
Основные понятия API частной агрегации
Для кого предназначен этот документ?
API частной агрегации позволяет собирать агрегированные данные из рабочих модулей, имеющих доступ к данным между сайтами. Представленные здесь концепции важны для разработчиков, создающих функции отчетности в рамках API общего хранилища и защищенной аудитории.
- Если вы разработчик, создающий систему отчетности для межсайтового измерения.
- Если вы маркетолог , специалист по анализу данных или другой пользователь сводных отчетов , понимание этих механизмов поможет вам принимать решения по проектированию для получения оптимизированного сводного отчета.
Ключевые термины
Перед прочтением этого документа полезно ознакомиться с ключевыми терминами и понятиями. Каждый из этих терминов будет подробно описан здесь.
- Ключ агрегации (также известный как «корзина») — это заранее определённый набор точек данных. Например, вы можете захотеть собрать корзину данных о местоположении, где браузер сообщает название страны. Ключ агрегации может содержать более одного измерения (например, страну и идентификатор вашего виджета контента).
- Агрегируемое значение — это отдельная точка данных, объединенная в ключ агрегации. Если вы хотите измерить, сколько пользователей из Франции просмотрели ваш контент, то
Franceявляется измерением в ключе агрегации, аviewCountравное1— это агрегируемое значение. - Агрегируемые отчеты генерируются и шифруются в браузере. Для API частной агрегации это содержит данные об одном событии.
- Сервис агрегации обрабатывает данные из сводных отчетов для создания итогового отчета.
- Итоговый результат работы сервиса агрегации — это сводный отчет , содержащий агрегированные данные о пользователях с ошибками и подробные данные о конверсиях.
- Ворлет — это элемент инфраструктуры, позволяющий запускать определенные функции JavaScript и возвращать информацию запрашивающему. Внутри ворлета можно выполнять JavaScript, но нельзя взаимодействовать или обмениваться данными с внешней страницей.
Рабочий процесс частной агрегации
При вызове API частной агрегации с ключом агрегации и агрегируемым значением браузер генерирует агрегируемый отчет. Отчеты отправляются на ваш сервер, который обрабатывает их пакетами. Пакетные отчеты обрабатываются позже службой агрегации, и генерируется сводный отчет.
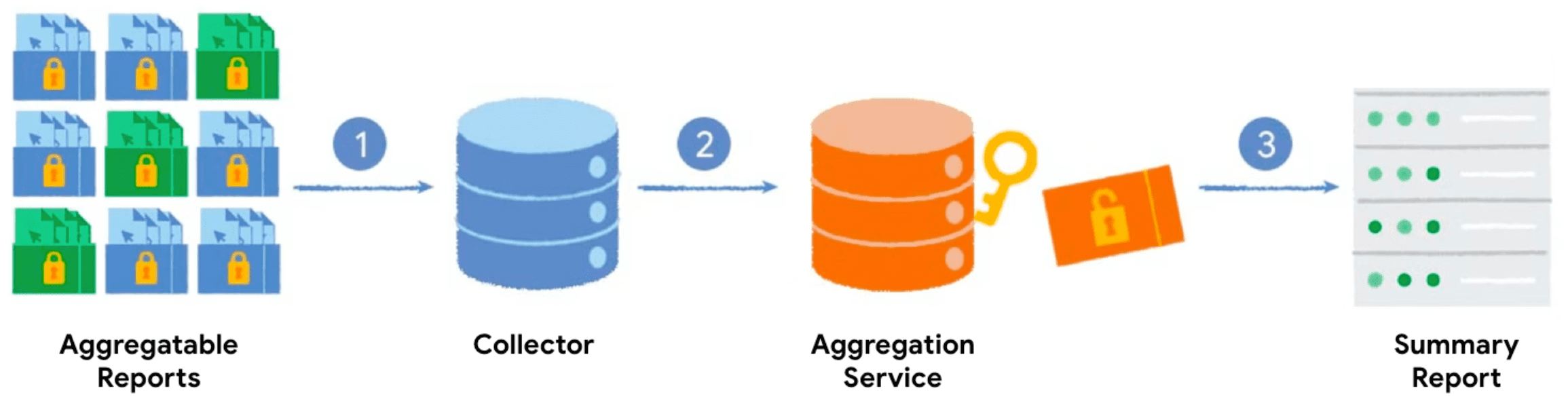
- При вызове API частной агрегации клиент (браузер) генерирует и отправляет агрегируемый отчет на ваш сервер для сбора данных.
