
このドキュメントについて
このドキュメントを読むことで、次のことがわかります。
- 概要レポートを生成する前に、作成する戦略を理解します。
- さまざまなノイズ パラメータの影響を把握し、さまざまなノイズ管理戦略を迅速に調査して評価できるツールである Noise Lab について説明します。
フィードバックをお寄せください
このドキュメントでは、要約レポートを扱うためのいくつかの原則をまとめていますが、ノイズ管理にはさまざまなアプローチがあり、このドキュメントに反映されていないものもあります。ご提案、追加、ご質問をお待ちしております。
- ノイズ管理戦略、API の有用性やプライバシー(イプシロン)について公開でフィードバックを送信する場合、または Noise Lab でシミュレーションを行った際の観察結果を共有する場合は、この問題にコメントしてください。
- API の別の側面について公開フィードバックを送信するには: こちらで新しい問題を登録してください。
始める前に
- 概要については、アトリビューション レポート: 概要レポートとアトリビューション レポートのシステム全体の概要をご覧ください。
- このガイドを最大限に活用するには、ノイズについてと集計キーについてをご覧ください。
設計上の意思決定
基本的な設計原則
サードパーティ Cookie とサマリー レポートの動作には根本的な違いがあります。主な違いは、概要レポートの測定データに追加されるノイズです。もう 1 つは、レポートのスケジュール設定です。
シグナル対ノイズ比の高いサマリー レポートの測定データにアクセスするには、デマンドサイド プラットフォーム(DSP)と広告測定プロバイダが広告主様と協力してノイズ管理戦略を策定する必要があります。こうした戦略を策定するには、DSP と測定プロバイダが設計上の判断を下す必要があります。これらの決定は、1 つの重要なコンセプトを中心に展開されます。
厳密に言えば、ノイズ値の分布は 2 つのパラメータ(イプシロンと貢献度予算)のみに依存しますが、出力測定データの信号対雑音比に影響する他の多くの制御も利用できます。
反復プロセスが最善の決定につながると考えられますが、これらの決定のバリエーションごとに実装が若干異なるため、各コードの反復処理(および広告の掲載)の前にこれらの決定を行う必要があります。
決定: ディメンションの粒度
Noise Lab で試す
- 詳細モードに移動します。
- [パラメータ] サイドパネルで、[コンバージョン データ] を探します。
- デフォルトのパラメータを確認します。デフォルトでは、1 日あたりの合計貢献度割り当てコンバージョン数は 1, 000 件です。デフォルト設定(デフォルトのディメンション、各ディメンションの可能な異なる値のデフォルト数、キー戦略 A)を使用する場合、バケットあたり約 40 個になります。入力の [1 日の平均アトリビューション コンバージョン数(バケットごと)] の値が 40 になっていることを確認します。
- [シミュレーション] をクリックして、デフォルトのパラメータでシミュレーションを実行します。
- [パラメータ] サイドパネルで、[ディメンション] を探します。[Geography] の名前を [City] に変更し、異なる値の数を 50 に変更します。
- これにより、バケットあたりの平均アトリビューション コンバージョン数がどのように変化するかを確認します。現在は大幅に減少しています。これは、このディメンション内の可能な値の数を増やしても、他の値が変更されない場合、各バケットに分類されるコンバージョン イベントの数は変わらずに、バケットの合計数が増えるためです。
