
מידע על המסמך הזה
במאמר הזה נסביר על הנושאים הבאים:
- לפני שיוצרים דוחות סיכום, חשוב להבין אילו אסטרטגיות כדאי ליצור.
- היכרות עם Noise Lab, כלי שעוזר להבין את ההשפעות של פרמטרים שונים של נתונים מיותרים, ומאפשר לבחון ולהעריך במהירות אסטרטגיות שונות לניהול נתונים מיותרים.
שיתוף משוב
במאמר הזה מפורטים כמה עקרונות לעבודה עם דוחות סיכום, אבל יש גישות רבות לניהול רעשי רקע שלא מפורטות כאן. נשמח לקבל הצעות, תוספות ושאלות.
- כדי לשלוח משוב ציבורי על אסטרטגיות לניהול רעשי רקע, על התועלת או על הפרטיות של ה-API (אפסילון), ולשתף את התצפיות שלכם כשאתם מבצעים סימולציה באמצעות Noise Lab: אפשר להוסיף תגובה לבעיה הזו
- כדי לתת משוב ציבורי על היבט אחר של ה-API: יוצרים בעיה חדשה כאן
לפני שמתחילים
- כדאי לקרוא את המאמרים Attribution Reporting: summary reports וAttribution Reporting full system overview כדי לקבל מבוא.
- כדי להפיק את המרב מהמדריך הזה, כדאי לעיין במאמרים הסבר על רעשי רקע והסבר על מפתחות צבירה.
החלטות בנוגע לעיצוב
עקרון עיצוב מרכזי
יש הבדלים מהותיים בין האופן שבו פועלים קובצי Cookie של צד שלישי לבין האופן שבו פועלים דוחות סיכום. הבדל משמעותי אחד הוא הרעש שנוסף לנתוני המדידה בדוחות הסיכום. היבט נוסף הוא תזמון הדוחות.
כדי לגשת לנתוני מדידה של דוחות סיכום עם יחסי אות לרעש גבוהים יותר, פלטפורמות למפרסמים (DSP) וספקי שירותי מדידה של מודעות יצטרכו לעבוד עם המפרסמים שלהם כדי לפתח אסטרטגיות לניהול רעשי רקע. כדי לפתח את האסטרטגיות האלה, פלטפורמות DSP וספקי פתרונות מדידה צריכים לקבל החלטות בנוגע לעיצוב. ההחלטות האלה מתבססות על מושג חיוני אחד:
הפיזור של ערכי הרעש נגזר רק משני פרמטרים – אפסילון ותקציב התרומה. עם זאת, יש לכם מספר אמצעי בקרה אחרים שישפיעו על יחסי האות לרעש של נתוני המדידה שמתקבלים.
אנחנו מאמינים שתהליך איטרטיבי יוביל להחלטות הטובות ביותר, אבל כל וריאציה של ההחלטות האלה תוביל להטמעה קצת שונה – לכן צריך לקבל את ההחלטות האלה לפני שכותבים כל איטרציה של קוד (ולפני שמציגים מודעות).
החלטה: רמת הפירוט של המאפיין
כדאי לנסות את התכונה ב-Noise Lab
- עוברים למצב מתקדם.
- בחלונית הצדדית 'פרמטרים', מחפשים את הקטע 'נתוני ההמרות שלך'.
- שימו לב לפרמטרים שמוגדרים כברירת מחדל. כברירת מחדל, המספר הכולל של ההמרות היומיות שאפשר לייחס למקורות תנועה הוא 1,000. אם משתמשים בהגדרת ברירת המחדל (מאפייני ברירת מחדל, מספר ברירת מחדל של ערכים שונים אפשריים לכל מאפיין, אסטרטגיה A של מפתח), המספר הממוצע הוא בערך 40 לכל קטגוריה. שימו לב שהערך הוא 40 בקלט Average daily attributable conversion count (מספר ההמרות הממוצע ביום שאפשר לשייך לקטגוריה) PER BUCKET (לכל קטגוריה).
- לוחצים על 'סימולציה' כדי להפעיל סימולציה עם פרמטרים שמוגדרים כברירת מחדל.
- בחלונית הצדדית Parameters (פרמטרים), מחפשים את Dimensions (מאפיינים). משנים את השם של Geography ל-City ומשנים את מספר הערכים השונים האפשריים ל-50.
- בודקים איך זה משפיע על מספר ההמרות הממוצע שמשויך לכל יום. עכשיו הוא הרבה יותר נמוך. הסיבה לכך היא שאם מגדילים את מספר הערכים האפשריים במאפיין הזה בלי לשנות שום דבר אחר, מגדילים את המספר הכולל של הדליים בלי לשנות את מספר אירועי ההמרה שייכללו בכל דלי.
- לוחצים על 'סימולציה'.
- בודקים את יחסי הרעש של הסימולציה שהתקבלה: יחסי הרעש גבוהים עכשיו מאלה של הסימולציה הקודמת.
בהתאם לעקרון העיצוב המרכזי, סביר להניח שערכי סיכום קטנים יהיו רועשים יותר מערכי סיכום גדולים. לכן, הבחירה שלכם בהגדרה משפיעה על מספר אירועי ההמרה המשויכים שמגיעים לכל קבוצה (שנקראת גם מפתח הצבירה), והמספר הזה משפיע על הרעש בדוחות הסיכום הסופיים.
החלטה עיצובית אחת שמשפיעה על מספר אירועי ההמרה שמשויכים למשבצת זמן אחת היא רמת הפירוט של המאפיין. הנה כמה דוגמאות למפתחות צבירה ולמאפיינים שלהם:
- גישה 1: מבנה מפתח אחד עם מימדים גסים: מדינה x קמפיין פרסום (או קבוצת הצבירה הגדולה ביותר של קמפיינים) x סוג מוצר (מתוך 10 סוגי מוצרים אפשריים)
- גישה 2: מבנה מפתח אחד עם מאפיינים מפורטים: עיר x מזהה קריאייטיב x מוצר (מתוך 100 מוצרים אפשריים)
המאפיין עיר הוא גרנולרי יותר מהמאפיין מדינה, המאפיין מזהה קריאייטיב הוא גרנולרי יותר מהמאפיין קמפיין, והמאפיין מוצר הוא גרנולרי יותר מהמאפיין סוג מוצר. לכן, בדוח הסיכום של גישה 2 יהיה מספר נמוך יותר של אירועים (המרות) לכל קבוצה (כלומר לכל מפתח) בהשוואה לגישה 1. בהתחשב בכך שהרעש שנוסף לפלט לא תלוי במספר האירועים בדלי, נתוני המדידה בדוחות הסיכום יהיו רועשים יותר בגישה 2. כל מפרסם צריך להתנסות בשינויים שונים ברמת הפירוט של המפתח כדי להפיק את התועלת המרבית מהתוצאות.
החלטה: מבנים מרכזיים
כדאי לנסות את התכונה ב-Noise Lab
במצב הפשוט, נעשה שימוש במבנה ברירת המחדל של המפתחות. במצב המתקדם, אפשר להתנסות במבני מפתח שונים. כלולות כמה דוגמאות למאפיינים, ואפשר גם לשנות אותן.
- עוברים למצב מתקדם.
- בחלונית הצדדית Parameters (פרמטרים), מחפשים את האפשרות Key strategy (שיטת בידינג מרכזית). שימו לב ששיטת ברירת המחדל, שנקראת A בכלי, משתמשת במבנה מפתח גרנולרי אחד שכולל את כל המאפיינים: מיקום גיאוגרפי x מזהה קמפיין x קטגוריית מוצר.
