
Lorsque vous regroupez des rapports agrégables, il est important d'optimiser les stratégies de regroupement afin de ne pas dépasser les limites de confidentialité. Voici quelques stratégies recommandées pour envoyer des lots de rapports au service d'agrégation.
Recueillir des rapports
Lorsque vous collectez des rapports à inclure dans un lot, tenez compte des points suivants :
Nouvelles tentatives d'importation de rapports
Remarque : Les critères de nouvelle tentative sont susceptibles d'être modifiés. Dans ce cas, les informations de cette section seront mises à jour.
Sur les plates-formes Web et OS, une plate-forme tentera d'envoyer le rapport trois fois. Si le rapport ne peut pas être envoyé après la troisième tentative, il ne le sera pas. La valeur scheduled_report_time d'origine est conservée, quelle que soit la date d'envoi du rapport. Le calendrier des nouvelles tentatives varie selon la plate-forme :
- Un navigateur Web envoie des rapports lorsqu'il est en ligne. Si le rapport ne peut pas être envoyé, le système attend cinq minutes avant de réessayer une deuxième fois, puis 15 minutes avant de réessayer une troisième fois. Si le navigateur se déconnecte, la prochaine tentative aura lieu une minute après sa reconnexion. Il n'y a pas de délai maximal pour l'envoi de rapports sur le Web. Cela signifie que si le navigateur se déconnecte, quelle que soit la date de génération du rapport, il tentera de l'envoyer une fois qu'il sera de nouveau en ligne, conformément à la stratégie de réessai.
- Un téléphone Android dispose d'une connexion réseau stable. Par conséquent, il exécutera le job pour envoyer des rapports une fois par heure. Cela signifie que si un rapport ne peut pas être envoyé, une nouvelle tentative sera effectuée l'heure suivante, puis encore l'heure d'après. Si l'appareil n'est pas connecté, il tentera d'envoyer le rapport lors de la prochaine tâche de création de rapports qui s'exécutera une fois que l'appareil sera de nouveau connecté au réseau. Le délai maximal est de 28 jours. Cela signifie que l'appareil n'enverra pas de rapport généré il y a plus de 28 jours.
Attendre les rapports
Il est recommandé d'attendre les rapports tardifs lorsque vous collectez des rapports pour le regroupement. Pour déterminer si un rapport est en retard, comparez la valeur scheduled_report_time à la date de réception du rapport. La différence de temps entre ces rapports vous aidera à déterminer combien de temps vous devez attendre pour les rapports qui arrivent en retard. Par exemple, à mesure que les rapports différés sont collectés, vérifiez le champ scheduled_report_time et notez le délai en heures lorsque 90 %, 95 % et 99 % des rapports sont reçus. Ces données peuvent être utilisées pour déterminer le temps d'attente pour les rapports en retard.
Les rapports agrégés instantanés peuvent être utilisés pour réduire le risque de retard.
L'illustration suivante montre comment les rapports reçus en retard sont stockés dans les lots appropriés en fonction de l'heure prévue du rapport. "Batch T" représente scheduled_report_time, et "T+X" représente le temps d'attente pour les rapports différés. Vous obtenez ainsi un rapport récapitulatif qui inclut la majorité des rapports du lot correspondant à leur heure de planification.
