
เกี่ยวกับเอกสารนี้
เมื่ออ่านเอกสารนี้ คุณจะได้รับประโยชน์ต่อไปนี้
- ทำความเข้าใจกลยุทธ์ที่จะสร้างก่อนสร้างรายงานสรุป
- ทำความรู้จักห้องทดลองสัญญาณรบกวน ซึ่งเป็นเครื่องมือที่ช่วยให้เข้าใจผลกระทบของพารามิเตอร์สัญญาณรบกวนต่างๆ และช่วยให้สำรวจและประเมินกลยุทธ์การจัดการสัญญาณรบกวนต่างๆ ได้อย่างรวดเร็ว
แชร์ความคิดเห็น
แม้ว่าเอกสารนี้จะสรุปหลักการบางอย่างในการทำงานกับรายงานสรุป แต่ก็มีแนวทางการจัดการสัญญาณรบกวนหลายอย่างที่อาจไม่ได้ระบุไว้ ที่นี่ เรายินดีรับฟังคำแนะนำ การเพิ่มเติม และคำถามจากคุณ
- หากต้องการแสดงความคิดเห็นต่อสาธารณะเกี่ยวกับกลยุทธ์การจัดการสัญญาณรบกวน เกี่ยวกับยูทิลิตีหรือความเป็นส่วนตัวของ API (epsilon) และแชร์ข้อสังเกตเมื่อ จำลองด้วย Noise Lab ให้ทำดังนี้ แสดงความคิดเห็นในปัญหานี้
- หากต้องการแสดงความคิดเห็นต่อสาธารณะเกี่ยวกับ API ในด้านอื่นๆ ให้ทำดังนี้ สร้างปัญหาใหม่ที่นี่
ก่อนจะเริ่ม
- อ่านAttribution Reporting: รายงานสรุปและภาพรวมระบบทั้งหมดของ Attribution Reporting เพื่อดูข้อมูลเบื้องต้น
- โปรดสแกนทำความเข้าใจสัญญาณรบกวนและทำความเข้าใจคีย์การรวมเพื่อใช้ประโยชน์จากคู่มือนี้ให้ได้มากที่สุด
การตัดสินใจเรื่องการออกแบบ
หลักการออกแบบหลัก
คุกกี้ของบุคคลที่สามและรายงานข้อมูลสรุปมีวิธีการทำงานที่แตกต่างกันโดยพื้นฐาน ความแตกต่างที่สำคัญอย่างหนึ่งคือสัญญาณรบกวนที่เพิ่มลงในข้อมูลการวัดผลในรายงานสรุป อีกอย่างคือวิธีตั้งเวลารายงาน
หากต้องการเข้าถึงข้อมูลการวัดผลรายงานสรุปที่มีอัตราส่วนสัญญาณต่อสัญญาณรบกวนสูงขึ้น แพลตฟอร์มฝั่งดีมานด์ (DSP) และผู้ให้บริการวัดผลโฆษณาจะต้อง ทำงานร่วมกับผู้ลงโฆษณาเพื่อพัฒนากลยุทธ์การจัดการสัญญาณรบกวน DSP และผู้ให้บริการวัดผลต้องตัดสินใจเรื่องการออกแบบเพื่อพัฒนากลยุทธ์เหล่านี้ การตัดสินใจเหล่านี้เกี่ยวข้องกับแนวคิดสำคัญอย่างหนึ่ง นั่นคือ
แม้ว่าการกระจายค่าสัญญาณรบกวนจะดึงมาจากพารามิเตอร์ 2 รายการเท่านั้น ได้แก่ epsilon และงบประมาณการมีส่วนร่วม แต่คุณก็มีตัวควบคุมอื่นๆ อีกหลายรายการที่จะส่งผลต่ออัตราส่วนสัญญาณต่อสัญญาณรบกวนของข้อมูลการวัดผลลัพธ์
แม้ว่าเราจะคาดหวังว่ากระบวนการแบบวนซ้ำจะนำไปสู่การตัดสินใจที่ดีที่สุด แต่การตัดสินใจแต่ละครั้งจะ นำไปสู่การติดตั้งใช้งานที่แตกต่างกันเล็กน้อย ดังนั้นจึงต้องตัดสินใจก่อนที่จะเขียนโค้ดแต่ละครั้ง (และก่อนที่จะแสดงโฆษณา)
การตัดสินใจ: ระดับรายละเอียดของมิติข้อมูล
ลองใช้ใน Noise Lab
- ไปที่โหมดขั้นสูง
- ในแผงด้านข้างของพารามิเตอร์ ให้มองหาข้อมูล Conversion
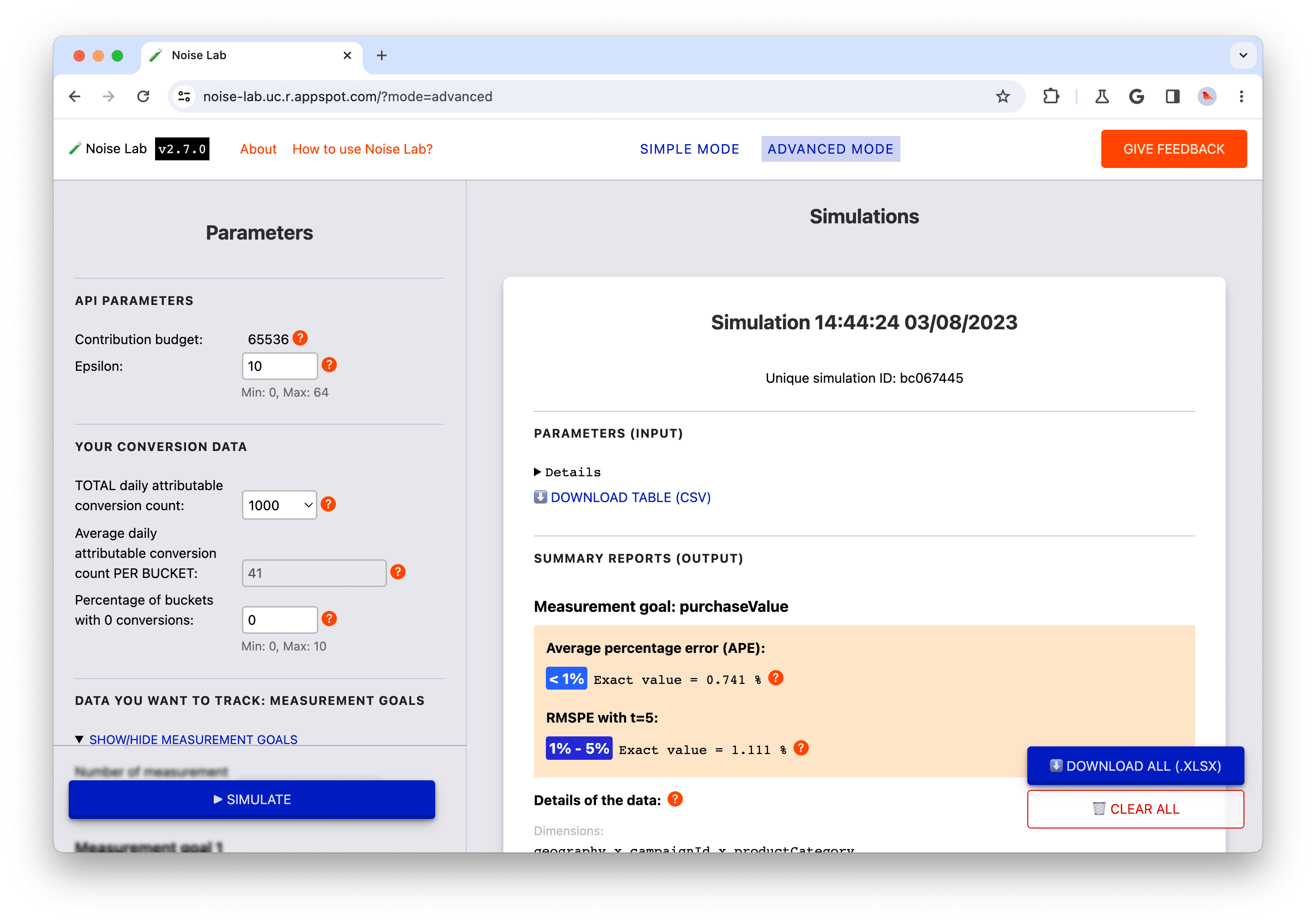
- สังเกตพารามิเตอร์เริ่มต้น โดยค่าเริ่มต้น จำนวน Conversion ที่ระบุแหล่งที่มาได้ทั้งหมดต่อวันคือ 1, 000 ซึ่งโดยเฉลี่ยจะอยู่ที่ประมาณ 40 ต่อ ที่เก็บข้อมูล หากคุณใช้การตั้งค่าเริ่มต้น (มิติข้อมูลเริ่มต้น จำนวน ค่าที่แตกต่างกันที่เป็นไปได้เริ่มต้นสำหรับแต่ละมิติข้อมูล กลยุทธ์คีย์ A) สังเกตว่า ค่าคือ 40 ในจํานวน Conversion ที่ระบุแหล่งที่มาเฉลี่ยรายวันที่ป้อน ต่อกลุ่ม
- คลิกจำลองเพื่อเรียกใช้การจำลองด้วยพารามิเตอร์เริ่มต้น
- ในแผงด้านข้างของพารามิเตอร์ ให้มองหามิติข้อมูล เปลี่ยนชื่อ ภูมิศาสตร์เป็นเมือง และเปลี่ยนจำนวนค่าที่แตกต่างกันที่เป็นไปได้เป็น 50
- สังเกตว่าการเปลี่ยนแปลงนี้ส่งผลต่อจํานวน Conversion ที่ระบุแหล่งที่มาได้รายวันโดยเฉลี่ย ต่อกลุ่มอย่างไร ซึ่งตอนนี้ต่ำกว่ามาก เนื่องจากหากคุณเพิ่ม จำนวนค่าที่เป็นไปได้ภายในมิตินี้โดยไม่เปลี่ยนแปลง สิ่งอื่นใด คุณจะเพิ่มจำนวนกลุ่มทั้งหมดโดยไม่เปลี่ยนแปลง จำนวนเหตุการณ์ Conversion ที่จะอยู่ในแต่ละกลุ่ม
- คลิกจำลอง
- สังเกตอัตราส่วนสัญญาณรบกวนของการจำลองที่ได้ อัตราส่วนสัญญาณรบกวน ตอนนี้สูงกว่าการจำลองครั้งก่อน
เนื่องจากหลักการออกแบบหลัก ค่าสรุปขนาดเล็กจึงมีแนวโน้มที่จะ มีสัญญาณรบกวนมากกว่าค่าสรุปขนาดใหญ่ ดังนั้น ตัวเลือกการกำหนดค่า จึงส่งผลต่อจำนวนเหตุการณ์ Conversion ที่ระบุแหล่งที่มาซึ่งลงท้ายในแต่ละกลุ่ม (หรือที่เรียกว่าคีย์การรวบรวม) และจำนวนดังกล่าวจะส่งผลต่อสัญญาณรบกวนในรายงานสรุปเอาต์พุตสุดท้าย
