
Об этом документе
Прочитав этот документ, вы узнаете:
- Прежде чем составлять сводные отчеты, необходимо понять, какие стратегии следует разработать.
- Познакомьтесь с Noise Lab — инструментом, который помогает понять влияние различных параметров шума и позволяет быстро исследовать и оценивать различные стратегии управления шумом.
Поделитесь своим мнением.
Хотя в этом документе обобщены некоторые принципы работы с аналитическими отчетами, существует множество подходов к управлению шумом, которые могут здесь не быть отражены. Ваши предложения, дополнения и вопросы приветствуются!
- Чтобы оставить публичный отзыв о стратегиях управления шумом, о полезности или конфиденциальности API (epsilon), а также поделиться своими наблюдениями при моделировании с помощью Noise Lab: оставьте комментарий к этому вопросу.
- Чтобы оставить отзыв о другом аспекте API: создайте новую проблему здесь.
Прежде чем начать
- Для ознакомления с системой отчетности по атрибуции прочтите разделы «Сводные отчеты по атрибуции» и «Полный обзор системы отчетности по атрибуции» .
- Для наилучшего использования этого руководства ознакомьтесь с разделами «Понимание шума» и «Понимание ключей агрегации» .
проектные решения
Основной принцип проектирования
Между принципами работы сторонних файлов cookie и сводных отчетов существуют принципиальные различия. Одно из ключевых различий заключается в шуме , добавляемом к данным измерений в сводных отчетах. Другое различие состоит в способе планирования отчетов.
Для получения сводных отчетов об измерениях с более высоким соотношением сигнал/шум платформам со стороны спроса (DSP) и поставщикам услуг по измерению эффективности рекламы необходимо будет сотрудничать со своими рекламодателями для разработки стратегий управления шумом. Для разработки этих стратегий DSP и поставщикам услуг по измерению эффективности необходимо принять проектные решения. Эти решения вращаются вокруг одной важной концепции:
Хотя значения шума распределения, по сути, зависят только от двух параметров — ε и бюджета вклада , — у вас есть ряд других факторов, которые повлияют на отношение сигнал/шум в данных измерений выходного сигнала.
Хотя мы ожидаем, что итеративный процесс приведет к наилучшим решениям, каждая вариация этих решений приведет к немного отличающейся реализации — поэтому эти решения необходимо принимать до написания каждой итерации кода (и до запуска рекламы).
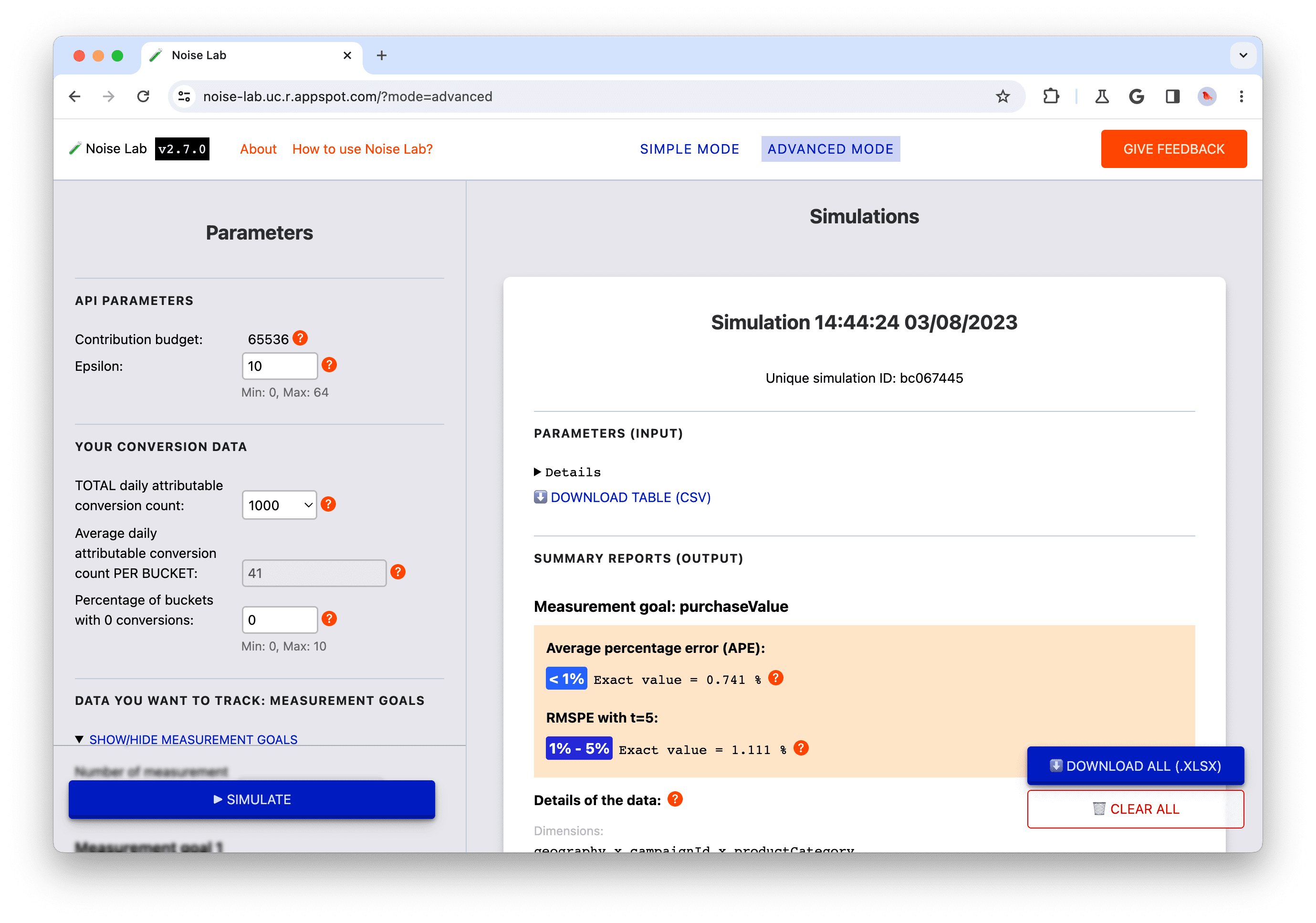
Решение: Детализация измерений
Попробуйте это в Noise Lab.
- Перейдите в расширенный режим.
- В боковой панели «Параметры» найдите раздел «Ваши данные о конверсиях».
- Обратите внимание на параметры по умолчанию. По умолчанию общее количество ежедневных конверсий, соответствующих критериям, составляет 1000. В среднем это составляет примерно 40 на каждый сегмент, если вы используете настройки по умолчанию (измерения по умолчанию, количество возможных значений для каждого измерения по умолчанию, ключевая стратегия A). Обратите внимание, что значение равно 40 во входных данных «Среднее количество ежедневных конверсий, соответствующих критериям, НА СЕГМЕНТ».
