
Private Aggregation API के मुख्य सिद्धांत
यह दस्तावेज़ किसके लिए है?
Private Aggregation API, अलग-अलग साइटों से मिले डेटा को ऐक्सेस करने वाले वर्कलेट से एग्रीगेट किया गया डेटा इकट्ठा करने की सुविधा देता है. यहां शेयर किए गए कॉन्सेप्ट, उन डेवलपर के लिए ज़रूरी हैं जो Shared Storage और Protected Audience API में रिपोर्टिंग फ़ंक्शन बनाते हैं.
- अगर आप डेवलपर हैं और आपको अलग-अलग साइट पर मेज़रमेंट के लिए रिपोर्टिंग सिस्टम बनाना है.
- अगर आप मार्केटर, डेटा साइंटिस्ट या खास जानकारी वाली रिपोर्ट का इस्तेमाल करने वाले व्यक्ति हैं, तो इन तरीकों को समझने से आपको खास जानकारी वाली बेहतर रिपोर्ट पाने के लिए, डिज़ाइन से जुड़े फ़ैसले लेने में मदद मिलेगी.
मुख्य शब्द
इस दस्तावेज़ को पढ़ने से पहले, मुख्य शब्दों और कॉन्सेप्ट के बारे में जान लें. इनमें से हर शब्द के बारे में यहां विस्तार से बताया जाएगा.
- एग्रीगेशन की (इसे बकेट भी कहा जाता है) डेटा पॉइंट का पहले से तय किया गया कलेक्शन होता है. उदाहरण के लिए, आपको जगह की जानकारी का ऐसा डेटा इकट्ठा करना पड़ सकता है जिसमें ब्राउज़र, देश का नाम रिपोर्ट करता हो. एग्रीगेशन कुंजी में एक से ज़्यादा डाइमेंशन हो सकते हैं. उदाहरण के लिए, देश और आपके कॉन्टेंट विजेट का आईडी.
- एग्रीगेट की जा सकने वाली वैल्यू, एक ऐसा अलग डेटा पॉइंट होता है जिसे एग्रीगेशन की के तौर पर इकट्ठा किया जाता है. अगर आपको यह मेज़र करना है कि फ़्रांस के कितने उपयोगकर्ताओं ने आपका कॉन्टेंट देखा है, तो
Franceएग्रीगेशन कुंजी में एक डाइमेंशन है. साथ ही,1काviewCountएग्रीगेट की जा सकने वाली वैल्यू है. - एग्रीगेट की जा सकने वाली रिपोर्ट, ब्राउज़र में जनरेट और एन्क्रिप्ट की जाती हैं. Private Aggregation API के लिए, इसमें किसी एक इवेंट का डेटा होता है.
- Aggregation Service, एग्रीगेट की जा सकने वाली रिपोर्ट से मिले डेटा को प्रोसेस करके खास जानकारी वाली रिपोर्ट बनाती है.
- खास जानकारी वाली रिपोर्ट, एग्रीगेशन सेवा का फ़ाइनल आउटपुट होती है. इसमें, नॉइज़ी एग्रीगेट किया गया उपयोगकर्ता डेटा और कन्वर्ज़न का ज़्यादा जानकारी वाला डेटा शामिल होता है.
- वर्कलेट, इन्फ़्रास्ट्रक्चर का एक हिस्सा होता है. इसकी मदद से, JavaScript के कुछ खास फ़ंक्शन चलाए जा सकते हैं. साथ ही, अनुरोध करने वाले व्यक्ति को जानकारी वापस भेजी जा सकती है. वर्कलेट में, JavaScript को लागू किया जा सकता है. हालांकि, बाहरी पेज से इंटरैक्ट या कम्यूनिकेट नहीं किया जा सकता.
Private Aggregation का वर्कफ़्लो
जब एग्रीगेशन की और एग्रीगेट की जा सकने वाली वैल्यू के साथ Private Aggregation API को कॉल किया जाता है, तो ब्राउज़र एग्रीगेट की जा सकने वाली रिपोर्ट जनरेट करता है. ये रिपोर्ट, आपके सर्वर को भेजी जाती हैं. यह सर्वर, रिपोर्ट को बैच में भेजता है. बैच की गई रिपोर्ट को बाद में एग्रीगेशन सेवा प्रोसेस करती है. इसके बाद, खास जानकारी वाली रिपोर्ट जनरेट की जाती है.
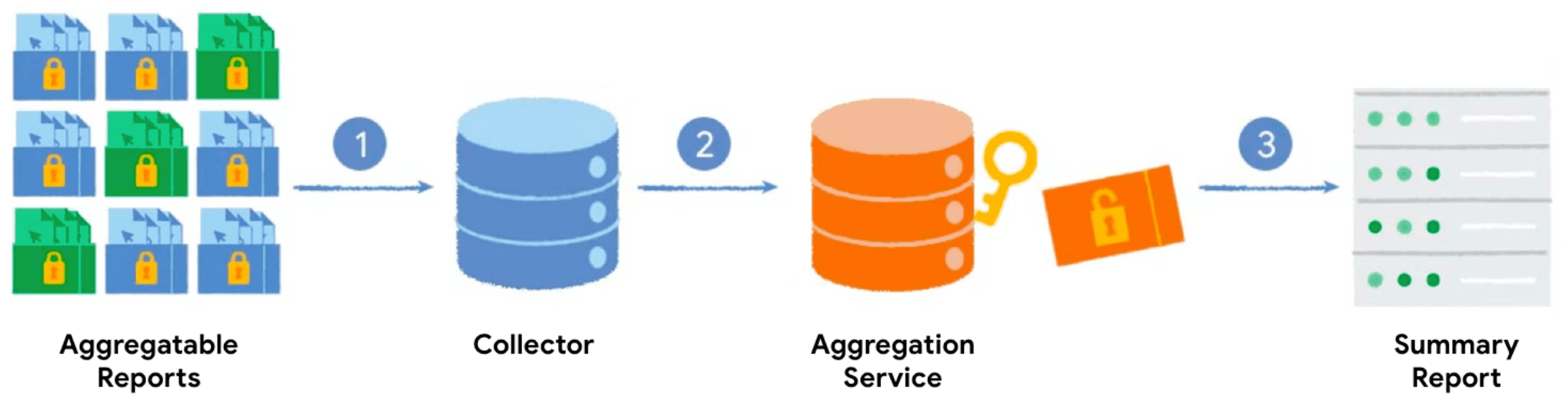
- Private Aggregation API को कॉल करने पर, क्लाइंट (ब्राउज़र) एग्रीगेट की जा सकने वाली रिपोर्ट जनरेट करता है. इसके बाद, वह इसे इकट्ठा करने के लिए आपके सर्वर को भेजता है.
