
關於這份文件
閱讀本文後,您將:
- 請先瞭解要建立哪些策略,再產生摘要報告。
- 瞭解 雜訊研究室,這項工具可協助您掌握各種雜訊參數的影響,並快速探索及評估各種雜訊管理策略。
提供意見
本文僅摘要說明幾項使用摘要報表的原則,可能未涵蓋所有雜訊管理方法。歡迎提出建議、新增內容或提出問題!
- 如要公開回饋有關噪音管理策略、API (epsilon) 的實用性或隱私權,以及分享使用 Noise Lab 模擬時的觀察結果,請:在此問題中留言
- 如要針對 API 的其他方面提供公開意見回饋: 請在這裡建立新問題
事前準備
- 如需簡介,請參閱「歸因報表:摘要報表」和「歸因報表完整系統總覽」。
- 請先掃描「瞭解雜訊」和「瞭解匯總鍵」,以便充分運用本指南。
設計決策
核心設計原則
第三方 Cookie 和摘要報表的運作方式有根本上的差異。主要差異在於摘要報表中的評估資料會加入雜訊。另一種是排定報表。
如要存取訊號雜訊比更高的摘要報表評估資料,需求端平台 (DSP) 和廣告評估服務供應商必須與廣告主合作,制定雜訊管理策略。為制定這些策略,需求端平台和評估服務供應商需要做出設計決策。這些決策都圍繞著一個基本概念:
雖然分布雜訊值絕對來說只取決於兩個參數 (即 epsilon 和貢獻預算),但您仍可使用其他控制項,影響輸出評估資料的訊號雜訊比。
我們認為反覆的過程會引導您做出最佳決策,但這些決策的每個變化都會導致實作略有不同,因此必須在編寫每個程式碼疊代 (以及放送廣告) 之前做出這些決策。
決策:維度精細程度
在 Noise Lab 中試用
- 前往「進階模式」。
- 在「參數」側邊面板中,尋找「您的轉換資料」。
- 觀察預設參數。根據預設,每日可歸因轉換總數為 1000 次。如果使用預設設定 (預設維度、每個維度可能的不同值預設數量、金鑰策略 A),平均每個值區約有 40 個值。請注意,輸入的每個區間平均每日可歸因轉換次數值為 40。
- 按一下「模擬」,使用預設參數執行模擬。
- 在「參數」側邊面板中,尋找「維度」。將「Geography」(地理位置)重新命名為「City」(城市),並將可能出現的不同值數量變更為 50。
- 觀察這項變更對每個區間的平均每日可歸因轉換次數有何影響。現在的價格比之前低很多。這是因為如果您增加這個維度中的可能值數量,但未變更任何其他項目,就會增加總儲存區數量,但每個儲存區中的轉換事件數量不會變更。
- 按一下「模擬」。
- 觀察模擬結果的雜訊比:現在的雜訊比高於先前的模擬。
根據核心設計原則,小型摘要值可能比大型摘要值更雜亂。因此,您的設定選擇會影響每個值區 (又稱為匯總鍵) 中歸因轉換事件的數量,而該數量會影響最終輸出摘要報表中的雜訊。
影響單一區間內歸因轉換事件數量的設計決策之一,就是維度精細程度。請參考以下匯總鍵和維度的範例:
- 方法 1:一個主要結構,搭配粗略的維度:國家/地區 x 廣告活動 (或最大的廣告活動匯總值區) x 產品類型 (10 種可能的產品類型)
- 方法 2:一個具有精細維度的鍵結構:城市 x 廣告素材 ID x 產品 (100 種可能產品)
城市比國家/地區更細緻;廣告素材 ID 比廣告活動更細緻;產品比產品類型更細緻。因此,在摘要報表輸出中,方法 2 的每個值區 (即每個鍵) 事件 (轉換) 數量會比方法 1 少。由於加到輸出內容的雜訊與 bucket 中的事件數量無關,因此使用方法 2 時,摘要報表中的評估資料會更加雜亂。針對每位廣告主,在金鑰設計中嘗試各種細微程度的取捨,盡可能提高結果的實用性。
決策:主要結構
