
Aggregation Service gives ad techs the performance insights needed to improve campaign effectiveness with customers.
This document covers:
- Key terms and concepts
- How Aggregation Service works to bring you detailed conversion data and reach measurement from raw aggregatable reports
- Aggregatable reports batching conceptual overview
- Cloud components conceptual overview
Who is this document for?
This page helps ad techs and developers understand how our APIs enable effective, privacy preserving advertising measurement.
This document assumes you are familiar with the Private Aggregation API, Attribution Reporting API, Protected Audience API, Shared Storage, and Trusted Execution Environments.
Key terms and concepts
Get familiar with key terms before proceeding:
Glossary
- Ad tech
-
An ad platform is a company that provides services to deliver ads.
- Aggregatable reports
-
Aggregatable reports are encrypted reports sent from individual user devices. These reports contain data about cross-site user behavior and conversions. Conversions (sometimes called attribution trigger events) and associated metrics are defined by the advertiser or ad tech. Each report is encrypted to prevent various parties from accessing the underlying data.
- Aggregatable report accounting
-
A distributed ledger, located in both coordinators, that tracks the allocated privacy budget and enforces the 'No Duplicates' rule. This is the privacy preserving mechanism, located and run within coordinators, that ensures no reports pass through the Aggregation Service beyond the allocated privacy budget.
Read more on how batching strategies relate to aggregatable reports.
- Aggregatable report accounting budget
-
References to the budget that ensures individual reports are not processed more than once.
- Aggregation Service
-
An ad tech-operated service that processes aggregatable reports to create a summary report.
Read more about the Aggregation Service backstory in our explainer and the full terms list.
- Attestation
-
A mechanism to authenticate software identity, usually with cryptographic hashes or signatures. For the aggregation service proposal, attestation matches the code running in your ad tech-operated aggregation service with the open source code.
- Contribution bonding
- Coordinator
-
Entities responsible for key management and aggregatable report accounting. A Coordinator maintains a list of hashes of approved aggregation service configurations and configures access to decryption keys.
- Noise and scaling
-
Statistical noise that is added to summary reports during the aggregation process to preserve privacy and ensure the final reports provide anonymized measurement information.
Read more about additive noise mechanism, which is drawn from Laplace distribution.
- Reporting origin
-
The entity that receives aggregatable reports—in other words, you or an ad tech that called the Attribution Reporting API. Aggregatable reports are sent from user devices to a well-known URL associated with the reporting origin. The reporting origin is designated during enrollment.
- Shared ID
-
A computed value that consists of
shared_info,reporting_origin,destination_site(for Attribution Reporting API only),source_registration-time(for Attribution Reporting API only),scheduled_report_time, and version.Multiple reports that share the same attributes in the
shared_infofield should have the same shared ID. Shared IDs play an important role within Aggregatable Report Accounting. - Summary report
-
An Attribution Reporting API and Private Aggregation API report type. A summary report includes aggregated user data, and can contain detailed conversion data with noise added. Summary reports are made up of aggregate reports. They allow for greater flexibility and provide a richer data model than event-level reporting, particularly for some use-cases like conversion values.
- Trusted Execution Environment (TEE)
-
A secure configuration of computer hardware and software that allows external parties to verify the exact versions of software running on the machine without fear of exposure. TEEs allow external parties to verify that the software does exactly what the software manufacturer claims it does—nothing more or less.
To learn more about TEEs used for the Privacy Sandbox proposals, read the Protected Audience API services explainer and the Aggregation Service explainer.
Aggregation Service workflow
Aggregation Service generates summary reports of detailed conversion and reach data from raw aggregatable reports. The report generation flow is comprised of the following steps:
- A browser fetches a public key to generate encrypted reports.
- Encrypted aggregatable reports are sent to ad tech servers.
- The ad tech server batches reports (in avro format) and sends them to the Aggregation Service.
- An Aggregation Worker retrieves the aggregated reports to decrypt.
- The Aggregation Worker retrieves decryption keys from a Coordinator.
- The Aggregation Worker decrypts the reports for aggregation and noising.
- The Aggregatable report accounting service checks if there is sufficient privacy budget to generate a summary report for the given aggregatable reports.
- Aggregation Service submits a final summary report.
The following diagram shows the Aggregation Service in action, from the time that reports are received from web and mobile devices, to the time a summary report is created by the Aggregation Service.