- לוחצים על 'סימולציה'.
- בודקים את יחסי הרעש בסימולציה שהתקבלה.
- משנים את שיטת הבידינג המרכזית לשיטה ב'. יוצגו אמצעי בקרה נוספים שבעזרתם תוכלו להגדיר את מבנה המפתח.
- מגדירים את מבנה המפתחות, למשל באופן הבא:
- מספר מבני המפתח: 2
- מבנה מפתח 1 = מיקום גיאוגרפי x קטגוריית מוצרים.
- מבנה מפתח 2 = מזהה קמפיין x קטגוריית מוצר.
- לוחצים על 'סימולציה'.
- שימו לב שעכשיו תקבלו שני דוחות סיכום לכל סוג של יעד מדידה (שניים למספר הרכישות, שניים לערך הרכישות), בהנחה שאתם משתמשים בשני מבנים נפרדים של מפתחות. בודקים את יחסי הרעש.
- אפשר גם לנסות את זה עם מאפיינים מותאמים אישית משלכם. כדי לעשות את זה, מחפשים את הנתונים שרוצים לעקוב אחריהם: מאפיינים. כדאי להסיר את המאפיינים לדוגמה וליצור מאפיינים משלכם באמצעות הלחצנים Add (הוספה), Remove (הסרה) או Reset (איפוס) שמתחת למאפיין האחרון.
החלטה עיצובית נוספת שתשפיע על מספר אירועי ההמרה שמשויכים לדלי אחד היא מבני המפתחות שבהם תבחרו להשתמש. הנה כמה דוגמאות למפתחות צבירה:
- מבנה מפתח אחד עם כל המאפיינים. נקרא לו 'אסטרטגיית מפתח א'.
- שתי מבנים מרכזיים, כל אחד עם קבוצת משנה של מאפיינים. נקרא לזה 'שיטת מפתח ב'.
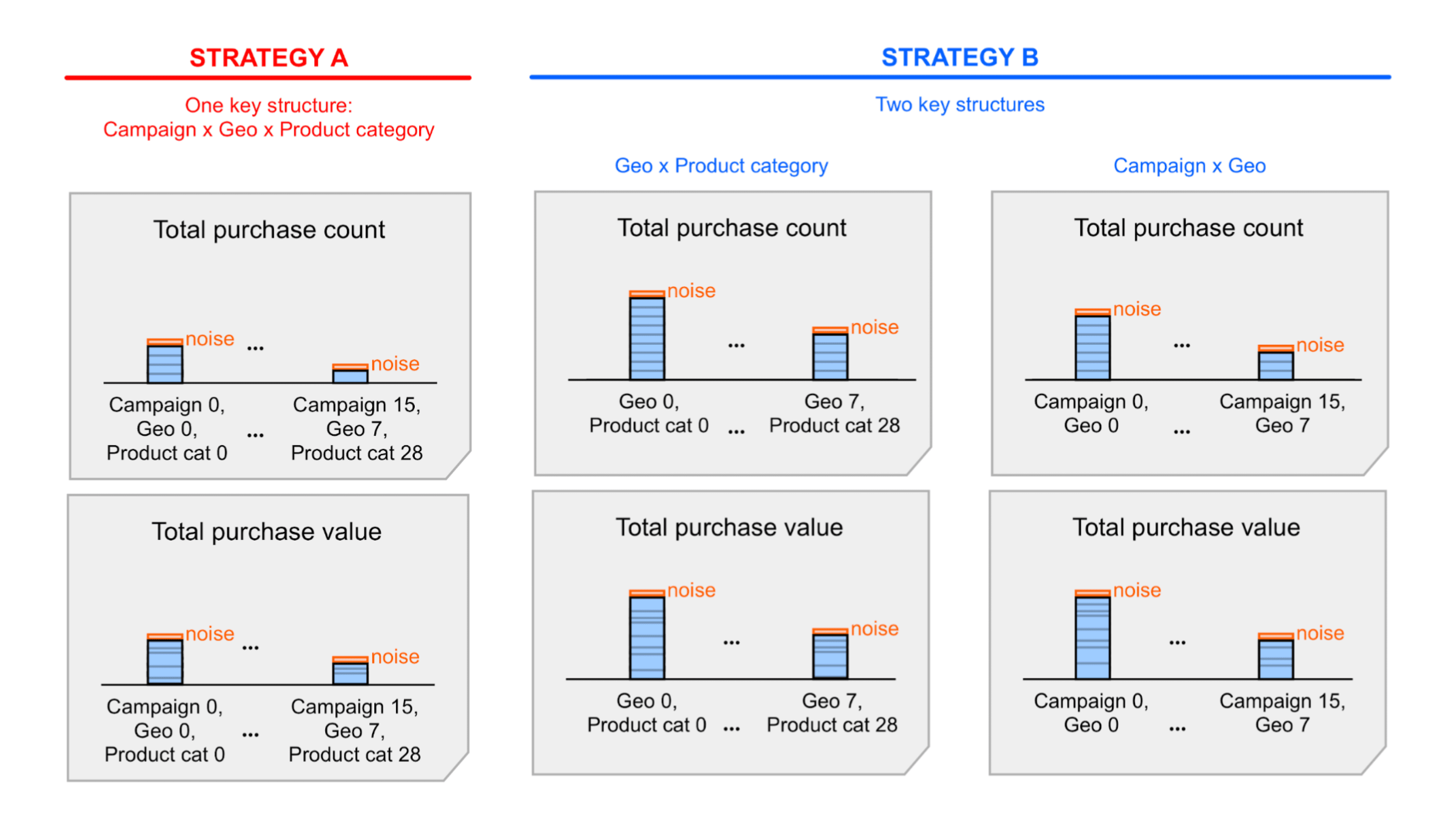
אסטרטגיה א' היא פשוטה יותר, אבל יכול להיות שתצטרכו לסכם את ערכי הסיכום עם הרעשים שכלולים בדוחות הסיכום כדי לגשת לתובנות מסוימות. כשמסכמים את הערכים האלה, מסכמים גם את הרעש. בשיטה ב', יכול להיות שהמידע שאתם צריכים כבר מופיע בסיכומי הדוחות. כלומר, סביר להניח ששיטה ב' תניב יחסי אות לרעש טובים יותר מאשר שיטה א'. עם זאת, יכול להיות שהרעש כבר מקובל באסטרטגיה א', ולכן עדיין כדאי להשתמש באסטרטגיה א' כדי לפשט את התהליך. מידע נוסף על שתי השיטות האלה זמין בדוגמה המפורטת.
ניהול מפתחות הוא נושא מורכב. יש מספר טכניקות מורכבות שאפשר להשתמש בהן כדי לשפר את יחסי האות לרעש. אחד מהם מתואר במאמר בנושא ניהול מתקדם של מפתחות.
החלטה: תדירות של איחוד
כדאי לנסות את התכונה ב-Noise Lab
- עוברים למצב פשוט (או למצב מתקדם – שני המצבים פועלים באותו אופן כשמדובר בתדירות של העלאות בכמות גדולה)
- בחלונית הצדדית 'פרמטרים', מחפשים את האפשרות 'אסטרטגיית הצבירה שלך' > 'תדירות העיבוד באצווה'. הכוונה היא לתדירות של חבילות דוחות שאפשר לצבור, שמעובדות באמצעות Aggregation Service במשימה אחת.