在 Noise Lab 中試用
在「簡單」模式中,系統會使用預設金鑰結構。在「進階」模式中,您可以嘗試不同的索引鍵結構。隨附部分維度範例,您也可以修改這些維度。
- 前往「進階模式」。
- 在「參數」側邊面板中,找出「主要策略」。請注意,工具中名為 A 的預設策略會使用一個精細的鍵結構,其中包含所有維度:地理位置 x 廣告活動 ID x 產品類別。
- 按一下「模擬」。
- 觀察模擬結果的雜訊比。
- 將 Key 策略變更為 B。畫面會顯示其他控制項,供您設定金鑰結構。
- 設定鍵結構,例如:
- 重要結構數量:2
- 主要結構 1 = 地理位置 x 產品類別。
- 主要結構 2 = 廣告活動 ID x 產品類別。
- 按一下「模擬」。
- 請注意,您現在會針對每種評估目標類型取得兩份摘要報表 (兩份是購買次數,兩份是購買價值),因為您使用了兩種不同的索引鍵結構。觀察噪音比率。
- 您也可以使用自己的自訂維度嘗試這項功能。如要這麼做,請尋找要追蹤的資料:維度。建議您移除範例維度,然後使用最後一個維度下方的「新增」、「移除」或「重設」按鈕,自行建立維度。
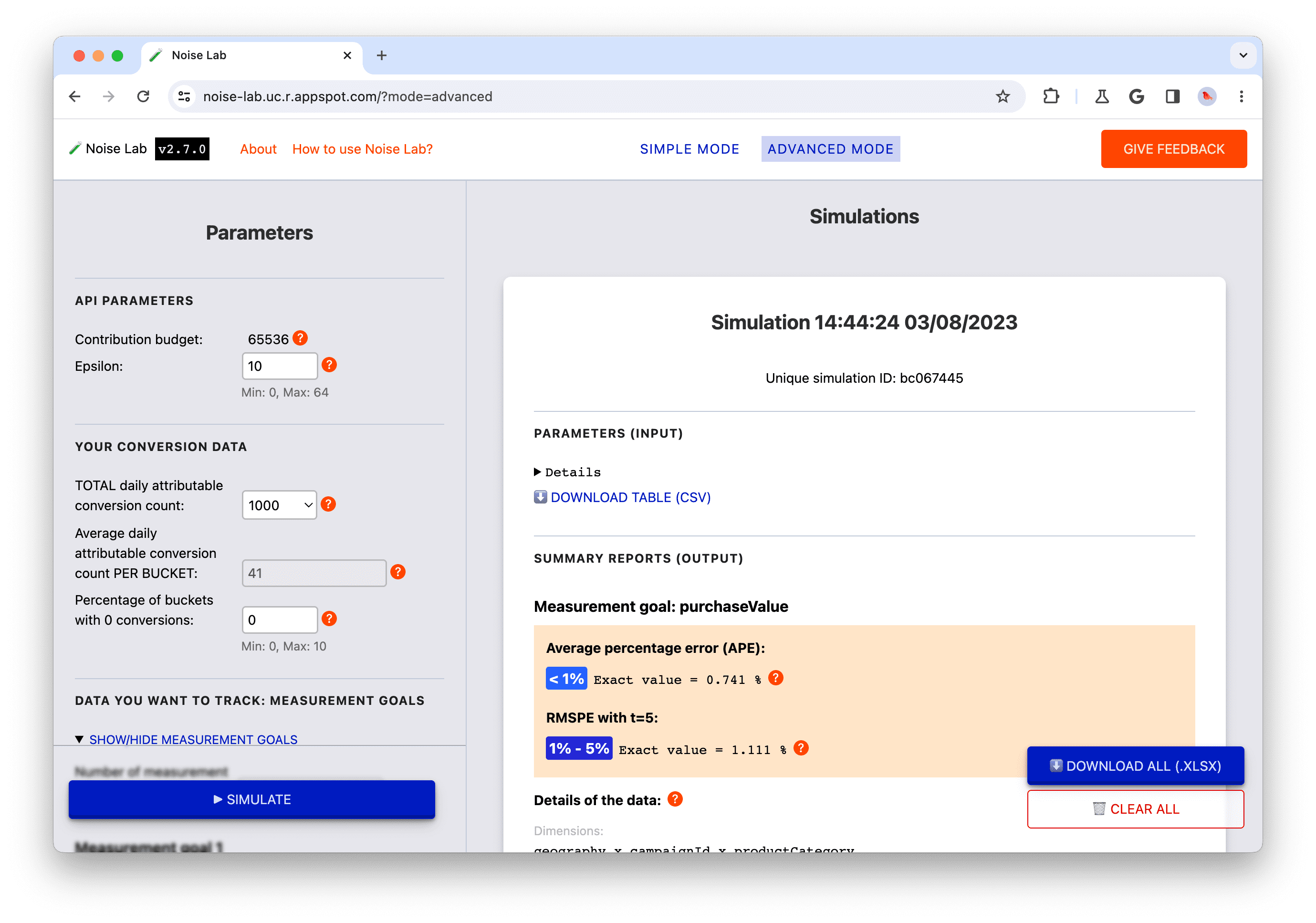
另一個會影響單一值區中歸因轉換事件數量的設計決策,就是您決定使用的金鑰結構。以下是匯總鍵的範例:
- 一個包含所有維度的主要結構,我們稱之為「策略 A」。
- 兩種主要結構,每種結構都包含維度子集;我們將此稱為「主要策略 B」。
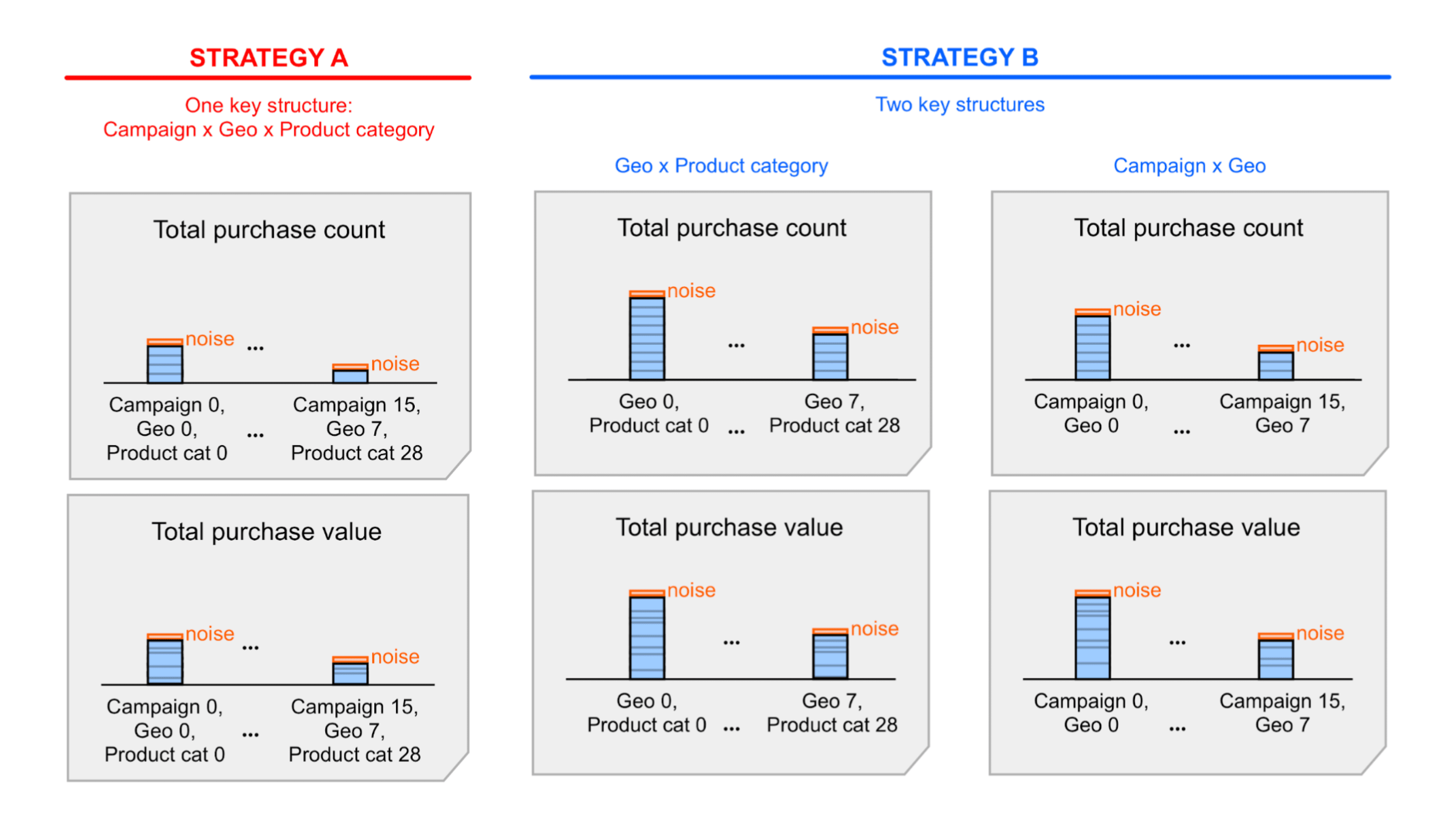
策略 A 較簡單,但您可能需要彙整 (加總) 摘要報表中的雜訊摘要值,才能取得特定洞察資料。加總這些值時,也會加總雜訊。 使用策略 B 時,摘要報表中顯示的摘要值可能已提供您所需的資訊。這表示策略 B 的訊號雜訊比可能優於策略 A。不過,策略 A 的雜訊可能已可接受,因此您可能仍會選擇策略 A,以求簡單。如要進一步瞭解這兩種策略,請參閱詳細範例。
金鑰管理是個深入的主題,您可以考慮採用多種精細技術,提升訊號雜訊比。其中一種方法請參閱「進階金鑰管理」。
決策:批次處理頻率
在 Noise Lab 中試用
- 前往「簡單」模式 (或「進階」模式,這兩種模式在批次處理頻率方面運作方式相同)
- 在「參數」側邊面板中,依序尋找「您的匯總策略」>「批次處理頻率」。這是指在單一工作中,透過匯總服務處理可匯總報表的批次頻率。
- 觀察預設的批次處理頻率:預設會模擬每日批次處理頻率。
- 按一下「模擬」。
- 觀察模擬結果的雜訊比。
- 將批次處理頻率變更為每週。
- 觀察模擬結果的雜訊比:雜訊比現在比先前的模擬結果低 (更好)。
另一個會影響單一值區中歸因轉換事件數量的設計決策,就是您決定使用的批次處理頻率。批次處理頻率是指您處理可匯總報表的頻率。
如果報表的匯總頻率較高 (例如每小時),所含的轉換事件就會比匯總頻率較低的報表 (例如每週) 少。因此,每小時報表會包含更多雜訊。``` 與匯總時間表頻率較低的相同報表 (例如每週) 相比,每小時報表包含的轉換事件較少。因此,在其他條件相同的情況下,每小時報表的訊號雜訊比會低於每週報表。以不同頻率測試報表需求,並評估每項需求的訊號雜訊比。
詳情請參閱「批次處理」和「在較長的時間範圍內匯總」。
決策:影響可歸因轉換的廣告活動變數
在 Noise Lab 中試用
雖然這類轉換難以預測,且除了季節性影響外,還可能出現大幅變化,但請盡量估算每日單一觸控歸因轉換次數,並四捨五入至最接近的 10 的次方:10、100、1,000 或 10,000。