- Нажмите кнопку «Симуляция», чтобы запустить симуляцию с параметрами по умолчанию.
- В боковой панели «Параметры» найдите раздел «Измерения». Переименуйте параметр «География» в «Город» и измените количество возможных значений на 50.
- Обратите внимание, как это меняет среднее ежедневное количество конверсий, учитываемых в каждой группе. Теперь оно значительно ниже. Это происходит потому, что если увеличить количество возможных значений в этом измерении, не меняя ничего другого, то увеличится общее количество групп, но количество событий конверсии, попадающих в каждую группу, останется неизменным.
- Нажмите «Имитировать».
- Обратите внимание на соотношение шумов в полученной симуляции: теперь соотношение шумов выше, чем в предыдущей симуляции.
Исходя из основного принципа проектирования , небольшие сводные значения, вероятно, будут содержать больше шума, чем большие. Поэтому ваш выбор конфигурации влияет на то, сколько атрибутированных событий конверсии попадает в каждый сегмент (иначе называемый ключом агрегации), и это количество влияет на уровень шума в итоговых сводных отчетах.
Одним из проектных решений, влияющих на количество атрибутированных событий конверсии в рамках одного сегмента, является детализация измерений. Рассмотрим следующие примеры ключей агрегации и их измерений:
- Подход 1: одна ключевая структура с приблизительными параметрами: Страна x Рекламная кампания (или самый крупный сегмент агрегации кампаний) x Тип продукта (из 10 возможных типов продуктов)
- Подход 2: одна ключевая структура с детализированными параметрами: Город x Креативный идентификатор x Продукт (из 100 возможных продуктов)
Город — более детализированный параметр, чем Страна ; идентификатор креатива — более детализированный, чем Кампания ; а продукт — более детализированный, чем тип продукта . Следовательно, в сводном отчете по Подходу 2 будет меньше событий (конверсий) на каждый сегмент (= на каждый ключ), чем по Подходу 1. Учитывая, что шум, добавляемый к выходным данным, не зависит от количества событий в сегменте, данные измерений в сводных отчетах будут более зашумленными при Подходе 2. Для каждого рекламодателя следует поэкспериментировать с различными компромиссами в детализации при проектировании ключа, чтобы получить максимальную пользу от результатов.
Решение: Ключевые структуры
Попробуйте это в Noise Lab.
В простом режиме используется структура ключей по умолчанию. В расширенном режиме вы можете экспериментировать с различными структурами ключей. Приведены некоторые примеры измерений; вы также можете их изменить.
- Перейдите в расширенный режим.
- В боковой панели «Параметры» найдите «Ключевая стратегия». Обратите внимание, что стратегия по умолчанию, обозначенная в инструменте как A, использует одну детализированную ключевую структуру, включающую все измерения: География x Идентификатор кампании x Категория продукта.
- Нажмите «Имитировать».
- Проанализируйте соотношение уровней шума в полученном результате моделирования.
- Измените стратегию ключа на B. При этом отобразятся дополнительные элементы управления для настройки структуры ключа.
- Настройте структуру ключей, например, следующим образом:
- Количество ключевых структур: 2
- Ключевая структура 1 = География x Категория товара.
- Ключевая структура 2 = Идентификатор кампании x Категория товара.
- Нажмите «Имитировать».
- Обратите внимание, что теперь вы получаете два сводных отчета по каждому типу цели измерения (два для количества покупок, два для стоимости покупок), поскольку вы используете две разные ключевые структуры. Обратите внимание на соотношение шума в них.
- Вы также можете попробовать это с собственными пользовательскими измерениями. Для этого найдите раздел «Данные, которые вы хотите отслеживать»: «Измерения». Рекомендуем удалить примеры измерений и создать свои собственные, используя кнопки «Добавить/Удалить/Сбросить» под последним измерением.
Еще одно проектное решение, которое повлияет на количество атрибутированных событий конверсии в рамках одного сегмента, — это ключевые структуры, которые вы решите использовать. Рассмотрим следующие примеры ключей агрегации:
- Единая ключевая структура, охватывающая все аспекты; назовем ее Ключевой стратегией А.
- Две ключевые структуры, каждая из которых имеет подмножество измерений; назовем это ключевой стратегией B.
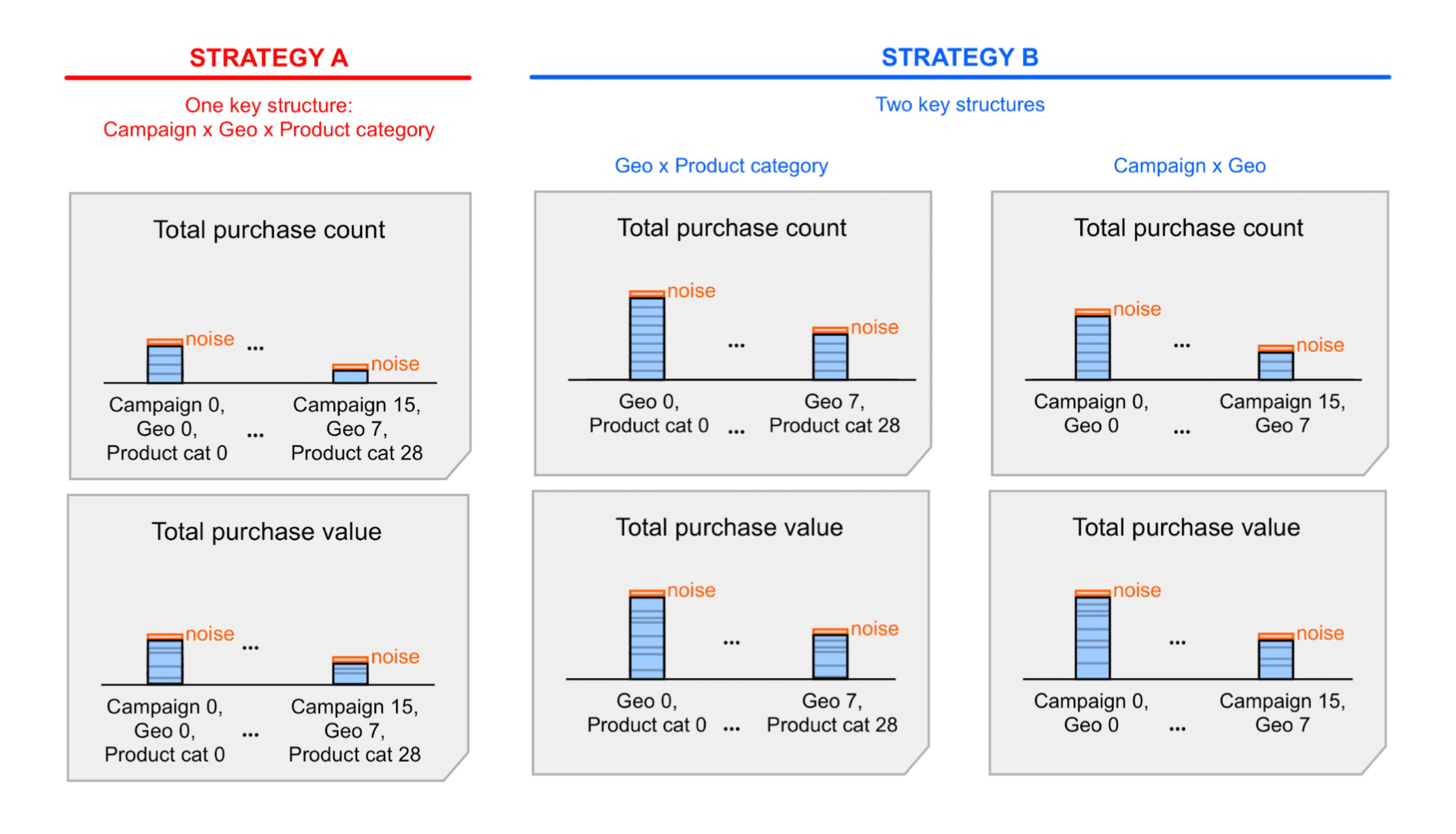
Стратегия А проще, но для получения определенных аналитических данных вам может потребоваться суммировать зашумленные значения, содержащиеся в сводных отчетах. Суммируя эти значения, вы также суммируете шум. При использовании стратегии B сводные значения, представленные в сводных отчетах, уже могут содержать необходимую информацию. Это означает, что стратегия B, вероятно, обеспечит лучшее соотношение сигнал/шум, чем стратегия А. Однако уровень шума может быть уже приемлемым при использовании стратегии А, поэтому вы все равно можете предпочесть стратегию А из-за простоты. Подробнее см. в подробном примере, описывающем эти две стратегии .