- Ваш сервер собирает отчеты от клиентов и объединяет их в пакеты для отправки в службу агрегации.
- Собрав достаточное количество отчетов, вы объедините их в пакет и отправите в службу агрегации, работающую в доверенной среде выполнения, для генерации сводного отчета.
Описанный в этом разделе рабочий процесс аналогичен API для отчетов по атрибуции . Однако отчеты по атрибуции связывают данные, собранные в результате показа и конверсии, которые происходят в разное время. Частная агрегация измеряет одно событие, затрагивающее несколько сайтов.
Ключ агрегации
Агрегационный ключ (сокращенно «ключ») представляет собой область, в которой будут накапливаться агрегируемые значения. В ключ можно закодировать одно или несколько измерений. Измерение представляет собой какой-либо аспект, по которому вы хотите получить более подробную информацию, например, возрастную группу пользователей или количество показов рекламной кампании.
Например, у вас может быть виджет, встроенный на нескольких сайтах, и вы хотите проанализировать страну пользователей, которые его видели. Вы хотите ответить на такие вопросы, как: «Сколько пользователей, которые видели мой виджет, из страны X?» Чтобы получить ответ на этот вопрос, вы можете настроить ключ агрегации, который кодирует два параметра: идентификатор виджета и идентификатор страны.
Ключ, передаваемый в API частной агрегации, представляет собой тип BigInt , состоящий из нескольких измерений. В этом примере измерениями являются идентификатор виджета и идентификатор страны. Допустим, идентификатор виджета может состоять до 4 цифр, например, 1234 , а каждая страна соответствует числу в алфавитном порядке, например, Афганистан — 1 , Франция — 61 , а Зимбабве — 195 Таким образом, агрегируемый ключ будет состоять из 7 цифр, где первые 4 символа зарезервированы для WidgetID , а последние 3 — для идентификатора CountryID .
Допустим, ключ представляет собой количество пользователей из Франции (идентификатор страны 061 ), которые видели виджет с идентификатором 3276 Ключ агрегации — 3276061 .
| Ключ агрегации | |
| Идентификатор виджета | Идентификатор страны |
| 3276 | 061 |
Ключ агрегации также может быть сгенерирован с помощью механизма хеширования, например, SHA-256 . Например, строку {"WidgetId":3276,"CountryID":67} можно хешировать, а затем преобразовать в значение BigInt размером 42943797454801331377966796057547478208888578253058197330928948081739249096287n . Если значение хеша содержит более 128 бит, его можно усечь, чтобы убедиться, что оно не превысит максимально допустимое значение сегмента 2^128−1 .
В рамках рабочего модуля Shared Storage вы можете получить доступ к модулям crypto и TextEncoder , которые помогут вам сгенерировать хеш. Чтобы узнать больше о генерации хеша, ознакомьтесь с SubtleCrypto.digest() на MDN .
В следующем примере показано, как сгенерировать ключ корзины из хешированного значения:
async function convertToBucket(data) {
// Encode as UTF-8 Uint8Array
const encodedData = new TextEncoder().encode(data);
// Generate SHA-256 hash
const hashBuffer = await crypto.subtle.digest('SHA-256', encodedData);
// Truncate the hash
const truncatedHash = Array.from(new Uint8Array(hashBuffer, 0, 16));
// Convert the byte sequence to a decimal
return truncatedHash.reduce((acc, curr) => acc * 256n + BigInt(curr), 0n);
}
const data = {
WidgetId: 3276,
CountryID: 67
};
const dataString = JSON.stringify(data);
const bucket = await convertToBucket(dataString);
console.log(bucket); // 126200478277438733997751102134640640264n
Совокупная стоимость
Агрегируемые значения суммируются по каждому ключу для множества пользователей, чтобы получить сводные данные в виде итоговых отчетов.
