
Conceptos clave de la API de Private Aggregation
¿Para quiénes es este documento?
La API de Private Aggregation permite la recopilación de datos agregados de worklets con acceso a datos de varios sitios. Los conceptos que se comparten aquí son importantes para los desarrolladores que crean funciones de informes dentro de la API de Shared Storage y Protected Audience.
- Si eres un desarrollador que crea un sistema de informes para la medición en varios sitios
- Si eres especialista en marketing, científico de datos o cualquier otro consumidor de informes de resumen, comprender estos mecanismos te ayudará a tomar decisiones de diseño para recuperar un informe de resumen optimizado.
Términos clave
Antes de leer este documento, te recomendamos que te familiarices con los términos y conceptos clave. Cada uno de estos términos se describirá en detalle aquí.
- Una clave de agregación (también conocida como discretización) es una colección predeterminada de puntos de datos. Por ejemplo, es posible que desees recopilar un conjunto de datos de ubicación en el que el navegador informe el nombre del país. Una clave de agregación puede contener más de una dimensión (por ejemplo, el país y el ID de tu widget de contenido).
- Un valor agregable es un punto de datos individual que se recopila en una clave de agregación. Si deseas medir cuántos usuarios de Francia vieron tu contenido,
Francees una dimensión en la clave de agregación, y elviewCountde1es el valor agregable. - Los informes agregables se generan y encriptan en un navegador. Para la API de Private Aggregation, contiene datos sobre un solo evento.
- El Servicio de agregación procesa los datos de los informes agregables para crear un informe de resumen.
- Un informe de resumen es el resultado final del Servicio de agregación y contiene datos agregados ruidosos del usuario y datos detallados de conversiones.
- Un worklet es una parte de la infraestructura que te permite ejecutar funciones específicas de JavaScript y devolver información al solicitante. Dentro de un worklet, puedes ejecutar JavaScript, pero no puedes interactuar ni comunicarte con la página externa.
Flujo de trabajo de Private Aggregation
Cuando llamas a la API de Private Aggregation con una clave de agregación y un valor agregable, el navegador genera un informe agregable. Los informes se envían a tu servidor, que los procesa por lotes. El Servicio de agregación procesa los informes por lotes más adelante y genera un informe de resumen.
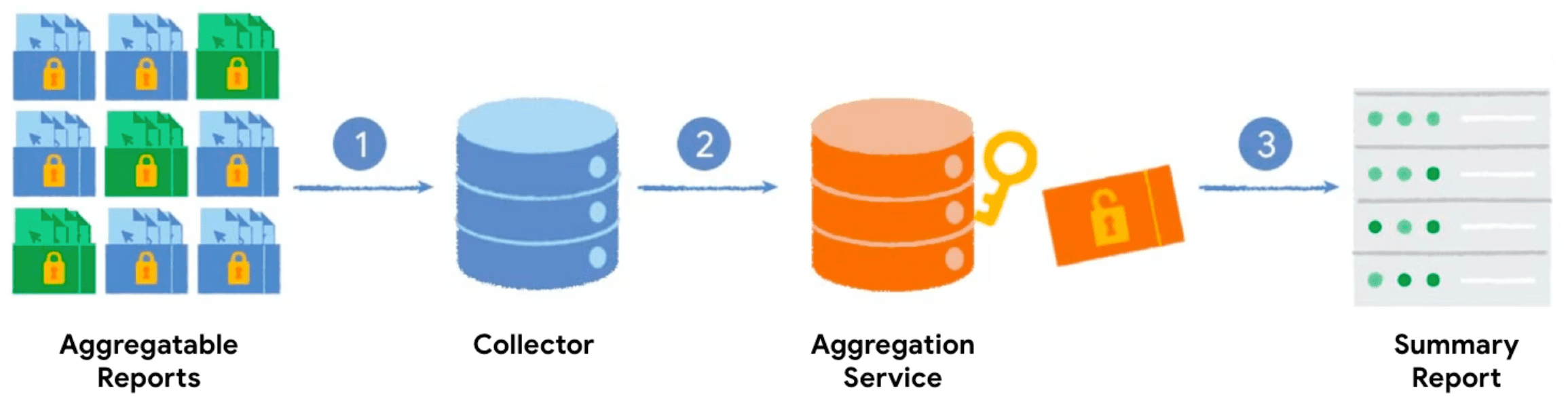
- Cuando llamas a la API de Private Aggregation, el cliente (navegador) genera y envía el informe agregable a tu servidor para que se recopile.