- 前往「進階模式」。
- 在「參數」側邊面板中,尋找「您的轉換資料」。
- 觀察預設參數。根據預設,每日可歸因轉換總數為 1000 次。如果使用預設設定 (預設維度、每個維度可能的不同值預設數量、金鑰策略 A),平均每個值區約有 40 個值。請注意,輸入的每個區間平均每日可歸因轉換次數值為 40。
- 按一下「模擬」,使用預設參數執行模擬。
- 觀察模擬結果的雜訊比。
- 現在將每日可歸因轉換總數設為 100。 請注意,這會降低每個區間的平均每日可歸因轉換次數值。
- 按一下「模擬」。
- 請注意,雜訊比率現在會更高,這是因為每個儲存區的轉換次數越少,為維護隱私權而套用的雜訊就越多。
廣告主可獲得的轉換總數與可歸因的轉換總數,兩者之間有重要差異。後者最終會影響摘要報告中的雜訊。歸因轉換是總轉換次數的子集,容易受到廣告活動變數影響,例如廣告預算和廣告指定目標。舉例來說,如果其他條件相同,您會預期 $1000 萬美元的廣告活動比 $1 萬美元的廣告活動帶來更多歸因轉換。
注意事項:
- 根據單一觸控點同裝置歸因模式評估歸因轉換,因為這些轉換屬於 Attribution Reporting API 收集的摘要報表範圍。
- 請同時考慮最壞情況和最佳情況下的歸因轉換次數。舉例來說,在其他條件相同的情況下,請考量廣告主的廣告活動預算下限和上限,然後將這兩種結果的可歸因轉換量預估值做為模擬輸入值。
- 如果您考慮使用 Android Privacy Sandbox,請在計算時納入跨平台歸因轉換。
決策:使用縮放功能
在 Noise Lab 中試用
- 前往「進階模式」。
- 在「參數」側邊面板中,找出「您的匯總策略」>「縮放」。這項設定預設為「是」。
- 為瞭解縮放比例對雜訊比率的正面影響,請先將「縮放比例」設為「否」。
- 按一下「模擬」。
- 觀察模擬結果的雜訊比。
- 將「縮放」設為「是」。請注意,Noise Lab 會根據您情境的評估目標範圍 (平均值和最大值),自動計算要使用的縮放比例係數。在實際系統或原始碼試用版設定中,您會想實作自己的縮放比例計算。
- 按一下「模擬」。
- 觀察到第二次模擬的雜訊比現在較低 (較好)。這是因為您正在使用縮放功能。
根據核心設計原則,新增的雜訊是貢獻預算的函式。
因此,如要提高訊號與雜訊比率,您可以決定根據貢獻預算調整轉換事件期間收集的值 (並在匯總後取消調整)。使用縮放功能提高訊號雜訊比。
決策:評估目標數量和隱私權預算分配
這與縮放有關,請務必閱讀「使用縮放」。
在 Noise Lab 中試用
評估目標是轉換事件中收集的個別資料點。
- 前往「進階模式」。
- 在「參數」側邊面板中,尋找要追蹤的資料: 評估目標。根據預設,您有兩個評估目標:購買價值和購買次數。
- 按一下「模擬」,即可使用預設目標執行模擬作業。
- 按一下「移除」。這會移除最後一個評估目標 (在本例中為購買次數)。
- 按一下「模擬」。
- 請注意,第二次模擬的購買價值雜訊比現在較低 (較佳)。這是因為您減少了評估目標,因此現在一個評估目標可獲得所有貢獻預算。
- 按一下「重設」。現在您有兩個評估目標:購買價值和購買次數。請注意,Noise Lab 會根據您情境的評估目標範圍 (平均值和最大值),自動計算要使用的縮放比例係數。根據預設,Noise Lab 會將預算平均分配給各個評估目標。
- 按一下「模擬」。
- 觀察模擬結果的雜訊比。請記下模擬結果中顯示的縮放比例係數。
- 現在,請自訂隱私權預算分配,以獲得更佳的訊號雜訊比。