- שימו לב לתדירות ברירת המחדל של העיבוד באצווה: כברירת מחדל, מתבצעת סימולציה של תדירות עיבוד באצווה מדי יום.
- לוחצים על 'סימולציה'.
- בודקים את יחסי הרעש בסימולציה שהתקבלה.
- משנים את תדירות האצווה לשבועית.
- בודקים את יחסי האות לרעש של הסימולציה שמתקבלת: יחסי האות לרעש עכשיו נמוכים יותר (טובים יותר) מאשר בסימולציה הקודמת.
החלטה נוספת לגבי העיצוב שתשפיע על מספר אירועי ההמרה שמשויכים לקטגוריה אחת היא תדירות האצווה שבה תבחרו להשתמש. תדירות העיבוד באצווה היא התדירות שבה מעבדים דוחות שניתן לצבור.
דוח שמתוזמן לצבירה בתדירות גבוהה יותר (למשל, כל שעה) יכלול פחות אירועי המרה מאשר אותו דוח עם לוח זמנים לצבירה בתדירות נמוכה יותר (למשל, כל שבוע). כתוצאה מכך, הדוח השעתי יכלול יותר רעשי רקע.``` יכלול פחות אירועי המרה מאשר אותו דוח עם לוח זמנים פחות תדיר לצבירה (למשל, כל שבוע). כתוצאה מכך, יחס האות לרעש בדוח השעתי יהיה נמוך יותר מאשר בדוח השבועי, בהנחה שכל שאר התנאים שווים. כדאי להתנסות בדרישות דיווח בתדירויות שונות, ולבדוק את יחסי האות לרעש בכל אחת מהן.
מידע נוסף זמין במאמרים בנושא Batching וAggregating over longer time periods.
החלטה: משתני קמפיין שמשפיעים על המרות שניתן לשייך
כדאי לנסות את התכונה ב-Noise Lab
קשה לחזות את מספר ההמרות האלה, והוא יכול להשתנות באופן משמעותי בנוסף להשפעות העונתיות. לכן, כדאי לנסות להעריך את מספר ההמרות היומיות שמשויכות למגע יחיד, ולעגל אותו לחזקה הקרובה ביותר של 10: 10, 100, 1,000 או 10,000.
- עוברים למצב מתקדם.
- בחלונית הצדדית 'פרמטרים', מחפשים את הקטע 'נתוני ההמרות שלך'.
- שימו לב לפרמטרים שמוגדרים כברירת מחדל. כברירת מחדל, המספר הכולל של ההמרות היומיות שאפשר לייחס למקורות תנועה הוא 1,000. אם משתמשים בהגדרת ברירת המחדל (מאפייני ברירת מחדל, מספר ברירת מחדל של ערכים שונים אפשריים לכל מאפיין, אסטרטגיה A של מפתח), המספר הממוצע הוא בערך 40 לכל קטגוריה. שימו לב שהערך הוא 40 בקלט Average daily attributable conversion count (מספר ההמרות הממוצע ביום שאפשר לשייך לקטגוריה) PER BUCKET (לכל קטגוריה).
- לוחצים על 'סימולציה' כדי להפעיל סימולציה עם פרמטרים שמוגדרים כברירת מחדל.
- בודקים את יחסי הרעש בסימולציה שהתקבלה.
- עכשיו מגדירים את המספר הכולל של המרות יומיות שניתן לשייך ל-100. שימו לב שהפעולה הזו מורידה את הערך של מספר ההמרות היומי הממוצע שמשויך לכל דלי.
- לוחצים על 'סימולציה'.
- שימו לב שיחסי הרעש גבוהים יותר עכשיו: הסיבה לכך היא שכשיש פחות המרות בכל קבוצה, מוחל יותר רעש כדי לשמור על הפרטיות.
חשוב להבחין בין המספר הכולל של ההמרות האפשריות למפרסם לבין המספר הכולל של ההמרות האפשריות שמשויכות למפרסם. האפשרות השנייה היא זו שמשפיעה בסופו של דבר על הרעש בדוחות הסיכום. המרות משויכות הן קבוצת משנה של סך ההמרות שמושפעות ממשתני קמפיין, כמו תקציב המודעות והטירגוט של המודעות. לדוגמה, אם כל שאר התנאים זהים, אפשר לצפות למספר גבוה יותר של המרות שמשויכות לקמפיין פרסום בעלות של 10 מיליון דולר לעומת קמפיין פרסום בעלות של 10,000 דולר.
נקודות שצריך להביא בחשבון:
- הערכת ההמרות ששויכו למודל שיוך (Attribution) של מגע יחיד באותו מכשיר, כי הן נכללות בהיקף של דוחות הסיכום שנאספים באמצעות Attribution Reporting API.
- כדאי לקחת בחשבון גם את מספר ההמרות המשויכות בתרחיש הגרוע ביותר וגם את מספר ההמרות המשויכות בתרחיש הטוב ביותר. לדוגמה, אם כל שאר הגורמים שווים, כדאי לקחת בחשבון את התקציבים המינימלי והמקסימלי האפשריים לקמפיין של מפרסם, ואז להקרין המרות שניתן לשייך לשני התקציבים כנתוני קלט לסימולציה.
- אם אתם שוקלים להשתמש בארגז החול לפרטיות ב-Android, כדאי לכלול בחישוב המרות משויכות בפלטפורמות שונות.
החלטה: שימוש בהתאמה לעומס
כדאי לנסות את התכונה ב-Noise Lab
- עוברים למצב מתקדם.
- בחלונית הצדדית 'פרמטרים', מחפשים את האפשרות 'אסטרטגיית הצבירה שלך' > 'שינוי קנה מידה'. ההגדרה היא Yes כברירת מחדל.
- כדי להבין את ההשפעות החיוביות של שינוי קנה מידה על יחס הרעש, קודם צריך להגדיר את שינוי קנה המידה ל'לא'.
- לוחצים על 'סימולציה'.
- בודקים את יחסי הרעש בסימולציה שהתקבלה.
- מגדירים את האפשרות 'שינוי גודל' לערך 'כן'. שימו לב: Noise Lab מחשב באופן אוטומטי את גורמי ההתאמה לשימוש בהינתן הטווחים (ערכים ממוצעים ומקסימליים) של יעדי המדידה בתרחיש שלכם. במערכת אמיתית או בניסוי מקור מומלץ להטמיע חישוב משלכם לגורמי קנה מידה.
- לוחצים על 'סימולציה'.
- אפשר לראות שיחסי הרעש עכשיו נמוכים יותר (טובים יותר) בסימולציה השנייה הזו. הסיבה לכך היא שאתם משתמשים בהרחבת נפח האחסון.
בהתאם לעקרון התכנון המרכזי, הרעש שנוסף הוא פונקציה של תקציב התרומה.
לכן, כדי להגדיל את יחס האות לרעש, אתם יכולים להחליט לבצע שינוי קנה מידה לערכים שנאספו במהלך אירוע המרה ביחס לתקציב התרומה (ולבטל את שינוי קנה המידה אחרי הצבירה). משתמשים בהתאמת קנה מידה כדי להגדיל את יחסי האות לרעש.
החלטה: מספר יעדי המדידה והחלוקה של תקציב הפרטיות
הנושא הזה קשור להרחבת הפריסה. מומלץ לקרוא את המאמר שימוש בהרחבת פריסה.
כדאי לנסות את התכונה ב-Noise Lab
יעד מדידה הוא נקודת נתונים נפרדת שנאספת באירועי המרה.