Управление ключами — это сложная тема. Для улучшения соотношения сигнал/шум можно рассмотреть ряд сложных методов. Один из них описан в разделе «Расширенное управление ключами» .
Решение: Частота пакетной обработки
Попробуйте это в Noise Lab.
- Перейдите в простой режим (или расширенный режим — оба режима работают одинаково в отношении частоты пакетной обработки).
- В боковой панели «Параметры» найдите пункт «Ваша стратегия агрегирования» > «Частота пакетной обработки». Это относится к частоте пакетной обработки агрегируемых отчетов, которые обрабатываются службой агрегирования в рамках одного задания.
- Обратите внимание на частоту пакетной обработки по умолчанию: по умолчанию имитируется ежедневная частота пакетной обработки.
- Нажмите «Имитировать».
- Проанализируйте соотношение уровней шума в полученном результате моделирования.
- Измените частоту пакетной обработки на еженедельную.
- Обратите внимание на соотношение шумов в полученной симуляции: теперь соотношение шумов ниже (лучше), чем в предыдущей симуляции.
Еще одно проектное решение, которое повлияет на количество событий конверсии, отнесенных к определенному сегменту, — это частота пакетной обработки, которую вы выберете. Частота пакетной обработки определяет, как часто вы обрабатываете агрегируемые отчеты.
Отчет, агрегация которого запланирована на более частую частоту (например, каждый час), будет содержать меньше событий конверсии, чем тот же отчет с менее частым графиком агрегации (например, каждую неделю). В результате почасовой отчет будет содержать больше шума. В результате почасовой отчет будет иметь более низкое соотношение сигнал/шум, чем еженедельный отчет, при прочих равных условиях. Поэкспериментируйте с требованиями к отчетности при различной частоте и оцените соотношение сигнал/шум для каждого случая.
Подробнее об этом можно узнать в разделе «Пакетная обработка и агрегирование данных за более длительные периоды времени» .
Решение: Переменные кампании, влияющие на конверсии, которые можно отнести к той или иной кампании.
Попробуйте это в Noise Lab.
Хотя это сложно предсказать, и показатели могут значительно колебаться, помимо сезонных колебаний, попробуйте оценить количество ежедневных конверсий, обусловленных одним касанием, с точностью до ближайшей степени числа 10: 10, 100, 1000 или 10 000.
- Перейдите в расширенный режим.
- В боковой панели «Параметры» найдите раздел «Ваши данные о конверсиях».
- Обратите внимание на параметры по умолчанию. По умолчанию общее количество ежедневных конверсий, соответствующих критериям, составляет 1000. В среднем это составляет примерно 40 на каждый сегмент, если вы используете настройки по умолчанию (измерения по умолчанию, количество возможных значений для каждого измерения по умолчанию, ключевая стратегия A). Обратите внимание, что значение равно 40 во входных данных «Среднее количество ежедневных конверсий, соответствующих критериям, НА СЕГМЕНТ».
- Нажмите кнопку «Симуляция», чтобы запустить симуляцию с параметрами по умолчанию.
- Проанализируйте соотношение уровней шума в полученном результате моделирования.
- Теперь установите общее количество ежедневных конверсий, соответствующих критериям, равным 100. Обратите внимание, что это снизит значение среднего ежедневного количества конверсий, соответствующих критериям, для каждой группы пользователей.
- Нажмите «Имитировать».
- Обратите внимание, что теперь уровень шума выше: это происходит потому, что при меньшем количестве конверсий в каждой группе применяется больше шума для обеспечения конфиденциальности.
Важное различие заключается в общем количестве возможных конверсий для рекламодателя и общем количестве возможных конверсий, отнесенных к определенной категории . Именно последнее в конечном итоге влияет на «шум» в сводных отчетах. Отнесенные к определенной категории конверсии — это подмножество общего числа конверсий, которое подвержено влиянию переменных кампании, таких как рекламный бюджет и таргетинг. Например, при прочих равных условиях, вы ожидаете большего количества отнесенных к определенной категории конверсий для рекламной кампании стоимостью 10 миллионов долларов по сравнению с кампанией стоимостью 10 тысяч долларов.
Что следует учесть:
- Оценивайте конверсии, полученные с помощью модели атрибуции по одному касанию на одном устройстве, поскольку они входят в область действия сводных отчетов, собираемых с помощью API отчетности по атрибуции.
- Рассмотрите как наихудший, так и наилучший сценарий для количества конверсий, соответствующих критериям. Например, при прочих равных условиях, учтите минимальный и максимальный возможные бюджеты кампании для рекламодателя, а затем спрогнозируйте количество конверсий, соответствующих критериям, для обоих результатов в качестве входных данных для вашей симуляции.
- Если вы рассматриваете возможность использования Android Privacy Sandbox , учитывайте при расчетах кроссплатформенные атрибутированные конверсии.
Решение: Использование масштабирования
Попробуйте это в Noise Lab.