- 調整為每個評估目標分配的預算百分比。以預設參數為例,相較於購買次數 (介於 1 和 1 之間,也就是一律等於 1),購買價值 (介於 0 和 1000 之間) 的範圍較廣。因此,這個目標需要「更多空間來擴大規模」:理想的做法是為評估目標 1 分配的貢獻預算高於評估目標 2,這樣才能更有效率地擴大規模 (請參閱「擴大規模」),進而
- 將 70% 的預算分配給評估目標 1。將 30% 分配給評估目標 2。
- 按一下「模擬」。
- 觀察模擬結果的雜訊比。就購買價值而言,目前的雜訊比率明顯低於先前的模擬結果,因此更具參考價值。購買次數大致不變。
- 持續調整各項指標的預算分配比例。觀察這對噪音的影響。
請注意,您可以使用「新增/移除/重設」按鈕設定自己的自訂評估目標。
如果您評估轉換事件的一個資料點 (評估目標),例如轉換次數,該資料點可以取得所有貢獻預算 (65536)。如果為轉換事件設定多個評估目標 (例如轉換次數和購買價值),這些資料點就必須共用貢獻預算。也就是說,您可擴大規模的價值較少。
因此,評估目標越多,訊號雜訊比就越低 (雜訊越高)。
另一個與評估目標相關的決策是預算分配。如果將貢獻預算平均分配給兩個資料點,每個資料點的預算為 65536/2 = 32768。視每個資料點的最大可能值而定,這可能不是最佳做法。舉例來說,如果您要評估購買次數 (上限為 1) 和購買價值 (下限為 1,上限為 120),購買價值就會有「更多空間」可供調整,也就是獲得較大比例的貢獻預算。您會看到哪些評估目標應優先於其他目標,以因應雜訊造成的影響。
決策:離群值管理
在 Noise Lab 中試用
評估目標是轉換事件中收集的個別資料點。
- 前往「進階模式」。
- 在「參數」側邊面板中,找出「您的匯總策略」>「縮放」。
- 確認「縮放」設為「是」。請注意,Noise Lab 會根據您為評估目標提供的範圍 (平均值和最大值),自動計算要使用的縮放比例係數。
- 假設有史以來最大宗的交易為 $2000 美元,但大多數交易的金額介於 $10 美元到 $120 美元之間。首先,我們來看看使用字面值縮放方法 (不建議) 時會發生什麼事:輸入 $2000 做為 purchaseValue 的最大值。
- 按一下「模擬」。
- 觀察到雜訊比偏高。這是因為我們的縮放比例係以 $2000 美元為基準計算,但實際上大多數的購買價值都會明顯低於這個金額。
- 現在,讓我們採用更實用的擴充方法。將最高購買價值變更為 $120 美元。
- 按一下「模擬」。
- 觀察到第二次模擬的雜訊比率較低 (較好)。
如要實作縮放功能,通常會根據特定轉換事件的最大可能值計算縮放比例 (請參閱這個範例)。
不過,請避免使用字面上的最大值來計算縮放比例,因為這會導致訊號雜訊比變差。請改為移除離群值,並使用實用的最大值。
離群值管理是個深入的主題。您可以考慮採用多種精細技術,提升訊號雜訊比。其中一個方法請參閱「進階離群值管理」。
後續步驟
您已評估各種適用於您用途的雜訊管理策略,現在可以開始透過原始碼試用收集實際評估資料,並實驗摘要報表。參閱「試用 API」指南和提示。
附錄
Noise Lab 快速導覽
Noise Lab 可協助您快速評估及比較雜訊管理策略。其用途如下:
- 瞭解可能影響雜訊的主要參數,以及這些參數的影響。
- 模擬不同設計決策對輸出測量資料的影響。調整設計參數,直到達到適合用途的訊號雜訊比為止。
- 請分享您對摘要報表實用性的意見回饋,例如哪些 epsilon 和雜訊參數值適合您,哪些不適合。反曲點在哪裡?