Теперь вернёмся к ранее заданному примеру вопроса: «Сколько пользователей, которые видели мой виджет, из Франции?» Ответ на этот вопрос будет выглядеть примерно так: «Приблизительно 4881 пользователь, которые видели мой виджет с ID 3276, из Франции». Агрегируемое значение равно 1 для каждого пользователя, а «4881 пользователь» — это агрегированное значение , которое является суммой всех агрегируемых значений для этого ключа агрегации .
| Ключ агрегации | Совокупная стоимость | |
| Идентификатор виджета | Идентификатор страны | Количество просмотров |
| 3276 | 061 | 1 |
В этом примере мы увеличиваем значение на 1 для каждого пользователя, который видит виджет. На практике агрегируемое значение можно масштабировать для улучшения отношения сигнал/шум .
Бюджет взносов
Каждый вызов API частной агрегации называется вкладом . Для защиты конфиденциальности пользователей количество вкладов, которые могут быть собраны от одного человека, ограничено.
При суммировании всех агрегируемых значений по всем ключам агрегации сумма должна быть меньше бюджета вклада. Бюджет устанавливается для каждого источника рабочего процесса, на каждый день, и является отдельным для рабочих процессов Protected Audience API и Shared Storage. Для расчета бюджета используется скользящее окно, охватывающее приблизительно последние 24 часа. Если создание нового агрегируемого отчета приведет к превышению бюджета, отчет не будет создан.
Бюджет взносов представлен параметром L 1 и установлен на уровне 2 16 (65 536) за десять минут в день с резервом в 2 20 (1 048 576). Подробнее об этих параметрах см. пояснение .
Значение бюджета вклада произвольно, но шум масштабируется в соответствии с ним. Вы можете использовать этот бюджет для максимизации отношения сигнал/шум для суммарных значений (подробнее об этом в разделе «Шум и масштабирование »).
Чтобы узнать больше о бюджетах взносов, ознакомьтесь с пояснением . Также обратитесь к разделу «Бюджет взносов» для получения дополнительной информации.
Лимит взносов на один отчет
В зависимости от вызывающей стороны, лимит вкладов может отличаться, и для Shared Storage эти лимиты являются значениями по умолчанию, которые можно изменить . В настоящее время отчеты, создаваемые для вызывающих сторон API Shared Storage, ограничены 20 вкладами на отчет. С другой стороны, для вызывающих сторон API Protected Audience лимит составляет 100 вкладов на отчет. Эти ограничения были выбраны для того, чтобы сбалансировать количество вкладов, которые можно встроить, с размером полезной нагрузки.
В случае общего хранилища взносы, внесенные в рамках одной операции run() или selectURL() объединяются в один отчет. В случае защищенной аудитории взносы, внесенные одним источником в рамках аукциона, объединяются в один отчет.
Взносы с отступами
Дополнительные данные о вкладах корректируются с помощью функции заполнения. Заполнение полезной нагрузки защищает информацию об истинном количестве вкладов, содержащихся в агрегируемом отчете. Заполнение дополняет полезную нагрузку null данными (т.е. значениями 0) до достижения фиксированной длины.
Агрегируемые отчеты
После того, как пользователь вызывает API частной агрегации, браузер генерирует агрегируемые отчеты, которые позже обрабатываются службой агрегации для создания сводных отчетов . Агрегируемый отчет имеет формат JSON и содержит зашифрованный список вкладов, каждый из которых представляет собой пару {aggregation key, aggregatable value} . Агрегируемые отчеты отправляются со случайной задержкой до одного часа.
Внесенные данные зашифрованы и недоступны для чтения за пределами службы агрегации. Служба агрегации расшифровывает отчеты и генерирует сводный отчет. Ключ шифрования для браузера и ключ расшифровки для службы агрегации выдаются координатором, который выступает в качестве службы управления ключами. Координатор хранит список двоичных хешей образа службы для проверки того, что вызывающая сторона имеет право получить ключ расшифровки.