- Перейдите в расширенный режим.
- В боковой панели «Параметры» найдите пункт «Ваша стратегия агрегирования» > «Масштабирование». По умолчанию он установлен на «Да».
- Для понимания положительного влияния масштабирования на уровень шума, сначала установите параметр «Масштабирование» на «Нет».
- Нажмите «Имитировать».
- Проанализируйте соотношение уровней шума в полученном результате моделирования.
- Установите параметр «Масштабирование» в значение «Да». Обратите внимание, что Noise Lab автоматически рассчитывает коэффициенты масштабирования, исходя из диапазонов (средних и максимальных значений) целевых показателей измерений для вашего сценария. В реальной системе или в исходной тестовой конфигурации вам потребуется реализовать собственный расчет коэффициентов масштабирования.
- Нажмите «Имитировать».
- Обратите внимание, что во второй симуляции уровень шума стал ниже (лучше). Это связано с использованием масштабирования.
Исходя из основного принципа проектирования , добавляемый шум является функцией бюджета на внесение вклада.
Таким образом, для повышения отношения сигнал/шум можно преобразовать значения, собранные во время конверсии, путем масштабирования их относительно бюджета взносов (и последующего уменьшения масштаба после агрегирования). Используйте масштабирование для повышения отношения сигнал/шум.
Решение: Количество целей измерения и распределение бюджета на обеспечение конфиденциальности.
Это относится к масштабированию; обязательно ознакомьтесь с разделом «Использование масштабирования» .
Попробуйте это в Noise Lab.
Цель измерения — это отдельная точка данных, собираемая в ходе событий конверсии.
- Перейдите в расширенный режим.
- В боковой панели «Параметры» найдите раздел «Данные, которые вы хотите отслеживать: Цели измерения». По умолчанию у вас есть две цели измерения: стоимость покупки и количество покупок.
- Нажмите «Симулировать», чтобы запустить симуляцию с целевыми значениями по умолчанию.
- Нажмите «Удалить». Это удалит последнюю цель измерения (в данном случае, количество покупок).
- Нажмите «Имитировать».
- Обратите внимание, что во второй симуляции уровень шума для стоимости покупки стал ниже (лучше). Это связано с тем, что у вас меньше целей измерения, поэтому теперь весь бюджет на сбор данных достается вашей единственной цели измерения.
- Нажмите «Сброс». Теперь у вас снова две цели измерения: стоимость покупки и количество покупок. Обратите внимание, что Noise Lab автоматически рассчитывает коэффициенты масштабирования, которые будут использоваться, исходя из диапазонов (средних и максимальных значений) целей измерения для вашего сценария. По умолчанию Noise Lab распределяет бюджет поровну между целями измерения.
- Нажмите «Имитировать».
- Обратите внимание на соотношение шумов в полученной симуляции. Запишите масштабные коэффициенты, отображаемые в симуляции.
- Теперь давайте настроим распределение бюджета конфиденциальности для достижения лучшего соотношения сигнал-шум.
- Отрегулируйте процент бюджета, выделенный для каждой цели измерения. При параметрах по умолчанию цель измерения 1, а именно стоимость покупки, имеет гораздо более широкий диапазон (от 0 до 1000), чем цель измерения 2, а именно количество покупок (от 1 до 1, то есть всегда равно 1). Из-за этого ей требуется «больше места для масштабирования»: было бы идеально выделить больше средств на цель измерения 1, чем на цель измерения 2, чтобы ее можно было масштабировать более эффективно (см. раздел «Масштабирование»), и, следовательно,
- Выделите 70% бюджета на достижение цели измерения 1. Выделите 30% на достижение цели измерения 2.
- Нажмите «Имитировать».
- Обратите внимание на соотношение шумов в полученной симуляции. Для показателя стоимости покупки соотношение шумов теперь заметно ниже (лучше), чем в предыдущей симуляции. Для показателя количества покупок оно практически не изменилось.
- Продолжайте корректировать распределение бюджета по показателям. Наблюдайте, как это влияет на уровень шума.
Обратите внимание, что вы можете установить собственные цели измерений с помощью кнопок «Добавить/Удалить/Сбросить».
Если вы измеряете одну точку данных (цель измерения) для события конверсии, например, количество конверсий, то эта точка данных может получить весь бюджет взносов (65536). Если вы устанавливаете несколько целей измерения для события конверсии, например, количество конверсий и стоимость покупки, то этим точкам данных придется делить бюджет взносов. Это означает, что у вас будет меньше возможностей для масштабирования значений.
Следовательно, чем больше целей измерения, тем ниже, вероятно, будет отношение сигнал/шум (тем выше уровень шума).
Еще одно решение, касающееся целей измерения, — это распределение бюджета. Если разделить бюджет на сбор средств поровну между двумя точками данных, то на каждую точку данных будет выделен бюджет в размере 65536/2 = 32768. Это может быть оптимальным или нет, в зависимости от максимально возможного значения для каждой точки данных. Например, если вы измеряете количество покупок с максимальным значением 1 и стоимость покупок с минимальным значением 1 и максимальным значением 120, то для стоимости покупок будет полезно выделить больше места для масштабирования — то есть, большую долю бюджета на сбор средств. Вы увидите, следует ли отдавать приоритет одним целям измерения перед другими в зависимости от влияния шума.
Решение: Управление выбросами
Попробуйте это в Noise Lab.
Цель измерения — это отдельная точка данных, собираемая в ходе событий конверсии.
- Перейдите в расширенный режим.
- В боковой панели «Параметры» найдите раздел «Ваша стратегия агрегации» > «Масштабирование».
- Убедитесь, что параметр «Масштабирование» установлен в значение «Да». Обратите внимание, что Noise Lab автоматически рассчитывает коэффициенты масштабирования, которые будут использоваться, на основе диапазонов (средних и максимальных значений), которые вы указали для целей измерения.
- Предположим, что самая крупная покупка в истории составила 2000 долларов, но большинство покупок совершаются в диапазоне от 10 до 120 долларов. Для начала посмотрим, что произойдет, если мы используем буквальное масштабирование (не рекомендуется): введем 2000 долларов в качестве максимального значения для purchaseValue.
- Нажмите «Имитировать».
- Обратите внимание, что уровень шума высок. Это связано с тем, что наш масштабный коэффициент рассчитан исходя из 2000 долларов, тогда как в реальности большинство покупательских цен будут значительно ниже этой суммы.
- Теперь давайте применим более прагматичный подход к масштабированию. Изменим максимальную сумму покупки на 120 долларов.
- Нажмите «Имитировать».
- Обратите внимание, что во второй симуляции соотношение шумов ниже (лучше).
Для реализации масштабирования обычно рассчитывается коэффициент масштабирования, основанный на максимально возможном значении для данного события конверсии ( подробнее см. в этом примере ).