- Tu servidor recopila los informes de los clientes y los agrupa en lotes para enviarlos al Servicio de agregación.
- Una vez que hayas recopilado suficientes informes, los agruparás y enviarás al servicio de agregación, que se ejecuta en un entorno de ejecución de confianza, para generar un informe de resumen.
El flujo de trabajo que se describe en esta sección es similar al de la API de Attribution Reporting. Sin embargo, los Informes de atribución asocian los datos recopilados de un evento de impresión y un evento de conversión, que ocurren en diferentes momentos. La Agregación privada mide un solo evento en varios sitios.
Clave de agregación
Una clave de agregación (o simplemente "clave") representa el bucket en el que se acumularán los valores agregables. Se pueden codificar una o más dimensiones en la clave. Una dimensión representa algún aspecto sobre el que deseas obtener más estadísticas, como el grupo etario de los usuarios o el recuento de impresiones de una campaña publicitaria.
Por ejemplo, es posible que tengas un widget incorporado en varios sitios y quieras analizar el país de los usuarios que lo vieron. Quieres responder preguntas como "¿Cuántos de los usuarios que vieron mi widget son del país X?". Para generar un informe sobre esta pregunta, puedes configurar una clave de agregación que codifique dos dimensiones: el ID del widget y el ID del país.
La clave que se proporciona a la API de Private Aggregation es un BigInt, que consta de varias dimensiones. En este ejemplo, las dimensiones son el ID del widget y el ID del país. Supongamos que el ID del widget puede tener hasta 4 dígitos, como 1234, y que cada país se asigna a un número en orden alfabético, como Afganistán es 1, Francia es 61 y Zimbabue es 195.
Por lo tanto, la clave agregable tendría 7 dígitos, en la que los primeros 4 caracteres se reservan para WidgetID y los últimos 3, para CountryID.
Supongamos que la clave representa el recuento de usuarios de Francia (ID de país 061) que vieron el ID del widget 3276. La clave de agregación es 3276061.
| Clave de agregación | |
| ID del widget | ID del país |
| 3276 | 061 |
La clave de agregación también se puede generar con un mecanismo de hash, como SHA-256. Por ejemplo, la cadena {"WidgetId":3276,"CountryID":67} se puede generar con una función hash y, luego, convertirla en un valor BigInt de 42943797454801331377966796057547478208888578253058197330928948081739249096287n.
Si el valor hash tiene más de 128 bits, puedes truncarlo para asegurarte de que no supere el valor máximo permitido del bucket de 2^128−1.
Dentro de un worklet de Shared Storage, puedes acceder a los módulos crypto y TextEncoder que pueden ayudarte a generar un hash. Para obtener más información sobre cómo generar un hash, consulta SubtleCrypto.digest() en MDN.
En el siguiente ejemplo, se describe cómo puedes generar una clave de bucket a partir de un valor hash:
async function convertToBucket(data) {
// Encode as UTF-8 Uint8Array
const encodedData = new TextEncoder().encode(data);
// Generate SHA-256 hash
const hashBuffer = await crypto.subtle.digest('SHA-256', encodedData);
// Truncate the hash
const truncatedHash = Array.from(new Uint8Array(hashBuffer, 0, 16));
// Convert the byte sequence to a decimal
return truncatedHash.reduce((acc, curr) => acc * 256n + BigInt(curr), 0n);
}
const data = {
WidgetId: 3276,
CountryID: 67
};
const dataString = JSON.stringify(data);
const bucket = await convertToBucket(dataString);
console.log(bucket); // 126200478277438733997751102134640640264n
Valor agregable
Los valores agregables se suman por clave en muchos usuarios para generar estadísticas agregadas en forma de valores de resumen en los informes de resumen.