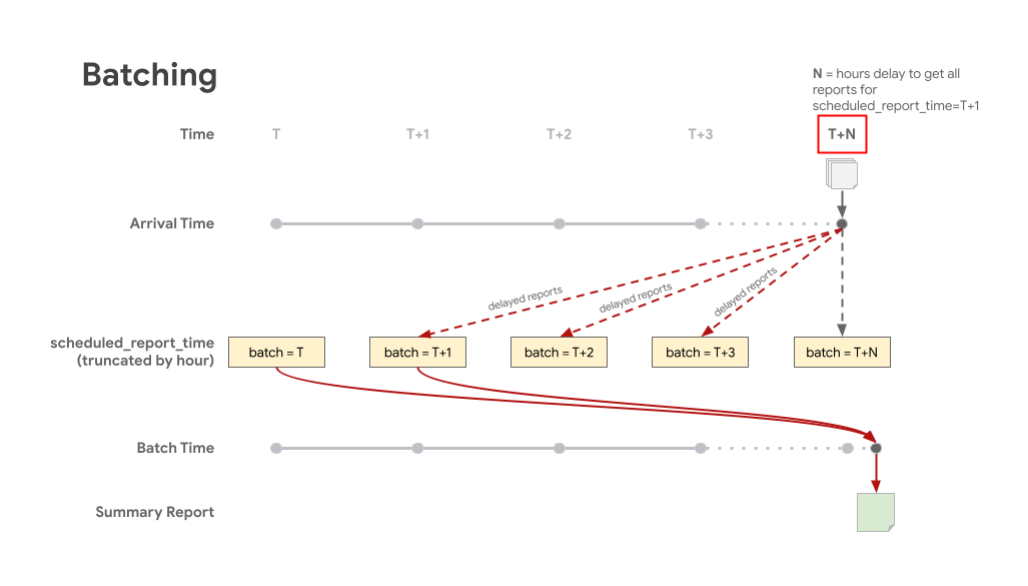
Comptabilisation des rapports agrégables
Le service d'agrégation applique une règle d'absence de doublons. Cette règle exige que tous les rapports agrégables ayant le même ID partagé soient inclus dans le même lot.
Une fois les rapports collectés, ils doivent être regroupés de sorte que tous les rapports ayant le même ID partagé fassent partie d'un même lot.
Si un rapport a déjà été traité dans un autre lot, le traitement peut générer une erreur de budget de confidentialité épuisé. Le regroupement correct des rapports permet d'éviter que les lots soient refusés en raison de la règle "Pas de doublons".
Un ID partagé est une clé générée pour chaque rapport afin de suivre la comptabilité des rapports agrégables. L'ID partagé permet de s'assurer que les rapports ayant le même ID partagé ne contribuent qu'à un seul rapport récapitulatif. Cela signifie que les rapports qui correspondent à un même ID partagé doivent tous être inclus dans un même lot. Par exemple, si les rapports X et Y ont le même ID partagé, ils doivent être inclus dans le même lot pour éviter que des rapports ne soient supprimés pour cause de doublons.
L'image suivante montre les composants shared_info qui sont hachés ensemble pour générer un ID partagé.
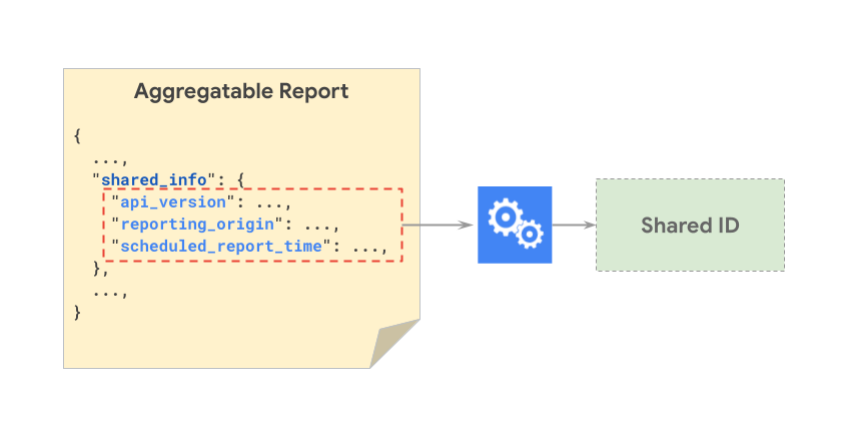
L'image suivante montre comment deux rapports différents peuvent avoir le même ID partagé :

Remarque : scheduled_report_time est tronqué à l'heure et source_registration_time est tronqué au jour. De plus, report_id n'est pas utilisé lors de la création d'ID partagés. La précision temporelle pourra être modifiée à l'avenir.
Rapports en double dans les lots
Le champ shared_info d'un rapport agrégable contient un UUID dans le champ report_id, qui permet d'identifier les rapports en double dans un lot. Si un lot contient plusieurs rapports avec le même report_id, seul le premier rapport sera agrégé. Les autres seront considérés comme des doublons et supprimés sans notification. L'agrégation se déroulera normalement et aucune erreur ne sera envoyée.
Bien que cela ne soit pas obligatoire, les technologies publicitaires peuvent s'attendre à une amélioration des performances en filtrant les rapports en double avec les mêmes ID de rapports avant l'agrégation.
Le report_id est unique pour chaque rapport.