- आपका सर्वर, क्लाइंट से रिपोर्ट इकट्ठा करता है और उन्हें बैच में रखता है, ताकि उन्हें एग्रीगेशन सेवा को भेजा जा सके.
- जब आपके पास ज़रूरत के मुताबिक रिपोर्ट इकट्ठा हो जाती हैं, तो आपको उन्हें बैच में रखना होगा. इसके बाद, आपको उन्हें एग्रीगेशन सेवा को भेजना होगा. यह सेवा, भरोसेमंद एक्ज़ीक्यूशन एनवायरमेंट में काम करती है. इससे आपको खास जानकारी वाली रिपोर्ट जनरेट करने में मदद मिलेगी.
इस सेक्शन में बताया गया वर्कफ़्लो, Attribution Reporting API जैसा ही है. हालांकि, एट्रिब्यूशन रिपोर्टिंग, इंप्रेशन इवेंट और कन्वर्ज़न इवेंट से इकट्ठा किए गए डेटा को जोड़ती है. ये दोनों इवेंट अलग-अलग समय पर होते हैं. प्राइवेट एग्रीगेशन, एक ही क्रॉस-साइट इवेंट को मेज़र करता है.
एग्रीगेशन की
एग्रीगेशन की ("key" के तौर पर भी जानी जाती है) उस बकेट को दिखाती है जहां एग्रीगेट की जा सकने वाली वैल्यू इकट्ठा की जाएंगी. एक या उससे ज़्यादा डाइमेंशन को कुंजी में कोड में बदला जा सकता है. डाइमेंशन, किसी ऐसे पहलू को दिखाता है जिसके बारे में आपको ज़्यादा जानकारी चाहिए. जैसे, उपयोगकर्ताओं का उम्र ग्रुप या किसी विज्ञापन कैंपेन के इंप्रेशन की संख्या.
उदाहरण के लिए, आपके पास ऐसा विजेट हो सकता है जिसे कई साइटों पर एम्बेड किया गया हो. साथ ही, आपको यह जानना हो कि किन देशों के उपयोगकर्ताओं ने आपका विजेट देखा है. आपको "मेरे विजेट को देखने वाले उपयोगकर्ताओं में से, X देश के कितने उपयोगकर्ता हैं?" जैसे सवालों के जवाब चाहिए. इस सवाल की रिपोर्ट बनाने के लिए, एग्रीगेशन कुंजी सेट अप की जा सकती है. यह कुंजी, दो डाइमेंशन को कोड में बदलती है: विजेट आईडी और देश का आईडी.
Private Aggregation API को दिया गया मुख्य डेटा, BigInt होता है. इसमें कई डाइमेंशन शामिल होते हैं. इस उदाहरण में, डाइमेंशन के तौर पर विजेट आईडी और देश का आईडी इस्तेमाल किया गया है. मान लें कि विजेट आईडी चार अंकों का हो सकता है, जैसे कि 1234. साथ ही, हर देश को वर्णमाला के क्रम में किसी संख्या से मैप किया जाता है. जैसे, अफ़गानिस्तान को 1, फ़्रांस को 61, और ज़िंबाब्वे को 195.
इसलिए, एग्रीगेट की जा सकने वाली कुंजी सात अंकों की होगी. इसमें पहले चार वर्ण WidgetID के लिए और आखिरी तीन वर्ण CountryID के लिए रिज़र्व किए गए हैं.
मान लें कि कुंजी, फ़्रांस (देश का आईडी 061) के उन उपयोगकर्ताओं की संख्या को दिखाती है जिन्होंने विजेट आईडी 3276 देखा है. एग्रीगेशन कुंजी 3276061 है.
| एग्रीगेशन की | |
| विजेट आईडी | देश का आईडी |
| 3276 | 061 |
एग्रीगेशन कुंजी को हैशिंग मेकेनिज़्म की मदद से भी जनरेट किया जा सकता है. जैसे, SHA-256. उदाहरण के लिए, स्ट्रिंग {"WidgetId":3276,"CountryID":67} को हैश किया जा सकता है. इसके बाद, इसे 42943797454801331377966796057547478208888578253058197330928948081739249096287n की BigInt वैल्यू में बदला जा सकता है.
अगर हैश वैल्यू 128 बिट से ज़्यादा है, तो इसे छोटा किया जा सकता है. इससे यह पक्का किया जा सकेगा कि यह 2^128−1 की तय सीमा से ज़्यादा न हो.
शेयर किए गए स्टोरेज वर्कलेट में, crypto और TextEncoder मॉड्यूल को ऐक्सेस किया जा सकता है. ये मॉड्यूल, हैश जनरेट करने में आपकी मदद कर सकते हैं. हैश जनरेट करने के बारे में ज़्यादा जानने के लिए, MDN पर SubtleCrypto.digest() देखें.
