
成功部署匯總服務後,您可以使用 createJob 和 getJob 端點與服務互動。下圖以視覺化方式呈現這兩個端點的部署架構:
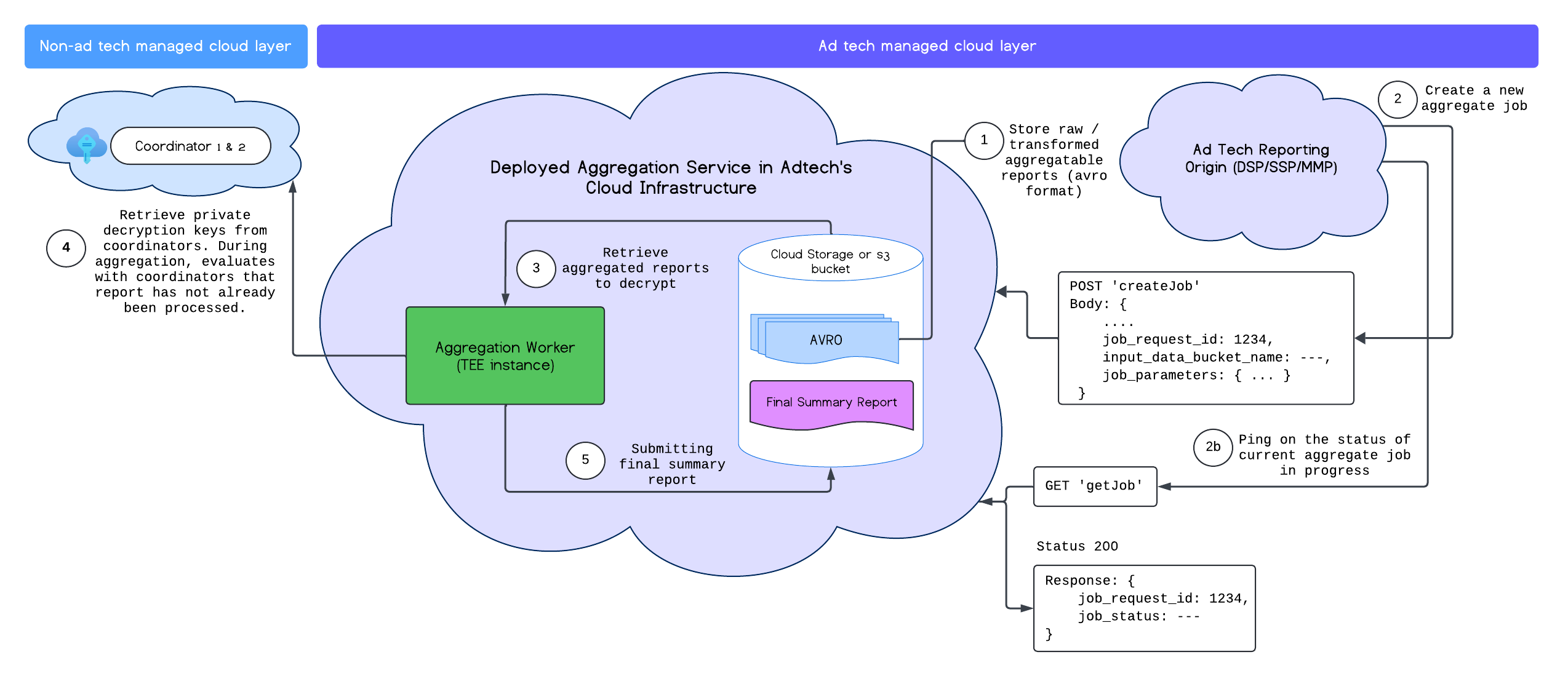
如要進一步瞭解 createJob 和 getJob 端點,請參閱 Aggregation Service API 說明文件。
建立工作
如要建立職缺,請將 POST 要求傳送至 createJob 端點。
bash
POST https://<api-gateway>/stage/v1alpha/createJob
-+
createJob 的要求主體範例:
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<host name of reporting origin>"
}
}
成功建立工作會產生 202 HTTP 狀態碼。
請注意,reporting_site 和 attribution_report_to 互斥,且只需要其中一個。
您也可以在 job_parameters 中加入 debug_run,要求執行偵錯工作。
如要進一步瞭解偵錯模式,請參閱匯總偵錯執行說明文件。
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>"
"debug_run": "true"
}
}
要求欄位
| 參數 | 類型 | 說明 |
|---|---|---|
job_request_id |
字串 |
這是廣告技術產生的專屬 ID,應為 ASCII 字母,且長度不得超過 128 個字元。這會識別批次工作要求,並從廣告技術雲端儲存空間上託管的 `input_data_bucket_name` 中,擷取 `input_data_blob_prefix` 指定的所有可匯總 AVRO 報表。
字元: `a-z, A-Z, 0-9, !"#$%&'()*+,-./:;<=>?@[\]^_`{}~
|
input_data_blob_prefix |
字串 |
這是 bucket 路徑。如果是單一檔案,可以使用路徑。如要上傳多個檔案,可以在路徑中使用前置字元。
範例:這個資料夾/檔案會收集 folder/file1.avro、folder/file/file1.avro 和 folder/file1/test/file2.avro 中的所有報表。 |
input_data_bucket_name |
字串 | 這是輸入資料或可匯總報表的值區。這項資訊位於廣告技術的雲端儲存空間。 |
output_data_blob_prefix |
字串 | 這是值區中的輸出路徑。支援單一輸出檔案。 |
output_data_bucket_name |
字串 |
這是傳送 output_data 的儲存空間值區。這項資訊位於廣告技術的雲端儲存空間。
|
job_parameters |
字典 |
必填。這個欄位包含下列不同欄位:
|
job_parameters.output_domain_blob_prefix |
字串 |
與 input_data_blob_prefix 類似,這是輸出網域 AVRO 所在的 output_domain_bucket_name 路徑。如要上傳多個檔案,可以在路徑中使用前置字元。匯總服務完成批次作業後,就會建立摘要報表,並以 output_data_blob_prefix 名稱放入輸出值區 output_data_bucket_name。 |
job_parameters.output_domain_bucket_name |
字串 | 這是輸出網域 AVRO 檔案的儲存空間值區。這項資訊位於廣告技術的雲端儲存空間。 |
job_parameters.attribution_report_to |
字串 | 這個值與 `reporting_site` 互斥。這是收到報表的報表網址或報表來源。網站來源已在匯總服務新手上路中註冊。 |
job_parameters.reporting_site |
字串 |
與 attribution_report_to 互斥。這是指收到報表的報表網址或報表來源主機名稱。網站來源已在匯總服務新手上路中註冊。
注意:您可以在單一要求中提交多份報表,但前提是所有來源都屬於這個參數中指定的相同報表網站。
|
job_parameters.debug_privacy_epsilon |
浮點數、雙精度浮點數 | 選填欄位。如未傳遞任何值,預設值為 10。可使用 0 到 64 之間的值。 |