Ahora, volvamos a la pregunta de ejemplo que se planteó anteriormente: "¿Cuántos de los usuarios que vieron mi widget son de Francia?". La respuesta a esta pregunta se verá de la siguiente manera: "Aproximadamente 4,881 usuarios que vieron mi ID de widget 3276 son de Francia". El valor agregable es 1 para cada usuario, y "4881 usuarios" es el valor agregado que es la suma de todos los valores agregables para esa clave de agregación.
| Clave de agregación | Valor agregable | |
| ID del widget | ID del país | Recuento de vistas |
| 3276 | 061 | 1 |
En este ejemplo, incrementamos el valor en 1 por cada usuario que ve el widget. En la práctica, el valor agregable se puede ajustar para mejorar la relación señal-ruido.
Presupuesto de contribución
Cada llamada a la API de Private Aggregation se denomina contribución. Para proteger la privacidad de los usuarios, se limita la cantidad de contribuciones que se pueden recopilar de una persona.
Cuando sumas todos los valores agregables en todas las claves de agregación, la suma debe ser inferior al presupuesto de contribución. El presupuesto se limita por origen de worklet y por día, y es independiente para los worklets de la API de Protected Audience y de Shared Storage. Para el día, se usa una ventana continua de aproximadamente las últimas 24 horas. Si un nuevo informe agregable provocaría que se supere el presupuesto, no se creará el informe.
El presupuesto de contribución se representa con el parámetro L1 y se establece en 216 (65, 536) por cada diez minutos por día,con un límite de 220 (1,048,576). Consulta la explicación para obtener más información sobre estos parámetros.
El valor del presupuesto de contribución es arbitrario, pero el ruido se ajusta a él. Puedes usar este presupuesto para maximizar la relación señal-ruido en los valores de resumen (se explica con más detalle en la sección Ruido y ajuste).
Para obtener más información sobre los presupuestos de contribución, consulta la explicación. También consulta Presupuesto de contribución para obtener más orientación.
Límite de contribución por informe
Según la persona que llama, el límite de contribución puede variar y, en el caso del almacenamiento compartido, estos límites son valores predeterminados que se pueden anular. En este momento, los informes generados para los llamadores de la API de Shared Storage tienen un límite de 20 contribuciones por informe. Por otro lado, los llamadores de la API de Protected Audience tienen un límite de 100 contribuciones por informe. Estos límites se eligieron para equilibrar la cantidad de contribuciones que se pueden incorporar con el tamaño de la carga útil.
En el caso del almacenamiento compartido, las contribuciones realizadas en una sola operación run() o selectURL() se agrupan en un informe. En el caso de Protected Audience, las contribuciones realizadas por un solo origen en una subasta se agrupan.
Contribuciones con padding
Las contribuciones se modifican aún más con una función de padding. La acción de agregar relleno a la carga útil protege la información sobre la cantidad real de contribuciones incorporadas en el informe agregable. El padding aumenta la carga útil con contribuciones de null (es decir, con un valor de 0) para alcanzar una longitud fija.
Informes agregables
Una vez que el usuario invoca la API de Private Aggregation, el navegador genera informes agregables para que el servicio de agregación los procese en un momento posterior y genere informes de resumen. Un informe agregable tiene formato JSON y contiene una lista encriptada de contribuciones, cada una de las cuales es un par {aggregation key, aggregatable value}.
Los informes agregables se envían con un retraso aleatorio de hasta una hora.
Las contribuciones están encriptadas y no se pueden leer fuera del servicio de agregación. El Servicio de agregación desencripta los informes y genera un informe de resumen. El coordinador, que actúa como servicio de administración de claves, emite la clave de encriptación para el navegador y la clave de desencriptación para el Servicio de agregación. El coordinador mantiene una lista de hashes binarios de la imagen del servicio para verificar que el llamador pueda recibir la clave de desencriptación.