इस उदाहरण में, हैश की गई वैल्यू से बकेट कुंजी जनरेट करने का तरीका बताया गया है:
async function convertToBucket(data) {
// Encode as UTF-8 Uint8Array
const encodedData = new TextEncoder().encode(data);
// Generate SHA-256 hash
const hashBuffer = await crypto.subtle.digest('SHA-256', encodedData);
// Truncate the hash
const truncatedHash = Array.from(new Uint8Array(hashBuffer, 0, 16));
// Convert the byte sequence to a decimal
return truncatedHash.reduce((acc, curr) => acc * 256n + BigInt(curr), 0n);
}
const data = {
WidgetId: 3276,
CountryID: 67
};
const dataString = JSON.stringify(data);
const bucket = await convertToBucket(dataString);
console.log(bucket); // 126200478277438733997751102134640640264n
एग्रीगेट की जा सकने वाली वैल्यू
कई उपयोगकर्ताओं के लिए, हर कुंजी के हिसाब से एग्रीगेट की जा सकने वाली वैल्यू को जोड़ा जाता है. इससे खास जानकारी वाली रिपोर्ट में, खास जानकारी वाली वैल्यू के तौर पर एग्रीगेट की गई अहम जानकारी जनरेट होती है.
अब, उस उदाहरण वाले सवाल पर वापस जाएं जो पहले पूछा गया था: "मेरे विजेट को देखने वाले उपयोगकर्ताओं में से कितने लोग फ़्रांस से हैं?" इस सवाल का जवाब कुछ इस तरह दिखेगा: "मेरे विजेट आईडी 3276 को देखने वाले करीब 4,881 उपयोगकर्ता फ़्रांस से हैं." हर उपयोगकर्ता के लिए जोड़ी जा सकने वाली वैल्यू 1 है. साथ ही, "4,881 उपयोगकर्ता" जोड़ी गई वैल्यू है. यह उस एग्रीगेशन कुंजी के लिए, सभी जोड़ी जा सकने वाली वैल्यू का योग है.
| एग्रीगेशन की | एग्रीगेट की जा सकने वाली वैल्यू | |
| विजेट आईडी | देश का आईडी | देखे जाने की संख्या |
| 3276 | 061 | 1 |
इस उदाहरण में, हम विजेट देखने वाले हर उपयोगकर्ता के लिए वैल्यू को 1 से बढ़ाते हैं. असल में, एग्रीगेट की जा सकने वाली वैल्यू को स्केल किया जा सकता है, ताकि सिग्नल-टू-नॉइज़ रेशियो को बेहतर बनाया जा सके.
योगदान का बजट
Private Aggregation API को की गई हर कॉल को योगदान कहा जाता है. उपयोगकर्ता की निजता को सुरक्षित रखने के लिए, किसी व्यक्ति से इकट्ठा किए जा सकने वाले योगदान की संख्या सीमित होती है.
सभी एग्रीगेशन कुंजियों के लिए, एग्रीगेट की जा सकने वाली सभी वैल्यू का योग, कॉन्ट्रिब्यूशन बजट से कम होना चाहिए. बजट को हर वर्कलेट ऑरिजिन और हर दिन के हिसाब से तय किया जाता है. साथ ही, यह Protected Audience API और Shared Storage के वर्कलेट के लिए अलग-अलग होता है. दिन के लिए, पिछले 24 घंटों के डेटा का इस्तेमाल किया जाता है. अगर नई एग्रीगेट की जा सकने वाली रिपोर्ट से बजट से ज़्यादा खर्च हो जाता है, तो रिपोर्ट नहीं बनाई जाती है.
योगदान बजट को L1 पैरामीटर से दिखाया जाता है. इसे हर दिन, हर दस मिनट में 216 (65,536) पर सेट किया जाता है. साथ ही, इसकी बैकस्टॉप वैल्यू 220 (1,048,576) होती है. इन पैरामीटर के बारे में ज़्यादा जानने के लिए, एक्सप्लेनर देखें.
योगदान बजट की वैल्यू मनमाने ढंग से तय की जाती है, लेकिन नॉइज़ को इसके हिसाब से स्केल किया जाता है. इस बजट का इस्तेमाल, खास जानकारी की वैल्यू पर सिग्नल-टू-नॉइज़ रेशियो को बढ़ाने के लिए किया जा सकता है. इसके बारे में नॉइज़ और स्केलिंग सेक्शन में ज़्यादा जानकारी दी गई है.
योगदान के बजट के बारे में ज़्यादा जानने के लिए, एक्सप्लेनर देखें. ज़्यादा जानकारी के लिए, योगदान का बजट देखें.
हर रिपोर्ट के लिए योगदान की सीमा
कॉल करने वाले के हिसाब से, योगदान की सीमा अलग-अलग हो सकती है. साथ ही, Shared Storage के लिए ये सीमाएं डिफ़ॉल्ट होती हैं. इन्हें बदला जा सकता है. फ़िलहाल, Shared Storage API का इस्तेमाल करने वालों के लिए जनरेट की गई रिपोर्ट में, हर रिपोर्ट के लिए 20 कॉन्ट्रिब्यूशन की सीमा तय की गई है. दूसरी ओर, Protected Audience API के कॉल करने वालों के लिए, हर रिपोर्ट में 100 योगदान की सीमा तय की गई है. इन सीमाओं को इसलिए चुना गया है, ताकि पेलोड के साइज़ के साथ-साथ एम्बेड किए जा सकने वाले योगदानों की संख्या को भी बैलेंस किया जा सके.
शेयर किए गए स्टोरेज के लिए, एक ही run() या selectURL() ऑपरेशन में किए गए योगदान को एक रिपोर्ट में बैच किया जाता है. Protected Audience API के लिए, नीलामी में एक ही ऑरिजिन से किए गए योगदान को एक साथ बैच किया जाता है.