job_parameters.report_error_threshold_percentage |
雙人床 | 選填欄位。這是工作失敗前可允許的失敗報表百分比上限。如果留空,預設值為 10%。 |
job_parameters.input_report_count |
長值 |
選填欄位。做為工作輸入資料的報表總數。這個值與 report_error_threshold_percentage 搭配使用時,如果報表因錯誤而遭到排除,工作就會提早失敗。
|
job_parameters.filtering_ids |
字串 |
選填欄位。以半形逗號分隔的未簽署篩選 ID 清單。系統會篩除與篩選 ID 不符的所有貢獻內容。(例如:"filtering_ids": "12345,34455,12")。預設值為 0。
|
job_parameters.debug_run |
布林值 |
選填欄位。執行偵錯時,系統會加入經過和未經過雜訊處理的偵錯摘要報表和註解,指出網域輸入內容和/或報表中出現的鍵。此外,系統也不會強制執行批次間的重複項目。請注意,偵錯執行作業只會考量含有 "debug_mode": "enabled" 旗標的報表。從 v2.10.0 開始,偵錯執行不會耗用隱私權預算。
|
取得工作
廣告技術想瞭解所要求批次的狀態時,可以呼叫 getJob 端點。使用 HTTPS GET 要求和 job_request_id 參數呼叫 getJob 端點。
GET https://<api-gateway>/stage/v1alpha/getJob?job_request_id=<job_request_id>
您應該會收到回應,其中包含工作狀態和任何錯誤訊息:
{
"job_status": "FINISHED",
"request_received_at": "2023-07-17T19:15:13.926530Z",
"request_updated_at": "2023-07-17T19:15:28.614942839Z",
"job_request_id": "PSD_0003",
"input_data_blob_prefix": "reports/output_reports_2023-07-17T19:11:27.315Z.avro",
"input_data_bucket_name": "ags-report-bucket",
"output_data_blob_prefix": "summary/summary.avro",
"output_data_bucket_name": "ags-report-bucket",
"postback_URL": "",
"result_info": {
"return_code": "SUCCESS",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-07-17T19:15:28.607802354Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "ags-report-bucket",
"output_domain_blob_prefix": "output_domain/output_domain.avro",
"attribution_report_to": "https://privacy-sandcastle-dev-dsp.web.app"
},
"request_processing_started_at": "2023-07-17T19:15:21.583759622Z"
}
回覆欄位
| 參數 | 類型 | 說明 |
|---|---|---|
job_request_id |
字串 |
這是 createJob 要求中指定的專屬工作/批次 ID。
|
job_status |
字串 | 這是工作要求的狀態。 |
request_received_at |
字串 | 收到要求的時間。 |
request_updated_at |
字串 | 上次更新工作的時間。 |
input_data_blob_prefix |
字串 |
這是 createJob 中設定的輸入資料前置字串。
|
input_data_bucket_name |
字串 |
這是廣告技術的輸入資料 bucket,可匯總報表會儲存在這裡。這個欄位是在 createJob 設定。
|
output_data_blob_prefix |
字串 |
這是 createJob 中設定的輸出資料前置字串。
|
output_data_bucket_name |
字串 |
