
Узнайте, что такое шум, где он возникает и как влияет на ваши измерения.
Сводные отчеты являются результатом агрегирования агрегируемых отчетов . Когда агрегируемые отчеты объединяются в пакеты сборщиком и обрабатываются службой агрегирования, к полученным сводным отчетам добавляется шум — случайное количество данных. Шум добавляется для защиты конфиденциальности пользователей. Цель этого механизма — создать структуру, способную поддерживать измерения с дифференцированной конфиденциальностью .
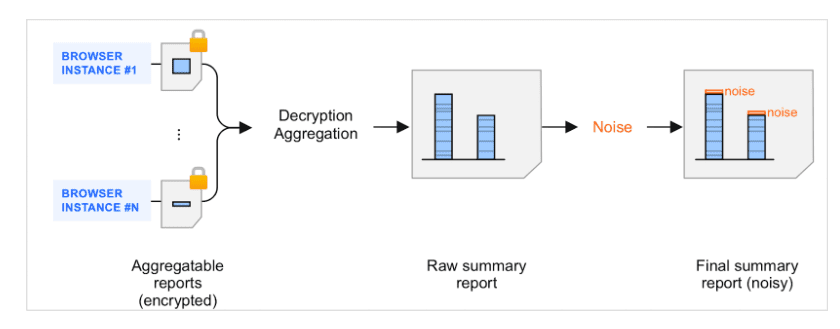
Введение в проблему шума в сводных отчетах
Хотя добавление шума сегодня обычно не входит в методику измерения эффективности рекламы, во многих случаях добавленный шум существенно не изменит интерпретацию результатов.
Полезно будет представить это следующим образом: были бы вы уверены в принятии решения на основе определенных данных, если бы эти данные не содержали шума?
Например, будет ли рекламодатель уверен в необходимости изменения стратегии или бюджета своей рекламной кампании, основываясь на том факте, что кампания А принесла 15 конверсий, а кампания Б — 16?
Если ответ отрицательный, то шум не имеет значения.
Вам потребуется настроить использование API следующим образом:
- Ответ на этот вопрос — да.
- Шум в данных подавляется таким образом, чтобы он не оказывал существенного влияния на вашу способность принимать решения на основе определенных данных. Подход может быть следующим: для достижения ожидаемого минимального количества конверсий вы хотите поддерживать уровень шума в собираемых показателях ниже определенного процента.
В этом и последующих разделах мы изложим стратегии достижения цели 2.
Основные концепции
Сервис агрегации добавляет шум один раз к каждому сводному значению — то есть один раз для каждого ключа — каждый раз, когда запрашивается сводный отчет.
Эти значения шума выбираются случайным образом из определенного вероятностного распределения следующим образом.
Все факторы, влияющие на уровень шума, основаны на двух основных концепциях.
Распределение шума ( подробности ниже ) одинаково независимо от значения суммарного параметра, будь оно низким или высоким. Следовательно, чем выше суммарное значение, тем меньшее влияние шума, вероятно, будет оказываться по сравнению с этим значением.
Например, предположим, что как общая сумма покупок в размере 20 000 долларов, так и общая сумма покупок в размере 200 долларов подвергаются воздействию шума, выбранного из одного и того же распределения.
Предположим, что уровень шума в этом распределении изменяется примерно в диапазоне от -100 до +100.
- При суммарной стоимости покупки в 20 000 долларов уровень шума колеблется от 0 до 100/20 000 = 0,5% .
- При суммарной стоимости покупки в 200 долларов уровень шума колеблется от 0 до 100/200 = 50% .
Следовательно, шум, вероятно, окажет меньшее влияние на общую стоимость покупки в 20 000 долларов, чем на стоимость в 200 долларов. Сравнительно говоря, 20 000 долларов, скорее всего, будут менее «шумными», то есть, вероятно, будут иметь более высокое соотношение сигнал/шум.
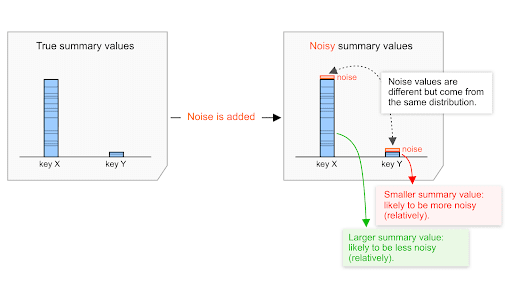
Более высокие суммарные значения оказывают относительно меньшее влияние на уровень шума. Это имеет несколько важных практических последствий, которые описаны в следующем разделе. Этот механизм является частью архитектуры API, и его практические последствия носят долгосрочный характер. Он будет продолжать играть важную роль при разработке и оценке различных стратегий агрегации рекламных технологий.
Хотя шум берется из одного и того же распределения независимо от суммарного значения, это распределение зависит от нескольких параметров. Один из этих параметров, эпсилон , может быть изменен специалистами по рекламным технологиям во время завершившегося пробного периода для оценки различных корректировок полезности/конфиденциальности. Однако рассматривайте возможность изменения эпсилона как временную. Мы будем рады вашим отзывам о ваших сценариях использования и значениях эпсилона, которые работают хорошо.