पैडिंग के साथ योगदान
पैडिंग की सुविधा का इस्तेमाल करके, योगदानों में और बदलाव किए जाते हैं. पेलोड में अतिरिक्त डेटा जोड़ने से, एग्रीगेट की जा सकने वाली रिपोर्ट में शामिल किए गए योगदान की सही संख्या के बारे में जानकारी सुरक्षित रहती है. पैडिंग की मदद से, पेलोड में null कॉन्ट्रिब्यूशन (यानी कि वैल्यू 0 के साथ) जोड़े जाते हैं, ताकि पेलोड की लंबाई तय की जा सके.
एग्रीगेट की जा सकने वाली रिपोर्ट
जब उपयोगकर्ता Private Aggregation API को चालू करता है, तो ब्राउज़र ऐसी रिपोर्ट जनरेट करता है जिन्हें एग्रीगेट किया जा सकता है. इन रिपोर्ट को बाद में एग्रीगेशन सेवा प्रोसेस करती है, ताकि खास जानकारी वाली रिपोर्ट जनरेट की जा सकें. एग्रीगेट की जा सकने वाली रिपोर्ट, JSON फ़ॉर्मैट में होती है. इसमें योगदान की एन्क्रिप्ट (सुरक्षित) की गई सूची होती है. हर योगदान एक {aggregation key, aggregatable value} जोड़ी होती है.
एग्रीगेट की जा सकने वाली रिपोर्ट, एक घंटे तक के रैंडम डिले के साथ भेजी जाती हैं.
योगदानों को एन्क्रिप्ट (सुरक्षित) किया जाता है. इन्हें एग्रीगेशन सेवा के बाहर नहीं पढ़ा जा सकता. एग्रीगेशन सेवा, रिपोर्ट को डिक्रिप्ट करती है और खास जानकारी वाली रिपोर्ट जनरेट करती है. ब्राउज़र के लिए एन्क्रिप्शन कुंजी और Aggregation Service के लिए डिक्रिप्शन कुंजी, कोऑर्डिनेटर जारी करता है. यह कुंजी मैनेज करने वाली सेवा के तौर पर काम करता है. कॉर्डीनेटर, सेवा की इमेज के बाइनरी हैश की सूची रखता है. इससे वह यह पुष्टि कर पाता है कि कॉलर को डिक्रिप्शन कुंजी पाने की अनुमति है.
डीबग मोड चालू करके एग्रीगेट की जा सकने वाली रिपोर्ट का उदाहरण:
"aggregation_service_payloads": [
{
"debug_cleartext_payload": "omRkYXRhgaJldmFsdWVEAAAAgGZidWNrZXRQAAAAAAAAAAAAAAAAAAAE0mlvcGVyYXRpb25paGlzdG9ncmFt",
"key_id": "2cc72b6a-b92f-4b78-b929-e3048294f4d6",
"payload": "a9Mk3XxvnfX70FsKrzcLNZPy+00kWYnoXF23ZpNXPz/Htv1KCzl/exzplqVlM/wvXdKUXCCtiGrDEL7BQ6MCbQp1NxbWzdXfdsZHGkZaLS2eF+vXw2UmLFH+BUg/zYMu13CxHtlNSFcZQQTwnCHb"
}
],
"debug_key": "777",
"shared_info": "{\"api\":\"shared-storage\",\"debug_mode\":\"enabled\",\"report_id\":\"5bc74ea5-7656-43da-9d76-5ea3ebb5fca5\",\"reporting_origin\":\"https://localhost:4437\",\"scheduled_report_time\":\"1664907229\",\"version\":\"0.1\"}"
एग्रीगेट की जा सकने वाली रिपोर्ट की जांच, chrome://private-aggregation-internals पेज पर जाकर की जा सकती है:

जांच के लिए, "चुनी गई रिपोर्ट भेजें" बटन का इस्तेमाल करके, रिपोर्ट को सर्वर पर तुरंत भेजा जा सकता है.
इकट्ठा की जा सकने वाली रिपोर्ट इकट्ठा करना और उन्हें बैच में प्रोसेस करना
ब्राउज़र, एग्रीगेट की जा सकने वाली रिपोर्ट को उस वर्कलेट के ऑरिजिन पर भेजता है जिसमें Private Aggregation API को कॉल किया गया है. इसके लिए, यहां दिए गए जाने-माने पाथ का इस्तेमाल किया जाता है:
- Shared Storage के लिए:
/.well-known/private-aggregation/report-shared-storage - Protected Audience के लिए:
/.well-known/private-aggregation/report-protected-audience
इन एंडपॉइंट पर, आपको एक सर्वर चलाना होगा. यह सर्वर, डेटा इकट्ठा करने वाले के तौर पर काम करेगा. यह क्लाइंट से भेजी गई एग्रीगेट की जा सकने वाली रिपोर्ट को स्वीकार करेगा.
इसके बाद, सर्वर को रिपोर्ट को बैच में रखना चाहिए और बैच को एग्रीगेशन सेवा को भेजना चाहिए. एग्रीगेट की जा सकने वाली रिपोर्ट के अनएन्क्रिप्टेड पेलोड में मौजूद जानकारी के आधार पर बैच बनाएं. जैसे, shared_info फ़ील्ड. आदर्श रूप से, हर बैच में 100 या उससे ज़्यादा रिपोर्ट होनी चाहिए.
आपके पास हर दिन या हर हफ़्ते के हिसाब से बैच बनाने का विकल्प होता है. यह रणनीति फ़्लेक्सिबल है. साथ ही, कुछ इवेंट के लिए बैचिंग की रणनीति बदली जा सकती है. जैसे, साल के उन दिनों में जब ज़्यादा इंप्रेशन मिलने की उम्मीद हो. बैच में, एक ही एपीआई वर्शन, रिपोर्टिंग ओरिजिन, और रिपोर्ट शेड्यूल करने के समय की रिपोर्ट शामिल होनी चाहिए.