這可視為準備步驟。雜訊研究室會根據您的輸入內容產生評估資料,模擬摘要報表輸出內容。不會保留或分享任何資料。
噪音實驗室提供兩種不同模式:
- 簡易模式:瞭解噪音控制的基本概念。
- 進階模式:測試不同的雜訊管理策略,評估哪種策略最適合您的用途,可達到最佳訊號雜訊比。
按一下頂端選單中的按鈕,即可在兩種模式之間切換 (下圖中的#1)。
簡易模式
- 在「簡單」模式中,您可以控制「參數」(位於左側,或下方的螢幕截圖中的#2),例如 Epsilon,並查看這些參數對雜訊的影響。
- 每個參數都有工具提示 (「?」按鈕)。點選這些參數即可查看說明 (下圖中的#3)
- 首先,請按一下「模擬」按鈕,觀察輸出內容的樣子 (#4. 在下方的螢幕截圖中)
- 「輸出」部分會顯示各種詳細資料,部分元素旁邊會顯示 `?`,請花時間點選每個「?」,查看各項資訊的說明。
- 在「輸出」部分中,按一下「詳細資料」切換按鈕,即可查看表格的展開版本 (下圖中的#5)。
- 輸出內容中的每個資料表後方,都有可供下載的選項,方便您離線使用。此外,在右下角還有下載所有資料表的選項 (下圖中的#6)。
- 在「參數」部分測試參數的不同設定,然後按一下「模擬」,查看這些設定對輸出內容的影響:
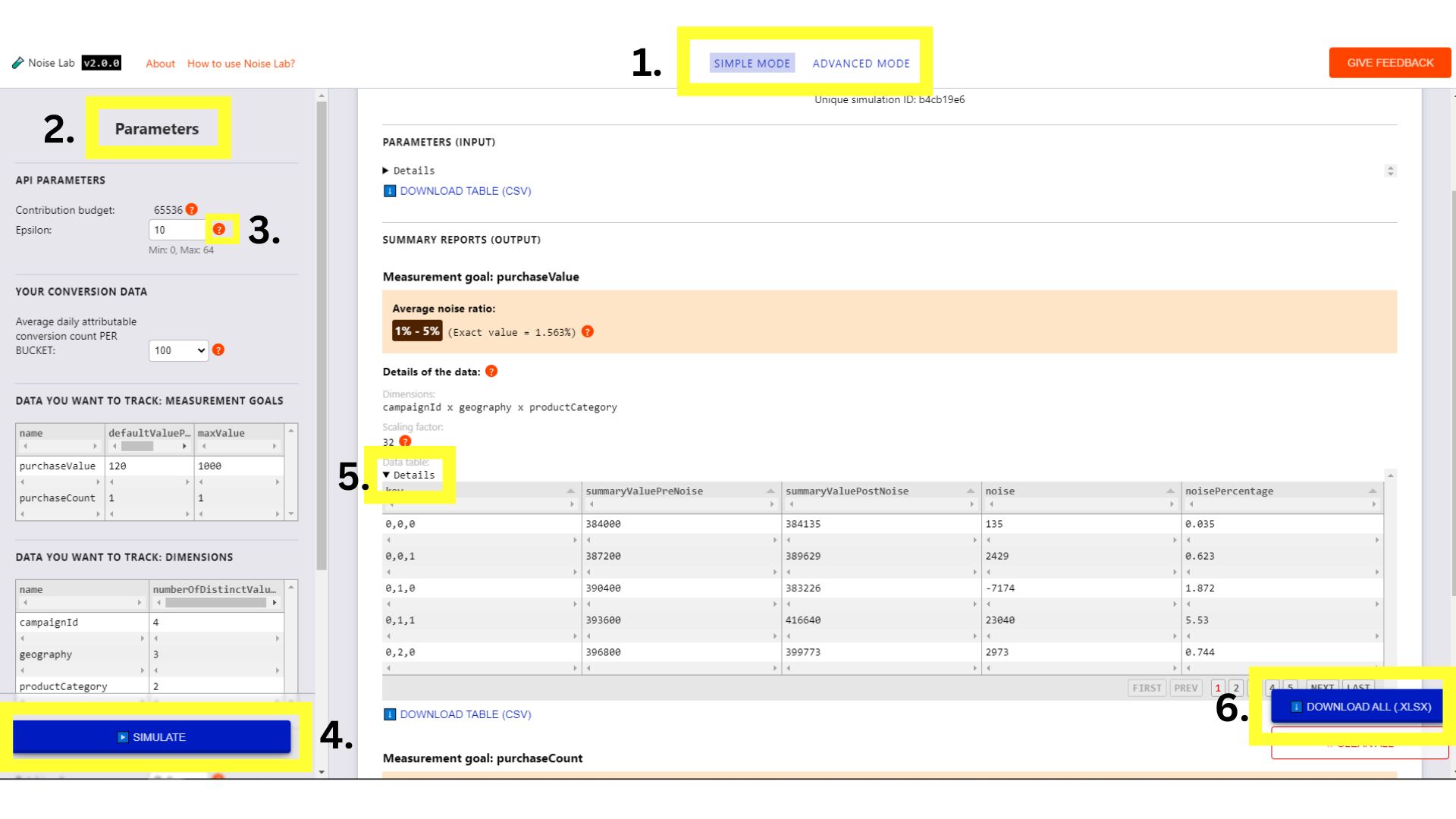 「簡單」模式的 Noise Lab 介面。
「簡單」模式的 Noise Lab 介面。
進階模式
- 在「進階」模式中,您可以進一步控管參數。您可以新增自訂評估目標和維度 (下圖中的#1 和 #2)。
- 在「參數」部分中進一步向下捲動,即可看到「關鍵字策略」選項。可用於測試不同的金鑰結構 (下圖中的 #3.)。
- 如要測試不同的目標結構,請將目標策略切換為「B」
- 輸入要使用的不同金鑰結構數量 (預設為「2」)
- 按一下「產生金鑰結構」
- 按一下每個金鑰結構旁邊的核取方塊,即可指定金鑰結構。
- 按一下「模擬」即可查看輸出內容。
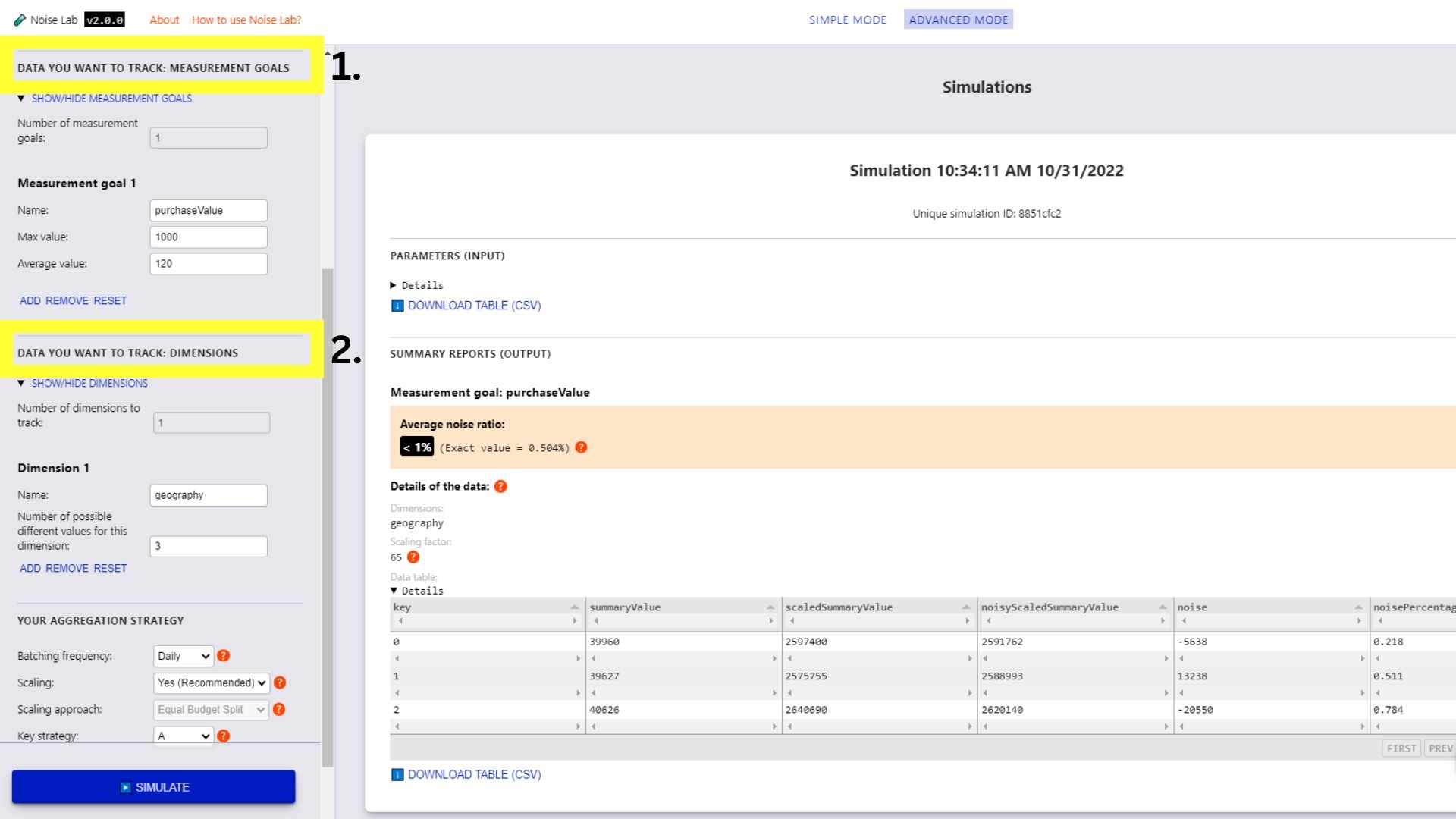
進階模式的噪音實驗室介面。 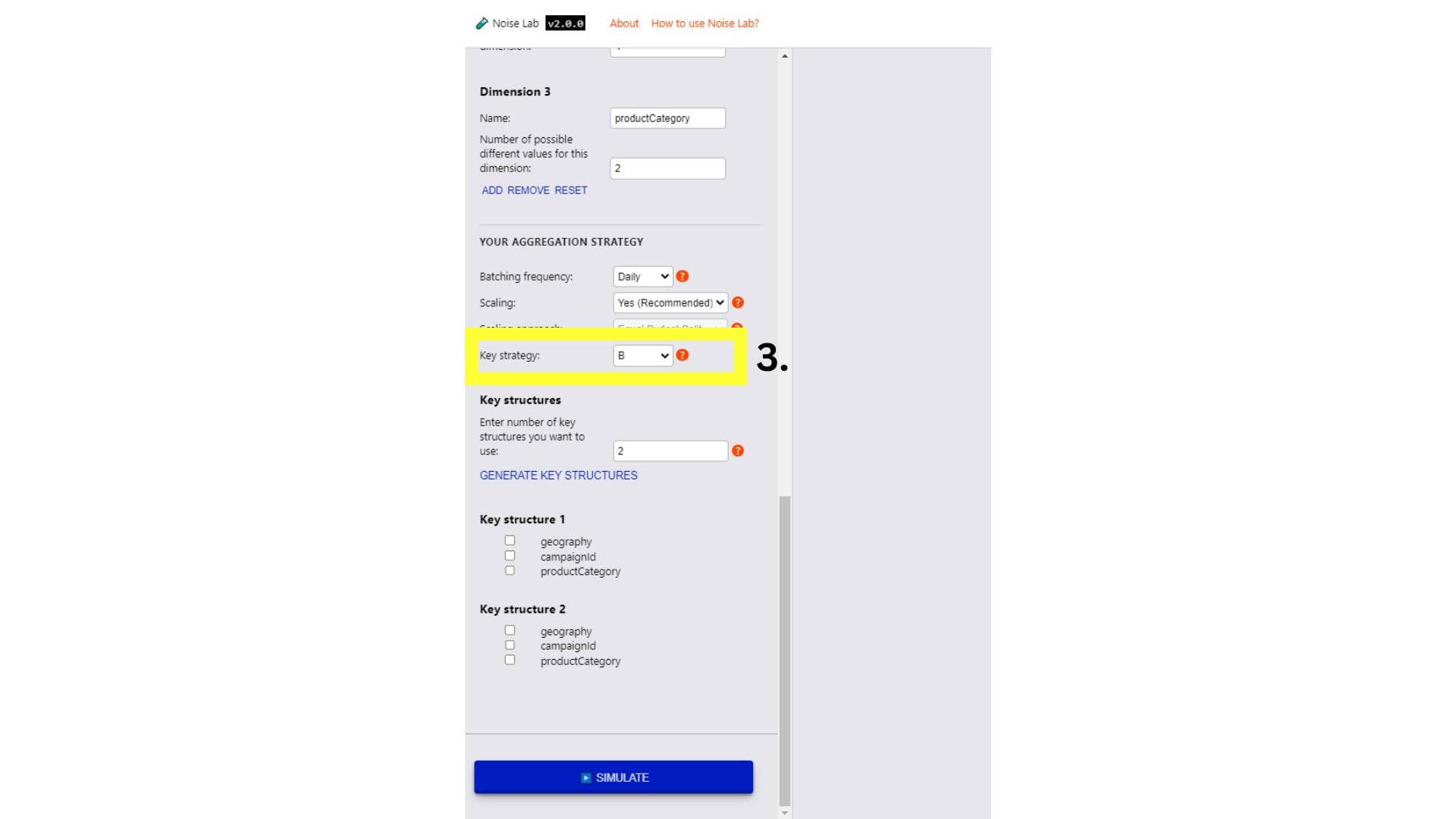
進階模式的噪音實驗室介面。
噪音指標
核心概念
加入雜訊可保護個別使用者的隱私。
高雜訊值表示 bucket/key 稀疏,且只包含少數敏感事件的貢獻。Noise Lab 會自動執行這項操作,讓個人「隱藏在人群中」,也就是加入大量雜訊,保護這些少數人的隱私權。
如果雜訊值偏低,表示資料設定的設計方式已允許使用者「隱藏在人群中」。也就是說,這些值區包含足夠數量的事件貢獻,可確保個人使用者隱私受到保護。
平均百分比誤差 (APE) 和 RMSRE_T (設有門檻的均方根相對誤差) 皆適用這項陳述。
APE (平均百分比誤差)
APE 是雜訊與信號的比率,也就是真實摘要值。
APE 值越低,代表訊號雜訊比越好。
公式