Однако следует избегать использования буквального максимального значения для расчета этого масштабного коэффициента, поскольку это ухудшит соотношение сигнал/шум. Вместо этого удалите выбросы и используйте прагматичное максимальное значение.
Управление выбросами — сложная тема. Для улучшения соотношения сигнал/шум можно рассмотреть ряд сложных методов. Один из них описан в книге «Расширенное управление выбросами» .
Следующие шаги
Теперь, когда вы оценили различные стратегии управления шумом для вашего конкретного случая, вы готовы начать экспериментировать с составлением сводных отчетов, собирая реальные данные измерений с помощью исходного эксперимента. Ознакомьтесь с руководствами и советами по использованию API .
Приложение
Краткий обзор лаборатории шума
Noise Lab поможет вам быстро оценить и сравнить стратегии управления шумом. Используйте его для:
- Разберитесь в основных параметрах, которые могут влиять на уровень шума, и в том, какое воздействие они оказывают.
- Смоделируйте влияние шума на выходные данные измерений при различных проектных решениях. Настраивайте параметры проектирования до тех пор, пока не достигнете соотношения сигнал/шум, подходящего для вашего конкретного случая.
- Поделитесь своим мнением о полезности сводных отчетов: какие значения параметров эпсилон и шума вам подходят, а какие нет? Где находятся точки перегиба?
Рассматривайте это как подготовительный этап. Noise Lab генерирует данные измерений для моделирования итоговых отчетов на основе ваших входных данных. Данные не сохраняются и не передаются третьим лицам.
В Noise Lab есть два разных режима:
- Простой режим: разберитесь в основах управления шумом с помощью имеющихся у вас средств.
- Расширенный режим: протестируйте различные стратегии подавления шума и оцените, какая из них обеспечивает наилучшее соотношение сигнал/шум для ваших задач.
Нажмите кнопки в верхнем меню, чтобы переключаться между двумя режимами ( № 1 на следующем скриншоте ).
Простой режим
- В простом режиме вы управляете параметрами (расположенными слева, или № 2 на следующем скриншоте ), такими как Epsilon, и видите, как они влияют на шум.
- Для каждого параметра есть всплывающая подсказка (кнопка «?»). Нажмите на неё, чтобы увидеть объяснение каждого параметра ( № 3 на следующем скриншоте ).
- Для начала нажмите кнопку «Имитировать» и посмотрите, как выглядит результат ( № 4 на следующем скриншоте ).
- В разделе «Вывод» вы можете увидеть множество подробностей. Некоторые элементы отмечены знаком «?». Уделите время, чтобы щелкнуть по каждому знаку «?» и увидеть объяснение различных элементов информации.
- В разделе «Вывод» нажмите переключатель «Подробности», если хотите увидеть расширенную версию таблицы ( № 5 на следующем скриншоте ).
- После каждой таблицы данных в разделе вывода есть возможность загрузить таблицу для использования в автономном режиме. Кроме того, в правом нижнем углу есть возможность загрузить все таблицы данных ( № 6 на следующем скриншоте ).
- Протестируйте различные настройки параметров в разделе «Параметры» и нажмите «Имитировать», чтобы увидеть, как они влияют на результат:
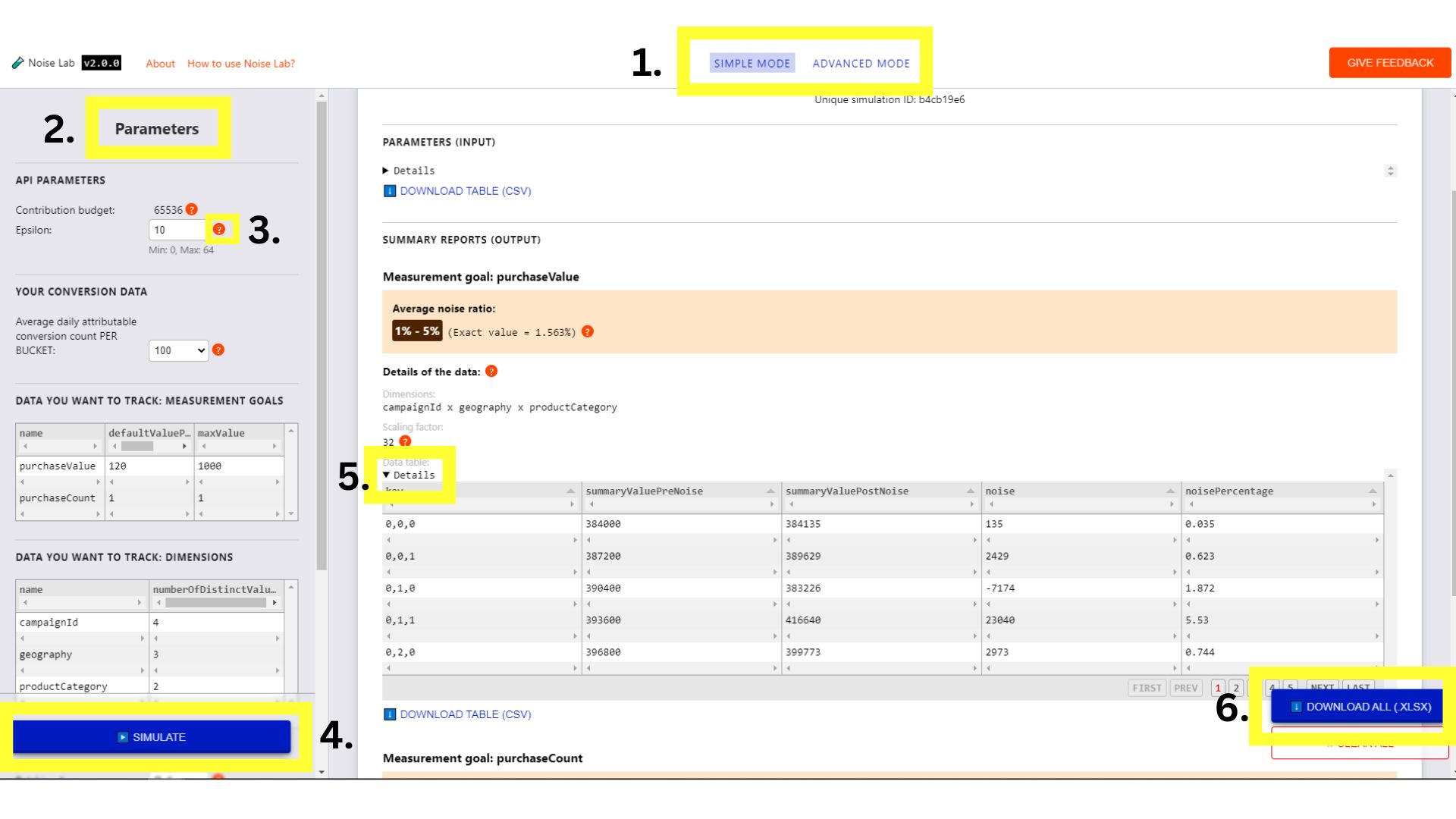
Интерфейс Noise Lab для простого режима.