आईडी फ़िल्टर करें
Private Aggregation API और Aggregation Service, फ़िल्टर करने वाले आईडी का इस्तेमाल करने की अनुमति देती है. इससे, मेज़रमेंट को ज़्यादा बारीकी से प्रोसेस किया जा सकता है. जैसे, बड़ी क्वेरी में नतीजों को प्रोसेस करने के बजाय, हर विज्ञापन कैंपेन के हिसाब से प्रोसेस करना.
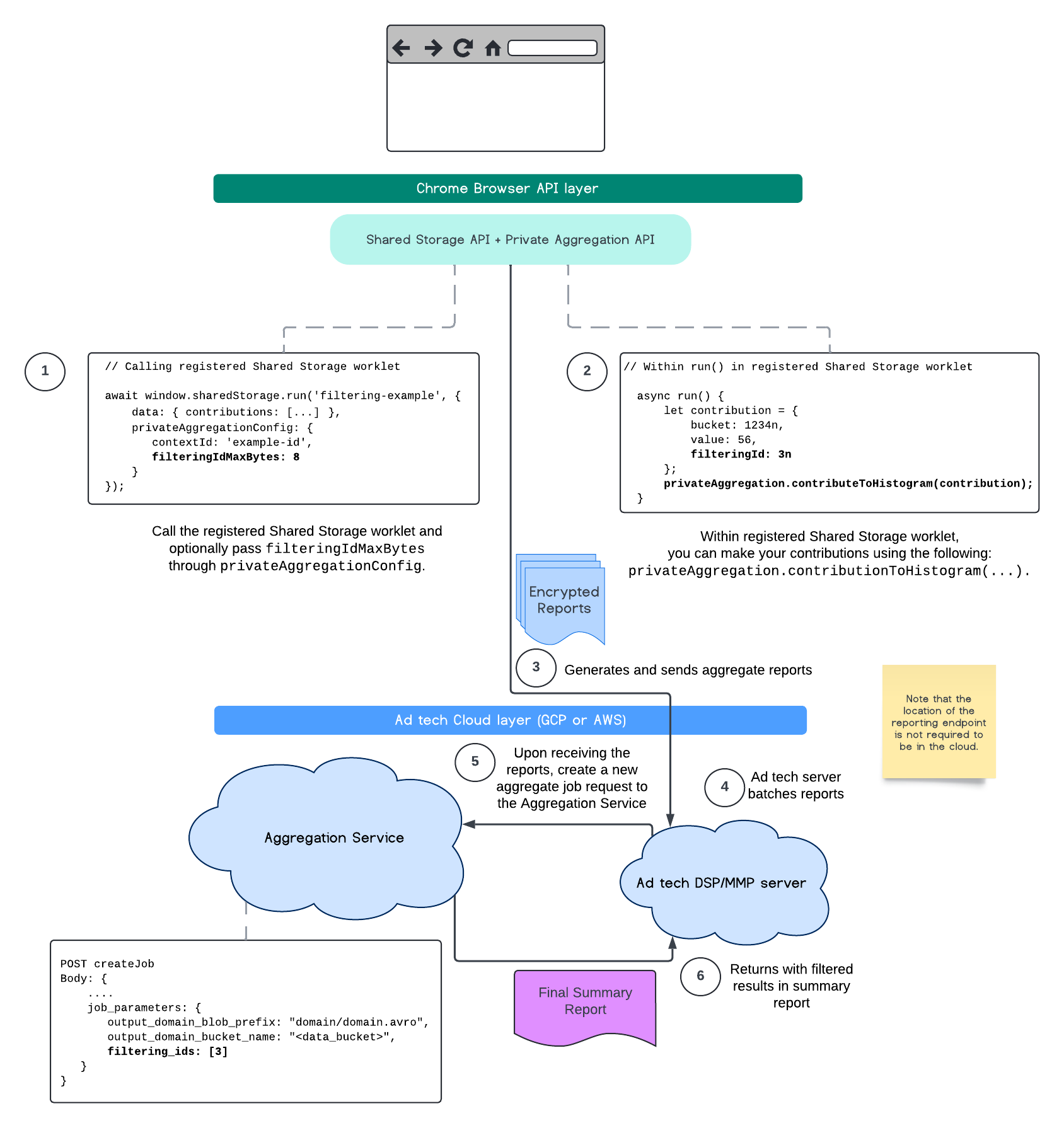
आज ही इसका इस्तेमाल शुरू करने के लिए, यहां कुछ सामान्य चरण दिए गए हैं. इन्हें अपने मौजूदा सेटअप पर लागू करें.
Shared Storage के चरण
अगर आपने अपने फ़्लो में Shared Storage API का इस्तेमाल किया है, तो:
यह तय करें कि आपको शेयर किए गए नए स्टोरेज मॉड्यूल को कहां डिक्लेयर करना है और उसे कहां चलाना है. यहां दिए गए उदाहरण में, हमने मॉड्यूल फ़ाइल का नाम
filtering-worklet.jsरखा है. यहfiltering-exampleके तहत रजिस्टर है.(async function runFilteringIdsExample () { await window.sharedStorage.worklet.addModule('filtering-worklet.js'); await window.sharedStorage.run('filtering-example', { keepAlive: true, privateAggregationConfig: { contextId: 'example-id', filteringIdMaxBytes: 8 // optional } }}); })();ध्यान दें कि
filteringIdMaxBytesको हर रिपोर्ट के हिसाब से कॉन्फ़िगर किया जा सकता है. अगर इसे सेट नहीं किया जाता है, तो यह डिफ़ॉल्ट रूप से 1 पर सेट होता है. इस डिफ़ॉल्ट वैल्यू का इस्तेमाल, पेलोड के साइज़ को ज़रूरत से ज़्यादा बढ़ने से रोकने के लिए किया जाता है. इससे स्टोरेज और प्रोसेसिंग की लागत कम होती है. फ़्लेक्सिबल योगदान के बारे में जानकारी देने वाले लेख में इसके बारे में ज़्यादा पढ़ें.filtering-worklet.jsमें, Shared Storage वर्कलेट मेंprivateAggregation.contributeToHistogram(...)को कॉन्ट्रिब्यूशन पास करते समय, फ़िल्टर करने के लिए आईडी तय किया जा सकता है.// Within filtering-worklet.js class FilterOperation { async run() { let contributions = [{ bucket: 1234n, value: 56, filteringId: 3n // defaults to 0n if not assigned, type bigint }]; for (const c of contributions) { privateAggregation.contributeToHistogram(c); } … } }); register('filtering-example', FilterOperation);एग्रीगेट की जा सकने वाली रिपोर्ट, उस जगह भेजी जाएंगी जहां आपने एंडपॉइंट
/.well-known/private-aggregation/report-shared-storageतय किया है. Aggregation Service के जॉब पैरामीटर में ज़रूरी बदलावों के बारे में जानने के लिए, आईडी फ़िल्टर करने से जुड़ी गाइड पढ़ें.
