
Sobre este documento
Ao ler este documento, você vai:
- Entenda quais estratégias criar antes de gerar relatórios de resumo.
- Conheça o Noise Lab, uma ferramenta que ajuda a entender os efeitos de vários parâmetros de ruído e permite explorar e avaliar rapidamente várias estratégias de gerenciamento de ruído.
Envie feedback
Este documento resume alguns princípios para trabalhar com relatórios de resumo, mas há várias abordagens para o gerenciamento de ruído que podem não estar refletidas aqui. Suas sugestões, adições e perguntas são bem-vindas.
- Para dar feedback público sobre estratégias de gerenciamento de ruído, utilidade ou privacidade da API (épsilon) e compartilhar suas observações ao simular com o Noise Lab: Comente este problema
- Para dar feedback público sobre outro aspecto da API: Crie um novo problema aqui
Antes de começar
- Leia Attribution Reporting: relatórios de resumo e Visão geral completa do sistema da Attribution Reporting para uma introdução.
- Leia Entender o ruído e Entender as chaves de agregação para aproveitar ao máximo este guia.
Decisões de design
Princípio fundamental de design
Há diferenças fundamentais entre como os cookies de terceiros e os relatórios de resumo funcionam. Uma diferença importante é o ruído adicionado aos dados de medição nos relatórios de resumo. Outra é como os relatórios são programados.
Para acessar dados de medição de relatórios de resumo com proporções sinal-ruído mais altas, as plataformas de demanda (DSPs) e os provedores de medição de anúncios precisam trabalhar com os anunciantes para desenvolver estratégias de gerenciamento de ruído. Para desenvolver essas estratégias, as DSPs e os provedores de medição precisam tomar decisões de design. Essas decisões giram em torno de um conceito essencial:
Embora a distribuição dos valores de ruído dependa, em termos absolutos, apenas de dois parâmetros (epsilon e o orçamento de contribuição), você tem vários outros controles à sua disposição que afetam as taxas de relação sinal-ruído dos dados de medição de saída.
Embora esperemos que um processo iterativo leve às melhores decisões, cada variação delas vai resultar em uma implementação ligeiramente diferente. Portanto, essas decisões precisam ser tomadas antes de escrever cada iteração de código e antes de veicular anúncios.
Decisão: granularidade da dimensão
Teste no Noise Lab
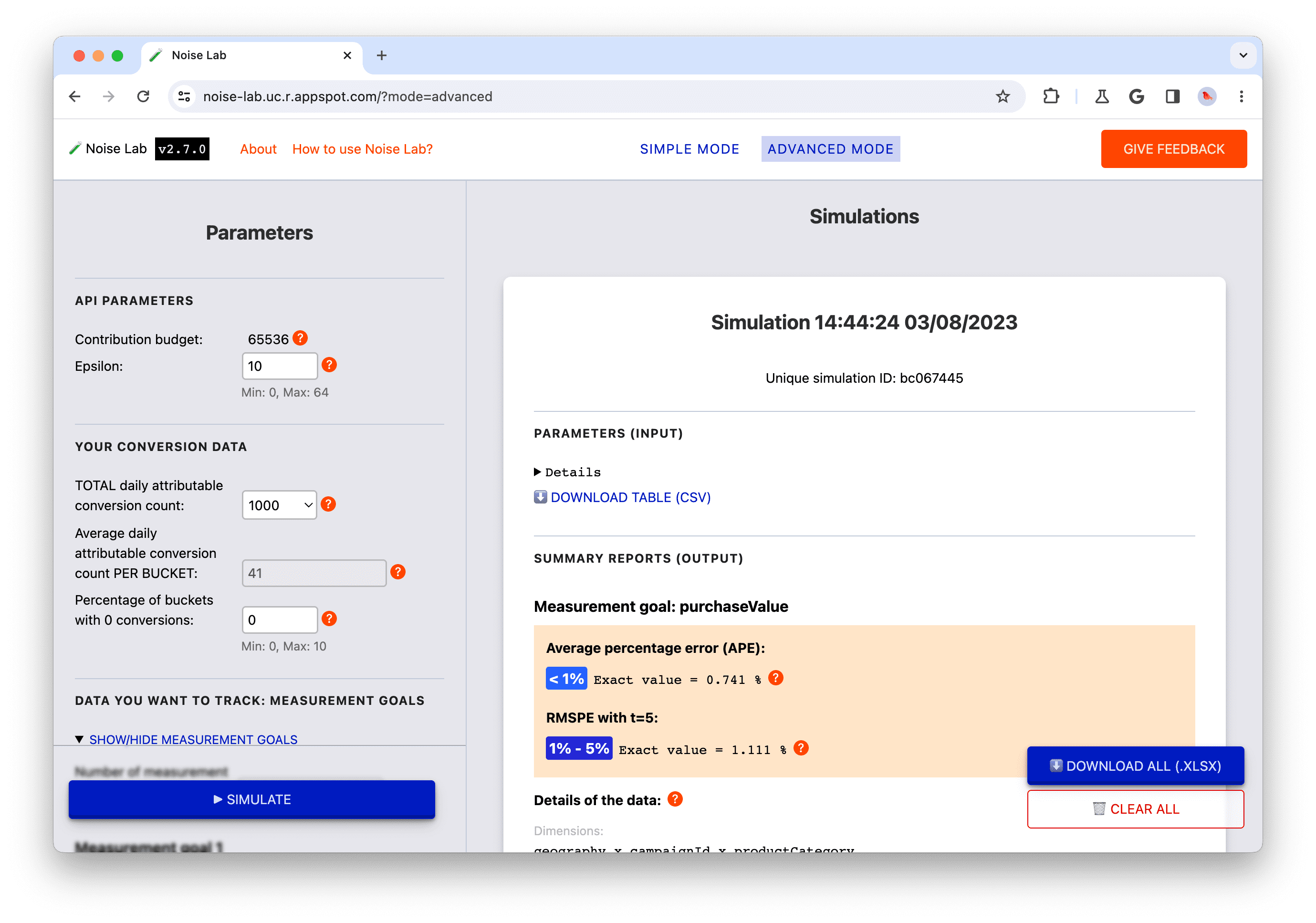
- Acesse o modo avançado.
- No painel lateral "Parâmetros", procure "Seus dados de conversão".
- Observe os parâmetros padrão. Por padrão, a contagem TOTAL diária de conversões atribuíveis é de 1.000. Isso dá uma média de aproximadamente 40 por bucket se você usar a configuração padrão (dimensões padrão, número padrão de valores diferentes possíveis para cada dimensão, estratégia de chave A). Observe que o valor é 40 na entrada "Contagem de conversões diárias atribuíveis médias POR BUCKET".