Хотя компания, занимающаяся рекламными технологиями, не контролирует напрямую способы добавления шума, она может влиять на его воздействие на данные измерений. В следующих разделах мы подробно рассмотрим, как можно влиять на шум на практике.
Прежде чем это сделать, давайте подробнее рассмотрим способ применения шума.
Приближение к сути: как применяется шум.
Одно распределение шума
Шум берется из распределения Лапласа со следующими параметрами:
- Среднее значение (
μ) равно 0. Это означает, что наиболее вероятное значение шума равно 0 (шум не добавлен), и что вероятность того, что значение шума будет меньше исходного, так же высока, как и вероятность того, что оно будет больше исходного (это иногда называют несмещенным ). - Параметр масштаба
b = CONTRIBUTION_BUDGET/epsilon.-
CONTRIBUTION_BUDGETопределен в браузере. - В сервисе агрегации используется
epsilon.
-
На следующей диаграмме показана функция плотности вероятности для распределения Лапласа с μ=0, b = 20:
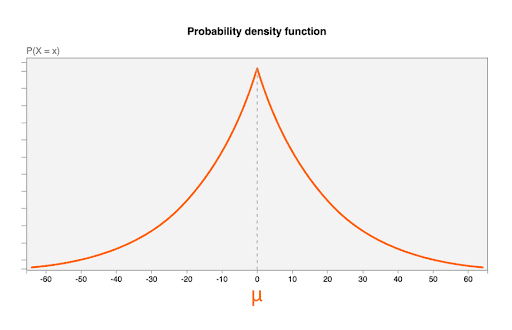
Значения случайного шума, одно распределение шума
Предположим, что компания, занимающаяся рекламными технологиями, запрашивает сводные отчеты по двум агрегационным ключам: key1 и key2.
Сервис агрегации выбирает два значения шума x1 и x2, следуя одному и тому же распределению шума . x1 добавляется к суммарному значению для ключа 1, а x2 — к суммарному значению для ключа 2.
На диаграммах мы будем представлять значения шума как одинаковые. Это упрощение; в действительности значения шума будут различаться, поскольку они выбираются случайным образом из распределения.
Это показывает, что все значения шума происходят из одного и того же распределения и не зависят от суммарного значения, к которому они применяются.
Другие свойства шума
К каждому значению сводки, включая пустые (0), применяется шум.
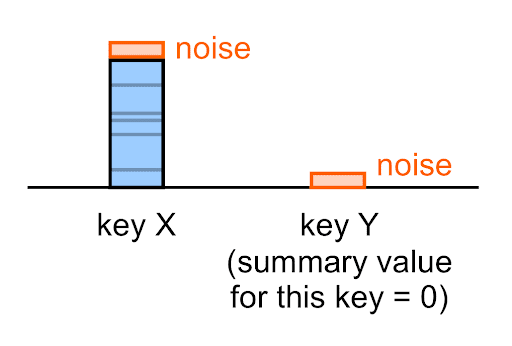
Например, даже если истинное суммарное значение для данного ключа равно 0, то некорректное суммарное значение, которое вы увидите в сводном отчете для этого ключа, (скорее всего) не будет равно 0.
Шум может быть как положительным, так и отрицательным числом.
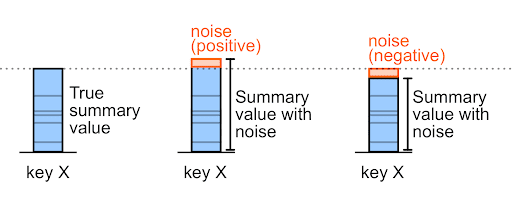
Например, при предварительной покупке 327 000 единиц шума значение шума может составлять +6000 или -6000 (это произвольные примерные значения).
Оценка шума
Вычисление стандартного отклонения шума
Стандартное отклонение шума составляет:
b*sqrt(2) = (CONTRIBUTION_BUDGET / epsilon)*sqrt(2)
Пример
При значении эпсилон = 10 стандартное отклонение шума составляет:
b*sqrt(2) = (CONTRIBUTION_BUDGET / epsilon)*sqrt(2) = (65,536/10)*sqrt(2) = 9,267
Оценка того, когда различия в измерениях являются существенными.
Поскольку вам будет известно стандартное отклонение шума, добавленного к каждому значению, выдаваемому службой агрегации, вы сможете определить соответствующие пороговые значения для сравнения, чтобы определить, могут ли наблюдаемые различия быть вызваны шумом.
Например, если добавленный к значению шум составляет приблизительно +/- 10 (с учетом масштабирования), а разница в значении между двумя кампаниями превышает 100, то, вероятно, можно с уверенностью заключить, что разница в измеренном значении между кампаниями обусловлена не только шумом.
Привлекайте и делитесь отзывами
Вы можете принять участие и поэкспериментировать с этим API .
- Узнайте об агрегируемых отчетах и сервисе агрегации , задавайте вопросы и предлагайте отзывы.
- Ознакомьтесь с руководствами по созданию отчетов об атрибуции .
Следующие шаги
- Чтобы узнать, какие переменные можно контролировать для улучшения отношения сигнал/шум, обратитесь к разделу «Работа с шумом» .
- Ознакомьтесь с вариантами дизайна сводных отчетов и поэкспериментируйте с ними , чтобы получить помощь в планировании стратегий составления сводных отчетов.
- Попробуйте лабораторию шума .