Расширенный режим
- В расширенном режиме у вас больше возможностей для управления параметрами. Вы можете добавлять пользовательские цели и измерения ( № 1 и № 2 на следующем скриншоте ).
- Прокрутите вниз в разделе «Параметры» и найдите опцию «Ключевая стратегия». Ее можно использовать для тестирования различных ключевых структур ( № 3 на следующем скриншоте ).
- Чтобы протестировать различные ключевые структуры, переключите ключевую стратегию на вариант «B».
- Укажите количество различных ключевых структур, которые вы хотите использовать (по умолчанию установлено значение «2»).
- Нажмите «Сгенерировать ключевые структуры».
- Вы увидите параметры для указания структуры ключей, установив флажки рядом с ключами, которые вы хотите включить для каждой структуры ключа.
- Нажмите «Имитировать», чтобы увидеть результат.
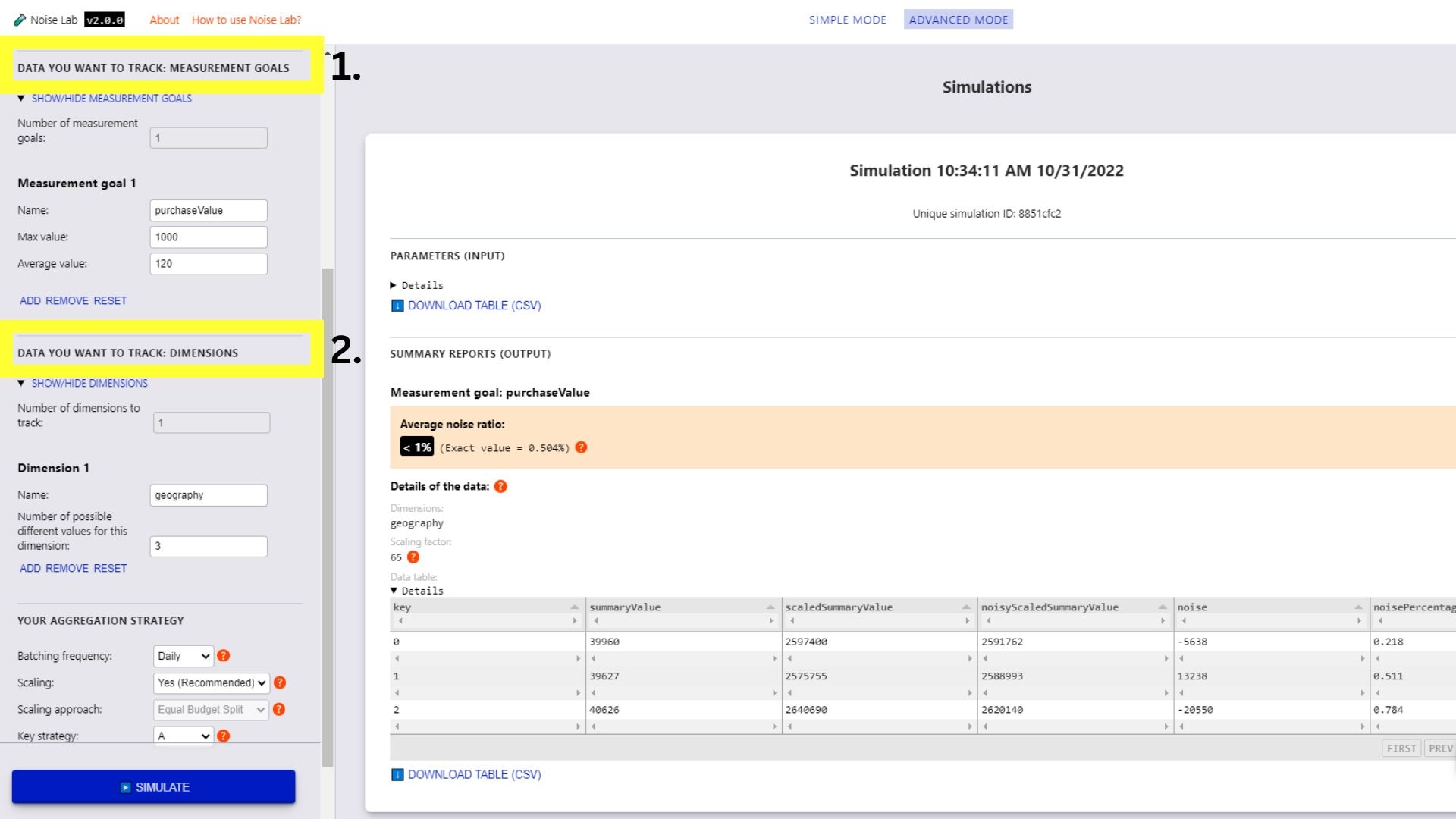
Интерфейс Noise Lab для расширенного режима. 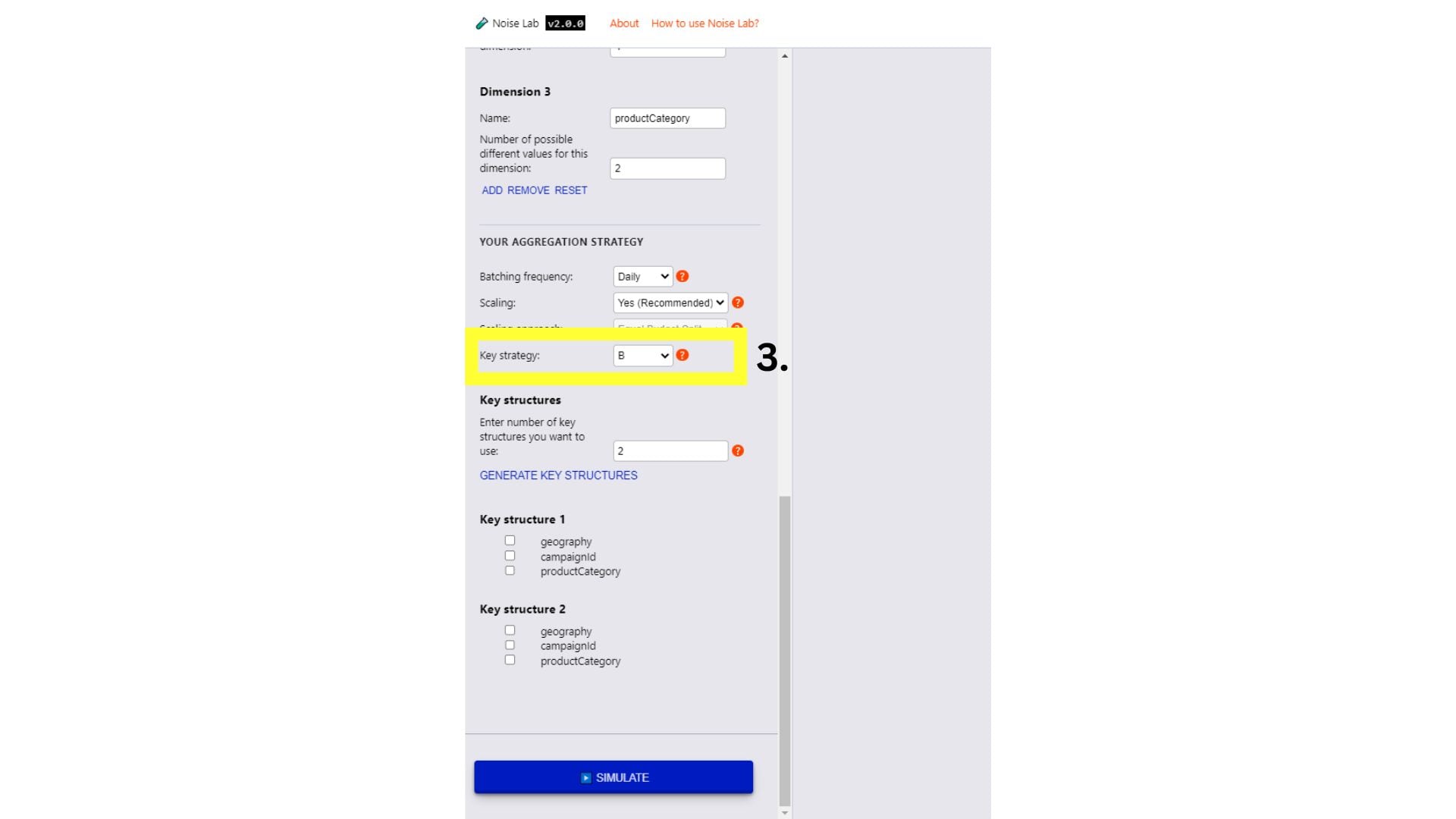
Интерфейс Noise Lab для расширенного режима.
Показатели шума
Основная концепция
Добавление шума предназначено для защиты конфиденциальности отдельных пользователей.
Высокий уровень шума указывает на то, что ячейки/ключи разрежены и содержат данные лишь от ограниченного числа конфиденциальных событий. Noise Lab автоматически обрабатывает эти данные, позволяя отдельным лицам «скрыться в толпе», или, другими словами, защищая конфиденциальность этих ограниченных групп за счет добавления большего количества шума.
Низкий уровень шума указывает на то, что структура данных была разработана таким образом, что позволяет отдельным лицам «скрываться в толпе». Это означает, что в группах содержится достаточное количество данных от различных событий, чтобы гарантировать защиту конфиденциальности отдельных пользователей.
Это утверждение справедливо как для средней процентной ошибки (APE), так и для RMSRE_T (среднеквадратичная относительная ошибка с пороговым значением).
APE (средняя процентная ошибка)
APE — это отношение шума к сигналу, то есть истинное суммарное значение.
Более низкие значения APE означают лучшее соотношение сигнал/шум.
Формула
Для данного сводного отчета показатель APE рассчитывается следующим образом:
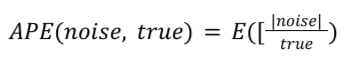
True — это истинное итоговое значение. APE — это среднее значение шума по каждому истинному итоговому значению, усредненное по всем записям в сводном отчете. В Noise Lab это значение затем умножается на 100, чтобы получить процентное значение.