- Clique em "Simular" para executar uma simulação com os parâmetros padrão.
- No painel lateral "Parâmetros", procure "Dimensões". Renomeie Geography para City e mude o número de valores diferentes possíveis para 50.
- Observe como isso muda a contagem de conversões diárias atribuíveis médias POR BUCKET. Agora, ele é muito menor. Isso porque, se você aumentar o número de valores possíveis nessa dimensão sem mudar mais nada, vai aumentar o número total de agrupamentos sem alterar quantos eventos de conversão vão se enquadrar em cada um deles.
- Clique em "Simular".
- Observe as proporções de ruído da simulação resultante: agora elas são maiores do que na simulação anterior.
Dado o princípio de design principal, valores de resumo pequenos provavelmente serão mais ruidosos do que valores grandes. Portanto, sua escolha de configuração afeta quantos eventos de conversão atribuídos acabam em cada bucket (também conhecido como chave de agregação), e essa quantidade afeta o ruído nos relatórios de resumo de saída final.
Uma decisão de design que afeta o número de eventos de conversão atribuídos em um único agrupamento é a granularidade da dimensão. Confira estes exemplos de chaves de agregação e dimensões:
- Abordagem 1: uma estrutura de chave com dimensões aproximadas: País x Campanha publicitária (ou o maior bucket de agregação de campanhas) x Tipo de produto (de 10 tipos possíveis de produtos)
- Abordagem 2: uma estrutura de chave com dimensões granulares: Cidade x ID do criativo x Produto (de 100 produtos possíveis)
Cidade é uma dimensão mais granular que País; ID do criativo é mais granular que Campanha; e Produto é mais granular que Tipo de produto. Portanto, a abordagem 2 terá um número menor de eventos (conversões) por agrupamento (= por chave) na saída do relatório de resumo do que a abordagem 1. Como o ruído adicionado à saída é independente do número de eventos no bucket, os dados de medição nos relatórios de resumo serão mais ruidosos com a abordagem 2. Para cada anunciante, teste várias compensações de granularidade no design da chave para ter a máxima utilidade nos resultados.
Decisão: estruturas principais
Teste no Noise Lab
No modo simples, a estrutura de chave padrão é usada. No modo avançado, você pode testar diferentes estruturas de chave. Algumas dimensões de exemplo estão incluídas, mas você também pode modificá-las.
- Acesse o modo avançado.
- No painel lateral "Parâmetros", procure "Estratégia principal". A estratégia padrão, chamada "A" na ferramenta, usa uma estrutura de chave granular que inclui todas as dimensões: geografia x ID da campanha x categoria do produto.
- Clique em "Simular".
- Observe as proporções de ruído da simulação resultante.
- Mude a estratégia de chave para B. Isso mostra outros controles para você configurar a estrutura de chaves.
- Configure sua estrutura de chaves, por exemplo, da seguinte maneira:
- Número de estruturas principais: 2
- Estrutura principal 1 = Geografia x Categoria de produto.
- Estrutura principal 2 = ID da campanha x categoria do produto.
- Clique em "Simular".
- Agora você recebe dois relatórios de resumo por tipo de meta de medição (dois para contagem de compras e dois para valor de compra), já que está usando duas estruturas de chave distintas. Observe as proporções de ruído.
- Você também pode testar com suas próprias dimensões personalizadas. Para isso, procure os dados que você quer acompanhar: "Dimensões". Remova as dimensões de exemplo e crie as suas usando os botões "Adicionar/Remover/Redefinir" abaixo da última dimensão.
Outra decisão de design que afeta o número de eventos de conversão atribuídos em um único agrupamento é a estrutura de chaves que você decide usar. Confira alguns exemplos de chaves de agregação:
- Uma estrutura principal com todas as dimensões. Vamos chamar isso de "Estratégia principal A".
- Duas estruturas principais, cada uma com um subconjunto de dimensões. Vamos chamar isso de Estratégia principal B.
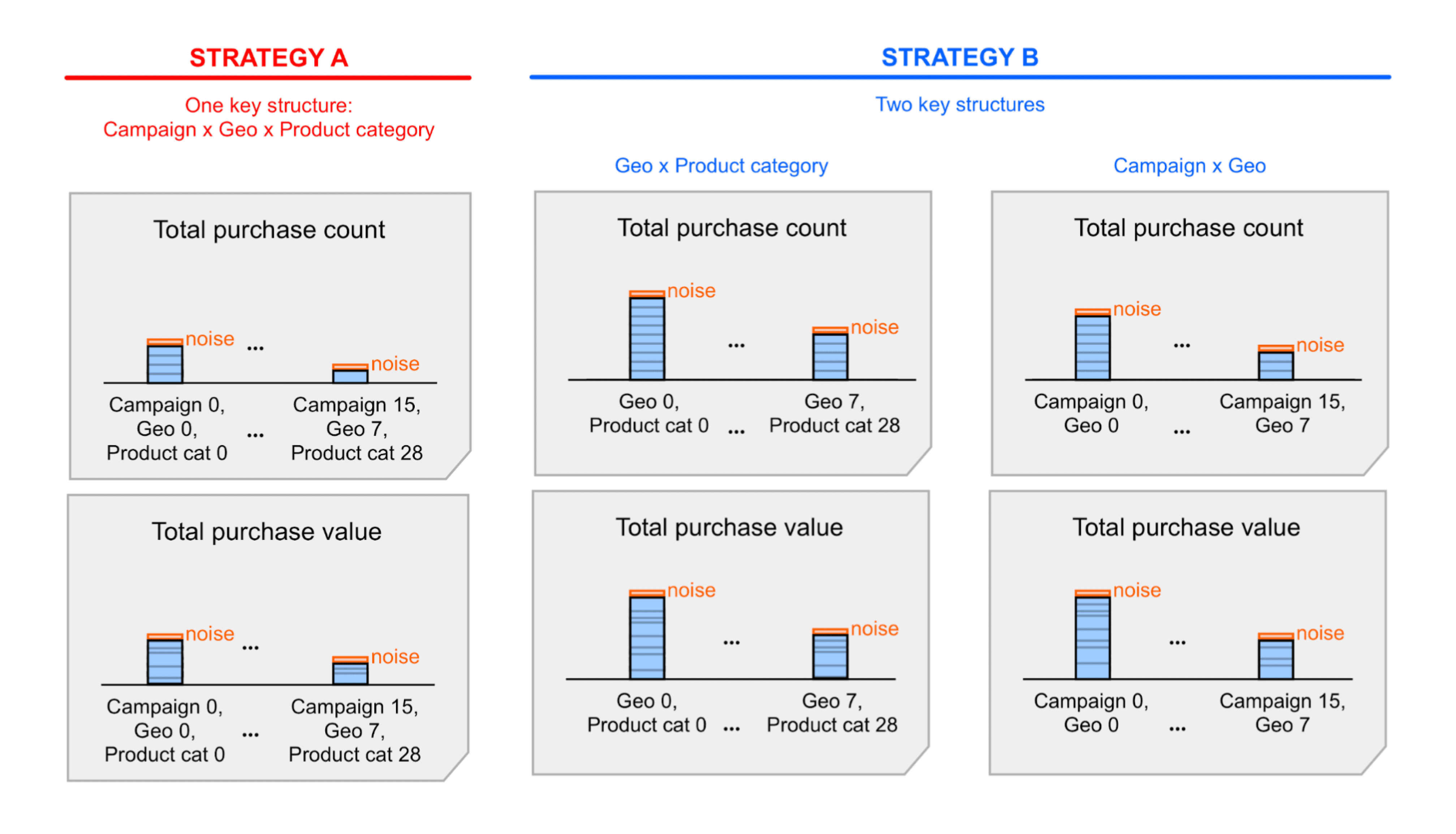
A estratégia A é mais simples, mas talvez seja necessário resumir (somar) os valores de resumo ruidosos incluídos nos relatórios de resumo para acessar determinados insights. Ao somar esses valores, você também soma o ruído. Com a estratégia B, os valores resumidos expostos nos relatórios de resumo já podem fornecer as informações necessárias. Isso significa que a estratégia B provavelmente vai gerar melhores proporções de sinal-ruído do que a estratégia A. No entanto, o ruído já pode ser aceitável com a estratégia A, então você ainda pode decidir favorecer a estratégia A por simplicidade. Saiba mais no exemplo detalhado que descreve essas duas estratégias.