- עוברים למצב מתקדם.
- בחלונית הצדדית 'פרמטרים', מחפשים את הנתונים שרוצים לעקוב אחריהם: יעדי מדידה. כברירת מחדל, יש לכם שני יעדי מדידה: ערך הרכישה ומספר הרכישות.
- לוחצים על 'סימולציה' כדי להריץ סימולציה עם היעדים שמוגדרים כברירת מחדל.
- לוחצים על 'הסרה'. הפעולה הזו תסיר את יעד המדידה האחרון (במקרה הזה, מספר הרכישות).
- לוחצים על 'סימולציה'.
- אפשר לראות שיחסי הרעש של ערך הרכישה נמוכים יותר (כלומר טובים יותר) בסימולציה השנייה הזו. הסיבה לכך היא שיש לכם פחות יעדי מדידה, ולכן יעד המדידה היחיד מקבל עכשיו את כל תקציב התרומה.
- לוחצים על איפוס. עכשיו יש לכם שוב שני יעדי מדידה: ערך הרכישה ומספר הרכישות. שימו לב: Noise Lab מחשב באופן אוטומטי את גורמי ההתאמה לשימוש בהינתן הטווחים (ערכים ממוצעים ומקסימליים) של יעדי המדידה בתרחיש שלכם. כברירת מחדל, Noise Lab מחלק את התקציב באופן שווה בין יעדי המדידה.
- לוחצים על 'סימולציה'.
- בודקים את יחסי הרעש בסימולציה שהתקבלה. רושמים את הגורמים לקביעת קנה המידה שמוצגים בסימולציה.
- עכשיו נתאים אישית את חלוקת תקציב הפרטיות כדי להשיג יחסי אות לרעש טובים יותר.
- משנים את אחוז התקציב שהוקצה לכל יעד מדידה. בהינתן פרמטרי ברירת המחדל, טווח הערכים של יעד המדידה 1, כלומר ערך הרכישה, רחב בהרבה (בין 0 ל-1,000) מטווח הערכים של יעד המדידה 2, כלומר מספר הרכישות (בין 1 ל-1, כלומר תמיד שווה ל-1). לכן, המערכת צריכה "יותר מקום להתרחבות": מומלץ להקצות תקציב תרומה גבוה יותר ליעד המדידה 1 מאשר ליעד המדידה 2, כדי שהמערכת תוכל להרחיב את הפעילות בצורה יעילה יותר (ראו הרחבת הפעילות), וכך
- מקצים 70% מהתקציב ליעד המדידה 1. הקצאת 30% ליעד 2 של המדידה.
- לוחצים על 'סימולציה'.
- בודקים את יחסי הרעש בסימולציה שהתקבלה. במקרה של ערך הרכישה, יחסי האות לרעש נמוכים (טובים) באופן משמעותי בהשוואה לסימולציה הקודמת. במספר הרכישות, השינוי הוא קל.
- ממשיכים לשנות את חלוקת התקציב בין המדדים. בדקו איך זה משפיע על הרעש.
שימו לב שאפשר להגדיר יעדי מדידה מותאמים אישית באמצעות הלחצנים 'הוספה', 'הסרה' ו'איפוס'.
אם אתם מודדים נקודת נתונים אחת (יעד מדידה) באירוע המרה, כמו מספר ההמרות, נקודת הנתונים הזו יכולה לקבל את כל תקציב התרומה (65536). אם מגדירים כמה יעדי מדידה באירוע המרה, כמו מספר המרות וערך רכישה, נקודות הנתונים האלה יצטרכו לחלוק את תקציב התרומה. המשמעות היא שיש לכם פחות גמישות להגדיל את הערכים.
לכן, ככל שיש לכם יותר יעדי מדידה, סביר להניח שיחסי האות לרעש יהיו נמוכים יותר (רעש גבוה יותר).
החלטה נוספת שצריך לקבל לגבי יעדי המדידה היא חלוקת התקציב. אם מחלקים את תקציב התרומה באופן שווה בין שתי נקודות נתונים, כל נקודת נתונים מקבלת תקציב של 65,536/2 = 32,768. יכול להיות שהערך הזה יהיה אופטימלי ויכול להיות שלא, בהתאם לערך המקסימלי האפשרי של כל נקודת נתונים. לדוגמה, אם אתם מודדים את מספר הרכישות עם ערך מקסימלי של 1, ואת ערך הרכישה עם ערך מינימלי של 1 וערך מקסימלי של 120, כדאי להקצות לערך הרכישה יותר מקום כדי להגדיל אותו – כלומר, להקצות לו חלק גדול יותר מתקציב התרומה. תוכלו לראות אם כדאי לתת עדיפות ליעדי מדידה מסוימים על פני אחרים בהתאם להשפעה של הרעש.
החלטה: ניהול חריגים
כדאי לנסות את התכונה ב-Noise Lab
יעד מדידה הוא נקודת נתונים נפרדת שנאספת באירועי המרה.
- עוברים למצב מתקדם.
- בחלונית הצדדית 'פרמטרים', מחפשים את האפשרות 'אסטרטגיית הצבירה שלך' > 'שינוי קנה מידה'.
- מוודאים שההגדרה 'שינוי גודל' מוגדרת ל'כן'. שימו לב: Noise Lab מחשב באופן אוטומטי את גורמי ההתאמה לשימוש, על סמך הטווחים (ערכים ממוצעים ומקסימליים) שציינתם ליעדי המדידה.
- נניח שהרכישה הכי גדולה שבוצעה אי פעם הייתה בסך 2,000$, אבל שרוב הרכישות הן בטווח של 10 $עד 120$. קודם נראה מה קורה אם משתמשים בגישה מילולית להרחבת טווח (לא מומלץ): מזינים 2, 000 $כערך המקסימלי של purchaseValue.
- לוחצים על 'סימולציה'.
- שימו לב שיחסי הרעש גבוהים. הסיבה לכך היא שגורם ההתאמה שלנו מחושב על סמך 2,000$, כשבפועל רוב ערכי הרכישה יהיו נמוכים משמעותית מהסכום הזה.
- עכשיו נשתמש בגישה פרגמטית יותר להרחבת הפעילות. משנים את ערך הרכישה המקסימלי ל-120$.
- לוחצים על 'סימולציה'.
- אפשר לראות שיחסי הרעש נמוכים יותר (כלומר טובים יותר) בסימולציה השנייה.
כדי להטמיע את ההתאמה, בדרך כלל מחשבים גורם התאמה על סמך הערך המקסימלי האפשרי לאירוע המרה נתון (מידע נוסף בדוגמה הזו).
עם זאת, מומלץ להימנע משימוש בערך מקסימלי מילולי כדי לחשב את מקדם ההתאמה הזה, כי זה יפגע ביחסי האות לרעש. במקום זאת, כדאי להסיר ערכים חריגים ולהשתמש בערך מקסימלי פרגמטי.
ניהול חריגים הוא נושא מורכב. יש מספר טכניקות מורכבות שאפשר להשתמש בהן כדי לשפר את יחסי האות לרעש. אחד מהם מתואר במאמר ניהול מתקדם של חריגים.
השלבים הבאים
אחרי שבחנתם אסטרטגיות שונות לניהול רעשי רקע לתרחיש השימוש שלכם, אתם מוכנים להתחיל להתנסות בדוחות סיכום על ידי איסוף נתוני מדידה אמיתיים באמצעות תקופת ניסיון של מקור. כדאי לעיין במדריכים ובטיפים כדי להתנסות ב-API.