Ejemplo de un informe agregable con el modo de depuración habilitado:
"aggregation_service_payloads": [
{
"debug_cleartext_payload": "omRkYXRhgaJldmFsdWVEAAAAgGZidWNrZXRQAAAAAAAAAAAAAAAAAAAE0mlvcGVyYXRpb25paGlzdG9ncmFt",
"key_id": "2cc72b6a-b92f-4b78-b929-e3048294f4d6",
"payload": "a9Mk3XxvnfX70FsKrzcLNZPy+00kWYnoXF23ZpNXPz/Htv1KCzl/exzplqVlM/wvXdKUXCCtiGrDEL7BQ6MCbQp1NxbWzdXfdsZHGkZaLS2eF+vXw2UmLFH+BUg/zYMu13CxHtlNSFcZQQTwnCHb"
}
],
"debug_key": "777",
"shared_info": "{\"api\":\"shared-storage\",\"debug_mode\":\"enabled\",\"report_id\":\"5bc74ea5-7656-43da-9d76-5ea3ebb5fca5\",\"reporting_origin\":\"https://localhost:4437\",\"scheduled_report_time\":\"1664907229\",\"version\":\"0.1\"}"
Los informes agregables se pueden inspeccionar desde la página chrome://private-aggregation-internals:

Para fines de pruebas, se puede usar el botón "Enviar informes seleccionados" para enviar el informe al servidor de inmediato.
Recopila y procesa por lotes informes agregables
El navegador envía los informes agregables al origen del worklet que contiene la llamada a la API de Private Aggregation, utilizando la ruta de acceso conocida que se indica a continuación:
- Para Shared Storage:
/.well-known/private-aggregation/report-shared-storage - Para Protected Audience:
/.well-known/private-aggregation/report-protected-audience
En estos extremos, deberás operar un servidor (que actuará como recopilador) que reciba los informes agregables enviados desde los clientes.
Luego, el servidor debe generar informes por lotes y enviarlos al servicio de agregación. Crea lotes según la información disponible en la carga útil sin encriptar del informe agregable, como el campo shared_info. Lo ideal sería que los lotes contengan 100 o más informes cada uno.
Puedes decidir agrupar los pedidos por lotes de forma diaria o semanal. Esta estrategia es flexible y puedes cambiar tu estrategia de procesamiento por lotes para eventos específicos en los que esperas más volumen, por ejemplo, los días del año en los que se esperan más impresiones. Los lotes deben incluir informes de la misma versión de la API, el mismo origen del informe y la misma hora programada del informe.
IDs de filtro