O gerenciamento de chaves é um assunto complexo. Várias técnicas elaboradas podem ser consideradas para melhorar as proporções sinal-ruído. Um deles é descrito em Gerenciamento avançado de chaves.
Decisão: frequência de agrupamento em lote
Teste no Noise Lab
- Acesse o modo simples ou avançado. Os dois funcionam da mesma forma em relação à frequência de agrupamento.
- No painel lateral "Parâmetros", procure "Sua estratégia de agregação" > "Frequência de agrupamento em lotes". Isso se refere à frequência de agrupamento de relatórios agregáveis processados com o serviço de agregação em um único job.
- Observe a frequência de agrupamento padrão: por padrão, uma frequência de agrupamento diário é simulada.
- Clique em "Simular".
- Observe as proporções de ruído da simulação resultante.
- Mude a frequência de agrupamento para semanal.
- Observe as proporções de ruído da simulação resultante: elas agora são menores (melhores) do que na simulação anterior.
Outra decisão de design que afeta o número de eventos de conversão atribuídos em um único bucket é a frequência de agrupamento em lotes que você decide usar. A frequência de agrupamento é a frequência com que você processa relatórios agregáveis.
Um relatório programado para agregação com mais frequência (por exemplo, a cada hora) terá menos eventos de conversão incluídos do que o mesmo relatório com uma programação de agregação menos frequente (por exemplo, a cada semana). Como resultado, o relatório por hora vai incluir mais ruído e menos eventos de conversão do que o mesmo relatório com uma programação de agregação menos frequente (por exemplo, a cada semana). Como resultado, o relatório por hora terá uma proporção sinal-ruído menor do que o relatório semanal, considerando que todo o restante seja igual. Teste requisitos de relatórios em várias frequências e avalie as proporções de sinal-ruído para cada uma delas.
Saiba mais em Agrupamento em lotes e Agregação em períodos mais longos.
Decisão: variáveis de campanha que afetam as conversões atribuíveis
Teste no Noise Lab
Embora seja difícil prever e possa haver variações significativas além dos efeitos sazonais, tente estimar o número de conversões diárias de atribuição de toque único para a potência de 10 mais próxima: 10, 100, 1.000 ou 10.000.
- Acesse o modo avançado.
- No painel lateral "Parâmetros", procure "Seus dados de conversão".
- Observe os parâmetros padrão. Por padrão, a contagem TOTAL diária de conversões atribuíveis é de 1.000. Isso dá uma média de aproximadamente 40 por bucket se você usar a configuração padrão (dimensões padrão, número padrão de valores diferentes possíveis para cada dimensão, estratégia de chave A). Observe que o valor é 40 na entrada "Contagem de conversões diárias atribuíveis médias POR BUCKET".
- Clique em "Simular" para executar uma simulação com os parâmetros padrão.
- Observe as proporções de ruído da simulação resultante.
- Agora defina o número TOTAL de conversões diárias atribuíveis como 100. Isso reduz o valor da contagem de conversões diárias atribuíveis médias POR INTERVALO.
- Clique em "Simular".
- Observe que as proporções de ruído agora são maiores. Isso acontece porque, quando você tem menos conversões por agrupamento, mais ruído é aplicado para manter a privacidade.
Uma distinção importante é o número total de conversões possíveis para um anunciante em comparação com o número total de conversões atribuídas possíveis. Este último é o que acaba afetando o ruído nos relatórios de resumo. As conversões atribuídas são um subconjunto do total de conversões que estão sujeitas a variáveis de campanha, como orçamento e segmentação de anúncios. Por exemplo, você esperaria um número maior de conversões atribuídas para uma campanha publicitária de US $10 milhões em comparação com uma de US $10 mil, considerando que todos os outros fatores sejam iguais.
Pontos a serem considerados:
- Avalie as conversões atribuídas em relação a um modelo de atribuição de toque único e mesmo dispositivo, já que elas estão no escopo dos relatórios de resumo coletados com a API Attribution Reporting.
- Considere uma contagem de conversões atribuídas para o pior e o melhor cenário. Por exemplo, considerando todo o resto igual, considere os orçamentos mínimo e máximo possíveis para uma campanha de um anunciante e projete as conversões atribuíveis para ambos os resultados como entradas na sua simulação.
- Se você estiver considerando usar o Sandbox de privacidade do Android, inclua as conversões atribuídas multiplataforma no cálculo.
Decisão: usar o escalonamento
Teste no Noise Lab
- Acesse o modo avançado.
- No painel lateral "Parâmetros", procure "Sua estratégia de agregação > Escalabilidade". Ela é definida como "Sim" por padrão.