- [シミュレーション] をクリックします。
- シミュレーションの結果のノイズ比を観察します。ノイズ比が前のシミュレーションよりも高くなっています。
コア設計原則を考慮すると、小さい概要値は大きい概要値よりもノイズが多くなる可能性があります。そのため、構成の選択は、各バケット(集計キーとも呼ばれます)に分類されるアトリビューション コンバージョン イベントの数に影響します。この数は、最終的な出力概要レポートのノイズに影響します。
1 つのバケット内のアトリビューション コンバージョン イベントの数に影響する設計上の決定の 1 つは、ディメンションの粒度です。集計キーとそのディメンションの例を次に示します。
- アプローチ 1: 粗いディメンションを含む 1 つのキー構造: 国 × 広告キャンペーン(または最大のキャンペーン集計バケット)× 商品タイプ(10 個の商品タイプのうちの 1 つ)
- アプローチ 2: 粒度の細かいディメンションを含む 1 つのキー構造: 市区町村 × クリエイティブ ID × 商品(100 個の商品から選択)
「都市」は「国」よりも詳細なディメンションです。「クリエイティブ ID」は「キャンペーン」よりも詳細なディメンションです。「商品」は「商品カテゴリ」よりも詳細なディメンションです。そのため、アプローチ 2 では、アプローチ 1 よりも、バケット(キー)あたりのイベント数(コンバージョン数)が少ないサマリー レポートが出力されます。出力に追加されるノイズはバケット内のイベント数とは無関係であるため、アプローチ 2 では概要レポートの測定データにノイズが多くなります。広告主ごとに、結果の有用性を最大限に高めるため、キーの設計でさまざまな粒度のトレードオフをテストします。
決定: 主要な構造
Noise Lab で試す
シンプル モードでは、デフォルトのキー構造が使用されます。詳細モードでは、さまざまなキー構造を試すことができます。ディメンションの例がいくつか含まれています。これらは変更することもできます。
- 詳細モードに移動します。
- [パラメータ] サイドパネルで、[Key strategy] を探します。ツールで A という名前のデフォルトの戦略は、すべてのディメンション(地域 × キャンペーン ID × 商品カテゴリ)を含む 1 つの粒度の細かいキー構造を使用していることに注意してください。
- [シミュレーション] をクリックします。
- シミュレーションの結果のノイズ比を観察します。
- Key 戦略を B に変更します。鍵構造を構成するための追加のコントロールが表示されます。
- キー構造を次のように構成します。
- キー構造の数: 2
- キー構造 1 = 地域 x 商品カテゴリ。
- キー構造 2 = キャンペーン ID × 商品カテゴリ。
- [シミュレーション] をクリックします。
- 2 つの異なるキー構造を使用しているため、測定目標タイプごとに 2 つの概要レポート(購入数用に 2 つ、購入額用に 2 つ)が生成されます。ノイズ比率を観察します。
- 独自のカスタム ディメンションでもお試しいただけます。これを行うには、[追跡するデータ: ディメンション] を探します。最後のディメンションの下にある追加、削除、リセットのボタンを使用して、サンプル ディメンションを削除し、独自のディメンションを作成することを検討してください。