特定摘要報表的 APE 計算方式如下:
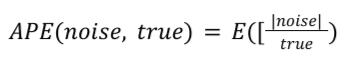
True 是摘要的實際值。APE 是每個真實摘要值的平均雜訊,並取摘要報表中所有項目的平均值。在 Noise Lab 中,這項值會乘以 100,得出百分比。
優點和缺點
如果 bucket 較小,對 APE 最終值的影響會不成比例。這可能會誤導噪音評估結果。因此,我們新增了另一個指標 RMSRE_T,旨在減輕 APE 的這項限制。詳情請參閱範例。
程式碼
查看 APE 計算的原始碼。
RMSRE_T (設有閾值的均方根相對誤差)
RMSRE_T (設有門檻的均方根相對誤差) 是另一種雜訊測量方式。
如何解讀 RMSRE_T
RMSRE_T 值越小,代表訊號雜訊比越好。
舉例來說,如果您的使用情境可接受的雜訊比為 20%,且 RMSRE_T 為 0.2,則可放心雜訊程度落在可接受的範圍內。
公式
特定摘要報表的 RMSRE_T 計算方式如下:
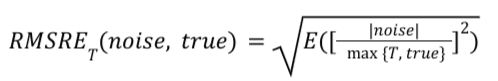
優缺點
相較於 APE,RMSRE_T 較難理解。不過,與 APE 相比,這項指標有幾項優勢,因此在某些情況下,更適合用於分析摘要報表中的雜訊:
- RMSRE_T 更穩定。「T」是門檻。在 RMSRE_T 計算中,我們會使用「T」為轉換次數較少的區間賦予較低的權重,因為這些區間的規模較小,因此對雜訊較為敏感。使用 T 時,指標不會在轉換次數較少的區間中大幅增加。如果 T 等於 5,轉換次數為 0 的值區中,即使雜訊值小至 1,也不會顯示為遠大於 1。而是會設為上限 0.2,相當於 1/5,因為 T 等於 5。這個指標會降低較小儲存區的權重,因此對雜訊較為敏感,也更穩定,方便比較兩項模擬結果。
- RMSRE_T 可直接匯總。知道多個 bucket 的 RMSRE_T 和實際計數後,您就能計算這些 bucket 總和的 RMSRE_T。您也可以針對這些合併值,將 RMSRE_T 最佳化。
雖然可以匯總 APE,但由於公式涉及拉普拉斯雜訊總和的絕對值,因此相當複雜。這會導致 APE 難以最佳化。
程式碼
查看 RMSRE_T 計算的原始碼。
範例
摘要報告,包含三個類別:
- bucket_1 = noise: 10, trueSummaryValue: 100
- bucket_2 = noise: 20, trueSummaryValue: 100
- bucket_3 = noise: 20, trueSummaryValue: 200
APE = (0.1 + 0.2 + 0.1) / 3 = 13%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,200))^2) / 3) = sqrt( (0.01 + 0.04 + 0.01) / 3) = 0.14
摘要報告,包含三個類別:
- bucket_1 = noise: 10, trueSummaryValue: 100
- bucket_2 = noise: 20, trueSummaryValue: 100
- bucket_3 = noise: 20, trueSummaryValue: 20
APE = (0.1 + 0.2 + 1) / 3 = 43%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,20))^2) / 3) = sqrt( (0.01 + 0.04 + 1.0) / 3) = 0.59
摘要報告,包含三個類別:
- bucket_1 = noise: 10, trueSummaryValue: 100
- bucket_2 = noise: 20, trueSummaryValue: 100
- bucket_3 = noise: 20, trueSummaryValue: 0
APE = (0.1 + 0.2 + Infinity) / 3 = Infinity
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,0))^2) / 3) = sqrt( (0.01 + 0.04 + 16.0) / 3) = 2.31
進階金鑰管理
DSP 或廣告成效評估公司可能在全球擁有數千名廣告客戶,涵蓋多個產業、幣別和潛在購買價格。也就是說,為每位廣告主建立及管理一個匯總鍵,可能非常不切實際。此外,要為全球數千名廣告主選取可匯總的最大值和匯總預算,以限制雜訊的影響,也是一大挑戰。請改為考慮下列情境:
主要策略 A
廣告技術供應商決定為所有廣告客戶建立及管理一個金鑰。在所有廣告主和所有幣別中,購買範圍從低量、高價購買到高量、低價購買都有。這會產生下列金鑰:
| 金鑰 (多種貨幣) | |
|---|---|
| 可匯總的最大值 | 5,000,000 |
| 購物價值範圍 | [120 - 5000000] |
主要策略 B
廣告技術供應商決定為所有廣告客戶建立及管理兩把金鑰。他們決定依幣別分隔金鑰。所有廣告主和所有幣別的購買範圍,從低量的高價購買到高量的低價購買都有。依幣別分開,建立 2 個金鑰:
| Key 1 (美元) | 鑰匙 2 (¥) | |
|---|---|---|
| 可匯總的最大值 | $40,000 美元 | ¥5,000,000 |
| 購物價值範圍 | [120 - 40,000] | [15,000 - 5,000,000] |
由於貨幣值並非平均分配給各個貨幣,因此關鍵策略 B 的結果雜訊會比關鍵策略 A 少。舉例來說,如果以日圓計價的交易與以美元計價的交易混雜在一起,基礎資料會如何改變,以及產生哪些雜訊輸出內容。
主要策略 C
廣告技術供應商決定為所有廣告客戶建立及管理四個金鑰,並依「幣別 x 廣告主產業」區分:
| Key 1 (美元 x 高檔珠寶廣告主) |