- Para entender os efeitos positivos do escalonamento na proporção de ruído, primeiro defina "Escalonamento" como "Não".
- Clique em "Simular".
- Observe as proporções de ruído da simulação resultante.
- Defina "Ajuste de escala" como "Sim". O Noise Lab calcula automaticamente os fatores de escalonamento a serem usados, considerando os intervalos (valores médio e máximo) das metas de medição do seu cenário. Em um sistema real ou em uma configuração de teste de origem, é recomendável implementar seu próprio cálculo para fatores de escalonamento.
- Clique em "Simular".
- Observe que as proporções de ruído agora são menores (melhores) nesta segunda simulação. Isso acontece porque você está usando o escalonamento.
Dado o princípio de design principal, o ruído adicionado é uma função do orçamento de contribuição.
Portanto, para aumentar as proporções de sinal-ruído, você pode transformar os valores coletados durante um evento de conversão escalonando-os em relação ao orçamento de contribuição e removendo o escalonamento após a agregação. Use o escalonamento para aumentar as proporções sinal-ruído.
Decisão: número de metas de medição e divisão do orçamento de privacidade
Isso está relacionado ao escalonamento. Leia Usar escalonamento.
Teste no Noise Lab
Uma meta de medição é um ponto de dados distinto coletado em eventos de conversão.
- Acesse o modo avançado.
- No painel lateral "Parâmetros", procure os dados que você quer acompanhar: Metas de medição. Por padrão, você tem duas metas de medição: valor da compra e contagem de compras.
- Clique em "Simular" para executar uma simulação com as metas padrão.
- Clique em "Remover". Isso vai remover a última meta de medição (contagem de compras, nesse caso).
- Clique em "Simular".
- Observe que as proporções de ruído para o valor da compra agora são menores (melhores) para esta segunda simulação. Isso acontece porque você tem menos metas de medição, então uma delas recebe todo o orçamento de contribuição.
- Clique em "Redefinir". Agora você tem duas metas de medição: valor da compra e contagem de compras. O Noise Lab calcula automaticamente os fatores de escalonamento a serem usados, considerando os intervalos (valores médio e máximo) das metas de medição do seu cenário. Por padrão, o Noise Lab divide o orçamento igualmente entre as metas de medição.
- Clique em "Simular".
- Observe as proporções de ruído da simulação resultante. Observe os fatores de escalonamento mostrados na simulação.
- Agora, vamos personalizar a divisão do orçamento de privacidade para alcançar proporções sinal-ruído melhores.
- Ajuste a porcentagem do orçamento atribuída a cada meta de medição. Considerando os parâmetros padrão, a meta de medição 1, ou seja, o valor da compra, tem um intervalo muito maior (entre 0 e 1.000) do que a meta de medição 2, ou seja, a contagem de compras (entre 1 e 1, sempre igual a 1). Por isso, ele precisa de "mais espaço para escalonar": o ideal seria atribuir mais orçamento de contribuição à meta de medição 1 do que à meta de medição 2, para que ele possa ser ampliado com mais eficiência (consulte "Escalonamento") e, portanto,
- Atribua 70% do orçamento à meta de medição 1. Atribua 30% à meta de medição 2.
- Clique em "Simular".
- Observe as proporções de ruído da simulação resultante. Para o valor de compra, as proporções de ruído agora são consideravelmente menores (melhores) do que na simulação anterior. Para a contagem de compras, elas permanecem praticamente inalteradas.
- Continue ajustando a divisão do orçamento entre as métricas. Observe como isso afeta o ruído.
É possível definir suas próprias metas de medição personalizadas com os botões "Adicionar/Remover/Redefinir".
Se você medir um ponto de dados (meta de medição) em um evento de conversão, como a contagem de conversões, esse ponto poderá receber todo o orçamento de contribuição (65.536). Se você definir várias metas de medição em um evento de conversão, como contagem de conversões e valor da compra, esses pontos de dados precisarão compartilhar o orçamento de contribuição. Isso significa que você tem menos espaço para aumentar seus valores.
Portanto, quanto mais metas de medição você tiver, menor será a probabilidade de as proporções sinal-ruído serem altas (mais ruído).
Outra decisão a ser tomada em relação às metas de medição é a divisão do orçamento. Se você dividir o orçamento de contribuição igualmente entre dois pontos de dados, cada um vai receber um orçamento de 65536/2 = 32768. Isso pode ou não ser ideal, dependendo do valor máximo possível para cada ponto de dados. Por exemplo, se você estiver medindo a contagem de compras com um valor máximo de 1 e o valor da compra com um mínimo de 1 e um máximo de 120, o valor da compra se beneficiaria de ter "mais espaço" para ser ampliado, ou seja, receber uma proporção maior do orçamento de contribuição. Você vai saber se algumas metas de medição devem ser priorizadas em relação a outras devido ao impacto do ruído.
Decisão: gerenciamento de outliers
Teste no Noise Lab
Uma meta de medição é um ponto de dados distinto coletado em eventos de conversão.
- Acesse o modo avançado.
- No painel lateral "Parâmetros", procure "Sua estratégia de agregação > Escalabilidade".
- Confira se a opção "Dimensionamento" está definida como "Sim". O Noise Lab calcula automaticamente os fatores de escalonamento a serem usados com base nos intervalos (valores médios e máximos) que você forneceu para as metas de medição.
- Vamos supor que a maior compra já feita foi de US $2.000, mas que a maioria das compras acontece na faixa de US $10 a US$ 120. Primeiro, vamos ver o que acontece se usarmos uma abordagem de escalonamento literal (não recomendado): insira US $2.000 como o valor máximo de purchaseValue.
- Clique em "Simular".
- Observe que as proporções de ruído são altas. Isso acontece porque nosso fator de escalonamento é calculado com base em US $2.000, quando, na realidade, a maioria dos valores de compra é muito menor.
- Agora, vamos usar uma abordagem de escalonamento mais pragmática. Mude o valor máximo de compra para US $120.
- Clique em "Simular".
- Observe que as proporções de ruído são menores (melhores) nessa segunda simulação.
Para implementar o escalonamento, normalmente você calcula um fator com base no valor máximo possível para um determinado evento de conversão (saiba mais neste exemplo).
No entanto, evite usar um valor máximo literal para calcular esse fator de escalonamento, porque isso pioraria as proporções sinal-ruído. Em vez disso, remova os outliers e use um valor máximo pragmático.
O gerenciamento de outliers é um assunto complexo. Várias técnicas elaboradas podem ser consideradas para melhorar as proporções sinal-ruído. Um deles é descrito em Gerenciamento avançado de outliers.