這是廣告技術的輸出資料值區,用於儲存產生的摘要報表。這個欄位是在 createJob 設定。
|
request_processing_started_at |
字串 |
上次嘗試處理作業的開始時間。但不包括在工作佇列中等待的時間。
(總處理時間 = request_updated_at - request_processing_started_at)
|
result_info |
字典 |
這是 createJob 要求的回覆,包含所有可用的資訊。
這會顯示 return_code、return_message、finished_at 和 error_summary 值。
|
result_info.return_code |
字串 | 工作結果回傳代碼。如果匯總服務發生問題,我們需要這項資訊來進行疑難排解。 |
result_info.return_message |
字串 | 作業傳回的成功或失敗訊息。此外,這項資訊也是排解匯總服務問題的必要條件。 |
result_info.error_summary |
字典 | 工作傳回的錯誤。這份報表會列出報表數量,以及遇到的錯誤類型。 |
result_info.finished_at |
時間戳記 | 表示工作完成的時間戳記。 |
result_info.error_summary.error_counts |
清單 |
這會傳回錯誤訊息清單,以及因相同錯誤訊息而失敗的報表數量。每個錯誤計數都包含類別、error_count 和 description。
|
result_info.error_summary.error_messages |
清單 | 這會傳回處理失敗的報表錯誤訊息清單。 |
job_parameters |
字典 |
其中包含 createJob 要求中提供的工作參數。相關屬性,例如 `output_domain_blob_prefix` 和 `output_domain_bucket_name`。
|
job_parameters.attribution_report_to |
字串 |
與 reporting_site 互斥。這是指報表網址或收到報表的來源。來源是註冊於匯總服務新手上路的網站一部分。這是 createJob 要求中指定的項目。
|
job_parameters.reporting_site |
字串 |
與 attribution_report_to 互斥。這是報表網址的主機名稱,或是收到報表的來源。來源是註冊於匯總服務新手上路的網站一部分。請注意,只要所有回報來源都屬於這個參數中提及的同一網站,您就可以在同一個要求中提交含有多個回報來源的報表。這是 createJob 要求中指定的項目。此外,請確認在建立工作時,儲存區只包含要匯總的報表。系統會處理新增至輸入資料 bucket 的所有報表,前提是報表來源與作業參數中指定的報表網站相符。
匯總服務只會考量資料 bucket 中與工作已註冊的報表來源相符的報表。舉例來說,如果註冊的來源是 https://exampleabc.com,即使 bucket 包含來自子網域 (https://1.exampleabc.com 等) 或完全不同網域 (https://3.examplexyz.com) 的報表,系統也只會納入來自 https://exampleabc.com 的報表。
|
job_parameters.debug_privacy_epsilon |
浮點數、雙精度浮點數 |
選填欄位。如未傳遞任何值,系統會使用預設值 10。值可介於 0 到 64 之間。這個值是在 createJob 要求中指定。
|
job_parameters.report_error_threshold_percentage |
雙人床 |
選填欄位。這是工作失敗前可失敗的報告百分比閾值。如未指派任何值,系統會使用預設值 10%。這是 createJob 要求中指定的項目。
|
job_parameters.input_report_count |
長值 | 選填欄位。這項工作輸入資料的報表總數。如果因錯誤而排除大量報表,`report_error_threshold_percentage` 會與這個值一併觸發提早結束工作。這項設定是在 `createJob` 要求中指定。 |
job_parameters.filtering_ids |
字串 |
選填欄位。以半形逗號分隔的未簽署篩選 ID 清單。系統會篩除符合篩選 ID 以外的所有貢獻內容。這是 createJob 要求中指定的項目。
(例如 "filtering_ids":"12345,34455,12"。預設值為「0」)。
|