การตัดสินใจด้านการออกแบบอย่างหนึ่งที่มีผลต่อจํานวนเหตุการณ์ Conversion ที่ระบุแหล่งที่มา ภายในกลุ่มเดียวคือระดับรายละเอียดของมิติข้อมูล ลองดูตัวอย่างต่อไปนี้ ของคีย์การรวบรวมและมิติข้อมูลของคีย์
- แนวทางที่ 1: โครงสร้างคีย์เดียวที่มีมิติข้อมูลแบบคร่าวๆ: ประเทศ x แคมเปญโฆษณา (หรือที่เก็บข้อมูลแคมเปญที่ใหญ่ที่สุด) x ประเภทผลิตภัณฑ์ (จากประเภทผลิตภัณฑ์ที่เป็นไปได้ 10 ประเภท)
- แนวทางที่ 2: โครงสร้างคีย์เดียวที่มีมิติข้อมูลแบบละเอียด: เมือง x รหัสชิ้นงานครีเอทีฟโฆษณา x ผลิตภัณฑ์ (จากผลิตภัณฑ์ที่เป็นไปได้ 100 รายการ)
เมืองเป็นมิติข้อมูลที่มีรายละเอียดมากกว่าประเทศ รหัสชิ้นงานมีรายละเอียดมากกว่า แคมเปญ และผลิตภัณฑ์มีรายละเอียดมากกว่าประเภทผลิตภัณฑ์ ดังนั้น แนวทางที่ 2 จะมีจํานวนเหตุการณ์ (Conversion) ต่อกลุ่ม (= ต่อ คีย์) น้อยกว่าแนวทางที่ 1 ในเอาต์พุตรายงานสรุป เนื่องจากสัญญาณรบกวนที่เพิ่มลงใน เอาต์พุตไม่ขึ้นอยู่กับจํานวนเหตุการณ์ในที่เก็บข้อมูล ข้อมูลการวัด ในรายงานสรุปจะมีสัญญาณรบกวนมากขึ้นเมื่อใช้แนวทางที่ 2 สําหรับผู้ลงโฆษณาแต่ละราย ให้ทดสอบการแลกเปลี่ยนความละเอียดต่างๆ ในการออกแบบคีย์เพื่อให้มีประโยชน์สูงสุดในผลลัพธ์
การตัดสินใจ: โครงสร้างหลัก
ลองใช้ใน Noise Lab
ในโหมดง่าย ระบบจะใช้โครงสร้างคีย์เริ่มต้น ในโหมดขั้นสูง คุณสามารถทดลองใช้โครงสร้างคีย์ต่างๆ ได้ ระบบจะรวมมิติข้อมูลตัวอย่างไว้ด้วย และคุณยังแก้ไขมิติข้อมูลเหล่านี้ได้ด้วย
- ไปที่โหมดขั้นสูง
- ในแผงด้านข้างของพารามิเตอร์ ให้มองหากลยุทธ์หลัก สังเกต ว่ากลยุทธ์เริ่มต้นชื่อ A ในเครื่องมือใช้โครงสร้างคีย์แบบละเอียด ซึ่งรวมมิติข้อมูลทั้งหมด ได้แก่ ภูมิศาสตร์ x รหัสแคมเปญ x หมวดหมู่ผลิตภัณฑ์
- คลิกจำลอง
- สังเกตอัตราส่วนสัญญาณรบกวนของการจำลองที่ได้
- เปลี่ยนกลยุทธ์คีย์เป็น B ซึ่งจะแสดงตัวควบคุมเพิ่มเติม เพื่อให้คุณกำหนดค่าโครงสร้างคีย์
- กำหนดค่าโครงสร้างคีย์ เช่น ดังนี้
- จำนวนโครงสร้างคีย์: 2
- โครงสร้างหลัก 1 = ภูมิศาสตร์ x หมวดหมู่ผลิตภัณฑ์
- โครงสร้างหลัก 2 = รหัสแคมเปญ x หมวดหมู่ผลิตภัณฑ์
- คลิกจำลอง
- โปรดสังเกตว่าตอนนี้คุณจะได้รับรายงานสรุป 2 ฉบับต่อเป้าหมายการวัดประเภทหนึ่งๆ (2 ฉบับสำหรับจำนวนการซื้อ 2 ฉบับสำหรับมูลค่าการซื้อ) เนื่องจากคุณใช้ โครงสร้างคีย์ที่แตกต่างกัน 2 โครงสร้าง สังเกตอัตราส่วนสัญญาณรบกวน
- คุณยังลองใช้กับมิติข้อมูลที่กำหนดเองได้ด้วย โดยให้มองหา ข้อมูลที่ต้องการติดตาม: มิติข้อมูล ลองนํามิติข้อมูลตัวอย่างออก แล้วสร้างมิติข้อมูลของคุณเองโดยใช้ปุ่มเพิ่ม/นําออก/รีเซ็ต ด้านล่างมิติข้อมูลสุดท้าย
การตัดสินใจด้านการออกแบบอีกอย่างที่จะส่งผลต่อจํานวนเหตุการณ์ Conversion ที่ระบุแหล่งที่มา ภายในที่เก็บข้อมูลเดียวคือโครงสร้างคีย์ ที่คุณตัดสินใจใช้ ลองดูตัวอย่างคีย์การรวบรวมต่อไปนี้
- โครงสร้างคีย์เดียวที่มีมิติข้อมูลทั้งหมด เราจะเรียกโครงสร้างนี้ว่ากลยุทธ์คีย์ A
- โครงสร้างหลัก 2 อย่าง ซึ่งแต่ละอย่างมีชุดมิติข้อมูลย่อย เราจะเรียกโครงสร้างนี้ว่า กลยุทธ์หลัก B
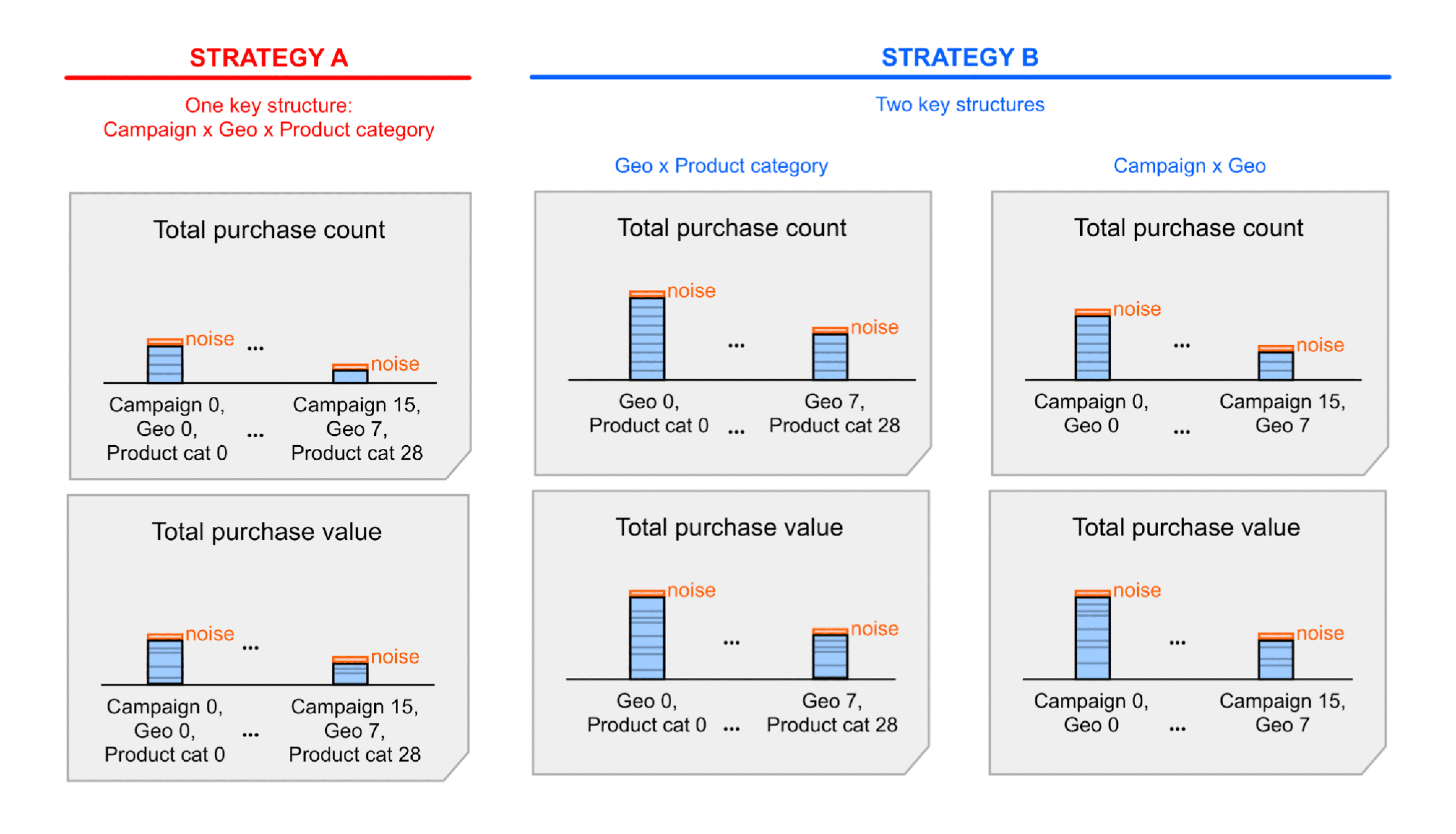
กลยุทธ์ ก. นั้นง่ายกว่า แต่คุณอาจต้องสรุป (รวม) ค่าสรุปที่มีสัญญาณรบกวนซึ่งรวมอยู่ในรายงานสรุปเพื่อเข้าถึงข้อมูลเชิงลึกบางอย่าง การรวมค่าเหล่านี้ยังเป็นการรวมสัญญาณรบกวนด้วย เมื่อใช้กลยุทธ์ B ค่าสรุปที่แสดงในรายงานสรุป อาจให้ข้อมูลที่คุณต้องการอยู่แล้ว ซึ่งหมายความว่ากลยุทธ์ B มีแนวโน้มที่จะทําให้อัตราส่วนสัญญาณต่อสัญญาณรบกวนดีกว่ากลยุทธ์ A อย่างไรก็ตาม สัญญาณรบกวนอาจยอมรับได้อยู่แล้วในกลยุทธ์ ก. ดังนั้นคุณอาจยังคงเลือกใช้กลยุทธ์ ก. เพื่อความเรียบง่าย ดูข้อมูลเพิ่มเติมในตัวอย่างแบบละเอียดที่อธิบายกลยุทธ์ทั้ง 2 นี้
การจัดการคีย์เป็นหัวข้อที่ซับซ้อน คุณอาจพิจารณาใช้เทคนิคที่ซับซ้อนหลายอย่างเพื่อปรับปรุงอัตราส่วนสัญญาณต่อสัญญาณรบกวน โดยจะอธิบายไว้ในการจัดการคีย์ขั้นสูง
การตัดสินใจ: ความถี่ในการประมวลผลแบบกลุ่ม
ลองใช้ใน Noise Lab
- ไปที่โหมดเรียบง่าย (หรือโหมดขั้นสูง ทั้ง 2 โหมดทำงานในลักษณะเดียวกันเมื่อพูดถึงความถี่ในการจัดกลุ่ม)