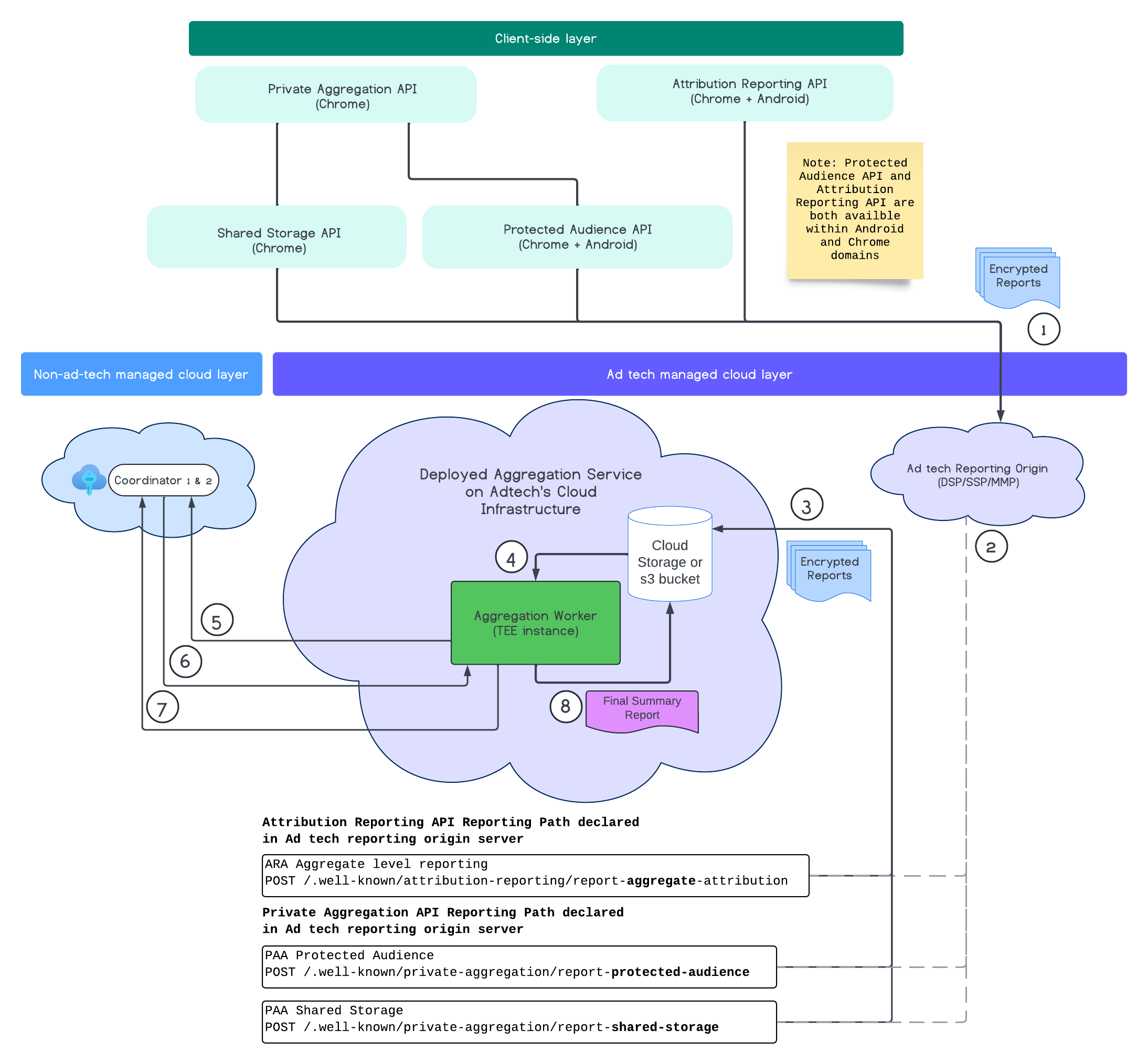
In summary, the Attribution Reporting API or the Private Aggregation API generate reports from multiple browser instances. Chrome obtains a public key, rotated every seven days, from the Key Hosting Service in the Coordinator, to encrypt the reports before sending them to the ad tech reporting origin. The ad tech reporting origin collects and converts incoming reports to avro format, and sends them to the Aggregation Service. When a batch request is then sent to the Aggregation Service, it fetches decryption keys from the Key Hosting Service, decrypts the reports, and aggregates and noises them to create a summary report, as long as there is enough privacy budget to create them.
Find out more about how to prepare your aggregatable reports in the implementation section.
Aggregatable reports batching
The reporting flow wouldn't be complete without the help of the designated reporting origin server, which you specified during the enrollment process. The reporting origin is responsible for collecting, transforming, and batching aggregatable reports, and preparing them to be sent to your Aggregation Service in either Google Cloud or Amazon Web Services. Read more on how to prepare your aggregatable reports.
Cloud components
The Aggregation Service consists of several cloud service components. You use provided Terraform scripts to provision and configure all necessary cloud service components.