Пример сводного отчета с включенным режимом отладки :
"aggregation_service_payloads": [
{
"debug_cleartext_payload": "omRkYXRhgaJldmFsdWVEAAAAgGZidWNrZXRQAAAAAAAAAAAAAAAAAAAE0mlvcGVyYXRpb25paGlzdG9ncmFt",
"key_id": "2cc72b6a-b92f-4b78-b929-e3048294f4d6",
"payload": "a9Mk3XxvnfX70FsKrzcLNZPy+00kWYnoXF23ZpNXPz/Htv1KCzl/exzplqVlM/wvXdKUXCCtiGrDEL7BQ6MCbQp1NxbWzdXfdsZHGkZaLS2eF+vXw2UmLFH+BUg/zYMu13CxHtlNSFcZQQTwnCHb"
}
],
"debug_key": "777",
"shared_info": "{\"api\":\"shared-storage\",\"debug_mode\":\"enabled\",\"report_id\":\"5bc74ea5-7656-43da-9d76-5ea3ebb5fca5\",\"reporting_origin\":\"https://localhost:4437\",\"scheduled_report_time\":\"1664907229\",\"version\":\"0.1\"}"
Сводные отчеты можно просмотреть на странице chrome://private-aggregation-internals :

В целях тестирования можно использовать кнопку «Отправить выбранные отчеты», чтобы немедленно отправить отчет на сервер.
Собирать и объединять в пакеты агрегируемые отчеты.
Браузер отправляет агрегируемые отчеты в источник рабочего модуля, содержащего вызов частного API агрегации, используя указанный общеизвестный путь:
- Для общего хранилища:
/.well-known/private-aggregation/report-shared-storage - Для защищенной аудитории:
/.well-known/private-aggregation/report-protected-audience
На этих конечных точках вам потребуется запустить сервер, выступающий в роли сборщика данных, который будет получать сводные отчеты, отправляемые клиентами.
Затем сервер должен сформировать пакет отчетов и отправить его в службу агрегации. Пакеты должны создаваться на основе информации, содержащейся в незашифрованном содержимом агрегируемого отчета, например, в поле shared_info . В идеале каждый пакет должен содержать 100 или более отчетов.
Вы можете настроить пакетную обработку отчетов на ежедневной или еженедельной основе. Эта стратегия является гибкой, и вы можете изменить свою стратегию пакетной обработки для конкретных событий, когда ожидаете большего объема — например, для дней года, когда ожидается больше показов. Пакеты должны включать отчеты из одной и той же версии API, источника отчетов и запланированного времени создания отчета.
Идентификаторы фильтров