- ในแผงด้านข้างของพารามิเตอร์ ให้มองหากลยุทธ์การรวบรวม > ความถี่ในการจัดกลุ่ม ซึ่งหมายถึงความถี่ในการจัดกลุ่มของ รายงานที่รวบรวมได้ซึ่งประมวลผลด้วยบริการรวมข้อมูลใน งานเดียว
- สังเกตความถี่ในการประมวลผลเป็นกลุ่มเริ่มต้น: โดยค่าเริ่มต้น ระบบจะจำลองความถี่ในการประมวลผลเป็นกลุ่มรายวัน
- คลิกจำลอง
- สังเกตอัตราส่วนสัญญาณรบกวนของการจำลองที่ได้
- เปลี่ยนความถี่ในการจัดกลุ่มเป็นรายสัปดาห์
- สังเกตอัตราส่วนสัญญาณต่อเสียงรบกวนของการจำลองที่ได้ อัตราส่วนสัญญาณต่อเสียงรบกวน ตอนนี้ต่ำกว่า (ดีกว่า) การจำลองก่อนหน้า
การตัดสินใจด้านการออกแบบอีกอย่างที่จะส่งผลต่อจํานวนเหตุการณ์ Conversion ที่ระบุแหล่งที่มา ภายในกลุ่มเดียวคือความถี่ในการประมวลผลแบบกลุ่มที่คุณตัดสินใจใช้ ความถี่ในการประมวลผลแบบกลุ่มคือความถี่ที่คุณประมวลผลรายงานที่รวบรวมได้
รายงานที่กําหนดเวลาการรวบรวมบ่อยขึ้น (เช่น ทุกชั่วโมง) จะมีเหตุการณ์ Conversion น้อยกว่ารายงานเดียวกันที่มีกําหนดเวลาการรวบรวมที่ถี่น้อยกว่า (เช่น ทุกสัปดาห์) ด้วยเหตุนี้ รายงานรายชั่วโมงจึงมีสัญญาณรบกวนมากขึ้น``` และมีเหตุการณ์ Conversion น้อยกว่ารายงานเดียวกันที่มีกำหนดการ การรวบรวมที่ถี่น้อยกว่า (เช่น ทุกสัปดาห์) ด้วยเหตุนี้ รายงานรายชั่วโมงจึงมี อัตราส่วนสัญญาณต่อสัญญาณรบกวนต่ำกว่ารายงานรายสัปดาห์ เมื่อพิจารณาจากปัจจัยอื่นๆ ที่เท่ากัน ทดลองใช้ข้อกำหนดการรายงานที่ความถี่ต่างๆ และประเมินอัตราส่วนสัญญาณต่อสัญญาณรบกวนสำหรับแต่ละข้อกำหนด
ดูข้อมูลเพิ่มเติมได้ใน การประมวลผลเป็นกลุ่ม และการรวบรวมข้อมูลในช่วงระยะเวลาที่นานขึ้น
การตัดสินใจ: ตัวแปรแคมเปญที่ส่งผลต่อ Conversion ที่ระบุแหล่งที่มาได้
ลองใช้ใน Noise Lab
แม้ว่าการคาดการณ์นี้อาจทำได้ยากและอาจมีความผันผวนอย่างมากนอกเหนือจากผลกระทบตามฤดูกาล แต่ให้ลองประมาณจำนวน Conversion ที่มาจากการแตะครั้งเดียวรายวันให้ใกล้เคียงกับเลขยกกำลังของ 10 มากที่สุด ได้แก่ 10, 100, 1,000 หรือ 10,000
- ไปที่โหมดขั้นสูง
- ในแผงด้านข้างของพารามิเตอร์ ให้มองหาข้อมูล Conversion
- สังเกตพารามิเตอร์เริ่มต้น โดยค่าเริ่มต้น จำนวน Conversion ที่ระบุแหล่งที่มาได้ทั้งหมดต่อวันคือ 1, 000 ซึ่งโดยเฉลี่ยจะอยู่ที่ประมาณ 40 ต่อ ที่เก็บข้อมูล หากคุณใช้การตั้งค่าเริ่มต้น (มิติข้อมูลเริ่มต้น จำนวน ค่าที่แตกต่างกันที่เป็นไปได้เริ่มต้นสำหรับแต่ละมิติข้อมูล กลยุทธ์คีย์ A) สังเกตว่า ค่าคือ 40 ในจํานวน Conversion ที่ระบุแหล่งที่มาเฉลี่ยรายวันที่ป้อน ต่อกลุ่ม
- คลิกจำลองเพื่อเรียกใช้การจำลองด้วยพารามิเตอร์เริ่มต้น
- สังเกตอัตราส่วนสัญญาณรบกวนของการจำลองที่ได้
- ตอนนี้ให้ตั้งค่าจํานวน Conversion ที่ระบุแหล่งที่มาได้ทั้งหมดต่อวันเป็น 100 โปรดทราบว่าการดำเนินการนี้จะลดมูลค่าของจำนวน Conversion ที่ระบุแหล่งที่มาได้เฉลี่ยรายวัน ต่อกลุ่ม
- คลิกจำลอง
- สังเกตว่าตอนนี้อัตราส่วนสัญญาณรบกวนสูงขึ้น เนื่องจากเมื่อคุณมี Conversion ต่อกลุ่มน้อยลง ระบบจะใช้สัญญาณรบกวนมากขึ้นเพื่อรักษาความเป็นส่วนตัว
ความแตกต่างที่สำคัญคือจำนวน Conversion ที่เป็นไปได้ทั้งหมดสำหรับผู้ลงโฆษณา เทียบกับจำนวน Conversion ที่ระบุแหล่งที่มาที่เป็นไปได้ทั้งหมด ซึ่งเป็นสิ่งที่ส่งผลต่อสัญญาณรบกวนในรายงานสรุปในท้ายที่สุด Conversion ที่มาจากการระบุแหล่งที่มา เป็นส่วนย่อยของ Conversion ทั้งหมดที่มีแนวโน้มที่จะได้รับผลกระทบจากตัวแปรของแคมเปญ เช่น งบประมาณโฆษณาและการกำหนดเป้าหมายโฆษณา เช่น คุณคาดหวังว่าแคมเปญโฆษณาที่มีงบประมาณ 300 ล้านบาทจะได้รับ Conversion ที่ระบุแหล่งที่มาจำนวนมากกว่าแคมเปญโฆษณาที่มีงบประมาณ 300,000 บาท เมื่อพิจารณาจากปัจจัยอื่นๆ ที่เท่ากัน
สิ่งที่ควรพิจารณา
- ประเมิน Conversion ที่ระบุแหล่งที่มาเทียบกับรูปแบบการระบุแหล่งที่มาแบบการแตะครั้งเดียวในอุปกรณ์เดียวกัน เนื่องจากอยู่ในขอบเขตของรายงานสรุปที่รวบรวมด้วย Attribution Reporting API
- พิจารณาทั้งจำนวนในกรณีที่เลวร้ายที่สุดและจำนวนในกรณีที่ดีที่สุด สำหรับ Conversion ที่มาจากการระบุแหล่งที่มา ตัวอย่างเช่น เมื่อพิจารณางบประมาณแคมเปญที่เป็นไปได้ขั้นต่ำและสูงสุดสำหรับผู้ลงโฆษณาแล้ว ให้ คาดการณ์ Conversion ที่มาจากการระบุแหล่งที่มาสำหรับผลลัพธ์ทั้ง 2 รายการเป็นข้อมูลนำเข้าในการ จำลอง