Próximas etapas
Agora que você avaliou várias estratégias de gerenciamento de ruído para seu caso de uso, é hora de começar a testar relatórios resumidos coletando dados de medição reais usando um teste de origem. Leia guias e dicas para testar a API.
Apêndice
Tour rápido pelo Noise Lab
O Noise Lab ajuda você a avaliar e comparar rapidamente estratégias de gestão de ruído. Use-o para:
- Entenda os principais parâmetros que podem afetar o ruído e o efeito deles.
- Simule o efeito do ruído nos dados de medição de saída com diferentes decisões de design. Ajuste os parâmetros de design até atingir uma relação sinal-ruído adequada para seu caso de uso.
- Compartilhe seu feedback sobre a utilidade dos relatórios de resumo: quais valores de parâmetros de epsilon e ruído funcionam para você e quais não funcionam? Onde estão os pontos de inflexão?
Pense nisso como uma etapa de preparação. O Noise Lab gera dados de medição para simular resultados de relatórios de resumo com base na sua entrada. Ele não persiste nem compartilha dados.
Há dois modos diferentes no Noise Lab:
- Modo simples: entenda os princípios básicos dos controles de ruído.
- Modo avançado: teste diferentes estratégias de gerenciamento de ruído e avalie qual delas gera as melhores proporções sinal-ruído para seus casos de uso.
Clique nos botões no menu da parte de cima para alternar entre os dois modos (1 na captura de tela a seguir).
Modo simples
- No modo simples, você controla parâmetros (encontrados no lado esquerdo ou #2 na captura de tela a seguir), como epsilon, e vê como eles afetam o ruído.
- Cada parâmetro tem uma dica (um botão "?"). Clique neles para ver uma explicação de cada parâmetro (nº 3 na captura de tela a seguir).
- Para começar, clique no botão "Simular" e observe como é a saída (nº 4 na captura de tela a seguir).
- Na seção "Saída", você pode conferir vários detalhes. Alguns elementos têm um "?" ao lado. Clique em cada "?" para ver uma explicação das várias informações.
- Na seção "Saída", clique na opção "Detalhes" se quiser ver uma versão expandida da tabela (nº 5 na captura de tela a seguir).
- Depois de cada tabela de dados na seção de saída, há uma opção para fazer o download da tabela e usar off-line. Além disso, no canto inferior direito, há uma opção para baixar todas as tabelas de dados (nº 6 na captura de tela a seguir).
- Teste diferentes configurações para os parâmetros na seção "Parâmetros" e clique em "Simular" para ver como eles afetam a saída:
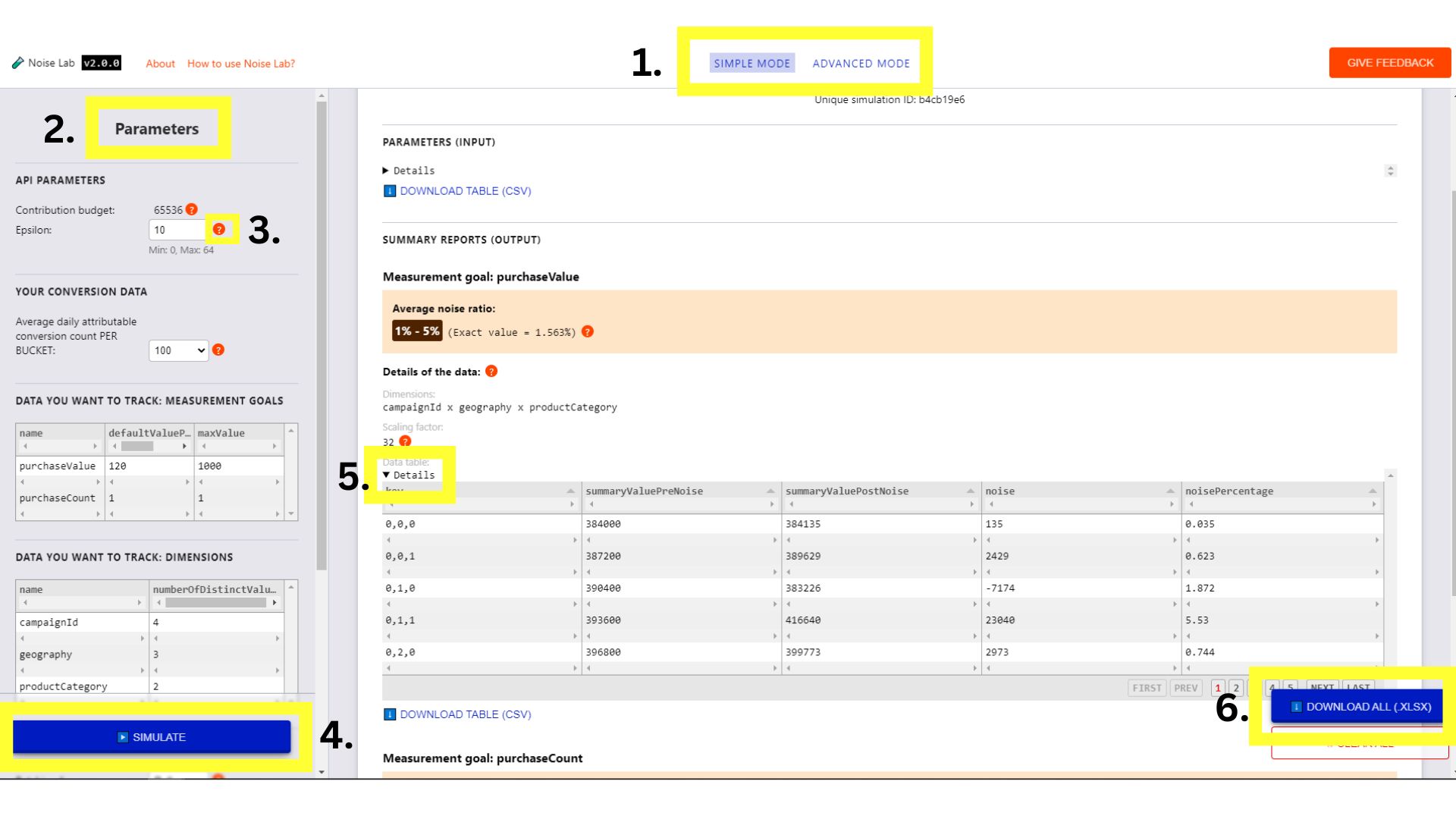
Interface do Noise Lab para o modo simples.
