
目前,您可以使用匯總服務,透過篩選 ID 以不同頻率處理特定評估資料。現在可以在匯總服務中建立工作時傳遞篩選 ID,如下所示:
POST createJob
Body: {
"job_parameters": {
"output_domain_blob_prefix": "domain/domain.avro",
"output_domain_bucket_name": "<data_bucket>",
"filtering_ids": [1, 3] // IDs to keep in the query
}
}
如要使用這項篩選實作功能,建議從評估用戶端 API (Attribution Reporting API 或 Private Aggregation API) 開始,並傳入篩選 ID。這些篩選條件會傳遞至已部署的匯總服務,因此最終摘要報表會傳回預期的篩選結果。
如果您擔心這會影響預算,請放心,系統只會針對報表job_parameters中指定的篩選 ID,從匯總報表帳戶預算中扣除費用。這樣一來,您就能為相同報表重新執行作業,並指定不同的篩選 ID,不會發生預算用盡錯誤。
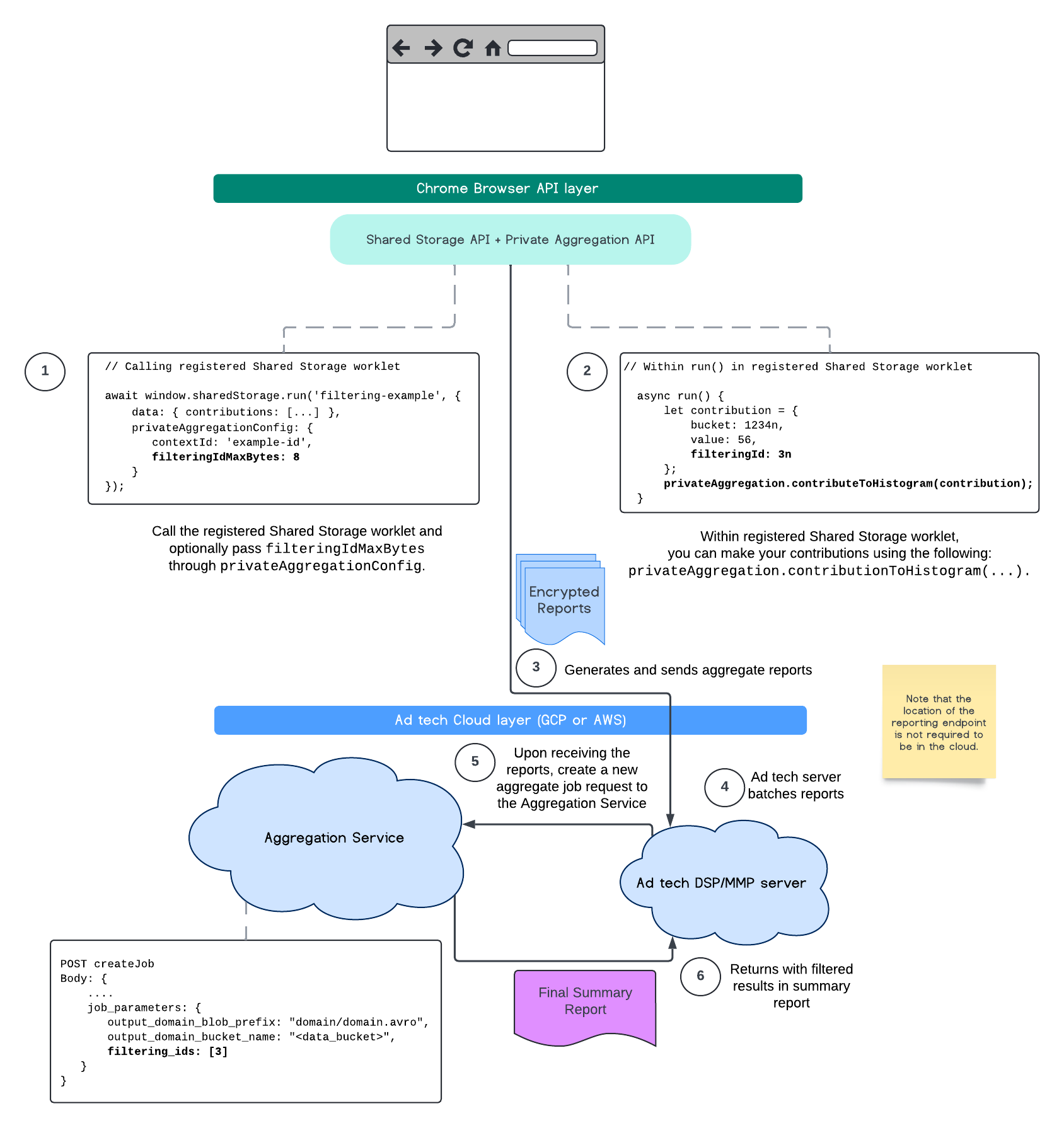
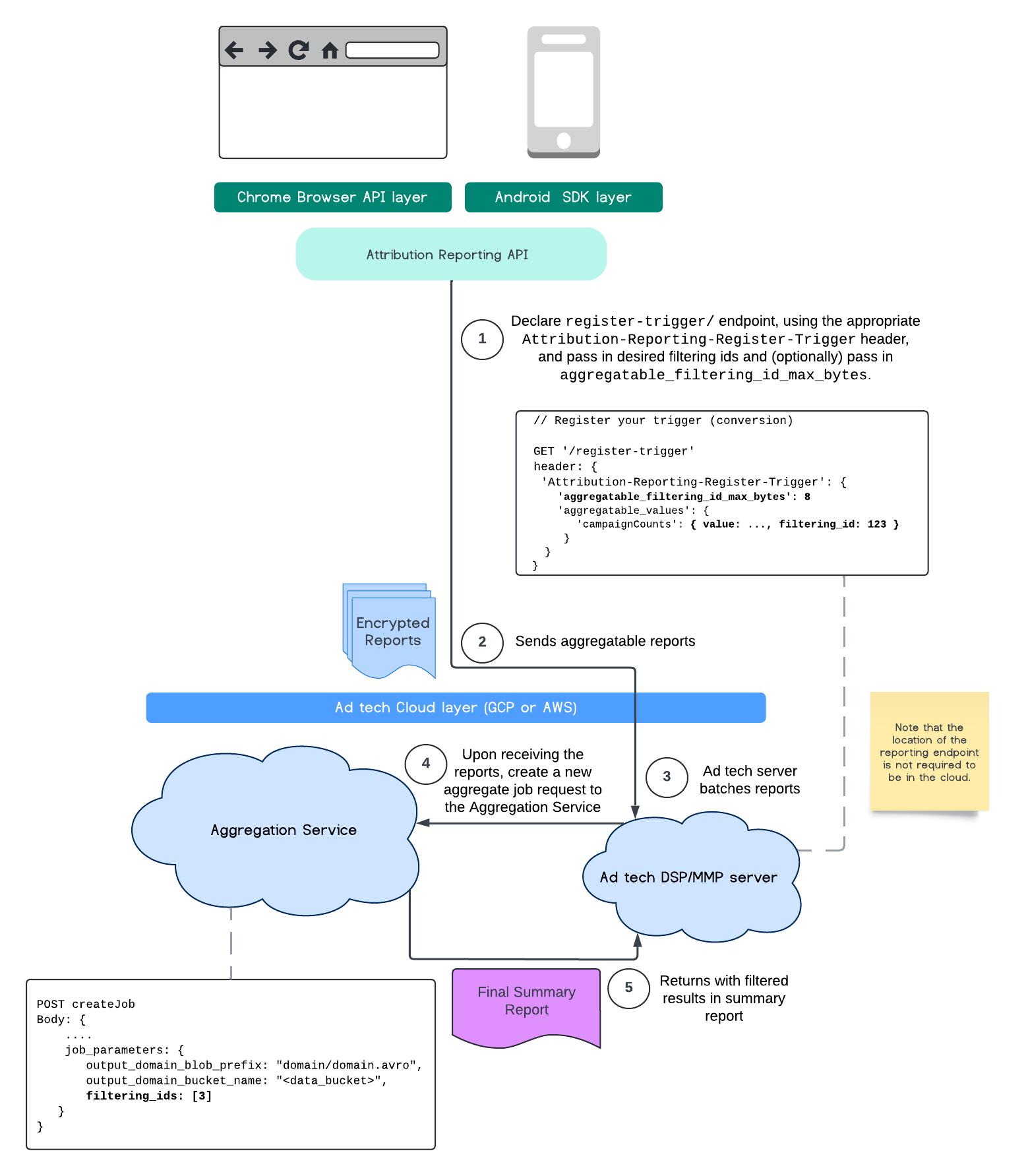
下圖顯示如何在Private Aggregation API、Shared Storage API 和公有雲中的 Aggregation Service 中使用這項功能。
這個流程說明如何透過 Attribution Reporting API 和公有雲中的 Aggregation Service,使用篩選 ID。
如要進一步瞭解,請參閱 Attribution Reporting API 說明和 Private Aggregation API 說明,以及初步提案。
請繼續閱讀「Attribution Reporting API」或「Private Aggregation API」一節,瞭解更詳細的說明。如要進一步瞭解 createJob 和 getJob 端點,請參閱 Aggregation Service API 說明文件。