API и сервис частной агрегации позволяют использовать идентификаторы фильтрации для обработки данных на более детальном уровне, например, по каждой рекламной кампании, вместо обработки результатов в более крупных запросах.
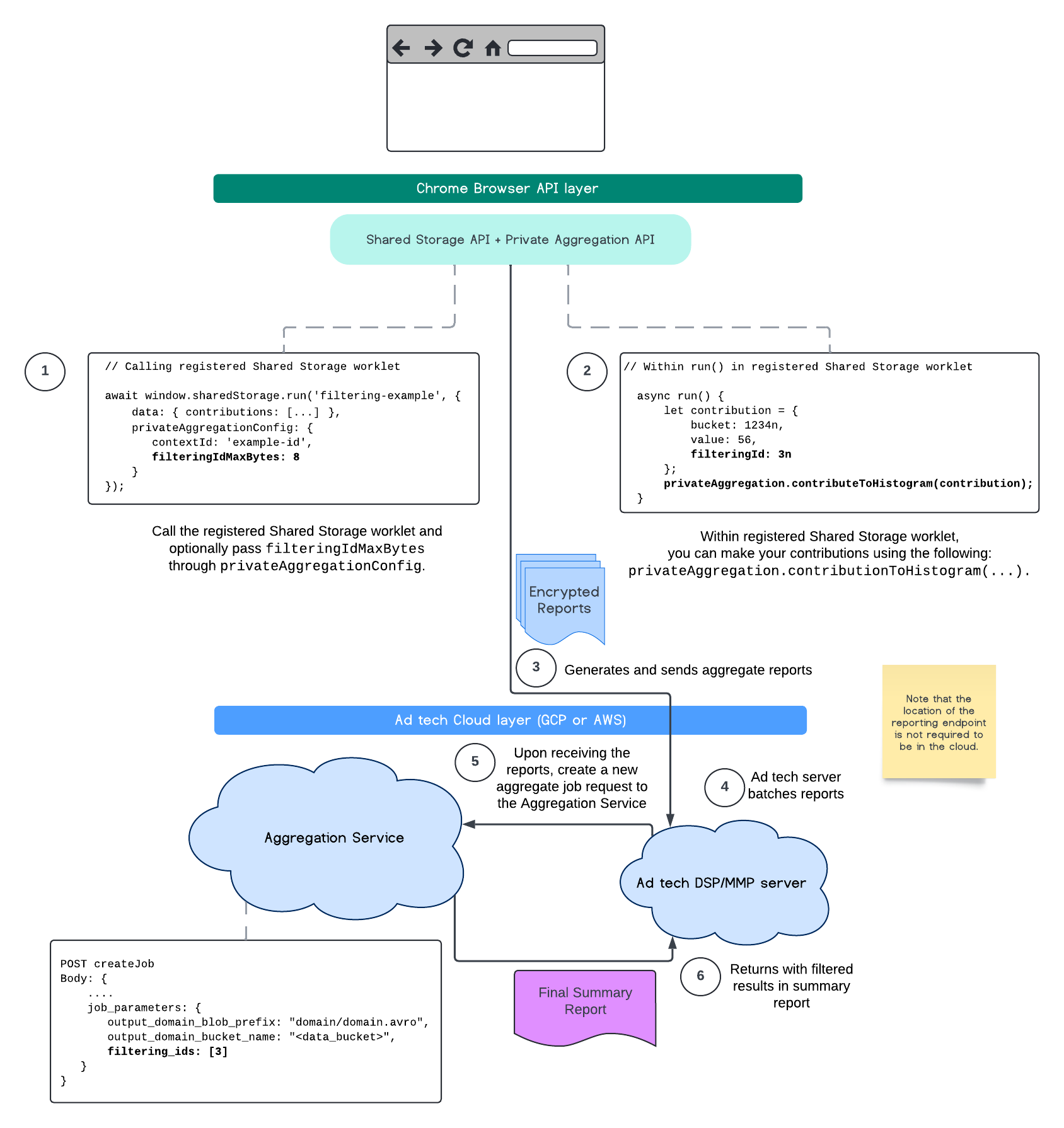
Чтобы начать использовать это уже сегодня, вот несколько примерных шагов, которые можно применить к вашей текущей реализации.
Этапы работы с общим хранилищем
Если вы используете API общего хранилища в своем рабочем процессе:
Определите место объявления и запуска нового модуля общего хранилища. В следующем примере мы назвали файл модуля
filtering-worklet.jsи зарегистрировали его в папкеfiltering-example.(async function runFilteringIdsExample () { await window.sharedStorage.worklet.addModule('filtering-worklet.js'); await window.sharedStorage.run('filtering-example', { keepAlive: true, privateAggregationConfig: { contextId: 'example-id', filteringIdMaxBytes: 8 // optional } }}); })();Обратите внимание, что
filteringIdMaxBytesнастраивается для каждого отчета и, если не задан, по умолчанию принимает значение 1. Это значение по умолчанию предотвращает ненужное увеличение размера полезной нагрузки и, следовательно, затрат на хранение и обработку. Подробнее см. в пояснении к гибкому вкладу .В
filtering-worklet.js, при передаче параметра contribution в методprivateAggregation.contributeToHistogram(...)в рамках рабочего процесса Shared Storage, можно указать идентификатор фильтрации.// Within filtering-worklet.js class FilterOperation { async run() { let contributions = [{ bucket: 1234n, value: 56, filteringId: 3n // defaults to 0n if not assigned, type bigint }]; for (const c of contributions) { privateAggregation.contributeToHistogram(c); } … } }); register('filtering-example', FilterOperation);Агрегируемые отчеты будут отправляться по указанной вами конечной точке
/.well-known/private-aggregation/report-shared-storage. Перейдите к руководству по идентификаторам фильтрации, чтобы узнать о необходимых изменениях в параметрах задания службы агрегации.
После завершения пакетной обработки и отправки результатов в развернутую вами службу агрегации, отфильтрованные результаты должны отразиться в итоговом сводном отчете.