נספח
סיור קצר ב-Noise Lab
Noise Lab עוזר לכם להעריך ולהשוות במהירות אסטרטגיות לניהול רעשים. אפשר להשתמש בשיטה הזו כדי:
- להבין את הפרמטרים העיקריים שיכולים להשפיע על הרעש ואת ההשפעה שלהם.
- הדמיה של השפעת הרעש על נתוני המדידה של הפלט בהינתן החלטות שונות לגבי העיצוב. משנים את פרמטרי העיצוב עד שמגיעים ליחס אות לרעש שמתאים לתרחיש לדוגמה.
- נשמח לקבל מכם משוב על התועלת של דוחות הסיכום: אילו ערכים של פרמטרים של אפסילון ורעש מתאימים לכם, ואילו לא? איפה נמצאות נקודות הפיתול?
אפשר לחשוב על זה כשלב הכנה. Noise Lab יוצר נתוני מדידה כדי לדמות את הפלט של דוחות סיכום על סמך הקלט שלכם. הוא לא שומר או משתף נתונים.
יש שני מצבים שונים ב-Noise Lab:
- מצב פשוט: הסבר על הפקדים שזמינים לכם לניהול הרעשים.
- מצב מתקדם: אפשר לבדוק אסטרטגיות שונות לניהול רעשים ולהעריך איזו מהן מובילה ליחסי אות לרעש הכי טובים בתרחישי השימוש שלכם.
לוחצים על הלחצנים בתפריט העליון כדי לעבור בין שני המצבים (מס' 1 בצילום המסך הבא).
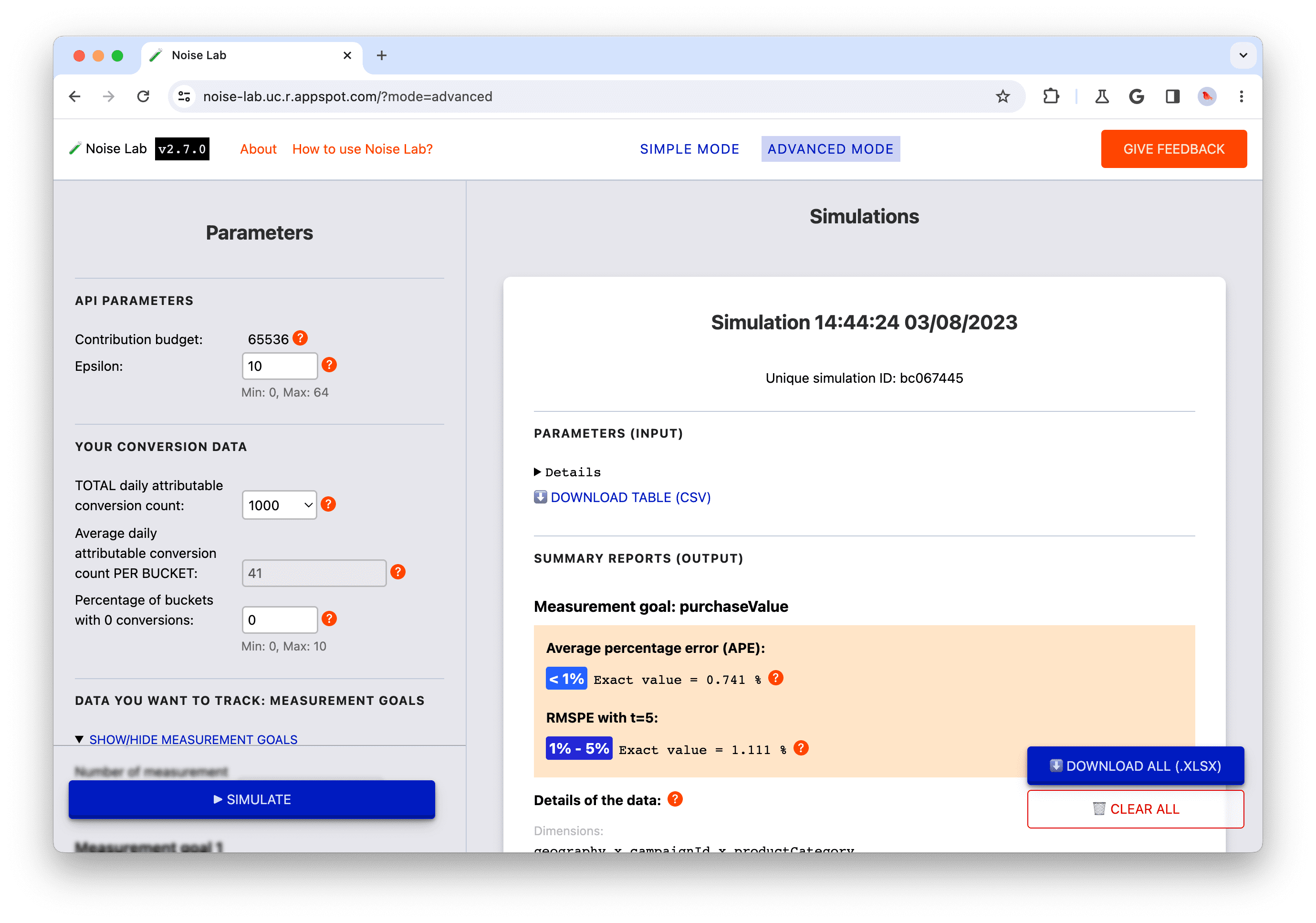
מצב פשוט
- במצב פשוט, אתם שולטים בפרמטרים (שנמצאים בצד ימין, או במספר 2 בצילום המסך הבא) כמו אפסילון, ורואים איך הם משפיעים על הרעש.
- לכל פרמטר יש הסבר קצר (לחצן `?`). לחיצה על הפרמטרים האלה תציג הסבר על כל אחד מהם (מספר 3 בצילום המסך הבא).
- כדי להתחיל, לוחצים על הלחצן Simulate (הדמיה) ומתבוננים בפלט (מספר 4 בצילום המסך הבא).
- בקטע Output (פלט) מוצגים פרטים שונים. לצד חלק מרכיבי ה-XML מופיע סימן השאלה '?'. כדאי להקדיש זמן ללחיצה על כל סימן שאלה '?' כדי לראות הסבר על חלקי המידע השונים.
- בקטע 'פלט', לוחצים על המתג 'פרטים' אם רוצים לראות גרסה מורחבת של הטבלה (מס' 5 בצילום המסך הבא).
- אחרי כל טבלת נתונים בקטע הפלט, יש אפשרות להוריד את הטבלה לשימוש אופליין. בנוסף, בפינה השמאלית התחתונה יש אפשרות להוריד את כל טבלאות הנתונים (מספר 6 בצילום המסך הבא).
- בודקים הגדרות שונות של הפרמטרים בקטע Parameters (פרמטרים) ולוחצים על Simulate (סימולציה) כדי לראות איך הן משפיעות על הפלט:
ממשק Noise Lab במצב Simple (פשוט).
מצב מתקדם
- במצב מתקדם, יש לכם יותר שליטה על הפרמטרים. אפשר להוסיף יעדי מדידה ומאפיינים מותאמים אישית (מספר 1 ומספר 2 בצילום המסך הבא)
- גוללים למטה בקטע 'פרמטרים' ורואים את האפשרות 'שיטת בידינג מרכזית'. אפשר להשתמש בזה כדי לבדוק מבנים שונים של מפתחות
(מס' 3 בצילום המסך הבא)
- כדי לבדוק מבני מפתחות שונים, צריך להחליף את אסטרטגיית המפתחות ל-B.