關鍵字 2 (¥ x 高檔珠寶廣告主) |
關鍵字 3 (美元 x 服飾零售廣告主) |
主要 4 (¥ x 服飾零售廣告主) |
|
|---|---|---|---|---|
| 可匯總的最大值 | $40,000 美元 | ¥5,000,000 | $500 美元 | ¥65,000 |
| 購物價值範圍 | [10,000 - 40,000] | [1,250,000 - 5,000,000] | [120 - 500] | [15,000 - 65,000] |
由於廣告主購買價值並非平均分配給各個廣告主,因此主要策略 C 的結果干擾較少,舉例來說,如果高檔珠寶的購買交易與棒球帽的購買交易混在一起,就會改變基礎資料,導致輸出結果出現雜訊。
建議您為多個廣告主之間的共同點建立共用的最大匯總值和共用的縮放比例,以減少輸出內容中的干擾。舉例來說,您可以為廣告主實驗下列策略:
- 以貨幣 (美元、日圓、加幣等) 分隔的策略
- 依廣告主產業區分策略 (保險、汽車、零售等)
- 以類似的購物價值範圍分隔策略 ([100]、[1000]、[10000] 等)
根據廣告主共性建立主要策略,可簡化指定鍵和相應程式碼的管理作業,並提高訊號雜訊比。針對不同廣告主共性實驗不同策略,找出可最大化噪音影響與程式碼管理之間的反曲點。
進階離群值管理
假設有兩位廣告主,情境如下:
- 廣告主 A:
- 在廣告主 A 網站上的所有產品中,可能的購買價格介於 [$120 - $1,000],範圍為 $880。
- 購買價格平均分布在 $880 美元的範圍內,且沒有超出購買價格中位數兩個標準差的離群值。
- 廣告主 B:
- 廣告主 B 網站上所有產品的可能購買價格介於 $120 美元至 $1,000 美元之間,範圍為 $880 美元。
- 購買價格大多落在 $120 美元至 $500 美元之間,只有 5% 的購買交易價格介於 $500 美元至 $1,000 美元。
根據貢獻預算規定和將干擾套用至最終結果的方法,廣告主 B 的輸出內容預設會比廣告主 A 更容易受到干擾,因為廣告主 B 的離群值可能對基礎計算造成影響。
您可以透過特定金鑰設定來緩解這個問題。測試有助於管理離群值資料,並在主要購買範圍內更平均分配購買值的關鍵策略。
對於廣告主 B,您可以建立兩個不同的鍵,擷取兩個不同的購買價值範圍。在本範例中,廣告技術注意到離群值出現在 $500 美元的購買價值以上。請嘗試為這個廣告主導入兩個不同的鍵:
- 主要結構 1:只擷取 $120 至 $500 範圍內的購買交易 (涵蓋約 95% 的總購買量)。
- 主要結構 2:只擷取高於 $500 美元的購買交易 (涵蓋約 5% 的總購買量)。
實施這項重要策略後,廣告主 B 就能更妥善地管理干擾,並盡可能從摘要報表中獲取實用資訊。由於範圍縮小,現在鍵 A 和鍵 B 應該會比先前的單一鍵更平均地分配資料。這樣一來,每個金鑰的輸出內容所受到的雜訊影響,就會比先前的單一金鑰更小。