Этапы защиты аудитории
Если вы используете API защищенной аудитории в своем рабочем процессе:
В вашей текущей реализации Protected Audience вы можете настроить следующие параметры для подключения к Private Aggregation. В отличие от Shared Storage, пока невозможно настроить максимальный размер идентификатора фильтрации. По умолчанию максимальный размер идентификатора фильтрации составляет 1 байт и будет установлен на
0n. Имейте в виду, что эти параметры будут устанавливаться в ваших функциях отчетности Protected Audience (например,reportResult()илиgenerateBid()).const contribution = { ... filteringId: 0n }; privateAggregation.contributeToHistogram(contribution);Агрегируемые отчеты будут отправляться по указанной вами конечной точке
/.well-known/private-aggregation/report-protected-audience. После завершения пакетной обработки и отправки в развернутую вами службу агрегации отфильтрованные результаты должны отразиться в итоговом сводном отчете. Ниже представлены пояснения к API Attribution Reporting и Private Aggregation API, а также первоначальное предложение.
Перейдите к руководству по фильтрации идентификаторов в службе агрегации или к разделам API отчетов по атрибуции для получения более подробной информации.
Сервис агрегации
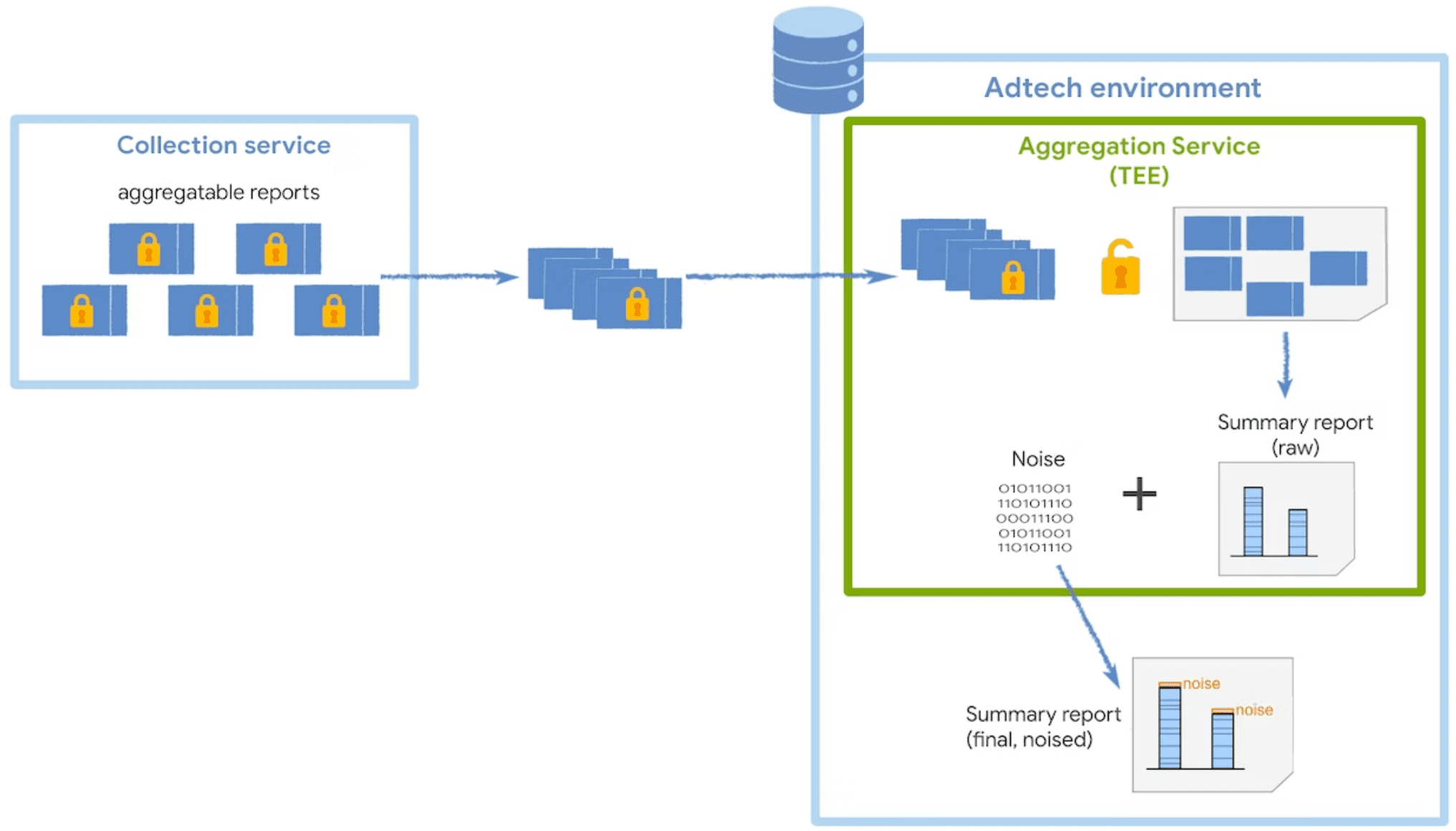
Служба агрегации получает зашифрованные агрегируемые отчеты от сборщика и генерирует сводные отчеты. Дополнительные рекомендации по пакетной обработке агрегируемых отчетов в вашем сборщике см. в нашем руководстве по пакетной обработке .
Сервис работает в доверенной среде выполнения (TEE), которая обеспечивает определенный уровень гарантии целостности данных, конфиденциальности данных и целостности кода. Если вы хотите подробнее узнать о том, как координаторы используются вместе с TEE, ознакомьтесь с информацией об их роли и назначении .
Сводные отчеты
Сводные отчеты позволяют просмотреть собранные данные с учетом шума. Вы можете запросить сводные отчеты для заданного набора ключей.
Сводный отчет содержит набор пар «ключ-значение» в формате словаря JSON. Каждая пара содержит:
-