बैचिंग की प्रोसेस पूरी होने के बाद, इसे डिप्लॉय की गई एग्रीगेशन सेवा को भेज दिया जाता है. इसके बाद, फ़िल्टर किए गए नतीजे आपकी फ़ाइनल खास जानकारी वाली रिपोर्ट में दिखने चाहिए.
Protected Audience API का इस्तेमाल करने का तरीका
अगर आपने अपने फ़्लो में Protected Audience API का इस्तेमाल किया है, तो:
Protected Audience के मौजूदा तरीके को लागू करने के दौरान, Private Aggregation API का इस्तेमाल करने के लिए, यहां दी गई सेटिंग सेट की जा सकती हैं. शेयर किए गए स्टोरेज के उलट, फ़िल्टरिंग आईडी के ज़्यादा से ज़्यादा साइज़ को अभी कॉन्फ़िगर नहीं किया जा सकता. डिफ़ॉल्ट रूप से, फ़िल्टरिंग आईडी का ज़्यादा से ज़्यादा साइज़ 1 बाइट होता है और इसे
0nपर सेट किया जाएगा. ध्यान रखें कि ये Protected Audience की रिपोर्टिंग से जुड़े फ़ंक्शन (जैसे,reportResult()याgenerateBid()) में सेट किए जाएंगे.const contribution = { ... filteringId: 0n }; privateAggregation.contributeToHistogram(contribution);एग्रीगेट की जा सकने वाली रिपोर्ट, उस जगह भेजी जाएंगी जहां आपने एंडपॉइंट
/.well-known/private-aggregation/report-protected-audienceतय किया है. बैचिंग की प्रोसेस पूरी होने के बाद, इसे डिप्लॉय की गई एग्रीगेशन सेवा को भेज दिया जाता है. इसके बाद, फ़िल्टर किए गए नतीजे, आपकी फ़ाइनल खास जानकारी वाली रिपोर्ट में दिखने चाहिए. Attribution Reporting API और Private Aggregation API के बारे में यहां जानकारी दी गई है. साथ ही, शुरुआती प्रस्ताव भी उपलब्ध है.
ज़्यादा जानकारी के लिए, एग्रीगेशन सेवा में आईडी फ़िल्टर करने से जुड़ी गाइड पढ़ें या Attribution Reporting API सेक्शन पर जाएं.
एग्रीगेशन सेवा
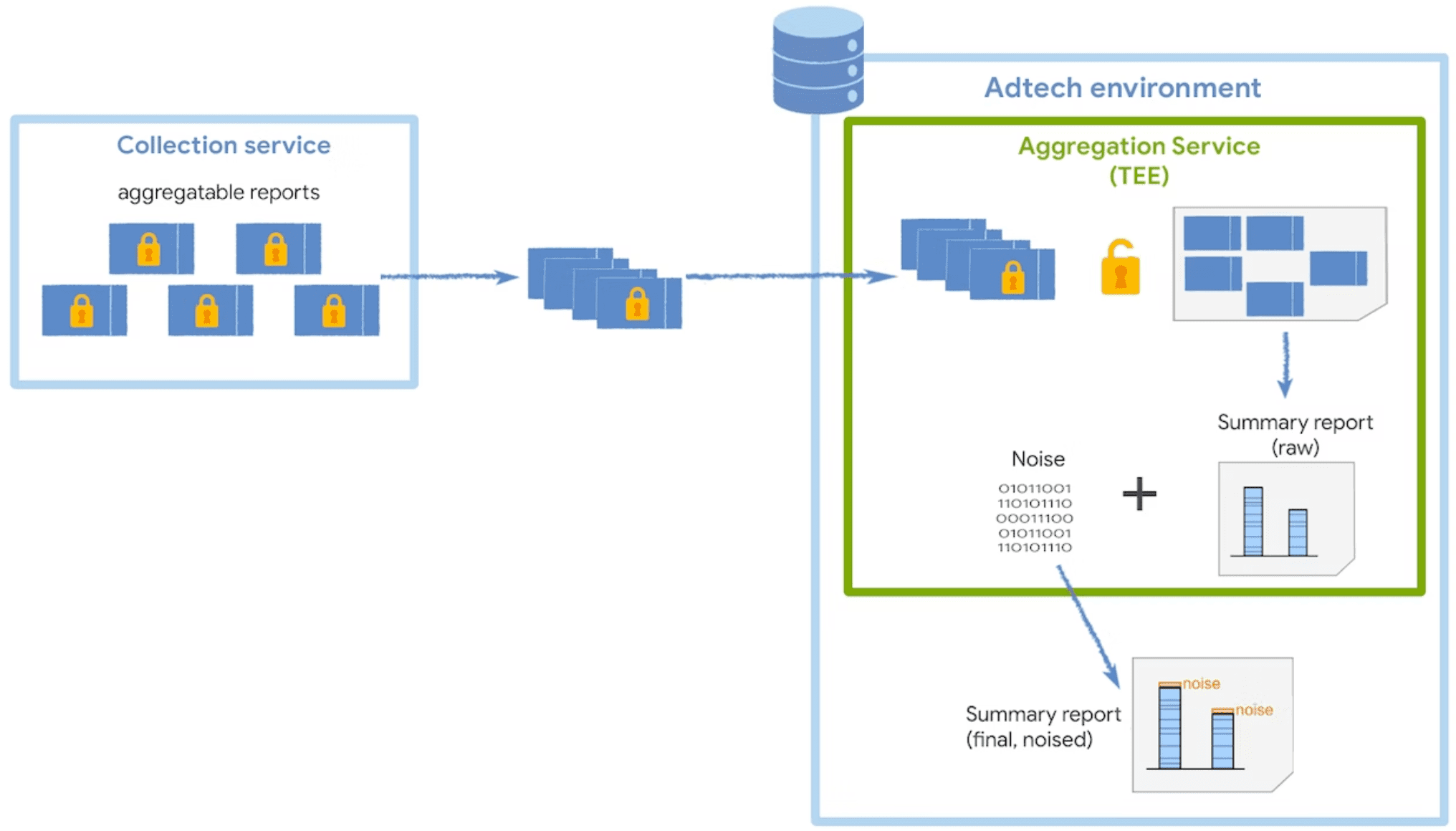
एग्रीगेशन सेवा को कलेक्टर से, एग्रीगेट की जा सकने वाली एन्क्रिप्ट की गई रिपोर्ट मिलती हैं. इसके बाद, यह खास जानकारी वाली रिपोर्ट जनरेट करती है. आपके कलेक्टर में, बैच में एग्रीगेट की जा सकने वाली रिपोर्ट बनाने के बारे में ज़्यादा रणनीतियां जानने के लिए, हमारी बैचिंग गाइड देखें.
यह सेवा, ट्रस्टेड एक्ज़ीक्यूशन एनवायरमेंट (टीईई) में काम करती है. इससे डेटा की अखंडता, डेटा की गोपनीयता, और कोड की अखंडता को लेकर भरोसा मिलता है. अगर आपको यह जानना है कि टीईई के साथ कोऑर्डिनेटर का इस्तेमाल कैसे किया जाता है, तो उनकी भूमिका और मकसद के बारे में ज़्यादा पढ़ें.