単一バケット内のアトリビューション コンバージョン イベントの数に影響するもう 1 つの設計上の決定は、使用するキー構造です。集計キーの例を次に示します。
- すべてのディメンションを含む 1 つのキー構造(キー戦略 A とします)。
- 2 つの主要な構造(それぞれにディメンションのサブセットが含まれます)。これを「主要な戦略 B」と呼びます。
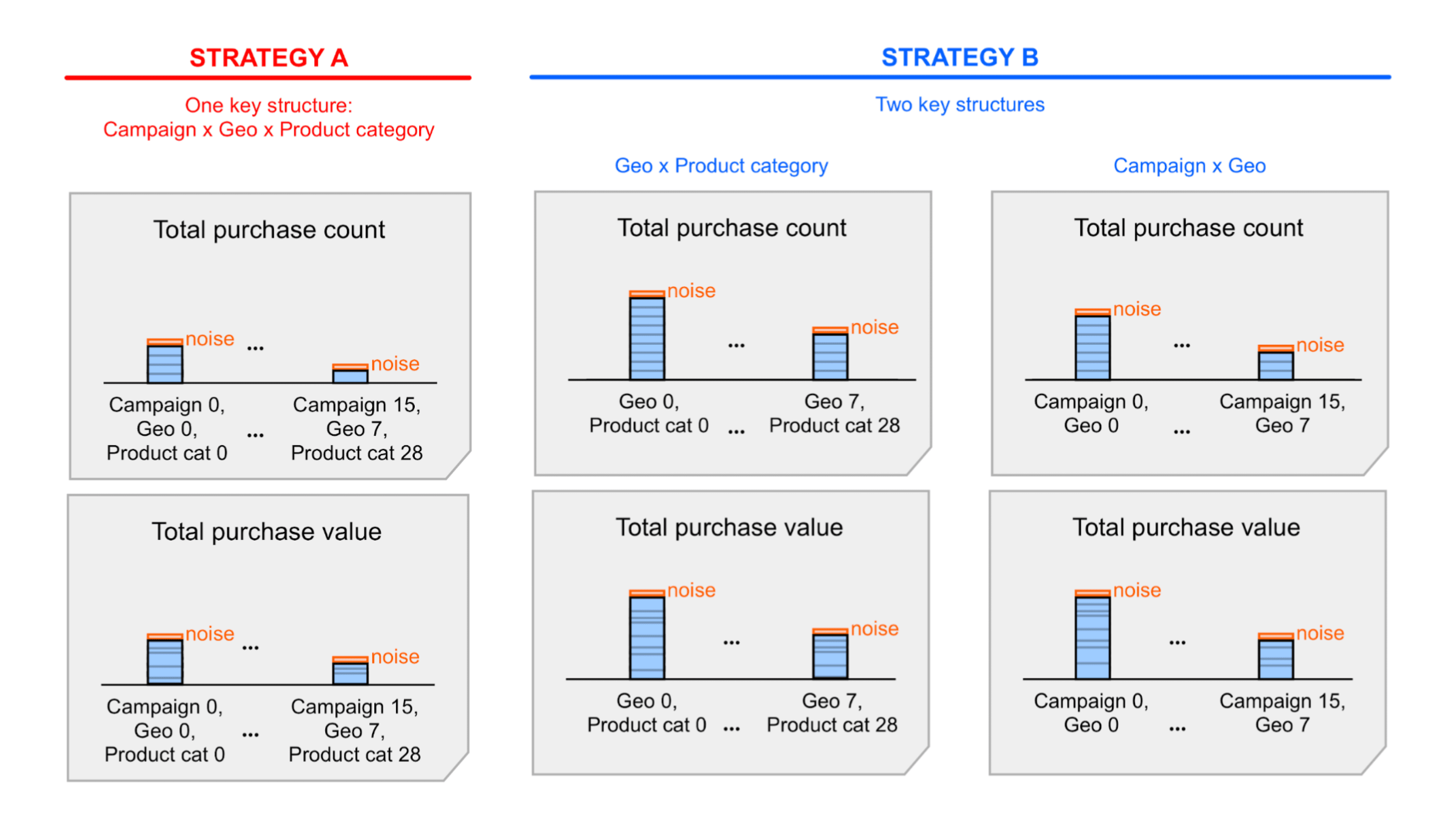
戦略 A はよりシンプルですが、特定の分析情報にアクセスするには、概要レポートに含まれるノイズの多い概要値をロールアップ(合計)する必要があります。これらの値を合計すると、ノイズも合計されます。戦略 B では、概要レポートに表示される概要値から必要な情報を得られる可能性があります。つまり、戦略 B の方が戦略 A よりもシグナル対ノイズ比が優れている可能性が高くなります。ただし、戦略 A でノイズが許容範囲内である可能性もあるため、シンプルさを重視して戦略 A を選択することもできます。これらの 2 つの戦略の概要を示す詳細な例をご覧ください。
鍵管理は奥深いトピックです。信号対雑音比を改善するために、さまざまな高度な手法を検討できます。1 つは高度な鍵管理で説明されています。
決定: バッチ処理の頻度
Noise Lab で試す
- [Simple] モード(または [Advanced] モード。バッチ処理の頻度に関してはどちらのモードも同じように動作します)に移動します。
- [パラメータ] サイドパネルで、[集計戦略] > [バッチ処理の頻度] を探します。これは、単一のジョブで集計サービスによって処理される集計可能レポートのバッチ処理頻度を指します。
- デフォルトのバッチ処理の頻度を確認します。デフォルトでは、1 日 1 回のバッチ処理の頻度がシミュレートされます。
- [シミュレーション] をクリックします。
- シミュレーションの結果のノイズ比を観察します。
- バッチ処理の頻度を週単位に変更します。
- シミュレーションの結果のノイズ比を観察します。ノイズ比が以前のシミュレーションよりも低くなっています(改善されています)。
1 つのバケット内のアトリビューション コンバージョン イベントの数に影響する別の設計上の決定事項は、使用するバッチ処理の頻度です。バッチ処理の頻度は、集計可能なレポートを処理する頻度です。
集計頻度が高い(1 時間ごとなど)ようにスケジュールされたレポートには、集計頻度が低い(1 週間ごとなど)ようにスケジュールされた同じレポートよりも、含まれるコンバージョン イベントの数が少なくなります。その結果、時間単位のレポートにはノイズが多く含まれ、集計スケジュールが頻繁でない(毎週など)同じレポートよりもコンバージョン イベントの数が少なくなります。その結果、他の条件が同じであれば、時間単位のレポートは週単位のレポートよりも信号対雑音比が低くなります。さまざまな頻度でレポートの要件を試し、それぞれのシグナル対ノイズ比を評価します。
決定: 割り当て可能なコンバージョンに影響するキャンペーン変数
Noise Lab で試す
この予測は難しく、季節性の影響に加えて大きな変動が生じる可能性がありますが、1 日のシングルタッチ アトリビューション コンバージョン数を 10 の累乗(10、100、1,000、10,000)に最も近い値で推定してみてください。
- 詳細モードに移動します。
- [パラメータ] サイドパネルで、[コンバージョン データ] を探します。