La API de Private Aggregation y el Servicio de agregación permiten usar IDs de filtrado para procesar las mediciones a un nivel más detallado, por ejemplo, por campaña publicitaria, en lugar de procesar los resultados en consultas más grandes.
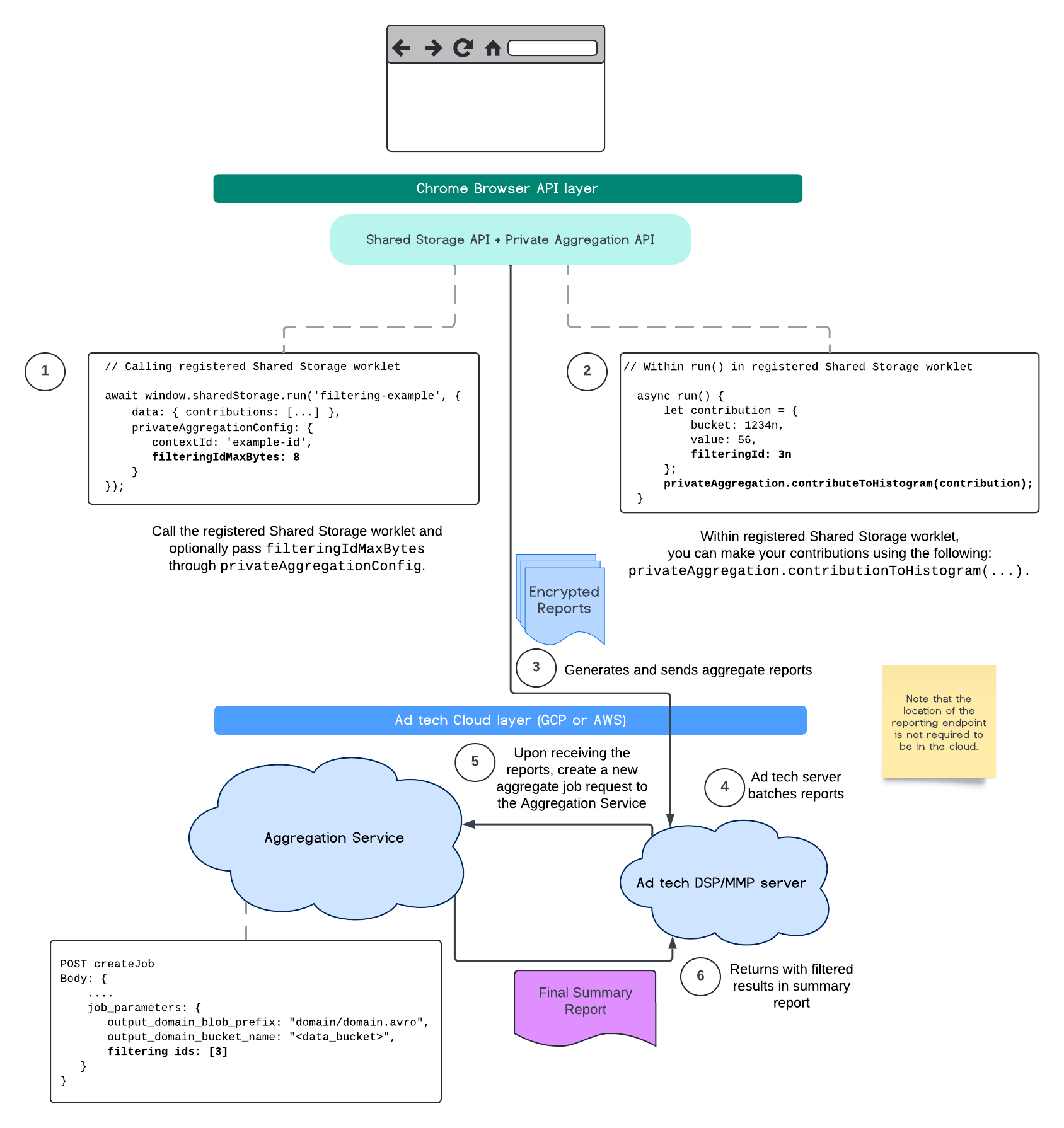
Para comenzar a usarlo hoy mismo, aquí tienes algunos pasos aproximados que puedes aplicar a tu implementación actual.
Pasos de Shared Storage
Si usas la API de Shared Storage en tu flujo, haz lo siguiente:
Define dónde declararás y ejecutarás tu nuevo módulo de Shared Storage. En el siguiente ejemplo, llamamos al archivo del módulo
filtering-worklet.js, registrado enfiltering-example.(async function runFilteringIdsExample () { await window.sharedStorage.worklet.addModule('filtering-worklet.js'); await window.sharedStorage.run('filtering-example', { keepAlive: true, privateAggregationConfig: { contextId: 'example-id', filteringIdMaxBytes: 8 // optional } }}); })();Ten en cuenta que
filteringIdMaxBytesse puede configurar para cada informe y, si no se establece, se usa el valor predeterminado 1. Este valor predeterminado evita que aumente innecesariamente el tamaño de la carga útil y, por lo tanto, los costos de almacenamiento y procesamiento. Obtén más información en la explicación sobre la contribución flexible.En
filtering-worklet.js, cuando pasas una contribución aprivateAggregation.contributeToHistogram(...)dentro del worklet de Shared Storage, puedes especificar un ID de filtrado.// Within filtering-worklet.js class FilterOperation { async run() { let contributions = [{ bucket: 1234n, value: 56, filteringId: 3n // defaults to 0n if not assigned, type bigint }]; for (const c of contributions) { privateAggregation.contributeToHistogram(c); } … } }); register('filtering-example', FilterOperation);Los informes agregables se enviarán al extremo
/.well-known/private-aggregation/report-shared-storageque definiste. Continúa con la guía de IDs de filtrado para obtener información sobre los cambios necesarios en los parámetros del trabajo del Servicio de agregación.
Una vez que se completó el procesamiento por lotes y se envió al servicio de agregación implementado, los resultados filtrados deberían reflejarse en el informe de resumen final.
