fait pas partie de l'ID partagé, vous pouvez ignorer cette différence.
Dans les exemples suivants pour Report1 et Report2, la valeur scheduled_report_time est la même.
Informations partagées pour Report1 :
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://shop.dev",
"report_id": "5b052748-...",
"reporting_origin": "https://dsp.dev",
"scheduled_report_time": "1708376890",
"source_registration_time": "0",
"version": "0.1"
}
Informations partagées par Report2 :
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://shop.dev",
"report_id": "5b052748-...",
"reporting_origin": "https://dsp.dev",
"scheduled_report_time": "1708376890",
"source_registration_time": "0",
"version": "0.1"
}
Les heures de planification des rapports sont "19 février 2024 à 21h08:10" pour Rapport1 et "19 février 2024 à 21h55:10" pour Rapport2. Étant donné que la valeur du champ scheduled_report_time est tronquée à l'heure, les deux rapports ont 1708376890 (la valeur encodée pour "19 février 2024 à 21h") comme valeur du champ scheduled_report_time.
Si tous les autres champs et l'ID de filtrage sont identiques, les deux rapports auront le même ID partagé. Comme les deux rapports ont le même ID partagé, ils doivent tous les deux être inclus dans le même lot.
Si Report1 a été traité par lot dans un lot précédent qui a réussi et que Report2 est traité dans un lot ultérieur, le lot contenant Report2 échoue avec une erreur PRIVACY_BUDGET_EXHAUSTED. Si cela se produit, supprimez les rapports avec l'ID partagé qui ont été regroupés avec succès dans les lots précédents, puis réessayez. Pour en savoir plus sur cette erreur, consultez Codes d'erreur et atténuations pour le service d'agrégation.
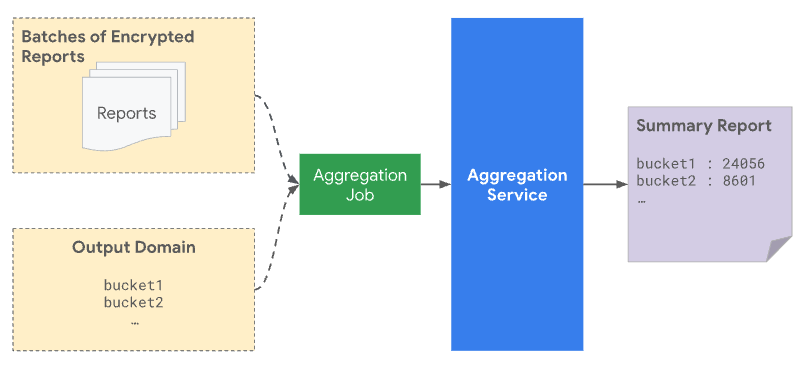
Clés d'agrégation prédéclarées
Lorsque vous envoyez un lot au service d'agrégation, il doit inclure à la fois les rapports agrégables reçus de l'origine des rapports et le fichier de domaine de sortie. Le domaine de sortie contient les clés ou les buckets récupérés à partir des rapports agrégables.
Du point de vue de la confidentialité, du bruit est ajouté à toutes les clés prédéclarées dans le domaine de sortie, même lorsqu'aucun rapport réel ne correspond à une clé spécifique. La spécification du domaine de sortie protège contre une attaque où la présence d'une clé dans la sortie révèle des informations sur un seul utilisateur ou événement. Par exemple, si vous n'avez diffusé une campagne qu'à un seul utilisateur, la réception d'une clé dans le résultat révèle que l'utilisateur a effectué une conversion par la suite, même avec du bruit ajouté. En spécifiant ce domaine en premier, vous pouvez être sûr qu'il ne révèle rien sur les contributions des utilisateurs.
Vous pouvez déclarer ces clés de 128 bits dans l'API Attribution Reporting ou l'API Private Aggregation, et les utiliser pour encoder les dimensions que vous souhaitez suivre.
Seules les clés prédéclarées sont prises en compte pour l'agrégation et incluses dans le rapport récapitulatif. Du bruit statistique est ajouté aux valeurs agrégées des buckets dans le rapport récapitulatif, ce qui se reflète dans le rapport récapitulatif créé.
Si une clé d'agrégation est incluse dans le fichier de domaine de sortie, mais qu'elle ne figure pas dans un rapport par lot, même si la valeur agrégée est nulle, le rapport récapitulatif final sera probablement non nul en raison du bruit ajouté pour préserver la confidentialité.