Преимущества и недостатки
Использование сегментов меньшего размера оказывает непропорциональное влияние на конечное значение APE. Это может ввести в заблуждение при оценке шума. Именно поэтому мы добавили еще одну метрику, RMSRE_T, которая призвана смягчить это ограничение APE. Подробности смотрите в примерах .
Код
Проверьте исходный код для расчета APE.
RMSRE_T (среднеквадратичная относительная ошибка с пороговым значением)
RMSRE_T (среднеквадратичная относительная ошибка с пороговым значением) — это еще один показатель уровня шума.
Как интерпретировать RMSRE_T
Более низкие значения RMSRE_T означают лучшее соотношение сигнал/шум.
Например, если допустимый для вашего случая уровень шума составляет 20%, а RMSRE_T равен 0,2, вы можете быть уверены, что уровень шума попадает в допустимый диапазон.
Формула
Для заданного сводного отчета значение RMSRE_T рассчитывается следующим образом:
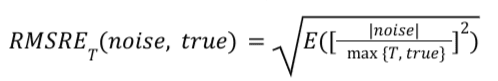
Преимущества и недостатки
RMSRE_T несколько сложнее для понимания, чем APE. Однако у него есть несколько преимуществ, которые в некоторых случаях делают его более подходящим, чем APE, для анализа шума в сводных отчетах:
- Показатель RMSRE_T более стабилен. "T" — это пороговое значение. "T" используется для того, чтобы при расчете RMSRE_T присваивать меньший вес группам с меньшим количеством конверсий, которые, следовательно, более чувствительны к шуму из-за своего небольшого размера. При использовании T, показатель не резко возрастает в группах с малым количеством конверсий. Если T равно 5, значение шума, равное 1, в группе с 0 конверсиями не будет отображаться как значительно превышающее 1. Вместо этого оно будет ограничено значением 0,2, что эквивалентно 1/5, поскольку T равно 5. Присваивая меньший вес меньшим группам, которые, следовательно, более чувствительны к шуму, этот показатель более стабилен и, следовательно, упрощает сравнение двух симуляций.
- RMSRE_T позволяет выполнять простую агрегацию. Зная RMSRE_T нескольких сегментов вместе с их истинными значениями, можно вычислить RMSRE_T их суммы. Это также позволяет оптимизировать RMSRE_T для этих объединенных значений.
Хотя агрегирование для APE возможно, формула довольно сложная, поскольку включает абсолютное значение суммы шумов Лапласа. Это затрудняет оптимизацию APE.
Код
Проверьте исходный код для расчета RMSRE_T.