- デフォルトのパラメータを確認します。デフォルトでは、1 日あたりの合計貢献度割り当てコンバージョン数は 1, 000 件です。デフォルト設定(デフォルトのディメンション、各ディメンションの可能な異なる値のデフォルト数、キー戦略 A)を使用する場合、バケットあたり約 40 個になります。入力の [1 日の平均アトリビューション コンバージョン数(バケットごと)] の値が 40 になっていることを確認します。
- [シミュレーション] をクリックして、デフォルトのパラメータでシミュレーションを実行します。
- シミュレーションの結果のノイズ比を観察します。
- 次に、1 日あたりの合計アトリビューション コンバージョン数を 100 に設定します。これにより、バケットあたりの 1 日の平均アトリビューション コンバージョン数が減少します。
- [シミュレーション] をクリックします。
- ノイズ比率が高くなっていることに注目してください。これは、バケットあたりのコンバージョン数が少ない場合、プライバシーを保護するためにノイズがより多く適用されるためです。
重要な違いは、広告主様が獲得できるコンバージョンの総数と、アトリビューションされるコンバージョンの総数です。後者が最終的に概要レポートのノイズに影響します。アトリビューション コンバージョンは、広告予算や広告のターゲティングなどのキャンペーン変数に影響を受けやすいコンバージョンの合計数の一部です。たとえば、他の条件が同じであれば、1,000 万ドルの広告キャンペーンでは、1 万ドルの広告キャンペーンよりもコンバージョン数が多くなることが予想されます。
注意点:
- アトリビューション レポート API で収集された概要レポートの範囲内であるため、単一タッチの同一デバイス アトリビューション モデルに対して、アトリビューションされたコンバージョンを評価します。
- アトリビューション コンバージョンについて、最悪のシナリオのカウントと最良のシナリオのカウントの両方を検討します。たとえば、他の条件がすべて同じであると仮定して、広告主様のキャンペーン予算の最小値と最大値を検討し、両方の結果について、シミュレーションの入力として貢献度を割り当てられるコンバージョン数を予測します。
- Android プライバシー サンドボックスの使用を検討している場合は、計算でクロス プラットフォームのコンバージョンを考慮してください。
決定: スケーリングを使用する
Noise Lab で試す
- 詳細モードに移動します。
- [パラメータ] サイドパネルで、[集計戦略] > [スケーリング] を探します。デフォルトでは [Yes] に設定されています。
- スケーリングがノイズ比に与えるプラスの効果を理解するために、まずスケーリングを [No] に設定します。
- [シミュレーション] をクリックします。
- シミュレーションの結果のノイズ比を観察します。
- [スケーリング] を [はい] に設定します。Noise Lab は、シナリオの測定目標の範囲(平均値と最大値)に基づいて、使用するスケーリング ファクタを自動的に計算します。実際のシステムやオリジン トライアルの設定では、スケーリング係数の独自の計算を実装する必要があります。
- [シミュレーション] をクリックします。
- この 2 回目のシミュレーションでは、ノイズ比が低くなっている(改善されている)ことがわかります。これは、スケーリングを使用しているためです。
コア設計原則を踏まえると、追加されるノイズは貢献予算の関数です。
そのため、信号対雑音比を上げるために、コンバージョン イベント中に収集された値を、貢献予算に対してスケーリング(集計後にスケーリング解除)して変換できます。スケーリングを使用して、信号対雑音比を増やします。