- หากคุณกำลังพิจารณาใช้ Privacy Sandbox ของ Android ให้พิจารณา Conversion ที่มาจากการระบุแหล่งที่มาข้ามแพลตฟอร์มในการคำนวณ
การตัดสินใจ: การใช้การปรับขนาด
ลองใช้ใน Noise Lab
- ไปที่โหมดขั้นสูง
- ในแผงด้านข้างของพารามิเตอร์ ให้มองหากลยุทธ์การรวบรวม > การปรับขนาด โดยค่าเริ่มต้น ระบบจะตั้งค่าเป็น "ใช่"
- เพื่อทำความเข้าใจผลลัพธ์เชิงบวกของการปรับขนาดต่ออัตราส่วนสัญญาณต่อสัญญาณรบกวน ให้ตั้งค่าการปรับขนาดเป็น "ไม่" ก่อน
- คลิกจำลอง
- สังเกตอัตราส่วนสัญญาณรบกวนของการจำลองที่ได้
- ตั้งค่าการปรับขนาดเป็น "ใช่" โปรดทราบว่า Noise Lab จะคำนวณ ค่าตัวคูณมาตราส่วนที่จะใช้โดยอัตโนมัติตามช่วง (ค่าเฉลี่ยและค่าสูงสุด) ของ เป้าหมายการวัดสำหรับสถานการณ์ของคุณ ในการตั้งค่าระบบจริงหรือการทดลองใช้แหล่งที่มา คุณจะต้องใช้การคำนวณของคุณเองสำหรับปัจจัยการปรับขนาด
- คลิกจำลอง
- สังเกตว่าตอนนี้อัตราส่วนสัญญาณต่อสัญญาณรบกวนต่ำลง (ดีขึ้น) ในการจำลองครั้งที่ 2 นี้ เนื่องจากคุณใช้การปรับขนาด
เมื่อพิจารณาหลักการออกแบบหลักแล้ว สัญญาณรบกวนที่เพิ่มเข้ามาจะเป็น ฟังก์ชันของงบประมาณการมีส่วนร่วม
ดังนั้น หากต้องการเพิ่มอัตราส่วนสัญญาณต่อสัญญาณรบกวน คุณสามารถเลือกที่จะเปลี่ยนค่าที่รวบรวมในระหว่างเหตุการณ์ Conversion โดยปรับขนาดค่าเหล่านั้นเทียบกับงบประมาณการมีส่วนร่วม (และยกเลิกการปรับขนาดหลังจากรวบรวม) ใช้การปรับขนาดเพื่อเพิ่มอัตราส่วนสัญญาณต่อสัญญาณรบกวน
การตัดสินใจ: จำนวนเป้าหมายการวัดผลและการแบ่งงบประมาณความเป็นส่วนตัว
ซึ่งเกี่ยวข้องกับการปรับขนาด โปรดอ่านการใช้การปรับขนาด
ลองใช้ใน Noise Lab
เป้าหมายการวัดผลคือจุดข้อมูลที่แตกต่างกันซึ่งรวบรวมในเหตุการณ์ Conversion
- ไปที่โหมดขั้นสูง
- ในแผงด้านข้างของพารามิเตอร์ ให้มองหาข้อมูลที่คุณต้องการติดตาม เป้าหมายการวัดผล โดยค่าเริ่มต้น คุณจะมีเป้าหมายการวัดผล 2 รายการ ได้แก่ มูลค่าการซื้อ และจํานวนการซื้อ
- คลิกจำลองเพื่อเรียกใช้การจำลองด้วยเป้าหมายเริ่มต้น
- คลิกนำออก การดำเนินการนี้จะนำเป้าหมายการวัดผลล่าสุดออก (ในกรณีนี้คือจำนวนการซื้อ)
- คลิกจำลอง
- สังเกตว่าอัตราส่วนสัญญาณรบกวนสำหรับมูลค่าการซื้อตอนนี้ต่ำลง (ดีขึ้น) สำหรับการจำลองครั้งที่ 2 นี้ เนื่องจากคุณมีเป้าหมายการวัดผลน้อยลง เป้าหมายการวัดผลเดียวจึงได้รับงบประมาณการระบุแหล่งที่มาทั้งหมด ในตอนนี้
- คลิกรีเซ็ต ตอนนี้คุณมีเป้าหมายการวัดผล 2 รายการอีกครั้ง ได้แก่ มูลค่าการซื้อและจำนวนการซื้อ โปรดทราบว่า Noise Lab จะคำนวณ ปัจจัยการปรับขนาดที่จะใช้โดยอัตโนมัติตามช่วง (ค่าเฉลี่ยและค่าสูงสุด) ของ เป้าหมายการวัดผลสำหรับสถานการณ์ของคุณ โดยค่าเริ่มต้น Noise Lab จะแบ่งงบประมาณเท่าๆ กันตามเป้าหมายการวัดผล
- คลิกจำลอง
- สังเกตอัตราส่วนสัญญาณรบกวนของการจำลองที่ได้ จดบันทึก ปัจจัยการปรับขนาดที่แสดงในการจำลอง
- ตอนนี้มาปรับแต่งการแยกงบประมาณความเป็นส่วนตัวเพื่อให้ได้ อัตราส่วนสัญญาณต่อสัญญาณรบกวนที่ดีขึ้นกัน
- ปรับแต่ง % งบประมาณที่กําหนดสําหรับเป้าหมายการวัดแต่ละรายการ เมื่อพิจารณาจากพารามิเตอร์เริ่มต้น เป้าหมายการวัดผล 1 ซึ่งก็คือมูลค่าการซื้อ มีช่วงที่กว้างกว่ามาก (ระหว่าง 0 ถึง 1000) เมื่อเทียบกับเป้าหมายการวัดผล 2 ซึ่งก็คือ จํานวนการซื้อ (ระหว่าง 1 ถึง 1 กล่าวคือเท่ากับ 1 เสมอ) ด้วยเหตุนี้ จึงต้องมี "พื้นที่เพิ่มเติมในการปรับขนาด" การจัดสรรงบประมาณการวัดผลเพิ่มเติมให้กับเป้าหมายการวัดผล 1 จึงเหมาะกว่าเป้าหมายการวัดผล 2 เพื่อให้ปรับขนาดได้อย่างมีประสิทธิภาพมากขึ้น (ดูการปรับขนาด) และด้วยเหตุนี้
- กําหนดงบประมาณ 70% ให้กับเป้าหมายการวัดผล 1 กําหนด 30% ให้กับเป้าหมายการวัดผล 2
- คลิกจำลอง
- สังเกตอัตราส่วนสัญญาณรบกวนของการจำลองที่ได้ สำหรับค่าการซื้อ อัตราส่วนสัญญาณต่อสัญญาณรบกวนจะต่ำกว่า (ดีกว่า) การจำลอง ก่อนหน้านี้อย่างเห็นได้ชัด ส่วนจำนวนการซื้อนั้นแทบไม่มีการเปลี่ยนแปลง