Pasos de Protected Audience
Si usas la API de Protected Audience en tu flujo, haz lo siguiente:
En tu implementación actual de Protected Audience, puedes configurar lo siguiente para conectarte a Private Aggregation. A diferencia de Shared Storage, aún no es posible configurar el tamaño máximo de los IDs de filtrado. De forma predeterminada, el tamaño máximo del ID de filtrado es de 1 byte y se establecerá en
0n. Ten en cuenta que estos parámetros se establecerían en tus funciones de informes de Protected Audience (p. ej.,reportResult()ogenerateBid()).const contribution = { ... filteringId: 0n }; privateAggregation.contributeToHistogram(contribution);Los informes agregables se enviarán al extremo
/.well-known/private-aggregation/report-protected-audienceque definiste. Una vez que se completa el procesamiento por lotes y se envía al servicio de agregación implementado, los resultados filtrados deberían reflejarse en el informe de resumen final. Están disponibles las siguientes explicaciones de la API de Attribution Reporting y la API de Private Aggregation, así como la propuesta inicial.
Continúa con nuestra guía de IDs de filtrado en el Servicio de agregación o dirígete a las secciones de la API de Attribution Reporting para obtener una explicación más detallada.
Servicio de agregación
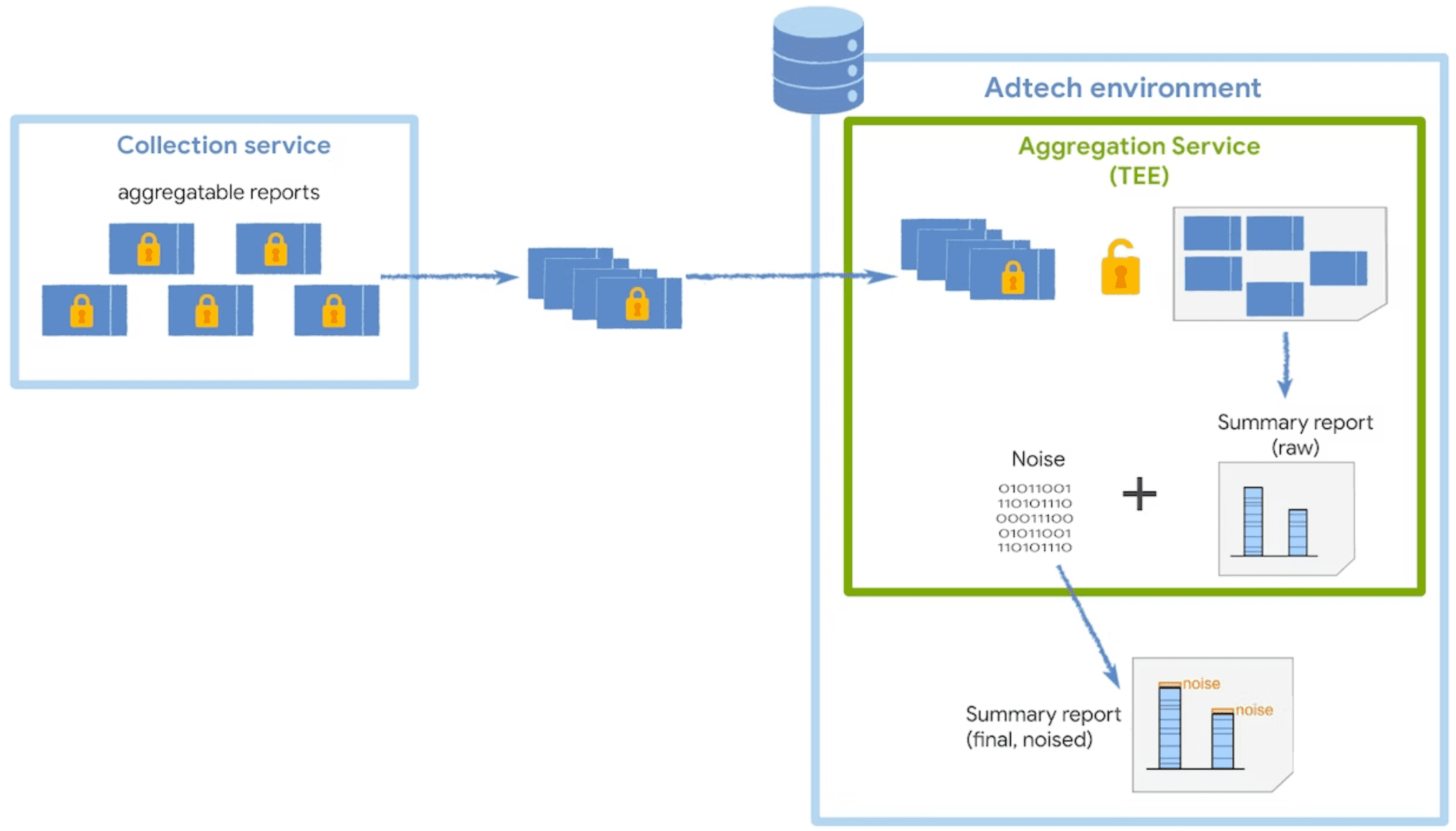
El Servicio de agregación recibe informes agregables encriptados del recopilador y genera informes de resumen. Para obtener más estrategias sobre cómo procesar por lotes los informes agregables en tu recopilador, consulta nuestra guía de procesamiento por lotes.