bucket: ключ агрегации в виде двоичной числовой строки. Если используется ключ агрегации "123", то bucket будет равен "1111011". -
value: суммарное значение для заданной цели измерения, полученное путем суммирования данных из всех доступных агрегируемых отчетов с добавлением шума.
Например:
[
{"bucket":` `"111001001",` `"value":` `"2558500"},
{"bucket":` `"111101001",` `"value":` `"3256211"},
{"bucket":` `"111101001",` `"value":` `"6536542"},
]
Шум и масштабирование
Для обеспечения конфиденциальности пользователей служба агрегации добавляет шум к каждому сводному значению при каждом запросе сводного отчета. Значения шума выбираются случайным образом из распределения вероятностей Лапласа . Хотя вы не можете напрямую контролировать способы добавления шума, вы можете повлиять на его воздействие на данные измерений.
Распределение шума остается одинаковым независимо от суммы всех суммируемых значений. Следовательно, чем выше суммируемые значения, тем меньше вероятность воздействия шума.
Например, предположим, что распределение шума имеет стандартное отклонение 100 и центрировано в нуле. Если собранное агрегируемое значение отчета (или «агрегируемое значение») составляет всего 200, то стандартное отклонение шума будет составлять 50% от агрегированного значения. Но если агрегируемое значение равно 20 000, то стандартное отклонение шума составит всего 0,5% от агрегированного значения. Таким образом, агрегируемое значение 20 000 будет иметь гораздо более высокое отношение сигнал/шум.
Таким образом, умножение агрегируемого значения на масштабирующий коэффициент может помочь уменьшить шум. Масштабирующий коэффициент показывает, насколько вы хотите масштабировать данное агрегируемое значение.

Увеличение значений за счет выбора большего коэффициента масштабирования снижает относительный уровень шума. Однако это также приводит к тому, что сумма всех взносов по всем категориям быстрее достигает лимита бюджета взносов. Уменьшение значений за счет выбора меньшего коэффициента масштабирования увеличивает относительный уровень шума, но снижает риск достижения лимита бюджета.