- ปรับการแบ่งงบประมาณในเมตริกต่อไป สังเกตว่าการดำเนินการนี้ส่งผลต่อ สัญญาณรบกวนอย่างไร
โปรดทราบว่าคุณสามารถตั้งเป้าหมายการวัดผลที่กำหนดเองได้โดยใช้ปุ่มเพิ่ม/นำออก/รีเซ็ต
หากคุณวัดจุดข้อมูล (เป้าหมายการวัด) 1 จุดในเหตุการณ์ Conversion เช่น จํานวน Conversion จุดข้อมูลนั้นจะได้รับงบประมาณการมีส่วนร่วมทั้งหมด (65536) หากคุณตั้งเป้าหมายการวัดผลหลายรายการในเหตุการณ์ Conversion เช่น จํานวน Conversion และมูลค่าการซื้อ จุดข้อมูลเหล่านั้นจะต้อง แชร์งบประมาณการระบุแหล่งที่มา ซึ่งหมายความว่าคุณมีอิสระในการเพิ่มมูลค่าน้อยลง
ดังนั้นยิ่งมีเป้าหมายการวัดผลมากเท่าใด อัตราส่วนสัญญาณต่อสัญญาณรบกวน ก็จะยิ่งต่ำลง (สัญญาณรบกวนสูงขึ้น)
อีกเรื่องที่ต้องตัดสินใจเกี่ยวกับเป้าหมายการวัดผลคือการแบ่งงบประมาณ หากคุณแบ่งงบประมาณการสนับสนุนเท่าๆ กันใน 2 จุดข้อมูล แต่ละจุดข้อมูลจะมีงบประมาณ 65536/2 = 32768 ซึ่งอาจเหมาะสมหรือไม่ก็ได้ ขึ้นอยู่กับ ค่าสูงสุดที่เป็นไปได้สำหรับจุดข้อมูลแต่ละจุด ตัวอย่างเช่น หากคุณกําลังวัดจํานวนการซื้อที่มีค่าสูงสุดเท่ากับ 1 และมูลค่าการซื้อที่มีค่าต่ำสุดเท่ากับ 1 และค่าสูงสุดเท่ากับ 120 มูลค่าการซื้อจะได้รับประโยชน์จากการมี "พื้นที่เพิ่มเติม" เพื่อเพิ่มขนาด นั่นคือการได้รับสัดส่วนที่มากขึ้นของงบประมาณการมีส่วนร่วม คุณจะเห็นว่าควรให้ความสําคัญกับเป้าหมายการวัดผลบางอย่างมากกว่าเป้าหมายอื่นๆ หรือไม่เมื่อพิจารณาถึงผลกระทบของสัญญาณรบกวน
การตัดสินใจ: การจัดการค่าผิดปกติ
ลองใช้ใน Noise Lab
เป้าหมายการวัดผลคือจุดข้อมูลที่แตกต่างกันซึ่งรวบรวมในเหตุการณ์ Conversion
- ไปที่โหมดขั้นสูง
- ในแผงด้านข้างของพารามิเตอร์ ให้มองหากลยุทธ์การรวบรวม > การปรับขนาด
- ตรวจสอบว่าได้ตั้งค่าการปรับขนาดเป็น "ใช่" โปรดทราบว่า Noise Lab จะคำนวณค่าตัวคูณมาตราส่วนที่จะใช้โดยอัตโนมัติ โดยอิงตาม ช่วง (ค่าเฉลี่ยและค่าสูงสุด) ที่คุณระบุสำหรับเป้าหมายการวัด
- สมมติว่าการซื้อที่ใหญ่ที่สุดเท่าที่เคยมีมาคือ $2, 000 แต่การซื้อส่วนใหญ่เกิดขึ้นในช่วง $10-$120 ก่อนอื่นมาดูกันว่าจะเกิดอะไรขึ้น หากเราใช้วิธีการปรับขนาดตามตัวอักษร (ไม่แนะนำ) ให้ป้อน $2000 เป็น ค่าสูงสุดสำหรับ purchaseValue
- คลิกจำลอง
- สังเกตว่าอัตราส่วนสัญญาณรบกวนสูง เนื่องจากเราคำนวณปัจจัยการปรับขนาด โดยอิงตาม $2, 000 แต่ในความเป็นจริงแล้ว มูลค่าการซื้อส่วนใหญ่ จะต่ำกว่านั้นอย่างเห็นได้ชัด
- ตอนนี้มาใช้แนวทางการปรับขนาดที่สมเหตุสมผลมากขึ้นกัน เปลี่ยนมูลค่าการซื้อสูงสุดเป็น $120
- คลิกจำลอง
- สังเกตว่าอัตราส่วนสัญญาณรบกวนต่ำกว่า (ดีกว่า) ในการจำลองครั้งที่ 2 นี้
โดยปกติแล้ว หากต้องการใช้การปรับขนาด คุณจะต้องคำนวณปัจจัยการปรับขนาดตาม ค่าสูงสุดที่เป็นไปได้สำหรับเหตุการณ์ Conversion ที่กำหนด (ดูข้อมูลเพิ่มเติมในตัวอย่างนี้)
อย่างไรก็ตาม โปรดหลีกเลี่ยงการใช้ค่าสูงสุดตามตัวอักษรเพื่อคำนวณปัจจัยการปรับขนาดนั้น เนื่องจากจะทําให้อัตราส่วนสัญญาณต่อสัญญาณรบกวนแย่ลง แต่ให้นำค่าผิดปกติออกและ ใช้ค่าสูงสุดที่สมเหตุสมผลแทน
การจัดการค่าผิดปกติเป็นหัวข้อที่ซับซ้อน คุณอาจพิจารณาใช้เทคนิคที่ซับซ้อนหลายอย่างเพื่อปรับปรุงอัตราส่วนสัญญาณต่อสัญญาณรบกวน โดยวิธีหนึ่งอธิบายไว้ในการจัดการค่าผิดปกติขั้นสูง
ขั้นตอนถัดไป
ตอนนี้คุณได้ประเมินกลยุทธ์การจัดการสัญญาณรบกวนต่างๆ สำหรับกรณีการใช้งานของคุณแล้ว คุณก็พร้อมที่จะเริ่มทดลองใช้รายงานสรุปโดยการรวบรวมข้อมูลการวัดผลจริง โดยใช้ช่วงทดลองใช้แหล่งที่มา อ่านคำแนะนำและเคล็ดลับเพื่อลองใช้ API
ภาคผนวก
การแนะนำสั้นๆ เกี่ยวกับ Noise Lab
ห้องทดลองสัญญาณรบกวนช่วยให้คุณประเมินและเปรียบเทียบกลยุทธ์การจัดการสัญญาณรบกวนได้อย่างรวดเร็ว เครื่องมือนี้ช่วยให้คุณทำสิ่งต่อไปนี้ได้
- ทําความเข้าใจพารามิเตอร์หลักที่อาจส่งผลต่อสัญญาณรบกวนและ ผลกระทบที่เกิดขึ้น
- จำลองผลกระทบของสัญญาณรบกวนต่อข้อมูลการวัดผลลัพธ์ที่กำหนด การตัดสินใจด้านการออกแบบที่แตกต่างกัน ปรับแต่งพารามิเตอร์การออกแบบจนกว่าจะได้ อัตราส่วนสัญญาณต่อสัญญาณรบกวนที่เหมาะกับกรณีการใช้งานของคุณ