El servicio se ejecuta en un entorno de ejecución confiable (TEE), que proporciona un nivel de garantía para la integridad de los datos, la confidencialidad de los datos y la integridad del código. Si quieres obtener más información sobre cómo se usan los coordinadores junto con los TEE, consulta su rol y propósito.
Informes de resumen
Los informes de resumen te permiten ver los datos que recopilaste con ruido agregado. Puedes solicitar informes de resumen para un conjunto determinado de claves.
Un informe de resumen contiene un conjunto de pares clave-valor en formato de diccionario JSON. Cada par contiene lo siguiente:
bucket: Es la clave de agregación como una cadena de números binarios. Si la clave de agregación utilizada es "123", el bucket es "1111011".value: Es el valor de resumen para un objetivo de medición determinado, que se obtiene sumando todos los informes agregables disponibles con ruido agregado.
Por ejemplo:
[
{"bucket":` `"111001001",` `"value":` `"2558500"},
{"bucket":` `"111101001",` `"value":` `"3256211"},
{"bucket":` `"111101001",` `"value":` `"6536542"},
]
Ruido y escalamiento
Para preservar la privacidad del usuario, el servicio de agregación agrega ruido una vez a cada valor de resumen cada vez que se solicita un informe de resumen. Los valores de ruido se extraen de forma aleatoria de una distribución de probabilidad de Laplace. Si bien no tienes control directo sobre las formas en que se agrega ruido, puedes influir en el impacto del ruido en sus datos de medición.
La distribución del ruido es la misma, independientemente de la suma de todos los valores agregables. Por lo tanto, cuanto más altos sean los valores agregables, menor será el impacto que probablemente tengan los datos aleatorios.
Por ejemplo, supongamos que la distribución del ruido tiene una desviación estándar de 100 y se centra en cero. Si el valor del informe agregable recopilado (o "valor agregable") es solo 200, la desviación estándar del ruido sería el 50% del valor agregado. Sin embargo, si el valor agregable es 20,000, la desviación estándar del ruido sería solo el 0.5% del valor agregado. Por lo tanto, el valor agregable de 20,000 tendría una relación señal-ruido mucho más alta.
Por lo tanto, multiplicar tu valor agregable por un factor de ajuste puede ayudar a reducir el ruido. El factor de ajuste representa cuánto deseas ajustar un valor agregable determinado.

Si eliges un factor de ajuste más grande para aumentar los valores, se reduce el ruido relativo. Sin embargo, esto también hace que la suma de todas las contribuciones en todos los segmentos alcance el límite del presupuesto de contribución más rápido. Reducir los valores eligiendo una constante de factor de ajuste más pequeña aumenta el ruido relativo, pero reduce el riesgo de alcanzar el límite de presupuesto.