- מזינים את מספר מבני המפתחות השונים שרוצים להשתמש בהם (ברירת המחדל היא 2)
- לוחצים על Generate Key Structures (יצירת מבני מפתח).
- יוצגו לכם אפשרויות לציין את מבני המפתחות על ידי לחיצה על תיבות הסימון לצד המפתחות שרוצים לכלול בכל מבנה מפתחות.
- לוחצים על 'סימולציה' כדי לראות את הפלט.
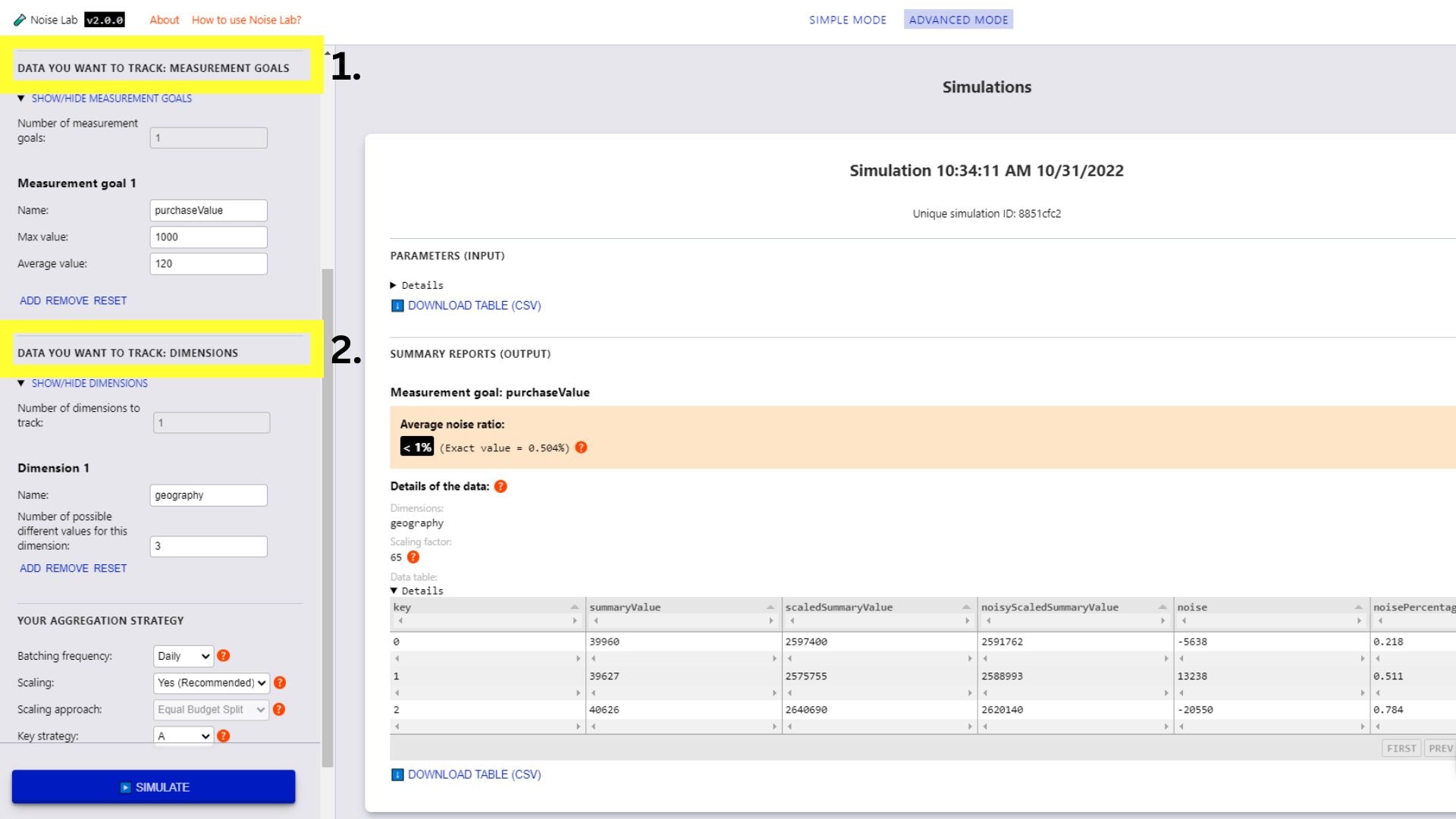
ממשק Noise Lab למצב מתקדם. 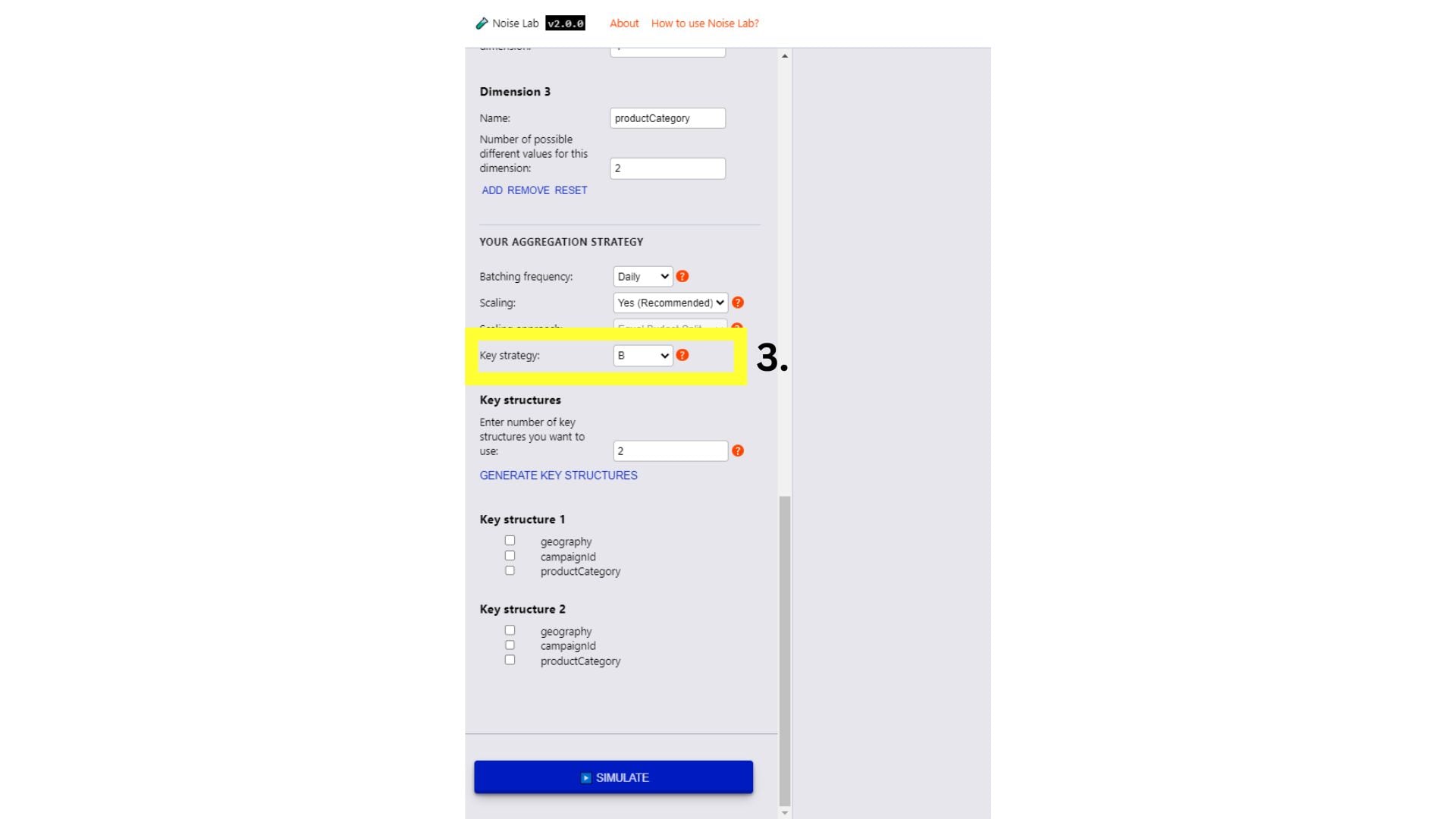
ממשק Noise Lab במצב מתקדם.