- โปรดแชร์ความคิดเห็นเกี่ยวกับประโยชน์ของรายงานสรุป เช่น ค่าของพารามิเตอร์เอปซิลอนและพารามิเตอร์สัญญาณรบกวนที่เหมาะกับคุณและไม่เหมาะกับคุณ จุดเปลี่ยนเว้าอยู่ที่ใด
ให้คิดว่านี่เป็นขั้นตอนการเตรียมตัว ห้องทดลองสัญญาณรบกวน สร้างข้อมูลการวัดเพื่อจำลองเอาต์พุตรายงานสรุปตามข้อมูลที่คุณป้อน โดยจะไม่จัดเก็บหรือแชร์ข้อมูลใดๆ
Noise Lab มี 2 โหมดดังนี้
- โหมดง่าย: ทำความเข้าใจพื้นฐานของการควบคุมที่คุณมี เกี่ยวกับเสียงรบกวน
- โหมดขั้นสูง: ทดสอบกลยุทธ์การจัดการสัญญาณรบกวนต่างๆ และประเมิน ว่ากลยุทธ์ใดทําให้เกิดอัตราส่วนสัญญาณต่อสัญญาณรบกวนที่ดีที่สุดสําหรับกรณีการใช้งานของคุณ
คลิกปุ่มในเมนูด้านบนเพื่อสลับระหว่าง 2 โหมด (#1 ในภาพหน้าจอต่อไปนี้)
โหมดเรียบง่าย
- ในโหมดง่าย คุณจะควบคุมพารามิเตอร์ (อยู่ทางด้านซ้ายมือหรือ #2 ในภาพหน้าจอต่อไปนี้) เช่น เอปซิลอน และดูว่าพารามิเตอร์เหล่านั้นส่งผลต่อสัญญาณรบกวนอย่างไร
- พารามิเตอร์แต่ละรายการมีเคล็ดลับเครื่องมือ (ปุ่ม `?`) คลิกเพื่อดูคำอธิบายของแต่ละพารามิเตอร์ (#3 ในภาพหน้าจอต่อไปนี้)
- หากต้องการเริ่มต้น ให้คลิกปุ่ม "จำลอง" แล้วสังเกตลักษณะเอาต์พุต (#4 ในภาพหน้าจอด้านล่าง)
- ในส่วนเอาต์พุต คุณจะเห็นรายละเอียดต่างๆ องค์ประกอบบางอย่างมีเครื่องหมาย `?` อยู่ข้างๆ โปรดใช้เวลาคลิกเครื่องหมาย `?` แต่ละรายการเพื่อดูคำอธิบาย ข้อมูลต่างๆ
- ในส่วนเอาต์พุต ให้คลิกปุ่มเปิด/ปิดรายละเอียด หากต้องการดูตารางเวอร์ชันขยาย (#5 ในภาพหน้าจอต่อไปนี้)
- หลังจากตารางข้อมูลแต่ละตารางในส่วนเอาต์พุต จะมีตัวเลือก ในการดาวน์โหลดตารางเพื่อใช้งานแบบออฟไลน์ นอกจากนี้ ที่มุมขวาล่างยังมีตัวเลือกในการดาวน์โหลดตารางข้อมูลทั้งหมด (#6 ใน ภาพหน้าจอต่อไปนี้)
- ทดสอบการตั้งค่าต่างๆ สำหรับพารามิเตอร์ในส่วนพารามิเตอร์
แล้วคลิกจำลองเพื่อดูว่าการตั้งค่าเหล่านั้นส่งผลต่อเอาต์พุตอย่างไร
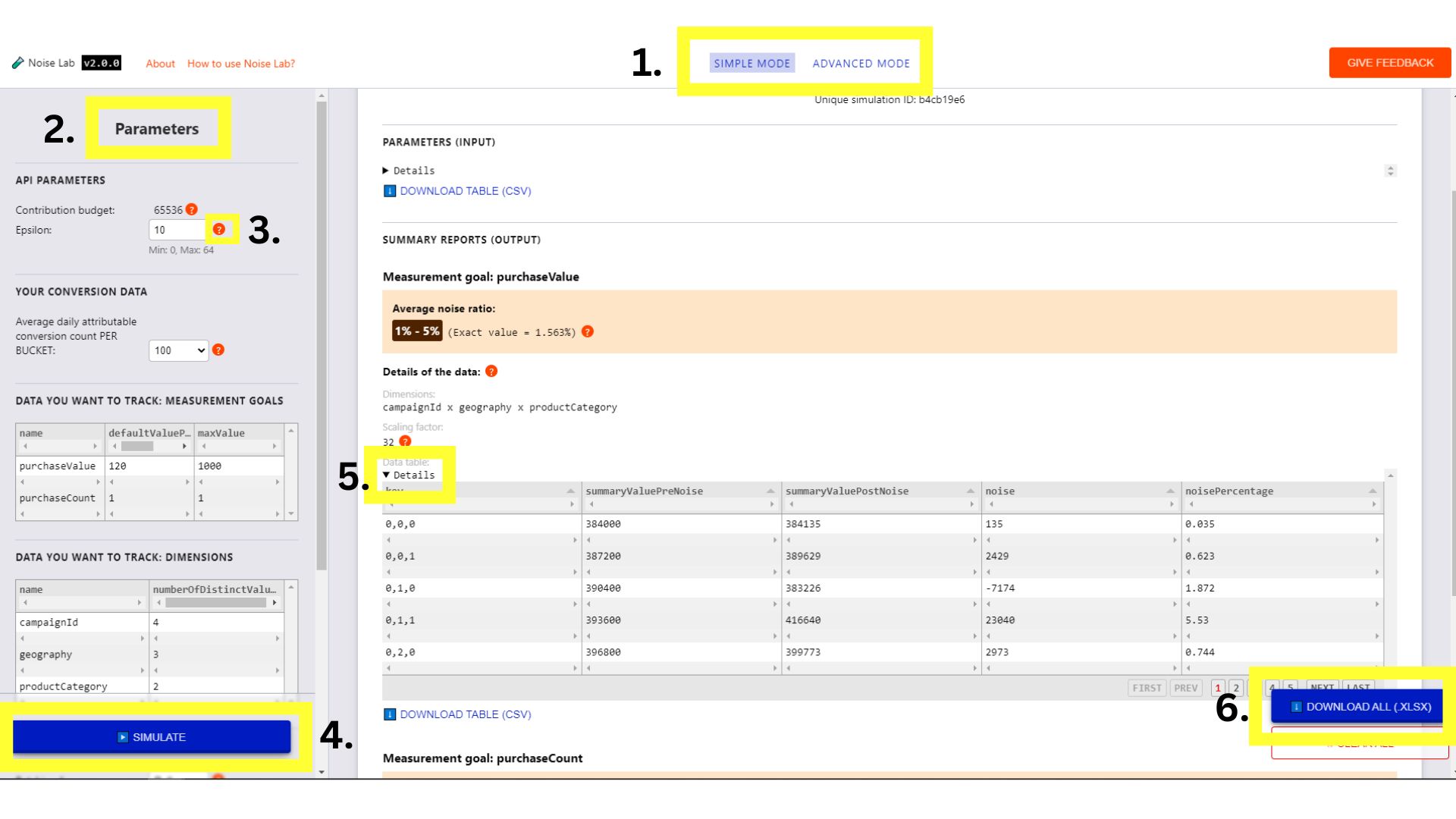
อินเทอร์เฟซ Noise Lab สำหรับโหมดง่าย
โหมดขั้นสูง
- ในโหมดขั้นสูง คุณจะควบคุมพารามิเตอร์ได้มากขึ้น คุณสามารถเพิ่มเป้าหมายการวัดและมิติข้อมูลที่กำหนดเองได้ (#1 และ #2 ในภาพหน้าจอด้านล่าง)
- เลื่อนลงไปที่ส่วนพารามิเตอร์ แล้วดูตัวเลือกคีย์
กลยุทธ์ ซึ่งใช้เพื่อทดสอบโครงสร้างคีย์ต่างๆ ได้
(#3 ในภาพหน้าจอต่อไปนี้)
- หากต้องการทดสอบโครงสร้างคีย์ต่างๆ ให้เปลี่ยนกลยุทธ์คีย์เป็น "B"
- ป้อนจำนวนโครงสร้างคีย์ที่แตกต่างกันที่คุณต้องการใช้ (ค่าเริ่มต้นตั้งไว้ที่ "2")
- คลิกสร้างโครงสร้างคีย์
- คุณจะเห็นตัวเลือกในการระบุโครงสร้างคีย์โดยคลิก ช่องทําเครื่องหมายข้างคีย์ที่ต้องการรวมสําหรับโครงสร้างคีย์แต่ละรายการ
- คลิก "จำลอง" เพื่อดูเอาต์พุต
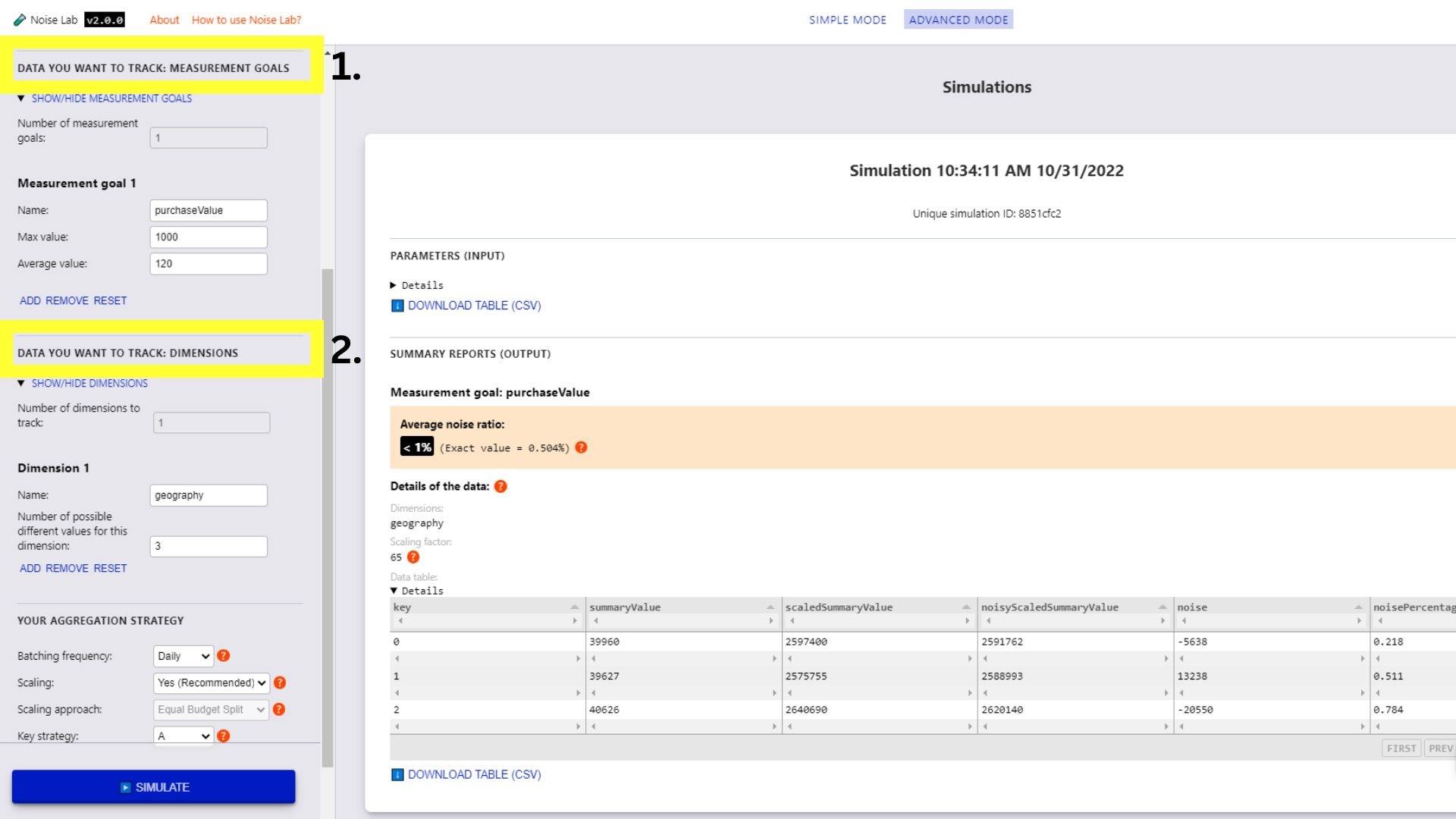
อินเทอร์เฟซ Noise Lab สำหรับโหมดขั้นสูง 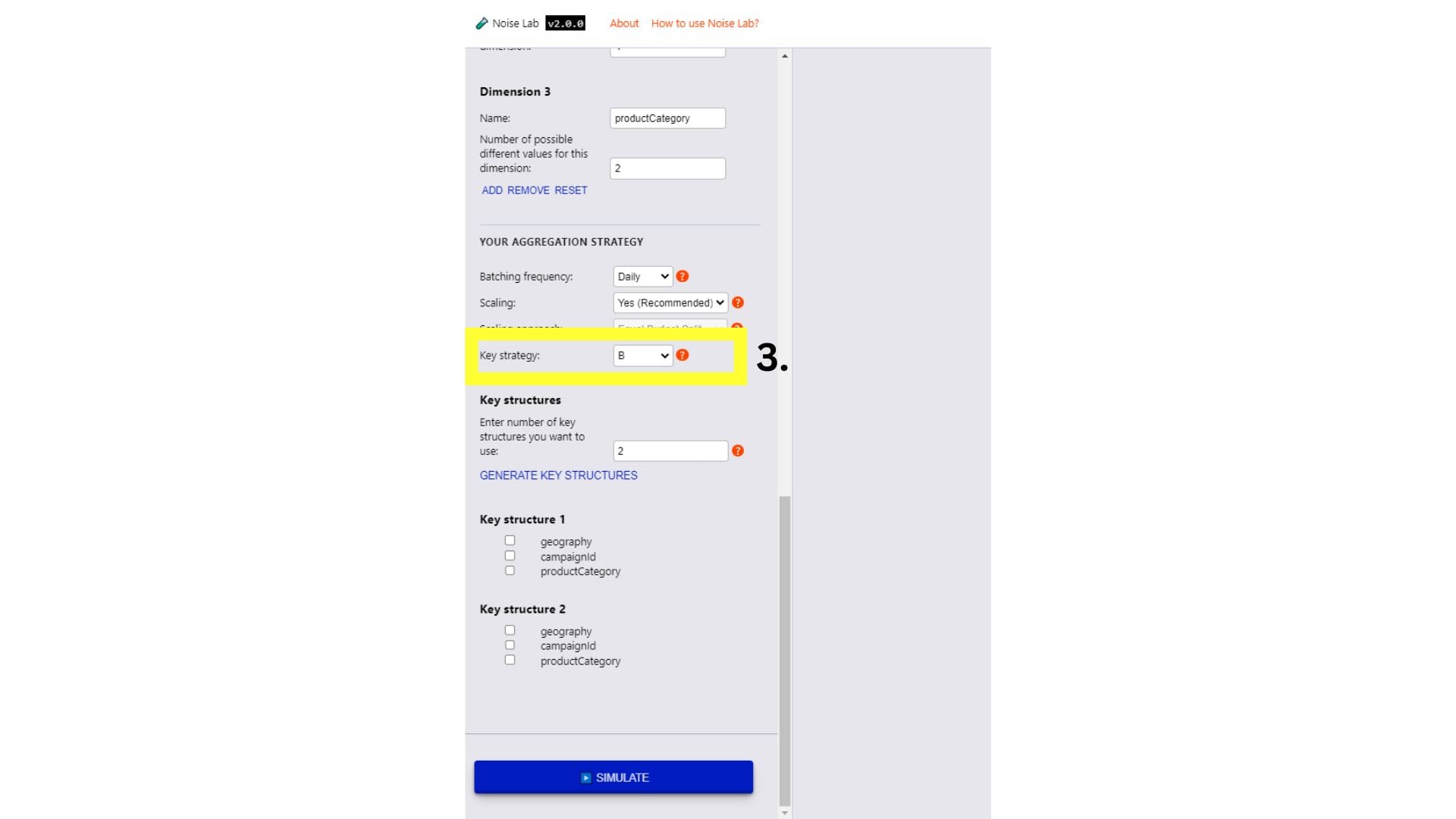
อินเทอร์เฟซ Noise Lab สำหรับโหมดขั้นสูง
เมตริกเสียงรบกวน
แนวคิดหลัก
ระบบจะเพิ่มสัญญาณรบกวนเพื่อปกป้องความเป็นส่วนตัวของผู้ใช้แต่ละราย
ค่าสัญญาณรบกวนสูงบ่งบอกว่ากลุ่ม/คีย์กระจัดกระจายและ มีการมีส่วนร่วมจากเหตุการณ์ที่ละเอียดอ่อนจำนวนจำกัด โดย Noise Lab จะดำเนินการนี้โดยอัตโนมัติเพื่อให้บุคคลสามารถ "ซ่อนตัวในฝูงชน" หรือกล่าวอีกนัยหนึ่งคือปกป้องความเป็นส่วนตัวของบุคคลที่จำกัดเหล่านี้ด้วยการเพิ่มสัญญาณรบกวนจำนวนมากขึ้น
ค่าสัญญาณรบกวนต่ำแสดงว่าการตั้งค่าข้อมูลได้รับการออกแบบในลักษณะที่อนุญาตให้บุคคล "ซ่อนตัวในฝูงชน" อยู่แล้ว ซึ่งหมายความว่า กลุ่มข้อมูลมีส่วนร่วมจากเหตุการณ์จำนวนมากพอที่จะยืนยันได้ว่า ความเป็นส่วนตัวของผู้ใช้แต่ละรายได้รับการปกป้อง
ข้อความนี้เป็นจริงทั้งสำหรับข้อผิดพลาดเป็นเปอร์เซ็นต์เฉลี่ย (APE) และ RMSRE_T (ข้อผิดพลาดสัมพัทธ์แบบรูทมีนสแควร์ที่มีเกณฑ์)
APE (ค่าเฉลี่ยของเปอร์เซ็นต์ความคลาดเคลื่อน)
APE คืออัตราส่วนของสัญญาณรบกวนต่อสัญญาณ ซึ่งก็คือค่าสรุปที่แท้จริง
ค่า APE ที่ต่ำกว่าหมายถึงอัตราส่วนสัญญาณต่อสัญญาณรบกวนที่ดีกว่า
สูตร
สำหรับรายงานสรุปที่ระบุ APE จะคำนวณดังนี้
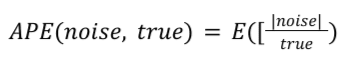