Modo avançado
- No modo avançado, você tem mais controle sobre os parâmetros. É possível adicionar metas e dimensões de métricas personalizadas (1 e 2 na captura de tela a seguir).
- Role para baixo na seção "Parâmetros" e confira a opção "Estratégia principal". Isso pode ser usado para testar diferentes estruturas de chave
(#3 na captura de tela a seguir)
- Para testar diferentes estruturas de chave, mude a estratégia de chave para "B".
- Insira o número de estruturas de chave diferentes que você quer usar (o padrão é "2").
- Clique em "Gerar estruturas de chaves".
- Clique nas caixas de seleção ao lado das chaves que você quer incluir em cada estrutura para especificar as opções.
- Clique em "Simular" para ver a saída.
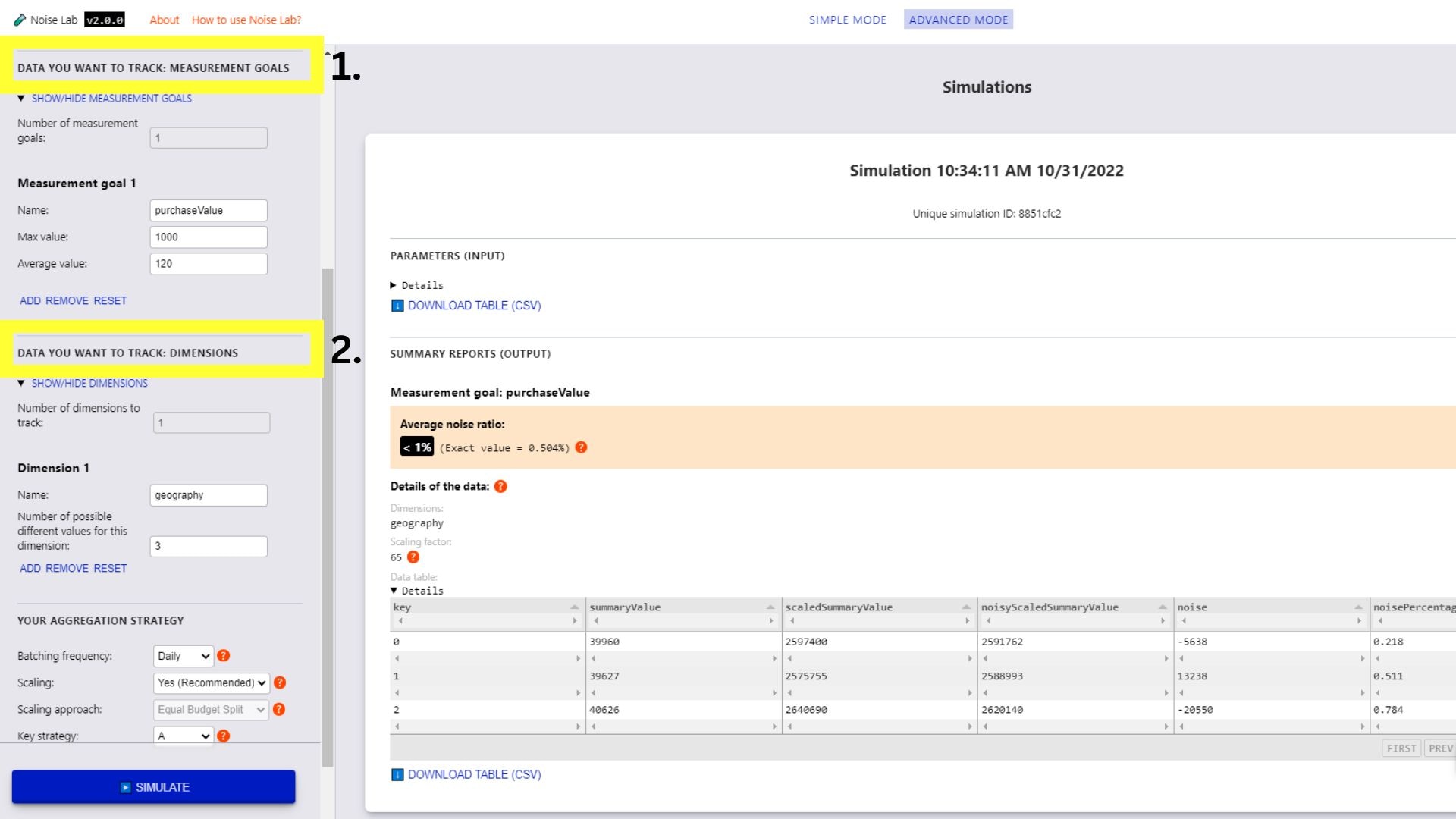
Interface do Noise Lab para o modo avançado. 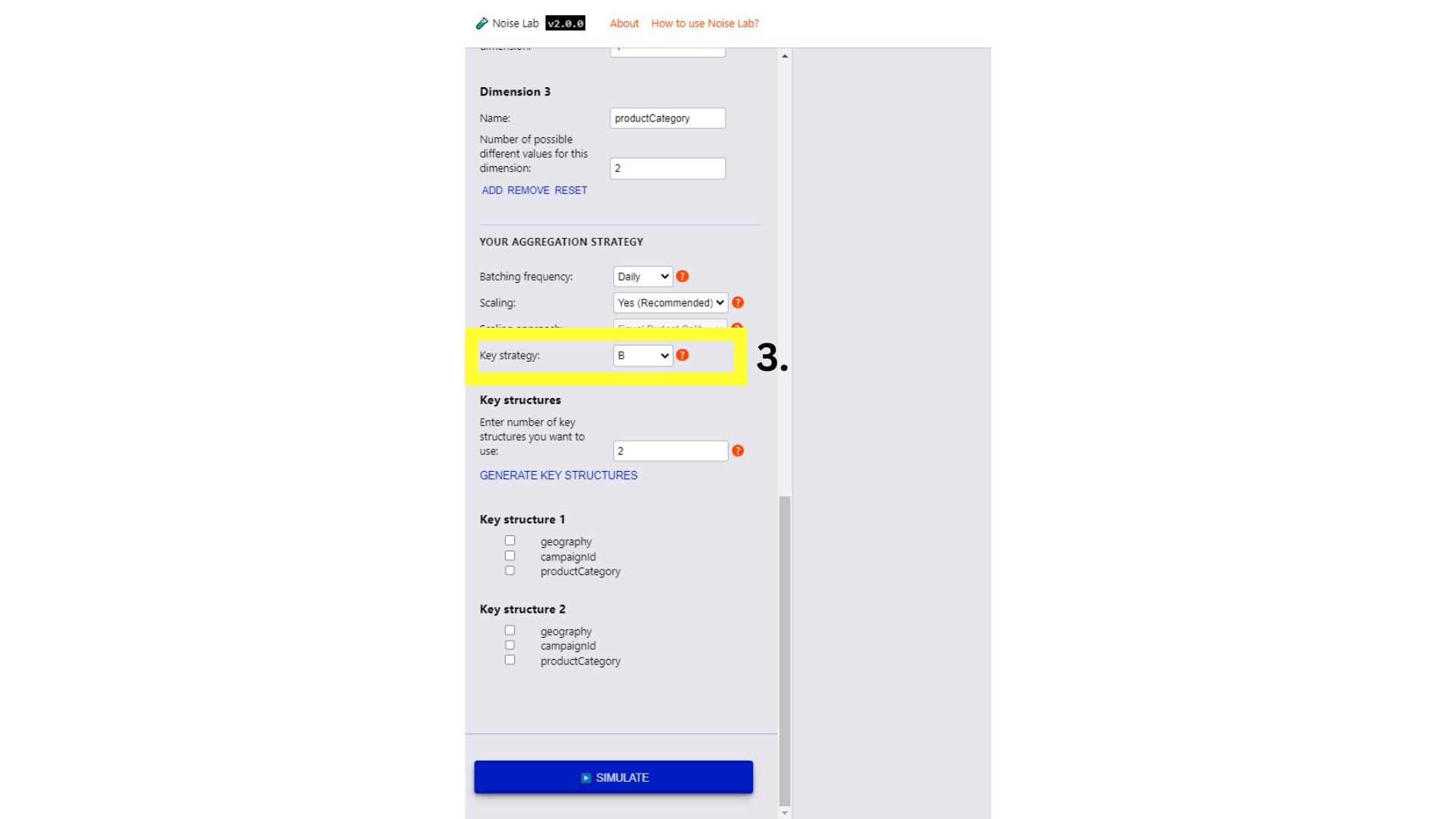
Interface do Noise Lab para o modo avançado.
Métricas de ruído
Conceito principal
O ruído é adicionado para proteger a privacidade de cada usuário.
Um valor de ruído alto indica que os buckets/chaves são esparsos e contêm contribuições de um número limitado de eventos sensíveis. Isso é feito automaticamente pelo Noise Lab para permitir que as pessoas se "escondam na multidão" ou, em outras palavras, protege a privacidade dessas pessoas com uma quantidade maior de ruído adicionado.
Um valor de ruído baixo indica que a configuração de dados foi projetada de forma que já permite que os indivíduos se "escondam na multidão". Isso significa que os agrupamentos contêm contribuições de um número suficiente de eventos para verificar se a privacidade do usuário individual está protegida.
Essa instrução é válida para o erro percentual médio (APE) e o RMSRE_T (erro relativo médio quadrático com um limite).
APE (erro percentual médio)
O APE é a proporção entre o ruído e o sinal, ou seja, o valor real do resumo.
Valores de APE mais baixos significam melhores proporções de sinal-ruído.
Fórmula
Para um determinado relatório de resumo, o APE é calculado da seguinte forma:
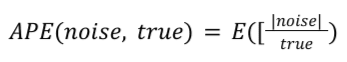
True é o valor verdadeiro do resumo. O APE é a média do ruído em cada valor de resumo verdadeiro, com média em todas as entradas de um relatório de resumo. No Noise Lab, esse valor é multiplicado por 100 para gerar uma porcentagem.