מדדי רעש
מושג ליבה
הוספת נתונים מיותרים נועדה להגן על פרטיות המשתמשים.
ערך רעש גבוה מצביע על כך שהקטגוריות או המפתחות דלילים ומכילים תרומות ממספר מוגבל של אירועים רגישים. התהליך הזה מתבצע באופן אוטומטי על ידי Noise Lab, כדי לאפשר לאנשים "להיטמע בקהל". במילים אחרות, המערכת מגנה על הפרטיות של מספר מצומצם של אנשים באמצעות כמות גדולה יותר של נתונים מיותרים.
ערך רעש נמוך מצביע על כך שהגדרת הנתונים תוכננה באופן שמאפשר לאנשים "להיטמע בקהל". כלומר, הדליים מכילים נתונים ממספר מספיק של אירועים כדי לוודא שהפרטיות של המשתמשים נשמרת.
ההצהרה הזו נכונה גם לגבי שגיאת האחוז הממוצעת (APE) וגם לגבי RMSRE_T (שגיאה יחסית של שורש ממוצע הריבועים עם סף).
APE (average percentage error)
ה-APE הוא היחס בין הרעש לבין האות, כלומר ערך הסיכום האמיתי.
ערכים נמוכים יותר של APE מצביעים על יחסי אות לרעש טובים יותר.
נוסחה
בדוח סיכום נתון, ה-APE מחושב באופן הבא:
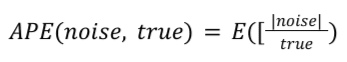
True הוא ערך הסיכום האמיתי. APE הוא הממוצע של הרעש בכל ערך סיכום אמיתי, והוא מחושב כממוצע של כל הרשומות בדוח סיכום. ב-Noise Lab, התוצאה מוכפלת ב-100 כדי לקבל אחוז.
יתרונות וחסרונות
לדליים עם גדלים קטנים יותר יש השפעה לא פרופורציונלית על הערך הסופי של APE. זה עלול להטעות כשמעריכים את הרעש. לכן הוספנו מדד נוסף, RMSRE_T, שנועד לצמצם את המגבלה הזו של APE. פרטים נוספים מופיעים בדוגמאות.
קוד
בודקים את קוד המקור לחישוב APE.
RMSRE_T (שורש טעות יחסית ממוצעת עם סף)
RMSRE_T (שגיאה יחסית של שורש ממוצע הריבועים עם סף) הוא מדד נוסף לרעש.
איך לפרש את הערך RMSRE_T
ערכים נמוכים יותר של RMSRE_T מצביעים על יחסי אות לרעש טובים יותר.
לדוגמה, אם יחס הרעש שמתאים לתרחיש השימוש שלכם הוא 20%, והערך של RMSRE_T הוא 0.2, אתם יכולים להיות בטוחים שרמות הרעש נמצאות בטווח המקובל.
נוסחה
בדוח סיכום נתון, המדד RMSRE_T מחושב באופן הבא:
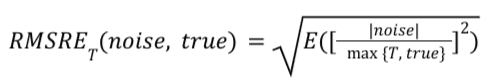
יתרונות וחסרונות
קשה יותר להבין את RMSRE_T מאשר את APE. עם זאת, יש לה כמה יתרונות שבמקרים מסוימים הופכים אותה למתאימה יותר מ-APE לניתוח רעשי רקע בדוחות סיכום:
- RMSRE_T יציב יותר. T הוא ערך סף. האות T משמשת כדי לתת משקל נמוך יותר בחישוב של RMSRE_T לדליים עם פחות המרות, ולכן הם רגישים יותר לרעשי רקע בגלל הגודל הקטן שלהם. בשיטה T, המדד לא מציג עלייה חדה בדליים עם מספר קטן של המרות. אם T שווה ל-5, ערך רעש קטן כמו 1 בדלי עם 0 המרות לא יוצג כגבוה מ-1. במקום זאת, הוא יוגבל ל-0.2, ששווה ל-1/5, כי T שווה ל-5. המדד הזה יציב יותר, ולכן קל יותר להשוות בין שני סימולציות, כי הוא נותן פחות משקל לדליים קטנים יותר שרגישים יותר לרעשי רקע.
- הערך RMSRE_T מאפשר צבירה פשוטה. אם יודעים את RMSRE_T של כמה דליים, יחד עם הספירות האמיתיות שלהם, אפשר לחשב את RMSRE_T של הסכום שלהם. האפשרות הזו מאפשרת גם לבצע אופטימיזציה של RMSRE_T עבור הערכים המשולבים האלה.
אפשר לבצע צבירה של APE, אבל הנוסחה די מסובכת כי היא כוללת את הערך המוחלט של סכום רעשי לפלס. כך קשה יותר לבצע אופטימיזציה של APE.
קוד
בודקים את קוד המקור של החישוב RMSRE_T.