True คือค่าสรุปที่แท้จริง APE คือค่าเฉลี่ยของสัญญาณรบกวนในแต่ละ ค่าสรุปที่แท้จริง โดยเฉลี่ยจากรายการทั้งหมดในรายงานสรุป ในห้องทดลองเสียง ระบบจะคูณค่านี้ด้วย 100 เพื่อให้ได้เป็นเปอร์เซ็นต์
ข้อดีและข้อเสีย
ที่เก็บข้อมูลที่มีขนาดเล็กกว่าจะส่งผลต่อมูลค่าสุดท้ายของ APE อย่างไม่สมส่วน ซึ่งอาจทำให้เข้าใจผิดเมื่อประเมินเสียง ด้วยเหตุนี้ เราจึงได้เพิ่มเมตริกอีกรายการหนึ่งคือ RMSRE_T ซึ่งออกแบบมาเพื่อลดข้อจำกัดของ APE นี้ ดูรายละเอียดได้ในตัวอย่าง
รหัส
ตรวจสอบซอร์สโค้ด สำหรับการคำนวณ APE
RMSRE_T (ค่าเฉลี่ยความคลาดเคลื่อนสัมพัทธ์กำลังสองที่มีเกณฑ์)
RMSRE_T (ค่าเฉลี่ยความคลาดเคลื่อนสัมพัทธ์กำลังสองที่มีเกณฑ์) เป็นอีกหนึ่งมาตรวัดสำหรับสัญญาณรบกวน
วิธีตีความ RMSRE_T
ค่า RMSRE_T ที่ต่ำกว่าหมายถึงอัตราส่วนสัญญาณต่อสัญญาณรบกวนที่ดีกว่า
ตัวอย่างเช่น หากอัตราส่วนสัญญาณต่อสัญญาณรบกวนที่ยอมรับได้สำหรับกรณีการใช้งานของคุณคือ 20% และ RMSRE_T คือ 0.2 คุณจะมั่นใจได้ว่าระดับสัญญาณรบกวนจะอยู่ในช่วงที่ยอมรับได้
สูตร
สำหรับรายงานสรุปที่ระบุ RMSRE_T จะคำนวณดังนี้
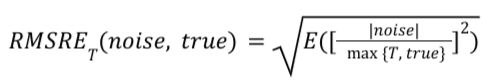
ข้อดีและข้อเสีย
RMSRE_T เข้าใจยากกว่า APE เล็กน้อย อย่างไรก็ตาม APE มีข้อดีบางประการที่ทำให้ในบางกรณีเหมาะสมกว่า APE ในการวิเคราะห์สัญญาณรบกวนในรายงานสรุป
- RMSRE_T มีความเสถียรมากขึ้น "T" คือเกณฑ์ "T" ใช้เพื่อให้น้ำหนักน้อยลงในการคำนวณ RMSRE_T สำหรับกลุ่มที่มี Conversion น้อยกว่า และจึงมีความไวต่อสัญญาณรบกวนมากกว่าเนื่องจากมีขนาดเล็ก เมื่อใช้ T เมตริกจะไม่เพิ่มขึ้นอย่างรวดเร็วในกลุ่มที่มี Conversion น้อย หาก T เท่ากับ 5 ค่าสัญญาณรบกวนที่เล็กเพียง 1 ในกลุ่มที่มี Conversion เป็น 0 จะไม่แสดงเป็นมากกว่า 1 แต่จะจำกัดไว้ที่ 0.2 ซึ่งเท่ากับ 1/5 เนื่องจาก T เท่ากับ 5 การให้น้ำหนักน้อยลงกับกลุ่มข้อมูลขนาดเล็กซึ่งมีความไวต่อสัญญาณรบกวนมากกว่าจะทำให้เมตริกนี้มีความเสถียรมากขึ้น และทำให้เปรียบเทียบการจำลอง 2 รายการได้ง่ายขึ้น
- RMSRE_T ช่วยให้การรวบรวมข้อมูลเป็นไปอย่างตรงไปตรงมา การทราบ RMSRE_T ของที่เก็บข้อมูลหลายรายการพร้อมกับจำนวนจริงจะช่วยให้คุณคำนวณ RMSRE_T ของผลรวมได้ นอกจากนี้ยังช่วยให้คุณเพิ่มประสิทธิภาพเพื่อ RMSRE_T สำหรับค่ารวมเหล่านี้ได้ด้วย
แม้ว่าการรวมจะทำได้สำหรับ APE แต่สูตรค่อนข้างซับซ้อนเนื่องจากเกี่ยวข้องกับค่าสัมบูรณ์ของผลรวมของสัญญาณรบกวนแบบลาปลาซ ซึ่งทำให้การเพิ่มประสิทธิภาพ APE ทำได้ยากขึ้น
รหัส
ตรวจสอบซอร์สโค้ดสำหรับการคำนวณ RMSRE_T
ตัวอย่าง
รายงานสรุปที่มี 3 กลุ่ม
- bucket_1 = noise: 10, trueSummaryValue: 100
- bucket_2 = noise: 20, trueSummaryValue: 100
- bucket_3 = noise: 20, trueSummaryValue: 200
APE = (0.1 + 0.2 + 0.1) / 3 = 13%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,200))^2) / 3) = sqrt( (0.01 + 0.04 + 0.01) / 3) = 0.14
รายงานสรุปที่มี 3 กลุ่ม
- bucket_1 = noise: 10, trueSummaryValue: 100
- bucket_2 = noise: 20, trueSummaryValue: 100
- bucket_3 = noise: 20, trueSummaryValue: 20
APE = (0.1 + 0.2 + 1) / 3 = 43%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,20))^2) / 3) = sqrt( (0.01 + 0.04 + 1.0) / 3) = 0.59
รายงานสรุปที่มี 3 กลุ่ม
- bucket_1 = noise: 10, trueSummaryValue: 100
- bucket_2 = noise: 20, trueSummaryValue: 100
- bucket_3 = noise: 20, trueSummaryValue: 0
APE = (0.1 + 0.2 + Infinity) / 3 = Infinity
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,0))^2) / 3) = sqrt( (0.01 + 0.04 + 16.0) / 3) = 2.31
การจัดการคีย์ขั้นสูง
DSP หรือบริษัทวัดผลโฆษณาอาจมีลูกค้าด้านการโฆษณาทั่วโลกหลายพันราย ซึ่งครอบคลุมอุตสาหกรรม สกุลเงิน และราคาซื้อที่มีศักยภาพหลายรายการ ซึ่งหมายความว่าการสร้างและจัดการคีย์การรวบรวม 1 รายการต่อผู้ลงโฆษณา 1 ราย อาจเป็นไปได้ยาก นอกจากนี้ การเลือกมูลค่าสูงสุดที่รวบรวมได้และงบประมาณการรวบรวมที่สามารถ จำกัดผลกระทบของสัญญาณรบกวนในผู้ลงโฆษณาทั่วโลกหลายพันรายเหล่านี้ก็จะเป็นเรื่องที่ท้าทาย แต่ให้พิจารณาสถานการณ์ต่อไปนี้แทน
กลยุทธ์หลัก ก.