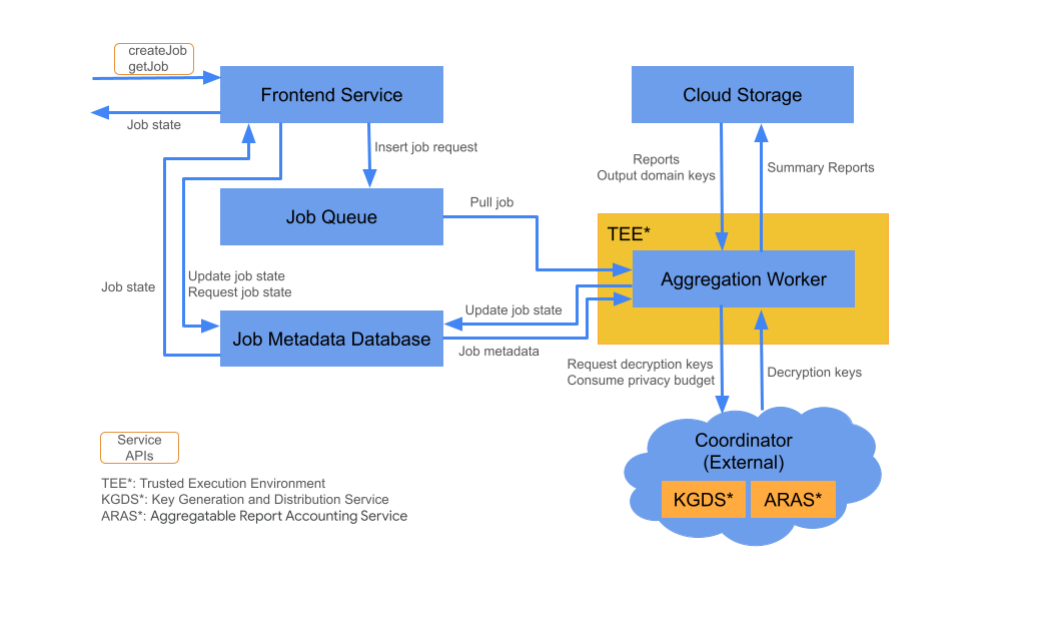
Frontend Service
Managed Cloud Service: Cloud Function (Google Cloud) / API Gateway (Amazon Web Services)
The Frontend Service is a serverless gateway that is the primary entry point for Aggregation API calls for job creation and job state retrieval. It is responsible for receiving requests from Aggregation Service users, validating input parameters, and initiating the aggregation job scheduling process.
The Frontend Service has two available APIs:
| Endpoint | Description |
|---|---|
createJob |
This API triggers an Aggregation Service job. To trigger the job, it requires information such as job ID, input storage details, output storage details, and reporting origin. |
getJob |
This API returns the status of the job having a specified job ID. It provides information about the state of the job, such as "Received," "In Progress," or "Finished." If the job is finished, it also returns the job result, including any error messages encountered during job execution. |
Check out the Aggregation Service API Documentation.
Job Queue
Managed Cloud Service: Pub/Sub (Google Cloud) / Amazon SQS (Amazon Web Services)
The Job Queue is a message queue containing job requests for the Aggregation Service. The Frontend Service inserts job requests into the queue, which are then consumed by Aggregation Workers that process them.
Cloud storage
Managed Cloud Service: Google Cloud Storage (Google Cloud) / Amazon S3 (Amazon Web Services)
Input and output files used by the Aggregation Service, such as encrypted report files and output summary reports, are kept in cloud storage.
Job Metadata Database
Managed Cloud Service: Spanner (Google Cloud) / DynamoDB (Amazon Web Services)
The Job Metadata Database is used to store and track the status of aggregation jobs. It records metadata such as creation time, requested time, updated time, and state such as Received, In Progress, or Finished. Aggregation Workers update the Job Metadata Database as jobs progress.
Aggregation Worker
Managed Cloud Service: Compute Engine with Confidential space (Google Cloud) / Amazon Web Services EC2 with Nitro Enclave (Amazon Web Services).
An Aggregation Worker processes job requests in the Job Queue, and decrypts the encrypted inputs using keys it fetches from the Key Generation and Distribution Service (KGDS) in Coordinators. To minimize job processing latency, Aggregation Workers cache decryption keys for a period of eight hours, and use them across jobs they process.
Aggregation Workers operate within a Trusted Execution Environment (TEE) instance. A worker handles only one job at a time. You can configure multiple workers to process jobs in parallel by setting the auto scaling configuration. If used, auto scaling dynamically adjusts the number of workers according to the number of messages in the job queue. You can configure the minimum and maximum number of workers for auto scaling through the Terraform environment file. More information about autoscaling can be found in these Terraform scripts: Amazon Web Services or Google Cloud.
Aggregation Workers call the Aggregatable Report Accounting Service for aggregatable report accounting. This service verifies that jobs are only run if the privacy budget limit has not been exceeded. (See "No duplicates" rule.) If the budget is available, a summary report is generated using the noisy aggregates. Read additional details regarding the aggregatable report accounting.
Aggregation Workers update job metadata in the Job Metadata Database. This information includes job return codes and report error counters in case of partial report failures. Users can fetch the state using the getJob job state retrieval API.
See this explainer for a more detailed description of the Aggregation Service.
Next steps
Now that you know how the Aggregation Service works, follow the getting started guide to deploy your own instance through Google Cloud or Amazon Web Services.