Vantagens e desvantagens
Os intervalos com tamanhos menores têm um impacto desproporcional no valor final do APE. Isso pode ser enganoso ao avaliar o ruído. Por isso, adicionamos outra métrica, RMSRE_T, projetada para reduzir essa limitação do APE. Confira os exemplos para mais detalhes.
Código
Revise o código-fonte para o cálculo do APE.
RMSRE_T (erro relativo quadrático médio com um limite)
RMSRE_T (erro relativo quadrático médio com um limite) é outra medida de ruído.
Como interpretar o RMSRE_T
Valores menores de RMSRE_T significam melhores proporções sinal/ruído.
Por exemplo, se uma proporção de ruído aceitável para seu caso de uso for de 20% e RMSRE_T for 0,2, você pode ter certeza de que os níveis de ruído estão dentro do intervalo aceitável.
Fórmula
Para um determinado relatório de resumo, o RMSRE_T é calculado da seguinte forma:
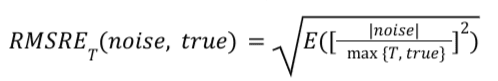
Vantagens e desvantagens
A RMSRE_T é um pouco mais complexa de entender do que a APE. No entanto, ele tem algumas vantagens que o tornam, em alguns casos, mais adequado do que o APE para analisar ruídos em relatórios de resumo:
- O RMSRE_T é mais estável. "T" é um limite. "T" é usado para dar menos peso no cálculo de RMSRE_T a intervalos que têm menos conversões e, portanto, são mais sensíveis a ruídos devido ao tamanho pequeno. Com T, a métrica não aumenta em intervalos com poucas conversões. Se T for igual a 5, um valor de ruído tão pequeno quanto 1 em um agrupamento com 0 conversões não será mostrado como muito acima de 1. Em vez disso, ele será limitado a 0,2, o que equivale a 1/5, já que T é igual a 5. Ao dar menos peso a intervalos menores, que são mais sensíveis a ruídos, essa métrica é mais estável e facilita a comparação de duas simulações.
- O RMSRE_T permite uma agregação simples. Conhecer o RMSRE_T de vários agrupamentos e as contagens reais permite calcular o RMSRE_T da soma deles. Isso também permite otimizar para RMSRE_T esses valores combinados.
Embora seja possível agregar o APE, a fórmula é bastante complicada, já que envolve o valor absoluto da soma de ruídos de Laplace. Isso dificulta a otimização do APE.
Código
Revise o código-fonte para o cálculo de RMSRE_T.