決定: 測定目標の数とプライバシー予算の分割
これはスケーリングに関連しています。スケーリングの使用をご覧ください。
Noise Lab で試す
測定目標は、コンバージョン イベントで収集される個別のデータポイントです。
- 詳細モードに移動します。
- [パラメータ] サイドパネルで、[追跡するデータ: 測定目標] を探します。デフォルトでは、購入額と購入数の 2 つの測定目標があります。
- [シミュレーション] をクリックして、デフォルトの目標でシミュレーションを実行します。
- [削除] をクリックします。これにより、最後の測定目標(この場合は購入数)が削除されます。
- [シミュレーション] をクリックします。
- この 2 回目のシミュレーションでは、購入額のノイズ比が低くなっている(改善されている)ことがわかります。これは、測定目標が少ないため、1 つの測定目標にすべての貢献度予算が割り当てられるためです。
- [リセット] をクリックします。これで、購入額と購入数の 2 つの測定目標が再び設定されました。ノイズラボでは、シナリオの測定目標の範囲(平均値と最大値)に基づいて、使用するスケーリング ファクタが自動的に計算されます。デフォルトでは、Noise Lab は測定目標間で予算を均等に分割します。
- [シミュレーション] をクリックします。
- シミュレーションの結果のノイズ比を観察します。シミュレーションに表示されるスケーリング ファクタをメモします。
- 次に、プライバシー バジェットの分割をカスタマイズして、SN 比を改善します。
- 各測定目標に割り当てられた予算の割合を調整します。デフォルトのパラメータが指定されている場合、測定目標 1(購入額)の範囲は 0 ~ 1,000 と、測定目標 2(購入数)の範囲(1 ~ 1、つまり常に 1)よりもはるかに広くなります。そのため、「拡大する余地」が必要です。測定目標 1 に測定目標 2 よりも多くの貢献度予算を割り当てるのが理想的です。そうすることで、より効率的に拡大できます(スケーリングを参照)。
- 予算の 70% を測定目標 1 に割り当てます。測定の目標 2 に 30% を割り当てます。
- [シミュレーション] をクリックします。
- シミュレーションの結果のノイズ比を観察します。購入額については、ノイズ比が以前のシミュレーションよりも大幅に低くなっています(改善されています)。購入数はほぼ変化していません。
- 指標間で予算の配分を調整し続けます。ノイズにどのような影響があるかを確認します。
[追加/削除/リセット] ボタンを使用すると、独自のカスタム測定目標を設定できます。
コンバージョン イベントで 1 つのデータポイント(測定目標)を測定する場合(コンバージョン数など)、そのデータポイントはすべての貢献度予算(65,536)を取得できます。コンバージョン イベントに複数の測定目標(コンバージョン数や購入額など)を設定した場合、これらのデータポイントは貢献度予算を共有する必要があります。つまり、値をスケールアップする余地が少なくなります。
したがって、測定目標が多いほど、SN 比が低くなる(ノイズが多くなる)可能性が高くなります。