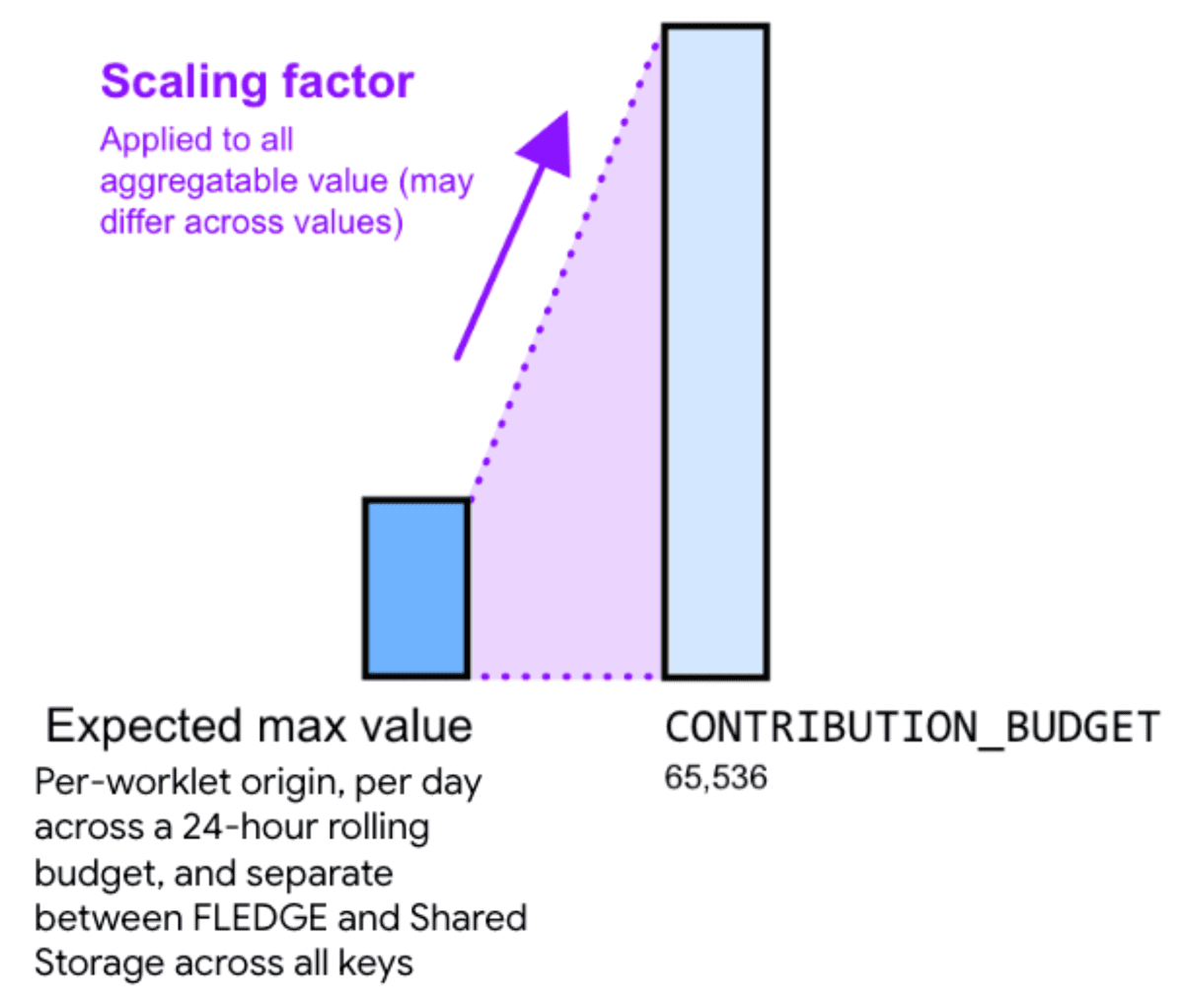
Для расчета соответствующего коэффициента масштабирования разделите бюджет взносов на максимальную сумму агрегируемых значений по всем ключам.
Для получения более подробной информации ознакомьтесь с документацией по бюджету взносов .
Принимайте участие и делитесь отзывами.
API для частной агрегации данных находится в стадии активного обсуждения и может быть изменен в будущем. Если вы попробуете этот API и у вас появятся отзывы, мы будем рады их услышать.
- GitHub : Прочитайте пояснение , задавайте вопросы и участвуйте в обсуждении .