खास जानकारी वाली रिपोर्ट
खास जानकारी वाली रिपोर्ट की मदद से, आपको इकट्ठा किया गया डेटा दिखता है. इसमें कुछ नॉइज़ भी शामिल होती है. कुंजियों के किसी सेट के लिए, खास जानकारी वाली रिपोर्ट का अनुरोध किया जा सकता है.
खास जानकारी वाली रिपोर्ट में, की-वैल्यू पेयर का JSON डिक्शनरी स्टाइल वाला सेट होता है. हर पेयर में ये शामिल हैं:
bucket: एग्रीगेशन कुंजी को बाइनरी नंबर स्ट्रिंग के तौर पर दिखाता है. अगर इस्तेमाल की गई एग्रीगेशन कुंजी "123" है, तो बकेट "1111011" है.value: किसी मेज़रमेंट लक्ष्य के लिए खास वैल्यू. यह वैल्यू, एग्रीगेट की जा सकने वाली सभी उपलब्ध रिपोर्ट से जोड़कर निकाली जाती है. इसमें नॉइज़ भी जोड़ा जाता है.
उदाहरण के लिए:
[
{"bucket":` `"111001001",` `"value":` `"2558500"},
{"bucket":` `"111101001",` `"value":` `"3256211"},
{"bucket":` `"111101001",` `"value":` `"6536542"},
]
शोर और स्केल करने की सुविधा
उपयोगकर्ता की निजता को सुरक्षित रखने के लिए, Aggregation Service हर बार खास जानकारी वाली रिपोर्ट का अनुरोध किए जाने पर, हर खास जानकारी वाली वैल्यू में एक बार नॉइज़ जोड़ती है. नॉइज़ वैल्यू को लैप्लस प्रायिकता डिस्ट्रिब्यूशन से रैंडम तरीके से लिया जाता है. नॉइज़ को जोड़ने के तरीकों को सीधे तौर पर कंट्रोल नहीं किया जा सकता. हालांकि, मेज़रमेंट डेटा पर नॉइज़ के असर को कम किया जा सकता है.
सभी एग्रीगेट की जा सकने वाली वैल्यू के योग से कोई फ़र्क़ नहीं पड़ता. नॉइज़ का डिस्ट्रिब्यूशन एक जैसा होता है. इसलिए, एग्रीगेट की जा सकने वाली वैल्यू जितनी ज़्यादा होंगी, नॉइज़ का असर उतना ही कम होगा.
उदाहरण के लिए, मान लें कि नॉइज़ डिस्ट्रिब्यूशन का स्टैंडर्ड डेविएशन 100 है और यह शून्य पर केंद्रित है. अगर एग्रीगेट की जा सकने वाली रिपोर्ट की वैल्यू (या "एग्रीगेट की जा सकने वाली वैल्यू") सिर्फ़ 200 है, तो नॉइज़ का स्टैंडर्ड डेविएशन, एग्रीगेट की गई वैल्यू का 50% होगा. हालांकि, अगर एग्रीगेट की जा सकने वाली वैल्यू 20,000 है, तो नॉइज़ का स्टैंडर्ड डेविएशन, एग्रीगेट की गई वैल्यू का सिर्फ़ 0.5% होगा. इसलिए, 20,000 की एग्रीगेट की जा सकने वाली वैल्यू का सिग्नल-शोर अनुपात बहुत ज़्यादा होगा.