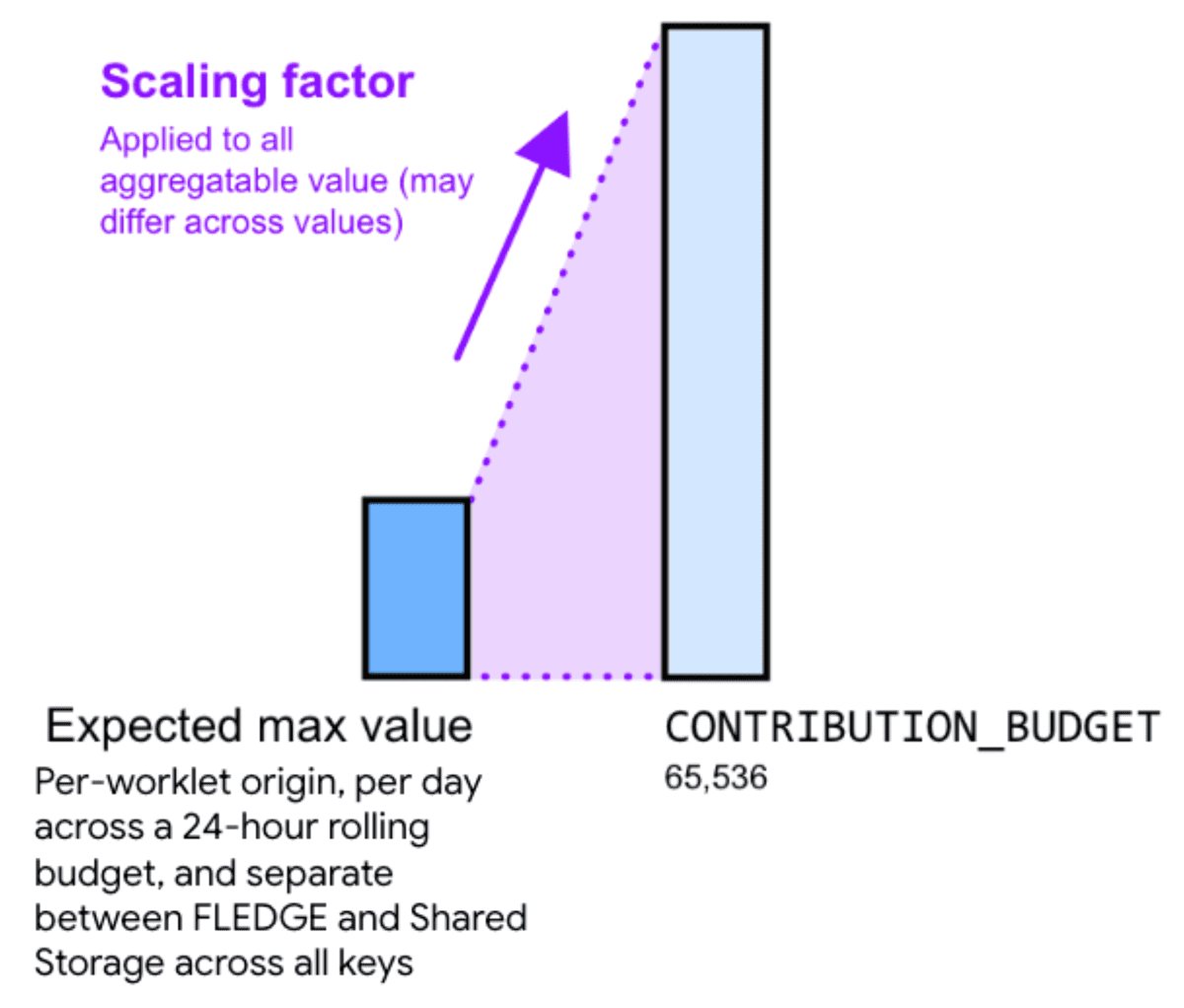
Para calcular un factor de ajuste adecuado, divide el presupuesto de contribución entre la suma máxima de valores agregables en todas las claves.
Consulta la documentación sobre el presupuesto de contribución para obtener más información.
Interactúa y comparte comentarios
La API de Private Aggregation se encuentra en debate activo y está sujeta a cambios en el futuro. Si pruebas esta API y tienes comentarios, nos encantaría conocerlos.
- GitHub: Lee la explicación, haz preguntas y participa en el debate.