Rapports en double dans les lots
Chaque rapport est associé à un ID partagé, qui est généré à partir de points de données combinés provenant du champ shared_info du rapport. Plusieurs rapports peuvent avoir le même ID partagé, et chaque lot peut contenir plusieurs ID partagés. Tous les rapports ayant le même ID partagé doivent figurer dans le même lot. Si des rapports avec le même ID partagé se retrouvent dans plusieurs lots, seul le premier lot sera accepté. Les autres seront refusés, car ils seront considérés comme des doublons. Pour éviter cela, les lots doivent être créés de manière appropriée.
L'image suivante montre un exemple où des rapports ayant le même ID partagé dans différents lots peuvent entraîner l'échec du lot ultérieur. Dans l'image, vous pouvez voir que deux rapports ou plus ayant le même ID partagé e679aa sont regroupés dans des lots différents (n° 1 et n° 2). Étant donné que le budget de tous les rapports avec l'ID partagé e679aa est consommé lors de la génération du rapport récapitulatif du lot 1, le lot 2 n'est pas autorisé et échoue avec une erreur.
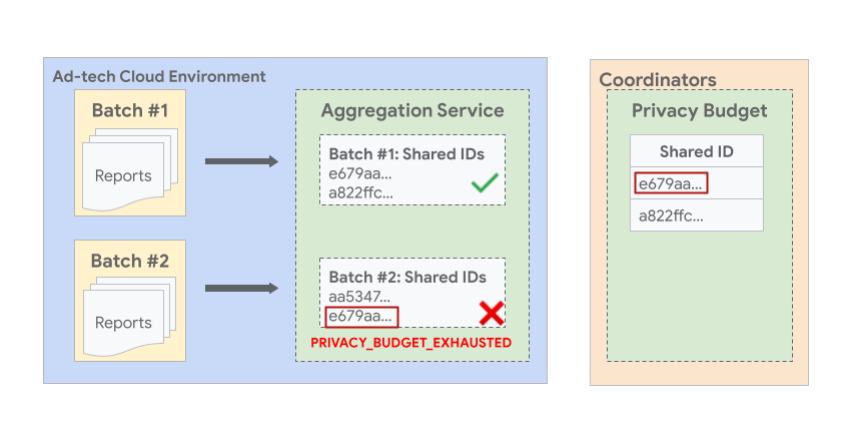
Rapports par lot
Voici quelques méthodes recommandées pour regrouper les rapports par lots afin d'éviter les doublons et d'optimiser la comptabilisation des rapports agrégés.
Regrouper par annonceur
Remarque : Cette stratégie n'est recommandée que pour l'agrégation des rapports sur l'attribution.
Private Aggregation ne comporte pas de champ attribution_destination, qui correspond à l'annonceur. Il est recommandé de regrouper les rapports par annonceur, c'est-à-dire d'inclure les rapports appartenant à un même annonceur dans le même lot, afin d'éviter d'atteindre la limite de comptes pour les rapports agrégables pour chaque lot. L'annonceur est un champ pris en compte dans la génération d'ID partagés. Par conséquent, les rapports avec le même annonceur peuvent également avoir le même ID partagé, ce qui les oblige à figurer dans le même lot pour éviter les erreurs.
Regrouper par période
Il est recommandé de tenir compte de l'heure d'envoi planifiée du rapport (shared_info.scheduled_report_time) lorsque vous regroupez des rapports. L'heure du rapport planifié est tronquée à l'heure dans la génération d'ID partagés. Par conséquent, les rapports doivent être regroupés par lots à des intervalles d'une heure au minimum. Cela signifie que tous les rapports dont l'heure de rapport planifiée se situe dans la même heure doivent figurer dans le même lot pour éviter d'avoir des rapports avec le même ID partagé dans plusieurs lots, ce qui entraînerait des erreurs de job.
Fréquence et bruit des lots
Nous vous recommandons de tenir compte de l'impact du bruit sur la fréquence de traitement des rapports agrégables. Si les rapports agrégables sont regroupés plus fréquemment (par exemple, s'ils sont traités une fois par heure), moins d'événements de conversion seront inclus et le bruit aura un impact relatif plus important. Si la fréquence est réduite et que les rapports sont traités une fois par semaine, le bruit aura un impact relatif plus faible. Pour mieux comprendre l'impact du bruit sur les lots, faites des tests avec le Noise Lab.