इसलिए, एग्रीगेट की जा सकने वाली वैल्यू को स्केलिंग फ़ैक्टर से गुणा करने पर, नॉइज़ को कम किया जा सकता है. स्केलिंग फ़ैक्टर से पता चलता है कि आपको किसी एग्रीगेट की जा सकने वाली वैल्यू को कितना स्केल करना है.

स्केलिंग फ़ैक्टर को बड़ा करके वैल्यू को स्केल करने से, नॉइज़ कम हो जाता है. हालांकि, इससे सभी बकेट में किए गए सभी योगदानों का कुल योग, योगदान बजट की सीमा तक तेज़ी से पहुंच जाता है. स्केलिंग फ़ैक्टर कॉन्स्टेंट को कम करके वैल्यू को कम करने से, रिलेटिव नॉइज़ बढ़ जाती है. हालांकि, इससे बजट की सीमा तक पहुंचने का जोखिम कम हो जाता है.
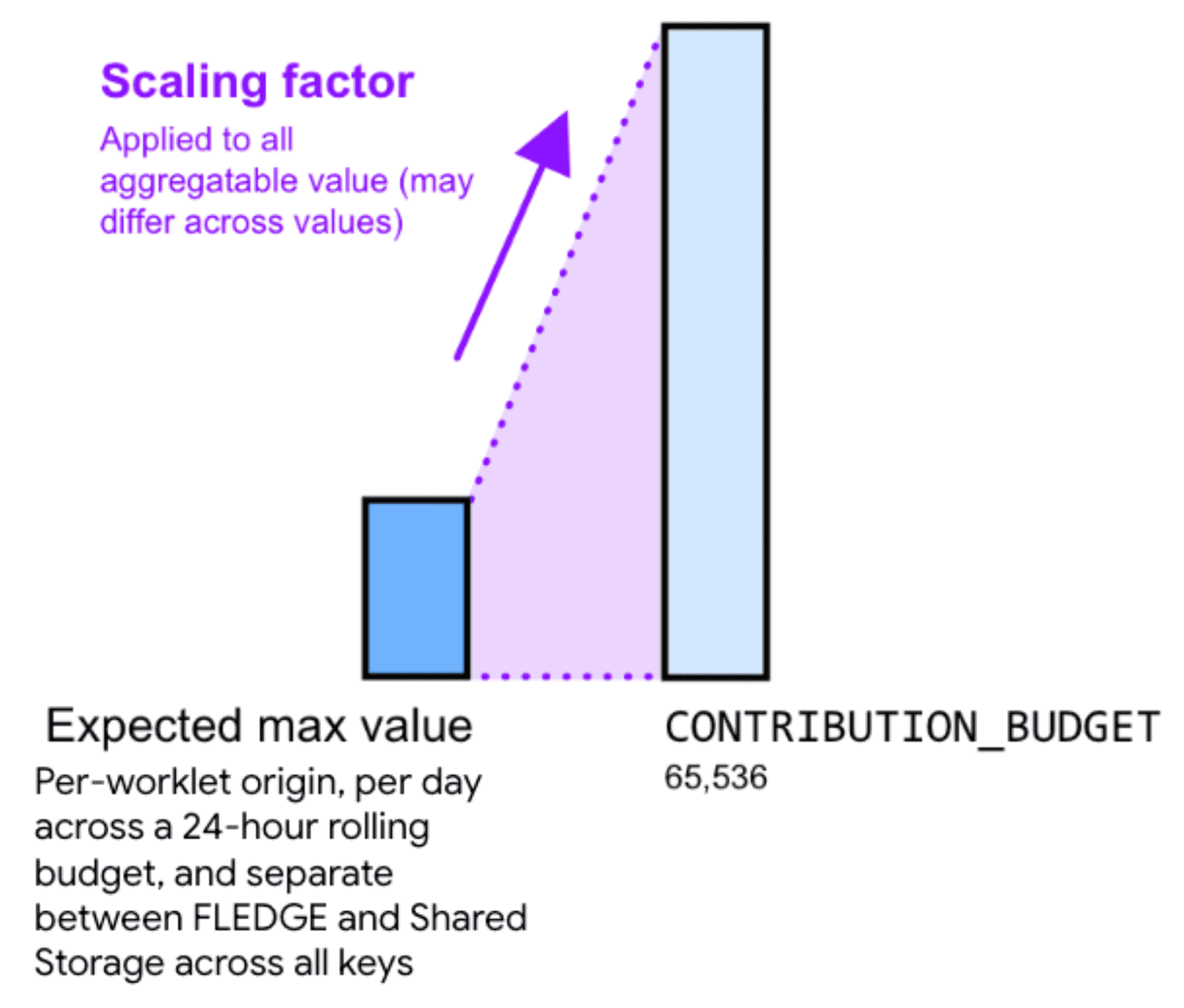
स्केलिंग फ़ैक्टर का सही हिसाब लगाने के लिए, कॉन्ट्रिब्यूशन बजट को सभी कुंजियों के लिए एग्रीगेट की जा सकने वाली वैल्यू के ज़्यादा से ज़्यादा योग से भाग दें.
ज़्यादा जानने के लिए, योगदान बजट के बारे में जानकारी देने वाला दस्तावेज़ पढ़ें.
उपयोग करना और सुझाव/राय देना या शिकायत करना
Private Aggregation API पर फ़िलहाल चर्चा चल रही है. आने वाले समय में, इसमें बदलाव हो सकता है. अगर आपने इस एपीआई को आज़माया है और आपको कोई सुझाव, शिकायत या राय देनी है, तो हमें ज़रूर बताएं.
- GitHub: एक्सप्लेनर पढ़ें, सवाल पूछें और चर्चा में हिस्सा लें.