Примеры
Сводный отчет, состоящий из трех разделов:
- bucket_1 = noise: 10, trueSummaryValue: 100
- bucket_2 = noise: 20, trueSummaryValue: 100
- bucket_3 = noise: 20, trueSummaryValue: 200
APE = (0,1 + 0,2 + 0,1) / 3 = 13%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,200))^2) / 3) = sqrt( (0.01 + 0.04 + 0.01) / 3) = 0.14
Сводный отчет, состоящий из трех разделов:
- bucket_1 = noise: 10, trueSummaryValue: 100
- bucket_2 = noise: 20, trueSummaryValue: 100
- bucket_3 = noise: 20, trueSummaryValue: 20
APE = (0,1 + 0,2 + 1) / 3 = 43%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,20))^2) / 3) = sqrt( (0.01 + 0.04 + 1.0) / 3) = 0.59
Сводный отчет, состоящий из трех разделов:
- bucket_1 = noise: 10, trueSummaryValue: 100
- bucket_2 = noise: 20, trueSummaryValue: 100
- bucket_3 = noise: 20, trueSummaryValue: 0
APE = (0,1 + 0,2 + Бесконечность) / 3 = Бесконечность
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,0))^2) / 3) = sqrt( (0.01 + 0.04 + 16.0) / 3) = 2.31
Расширенное управление ключами
У DSP-платформы или компании, занимающейся измерением эффективности рекламы, могут быть тысячи глобальных рекламных клиентов, представляющих различные отрасли, валюты и потенциальные цены покупки. Это означает, что создание и управление одним ключом агрегации для каждого рекламодателя, скорее всего, будет крайне непрактичным. Кроме того, будет сложно выбрать максимальное значение агрегации и бюджет агрегации, которые позволят ограничить влияние шума среди этих тысяч глобальных рекламодателей. Вместо этого рассмотрим следующие сценарии:
Ключевая стратегия А
Поставщик рекламных технологий решает создать и управлять одним ключом для всех своих рекламных клиентов. Для всех рекламодателей и всех валют диапазон покупок варьируется от небольших объемов дорогостоящих покупок до крупных объемов недорогих покупок. В результате получается следующий ключ:
| Условные обозначения (несколько валют) | |
|---|---|
| Максимальное агрегируемое значение | 5 000 000 |
| Диапазон стоимости покупки | [120 - 5000000] |
Ключевая стратегия B
Поставщик рекламных технологий решает создать и управлять двумя ключами для всех своих рекламных клиентов. Они решают разделить ключи по валютам. Для всех рекламодателей и всех валют диапазон покупок варьируется от небольших, дорогостоящих покупок до крупных, недорогих покупок. Разделяя по валютам, они создают 2 ключа:
| Ключ 1 (USD) | Ключ 2 (¥) | |
|---|---|---|
| Максимальное агрегируемое значение | 40 000 долларов | 5 000 000 иен |
| Диапазон стоимости покупки | [120 - 40,000] | [15 000 - 5 000 000] |
Ключевая стратегия B будет иметь меньший уровень шума в результатах, чем ключевая стратегия A, поскольку значения валют распределены неравномерно по валютам. Например, рассмотрим, как покупки, выраженные в иенах, вперемешку с покупками, выраженными в долларах США, изменят исходные данные и, как следствие, приведут к зашумленным результатам.
Ключевая стратегия C
Поставщик рекламных технологий решает создать и управлять четырьмя ключами для всех своих рекламных клиентов, разделяя их по валюте и отрасли рекламодателя:
| Ключ 1 (USD x Рекламодатели, размещающие рекламу элитных ювелирных изделий) | Ключ 2 (¥ x Рекламодатели элитных ювелирных изделий) | Ключ 3 (USD x Рекламодатели из числа розничных продавцов одежды) | Ключ 4 (¥ x Рекламодатели из числа розничных продавцов одежды) | |
|---|---|---|---|---|
| Максимальное агрегируемое значение | 40 000 долларов | 5 000 000 иен | 500 долларов | 65 000 иен |
| Диапазон стоимости покупки | [10 000 - 40 000] | [1 250 000 - 5 000 000] | [120 - 500] | [15 000 - 65 000] |
Ключевая стратегия C будет иметь меньший уровень шума в результатах, чем ключевая стратегия B, поскольку объемы покупок рекламодателей распределены неравномерно. Например, рассмотрим, как покупки дорогих ювелирных изделий, смешанные с покупками бейсбольных кепок, изменят исходные данные и, как следствие, приведут к появлению шума в результатах.
Рассмотрите возможность создания общих максимальных суммарных значений и общих коэффициентов масштабирования для общих параметров нескольких рекламодателей, чтобы уменьшить шум в выходных данных. Например, вы можете поэкспериментировать со следующими стратегиями для ваших рекламодателей:
- Одна стратегия, различающаяся валютой (USD, ¥, CAD и т. д.).
- Одна стратегия, различающаяся в зависимости от отрасли рекламодателя (страхование, автомобили, розничная торговля и т. д.).
- Одна стратегия, отличающаяся схожими диапазонами стоимости покупки ([100], [1000], [10000] и т. д.)
Создание ключевых стратегий, основанных на общих чертах рекламодателей, упрощает управление ключами и соответствующим кодом, а также повышает соотношение сигнала к шуму. Экспериментируйте с различными стратегиями, учитывающими общие черты рекламодателей, чтобы выявить точки перелома в вопросе максимизации влияния шума по сравнению с управлением кодом.
Рассмотрим сценарий с участием двух рекламодателей:
- Рекламодатель А:
- Для всех товаров на сайте рекламодателя А доступные цены покупки варьируются от 120 до 1000 долларов США, что составляет примерно 880 долларов США.
- Цены покупки равномерно распределены в диапазоне 880 долларов США, при этом отсутствуют выбросы, выходящие за пределы двух стандартных отклонений от медианной цены покупки.
- Рекламодатель B:
- Для всех товаров на сайте рекламодателя B доступны варианты покупки по цене от [120 до 1000 долларов США], что составляет примерно 880 долларов США.
- Цены на покупку в основном колеблются в диапазоне от 120 до 500 долларов, и лишь 5% покупок приходится на ценовой диапазон от 500 до 1000 долларов.
Учитывая требования к бюджету взносов и методологию, с помощью которой в конечные результаты вносится шум , рекламодатель B по умолчанию получит более зашумленные результаты, чем рекламодатель A, поскольку у рекламодателя B выше вероятность того, что выбросы повлияют на базовые расчеты.
Эту проблему можно смягчить с помощью специальной настройки ключа. Протестируйте ключевые стратегии, которые помогают управлять аномальными данными и более равномерно распределять суммы покупок в пределах диапазона покупок, заданного ключом.
Для рекламодателя B можно создать два отдельных ключа для фиксации двух разных диапазонов стоимости покупки. В этом примере специалист по рекламным технологиям отметил, что выбросы появляются при стоимости покупки выше 500 долларов. Попробуйте использовать два отдельных ключа для этого рекламодателя:
- Ключевая структура 1: Ключ, который фиксирует только покупки в диапазоне от 120 до 500 долларов (охватывая примерно 95% от общего объема покупок).
- Ключевая структура 2: Ключ, который фиксирует только покупки на сумму более 500 долларов (охватывает примерно 5% от общего объема покупок).
Implementing this key strategy should better manage noise for Advertiser B and help to maximize utility for them from summary reports. Given the new smaller ranges, Key A and Key B should now have a more uniform distribution of data across each respective key that for the previous single key. This will result in less noise impact in each key's output that for the previous single key.