Exemplos
Relatório de resumo com três intervalos:
- bucket_1 = noise: 10, trueSummaryValue: 100
- bucket_2 = noise: 20, trueSummaryValue: 100
- bucket_3 = noise: 20, trueSummaryValue: 200
APE = (0,1 + 0,2 + 0,1) / 3 = 13%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,200))^2) / 3) = sqrt( (0.01 + 0.04 + 0.01) / 3) = 0.14
Relatório de resumo com três intervalos:
- bucket_1 = noise: 10, trueSummaryValue: 100
- bucket_2 = noise: 20, trueSummaryValue: 100
- bucket_3 = noise: 20, trueSummaryValue: 20
APE = (0,1 + 0,2 + 1) / 3 = 43%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,20))^2) / 3) = sqrt( (0.01 + 0.04 + 1.0) / 3) = 0.59
Relatório de resumo com três intervalos:
- bucket_1 = noise: 10, trueSummaryValue: 100
- bucket_2 = noise: 20, trueSummaryValue: 100
- bucket_3 = noise: 20, trueSummaryValue: 0
APE = (0,1 + 0,2 + infinito) / 3 = infinito
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,0))^2) / 3) = sqrt( (0.01 + 0.04 + 16.0) / 3) = 2.31
Gerenciamento avançado de chaves
Uma DSP ou empresa de medição de publicidade pode ter milhares de clientes de publicidade global, abrangendo vários setores, moedas e potenciais de preço de compra. Isso significa que criar e gerenciar uma chave de agregação por anunciante provavelmente será muito impraticável. Além disso, será difícil selecionar um valor máximo agregável e um orçamento de agregação que possam limitar o impacto do ruído nesses milhares de anunciantes globais. Em vez disso, vamos considerar os seguintes cenários:
Estratégia principal A
O provedor de tecnologia de publicidade decide criar e gerenciar uma chave em todos os clientes de publicidade. Em todos os anunciantes e moedas, o intervalo de compras varia de baixo volume e alto valor a alto volume e baixo valor. Isso resulta na seguinte chave:
| Chave (várias moedas) | |
|---|---|
| Valor máximo agregável | 5.000.000 |
| Intervalo de valor de compra | [120 - 5000000] |
Estratégia principal B
O provedor de tecnologia de publicidade decide criar e gerenciar duas chaves em todos os clientes de publicidade. Eles decidem separar as chaves por moeda. Em todos os anunciantes e moedas, o intervalo de compras varia de baixo volume, compras de alto valor, a alto volume, compras de baixo valor. Separando por moeda, eles criam duas chaves:
| Chave 1 (USD) | Tecla 2 (¥) | |
|---|---|---|
| Valor máximo agregável | USD 40.000 | ¥5.000.000 |
| Intervalo de valor de compra | [120 a 40.000] | [15.000 - 5.000.000] |
A estratégia B terá menos ruído no resultado do que a estratégia A porque os valores de moeda não são distribuídos uniformemente entre as moedas. Por exemplo, considere como compras denominadas em ¥ e USD alteram os dados subjacentes e a saída ruidosa resultante.
Estratégia principal C
O provedor de adtech decide criar e gerenciar quatro chaves em todos os clientes de publicidade e separá-las por moeda x setor do anunciante:
| Chave 1 (USD x anunciantes de joias de alta qualidade) |
Chave 2 (¥ x Anunciantes de joias sofisticadas) |
Chave 3 (USD x anunciantes de varejo de roupas) |
Chave 4 (Anunciantes de varejo de roupas) |
|
|---|---|---|---|---|
| Valor máximo agregável | USD 40.000 | ¥5.000.000 | US$ 500 | ¥65.000 |
| Intervalo de valor de compra | [10.000 - 40.000] | [1.250.000 - 5.000.000] | [120 - 500] | [15.000 - 65.000] |
A estratégia C principal terá menos ruído no resultado do que a estratégia B principal porque os valores de compra do anunciante não são distribuídos uniformemente entre os anunciantes. Por exemplo, considere como as compras de joias sofisticadas misturadas com compras de bonés de beisebol alteram os dados subjacentes e a saída ruidosa resultante.
Considere criar valores agregados máximos e fatores de escalonamento compartilhados para semelhanças entre vários anunciantes a fim de reduzir o ruído na saída. Por exemplo, você pode testar as seguintes estratégias para seus anunciantes:
- Uma estratégia separada por moeda (USD, ¥, CAD etc.)
- Uma estratégia separada por setor do anunciante (seguros, automóveis, varejo etc.)
- Uma estratégia separada por intervalos de valor de compra semelhantes ([100], [1000], [10000] etc.)
Ao criar estratégias importantes com base nas semelhanças entre anunciantes, as chaves e o código correspondente ficam mais fáceis de gerenciar, e as proporções de sinal-ruído aumentam. Teste diferentes estratégias com diferentes pontos em comum do anunciante para descobrir pontos de inflexão na maximização do impacto de ruído em comparação com o gerenciamento de código.
Gerenciamento avançado de outliers
Vamos considerar um cenário com dois anunciantes:
- Anunciante A:
- Em todos os produtos no site do anunciante A, as possibilidades de preço de compra estão entre [$120 e $1.000] , para um intervalo de $880.
- Os preços de compra são distribuídos de maneira uniforme no intervalo de US $880, sem outliers fora de dois desvios padrão do preço médio de compra.
- Anunciante B:
- Em todos os produtos no site do anunciante B, as possibilidades de preço de compra estão entre [$120 e $1.000] , para um intervalo de $880.
- Os preços de compra são muito mais altos na faixa de US $120 a US$ 500, com apenas 5% das compras ocorrendo na faixa de US $500 a US$ 1.000.
Considerando os requisitos de orçamento de contribuição e a metodologia com que o ruído é aplicado aos resultados finais, o anunciante B terá, por padrão, uma saída mais ruidosa do que o anunciante A, já que o anunciante B tem um potencial maior de outliers afetarem os cálculos subjacentes.
É possível mitigar isso com uma configuração de chave específica. Teste estratégias importantes que ajudam a gerenciar dados discrepantes e distribuir os valores de compra de maneira mais uniforme no intervalo de compra da chave.
Para o anunciante B, você pode criar duas chaves separadas para capturar dois intervalos de valor de compra diferentes. Neste exemplo, a adtech observou que os outliers aparecem acima do valor de compra de US $500. Tente implementar duas chaves separadas para esse anunciante:
- Estrutura de chave 1 : chave que captura apenas compras entre US $120 e US$ 500 (cobrindo aproximadamente 95% do volume total de compras).
- Estrutura principal 2: chave que captura apenas compras acima de US $500 (cobrindo cerca de 5% do volume total de compras).
A implementação dessa estratégia principal vai gerenciar melhor o ruído para o anunciante B e ajudar a maximizar a utilidade dos relatórios de resumo. Com os novos intervalos menores, a chave A e a chave B agora têm uma distribuição mais uniforme de dados em cada chave respectiva do que a chave única anterior. Isso resulta em menos impacto de ruído na saída de cada chave do que na chave única anterior.