דוגמאות
דוח סיכום עם שלוש קבוצות:
- bucket_1 = noise: 10, trueSummaryValue: 100
- bucket_2 = noise: 20, trueSummaryValue: 100
- bucket_3 = noise: 20, trueSummaryValue: 200
APE = (0.1 + 0.2 + 0.1) / 3 = 13%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,200))^2) / 3) = sqrt( (0.01 + 0.04 + 0.01) / 3) = 0.14
דוח סיכום עם שלוש קבוצות:
- bucket_1 = noise: 10, trueSummaryValue: 100
- bucket_2 = noise: 20, trueSummaryValue: 100
- bucket_3 = noise: 20, trueSummaryValue: 20
APE = (0.1 + 0.2 + 1) / 3 = 43%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,20))^2) / 3) = sqrt( (0.01 + 0.04 + 1.0) / 3) = 0.59
דוח סיכום עם שלוש קבוצות:
- bucket_1 = noise: 10, trueSummaryValue: 100
- bucket_2 = noise: 20, trueSummaryValue: 100
- bucket_3 = noise: 20, trueSummaryValue: 0
APE = (0.1 + 0.2 + Infinity) / 3 = Infinity
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,0))^2) / 3) = sqrt( (0.01 + 0.04 + 16.0) / 3) = 2.31
ניהול מתקדם של מפתחות
יכול להיות שלפלטפורמת DSP או לחברה למדידת ביצועי מודעות יש אלפי לקוחות פרסום גלובליים, שפועלים בתחומים שונים, משתמשים במטבעות שונים ויש להם פוטנציאלים שונים למחיר רכישה. המשמעות היא שיצירה וניהול של מפתח צבירה אחד לכל מפרסם כנראה לא יהיו מעשיים. בנוסף, יהיה קשה לבחור ערך מקסימלי שניתן לצבירה ותקציב צבירה שיכולים להגביל את ההשפעה של הרעש על אלפי המפרסמים האלה ברחבי העולם. במקום זאת, נבחן את התרחישים הבאים:
אסטרטגיה מרכזית א'
ספק טכנולוגיית הפרסום מחליט ליצור ולנהל מפתח אחד לכל הלקוחות שלו בתחום הפרסום. בקרב כל המפרסמים ובכל המטבעות, טווח הרכישות משתנה מרכישות בנפח נמוך וערך גבוה לרכישות בנפח גבוה וערך נמוך. התוצאה היא המפתח הבא:
| מפתח (ריבוי מטבעות) | |
|---|---|
| ערך מקסימלי שניתן לצבירה | 5,000,000 |
| טווח ערכי רכישה | [120 - 5000000] |
אסטרטגיה מרכזית ב'
ספק טכנולוגיית הפרסום מחליט ליצור ולנהל שני מפתחות בכל הלקוחות שלו בתחום הפרסום. הם מחליטים להפריד בין המקשים לפי מטבע. בקרב כל המפרסמים ובכל המטבעות, טווח הרכישות משתנה מרכישות בנפח נמוך וברמה גבוהה לרכישות בנפח גבוה וברמה נמוכה. הם יוצרים 2 מפתחות, לפי המטבע:
| מפתח 1 (דולר ארה"ב) | מקש 2 (¥) | |
|---|---|---|
| ערך מקסימלי שניתן לצבירה | 40,000$ | 5,000,000 ין |
| טווח ערכי רכישה | [120 - 40,000] | [15,000 עד 5,000,000] |
לשיטת הבידינג המרכזית ב' יהיה פחות רעש בתוצאה מאשר לשיטת הבידינג המרכזית א', כי ערכי המטבע לא מפוזרים באופן אחיד בין המטבעות. לדוגמה, כדאי לחשוב איך רכישות שמתבצעות בין ישולבו עם רכישות שמתבצעות בדולר ארה"ב, וישנו את הנתונים הבסיסיים ואת הפלט הרועש שיתקבל.
אסטרטגיה מרכזית ג'
ספק טכנולוגיות הפרסום מחליט ליצור ולנהל ארבעה מפתחות אצל כל לקוחות הפרסום שלו, ולהפריד ביניהם לפי מטבע x ענף המפרסם:
| מילת מפתח 1 (USD x מפרסמים של תכשיטים יוקרתיים) |
מקש 2 (¥ x מפרסמים של תכשיטים יוקרתיים) |
מילת מפתח 3 (מפרסמים של קמעונאי בגדים בארה"ב) |
מקש 4 (¥ x מפרסמים קמעונאיים של בגדים) |
|
|---|---|---|---|---|
| ערך מקסימלי שניתן לצבירה | 40,000$ | 5,000,000 ין | 2,000 ש"ח | ¥65,000 |
| טווח ערכי רכישה | [10,000 – 40,000] | [1,250,000 - 5,000,000] | [120 - 500] | [15,000 עד 65,000] |
התוצאה של אסטרטגיה C תהיה פחות רועשת מזו של אסטרטגיה B, כי ערכי הרכישה של המפרסמים לא מפוזרים באופן אחיד בין המפרסמים. לדוגמה, תחשבו איך רכישות של תכשיטים יוקרתיים יחד עם רכישות של כובעי בייסבול ישנו את הנתונים הבסיסיים ואת הפלט הרועש שיתקבל.
כדי לצמצם את הרעש בתוצאה, כדאי ליצור ערכים משותפים מקסימליים מצטברים וגורמי קנה מידה משותפים למאפיינים משותפים של כמה מפרסמים. לדוגמה, תוכלו לנסות את השיטות הבאות עבור המפרסמים שלכם:
- שיטה אחת שמופרדת לפי מטבע (USD, ¥, CAD וכו')
- אסטרטגיה אחת שמחולקת לפי תחום העיסוק של המפרסם (ביטוח, רכב, קמעונאות וכו')
- שיטה אחת שמופרדת על ידי טווחי ערכי רכישה דומים ([100], [1000], [10000] וכו')
כשיוצרים אסטרטגיות מפתח סביב המאפיינים המשותפים של המפרסמים, קל יותר לנהל את המפתחות ואת הקוד התואם, ויחס האות לרעש עולה. כדאי להתנסות בשיטות שונות עם מאפיינים משותפים שונים של מפרסמים כדי לגלות נקודות מפנה במקסום ההשפעה של הרעש לעומת ניהול הקוד.
ניהול מתקדם של חריגים
נבחן תרחיש שבו יש שני מפרסמים:
- מפרסם א':
- בכל המוצרים באתר של מפרסם א', טווח המחירים האפשריים הוא [$120 – $1,000] , כלומר טווח של $880.
- מחירי הרכישה מתפלגים באופן שווה בטווח של 880$, ללא חריגים מחוץ לשתי סטיות תקן ממחיר הרכישה החציוני.
- מפרסם ב':
- בכל המוצרים באתר של מפרסם ב', טווח המחירים האפשריים הוא [$120 - $1,000] , כלומר טווח של $880.
- מחירי הרכישה נוטים מאוד לכיוון הטווח של 120 $עד 500$, ורק 5% מהרכישות מתרחשות בטווח של 500 $עד 1,000$.
בהתחשב בדרישות התקציב לתרומה ובמתודולוגיה שבה מוסיפים רעש לתוצאות הסופיות, כברירת מחדל, התוצאות של מפרסם ב' יהיו רועשות יותר מאלה של מפרסם א', כי למפרסם ב' יש פוטנציאל גבוה יותר לחריגים להשפיע על החישובים הבסיסיים.
אפשר לצמצם את הסיכון הזה באמצעות הגדרת מפתח ספציפית. כדאי לבדוק אסטרטגיות מרכזיות שיעזרו לכם לנהל נתונים חריגים ולחלק את ערכי הרכישה בצורה אחידה יותר בטווח הרכישה של מילת המפתח.
מפרסם ב' יכול ליצור שני מפתחות נפרדים כדי לתעד שני טווחי ערכים שונים של רכישות. בדוגמה הזו, הטכנולוגיה לפרסום זיהתה חריגים מעל ערך הרכישה של 500$. כדאי להטמיע שני מפתחות נפרדים עבור המפרסם הזה:
- מבנה מפתח 1 : מפתח שמתעד רק רכישות בטווח של 120 $עד 500$ (מכסה כ-95% מנפח הרכישות הכולל).
- מבנה מפתח 2: מפתח שמתעד רק רכישות מעל 500 $ (מכסה כ-5% מנפח הרכישות הכולל).
הטמעה של האסטרטגיה החשובה הזו תעזור למפרסם ב' לנהל טוב יותר את הרעש, ולמקסם את התועלת שהוא יכול להפיק מדוחות הסיכום. בהינתן הטווחים החדשים והקטנים יותר, עכשיו אמורה להיות למפתח א' ולמפתח ב' התפלגות נתונים אחידה יותר בכל מפתח בהשוואה למפתח היחיד הקודם. התוצאה תהיה פחות רעשי רקע בפלט של כל מפתח בהשוואה למפתח יחיד קודם.