ผู้ให้บริการด้านเทคโนโลยีโฆษณาตัดสินใจสร้างและจัดการคีย์เดียวสำหรับลูกค้าโฆษณาทั้งหมด ผู้ลงโฆษณาทุกรายและทุกสกุลเงินมี การซื้อตั้งแต่การซื้อปริมาณน้อยระดับไฮเอนด์ไปจนถึงการซื้อปริมาณมากระดับล่าง ซึ่งจะส่งผลให้เกิดคีย์ต่อไปนี้
| คีย์ (หลายสกุลเงิน) | |
|---|---|
| ค่าสูงสุดที่รวบรวมได้ | 5,000,000 |
| ช่วงมูลค่าการซื้อ | [120 - 5000000] |
กลยุทธ์ที่สำคัญ B
ผู้ให้บริการด้านเทคโนโลยีโฆษณาตัดสินใจสร้างและจัดการคีย์ 2 รายการในลูกค้าโฆษณาทั้งหมด จึงตัดสินใจแยกคีย์ตามสกุลเงิน การซื้อของผู้ลงโฆษณาทั้งหมดและทุกสกุลเงินมีตั้งแต่การซื้อปริมาณน้อยระดับสูงไปจนถึงการซื้อปริมาณมากระดับต่ำ แยกตามสกุลเงิน ระบบจะสร้างคีย์ 2 รายการ ดังนี้
| คีย์ 1 (USD) | คีย์ 2 (¥) | |
|---|---|---|
| ค่าสูงสุดที่รวบรวมได้ | $40,000 | ¥5,000,000 |
| ช่วงมูลค่าการซื้อ | [120 - 40,000] | [15,000 - 5,000,000] |
กลยุทธ์คีย์ B จะมีสัญญาณรบกวนในผลลัพธ์น้อยกว่ากลยุทธ์คีย์ A เนื่องจาก ค่าสกุลเงินไม่ได้กระจายอย่างสม่ำเสมอในสกุลเงินต่างๆ ตัวอย่างเช่น พิจารณาว่าการซื้อที่ระบุเป็น ¥ ซึ่งรวมกับการซื้อที่ระบุเป็น USD จะเปลี่ยนแปลงข้อมูลพื้นฐานและเอาต์พุตที่มีสัญญาณรบกวนที่ได้ผลอย่างไร
กลยุทธ์ที่สำคัญ ค.
ผู้ให้บริการเทคโนโลยีโฆษณาตัดสินใจที่จะสร้างและจัดการคีย์ 4 รายการในลูกค้าโฆษณาทั้งหมด และแยกคีย์ตามสกุลเงิน x อุตสาหกรรมผู้ลงโฆษณา
| คีย์ 1 (USD x ผู้ลงโฆษณาเครื่องประดับระดับไฮเอนด์) |
คีย์ 2 (¥ x ผู้ลงโฆษณาเครื่องประดับระดับไฮเอนด์) |
คีย์ 3 (USD x ผู้ลงโฆษณาที่เป็นผู้ค้าปลีกเสื้อผ้า) |
คีย์ 4 (¥ x ผู้ลงโฆษณาผู้ค้าปลีกเสื้อผ้า) |
|
|---|---|---|---|---|
| ค่าสูงสุดที่รวบรวมได้ | $40,000 | ¥5,000,000 | $500 | ¥65,000 |
| ช่วงมูลค่าการซื้อ | [10,000 - 40,000] | [1,250,000 - 5,000,000] | [120 - 500] | [15,000 - 65,000] |
กลยุทธ์หลัก ค. จะมีสัญญาณรบกวนในผลลัพธ์น้อยกว่ากลยุทธ์หลัก ข. เนื่องจาก มูลค่าการซื้อของผู้ลงโฆษณาไม่ได้กระจายอย่างสม่ำเสมอในกลุ่มผู้ลงโฆษณา ตัวอย่างเช่น การพิจารณาว่าการซื้อเครื่องประดับระดับไฮเอนด์ที่รวมกับการซื้อหมวกเบสบอลจะเปลี่ยนแปลงข้อมูลพื้นฐานและเอาต์พุตที่มีสัญญาณรบกวนที่ได้ผลลัพธ์อย่างไร
พิจารณาสร้างค่ารวมสูงสุดที่ใช้ร่วมกันและค่าตัวคูณมาตราส่วนที่ใช้ร่วมกัน สำหรับความเหมือนกันในผู้ลงโฆษณาหลายรายเพื่อลดสัญญาณรบกวนใน เอาต์พุต เช่น คุณอาจทดสอบกลยุทธ์ต่อไปนี้สำหรับผู้ลงโฆษณา
- 1 กลยุทธ์แยกตามสกุลเงิน (USD, ¥, CAD ฯลฯ)
- กลยุทธ์หนึ่งแยกตามอุตสาหกรรมของผู้ลงโฆษณา (ประกันภัย ยานยนต์ ค้าปลีก ฯลฯ)
- กลยุทธ์หนึ่งที่แยกตามช่วงมูลค่าการซื้อที่คล้ายกัน ([100], [1000], [10000] ฯลฯ)
การสร้างกลยุทธ์หลักๆ โดยอิงตามจุดร่วมของผู้ลงโฆษณาจะช่วยให้จัดการคีย์และ โค้ดที่เกี่ยวข้องได้ง่ายขึ้น และอัตราส่วนสัญญาณต่อสัญญาณรบกวนจะสูงขึ้น ทดสอบกลยุทธ์ต่างๆ กับความเหมือนกันของผู้ลงโฆษณาที่แตกต่างกันเพื่อค้นหาจุดเปลี่ยนในการเพิ่มผลกระทบจากสัญญาณรบกวนเทียบกับการจัดการโค้ด
การจัดการค่าผิดปกติขั้นสูง
ลองพิจารณาสถานการณ์ของผู้ลงโฆษณา 2 รายต่อไปนี้
- ผู้ลงโฆษณา ก:
- ในผลิตภัณฑ์ทั้งหมดในเว็บไซต์ของผู้ลงโฆษณา ก. ราคาซื้อ ที่เป็นไปได้อยู่ระหว่าง [$120 - $1,000] ซึ่งมีช่วงราคา $880
- ราคาซื้อจะกระจายอย่างสม่ำเสมอในช่วง $880 โดยไม่มีค่าผิดปกติที่อยู่นอกค่าเบี่ยงเบนมาตรฐาน 2 ค่าจากราคาซื้อมัธยฐาน
- ผู้ลงโฆษณา B:
- ในผลิตภัณฑ์ทั้งหมดในเว็บไซต์ของผู้ลงโฆษณา B ราคาซื้อ ที่เป็นไปได้อยู่ระหว่าง [$120 - $1,000] ซึ่งมีช่วงราคา $880
- ราคาซื้อส่วนใหญ่จะอยู่ในช่วง ฿3,600 - ฿15,000 โดยมีการซื้อเพียง 5% เท่านั้นที่อยู่ในช่วง ฿15,000 - ฿30,000
เนื่องจากข้อกำหนดด้านงบประมาณการมีส่วนร่วม และวิธีการที่ใช้การสุ่มกับผลลัพธ์สุดท้าย ผู้ลงโฆษณา B จะมีผลลัพธ์ที่มีการสุ่มมากกว่าผู้ลงโฆษณา A โดยค่าเริ่มต้น เนื่องจากผู้ลงโฆษณา B มีโอกาสสูงกว่าที่ค่าผิดปกติจะส่งผลต่อการคำนวณพื้นฐาน
คุณสามารถลดปัญหานี้ได้ด้วยการตั้งค่าคีย์ที่เฉพาะเจาะจง ทดสอบกลยุทธ์หลัก ที่ช่วยจัดการข้อมูลค่าผิดปกติ และกระจายมูลค่าการซื้อให้สม่ำเสมอมากขึ้น ในช่วงการซื้อของคีย์
สำหรับผู้ลงโฆษณา B คุณสามารถสร้างคีย์แยกกัน 2 คีย์เพื่อบันทึกช่วงมูลค่าการซื้อที่แตกต่างกัน 2 ช่วง ในตัวอย่างนี้ เทคโนโลยีโฆษณาสังเกตว่าค่าผิดปกติ ปรากฏเหนือมูลค่าการซื้อ $500 ลองใช้คีย์แยกกัน 2 คีย์สำหรับผู้ลงโฆษณารายนี้
- โครงสร้างคีย์ 1 : คีย์ที่บันทึกเฉพาะการซื้อในช่วง $120 - $500 (ครอบคลุมปริมาณการซื้อทั้งหมดประมาณ 95%)
- โครงสร้างคีย์ 2: คีย์ที่บันทึกเฉพาะการซื้อที่สูงกว่า $500 (ครอบคลุมปริมาณการซื้อทั้งหมดประมาณ 5%)
การใช้กลยุทธ์หลักนี้จะช่วยจัดการสัญญาณรบกวนสำหรับผู้ลงโฆษณา B ได้ดียิ่งขึ้น และช่วยเพิ่มอรรถประโยชน์จากรายงานข้อมูลสรุปให้ผู้ลงโฆษณารายนี้ได้ เมื่อพิจารณาช่วงใหม่ที่เล็กลง คีย์ A และคีย์ B ควรมีการกระจายข้อมูลที่สม่ำเสมอมากขึ้น ในแต่ละคีย์ที่เกี่ยวข้องมากกว่าคีย์เดียวในก่อนหน้านี้ ซึ่งจะส่งผลให้ สัญญาณรบกวนในเอาต์พุตของแต่ละคีย์น้อยกว่าคีย์เดียวในก่อนหน้านี้