測定目標に関して決定すべきもう 1 つの事項は、予算の分割です。貢献度予算を 2 つのデータポイントに均等に分割すると、各データポイントの予算は 65536/2 = 32768 になります。この値は、各データポイントの最大値によっては最適でない可能性があります。たとえば、最大値が 1 の購入数と、最小値が 1 で最大値が 120 の購入額を測定している場合、購入額は「より大きな幅」でスケールアップされる、つまり貢献度予算のより大きな割合が割り当てられるというメリットがあります。ノイズの影響を考慮して、他の測定目標よりも優先すべき測定目標があるかどうかがわかります。
決定: 外れ値の管理
Noise Lab で試す
測定目標は、コンバージョン イベントで収集される個別のデータポイントです。
- 詳細モードに移動します。
- [パラメータ] サイドパネルで、[集約戦略] > [スケーリング] を探します。
- [スケーリング] が [はい] に設定されていることを確認します。ノイズラボでは、測定目標に指定した範囲(平均値と最大値)に基づいて、使用するスケーリング ファクタが自動的に計算されます。
- 過去の最大購入額が 2, 000 ドルで、ほとんどの購入額が 10 ~ 120 ドルの範囲内であるとします。まず、リテラル スケーリング アプローチ(非推奨)を使用した場合にどうなるかを見てみましょう。purchaseValue の最大値として $2, 000 を入力します。
- [シミュレーション] をクリックします。
- ノイズ比が高いことを確認します。これは、スケーリング係数が $2, 000 に基づいて計算されるためです。実際には、ほとんどの購入額はそれよりも大幅に低くなります。
- では、より実用的なスケーリング アプローチを使用してみましょう。購入上限額を $120 に変更します。
- [シミュレーション] をクリックします。
- この 2 回目のシミュレーションでは、ノイズ比が低くなっている(良好である)ことがわかります。
スケーリングを実装するには、通常、特定のコンバージョン イベントの最大可能値に基づいてスケーリング係数を計算します(この例で詳細をご確認ください)。
ただし、このスケーリング係数を計算するためにリテラルの最大値を使用することは避けてください。信号対雑音比が悪化する可能性があります。代わりに、外れ値を削除し、実用的な最大値を使用します。
外れ値の管理は奥深いトピックです。信号対雑音比を改善するために、さまざまな高度な手法を検討できます。1 つは高度な外れ値管理で説明されています。
次のステップ
ユースケースのさまざまなノイズ管理戦略を評価したので、オリジン トライアルを使用して実際の測定データを収集し、要約レポートのテストを開始する準備が整いました。API を試すためのガイドとヒントを確認する。
付録
Noise Lab のクイックツアー
ノイズラボを使用すると、ノイズ管理戦略をすばやく評価して比較できます。適した用途:
- ノイズに影響を与える可能性のある主なパラメータと、それらの影響を理解します。
- さまざまな設計上の意思決定に基づいて、出力測定データに対するノイズの影響をシミュレートします。ユースケースに適した信号対雑音比になるまで、設計パラメータを調整します。
- 要約レポートの有用性についてフィードバックをお寄せください。イプシロンとノイズ パラメータのどの値が機能し、どの値が機能しないかをお知らせください。転換点はどこですか?
これは準備ステップと見なされます。Noise Lab は、入力に基づいて概要レポートの出力をシミュレートするための測定データを生成します。データは保存も共有もされません。
ノイズラボには 2 つのモードがあります。
- シンプル モード: ノイズに関するコントロールの基本を理解します。
- 高度なモード: さまざまなノイズ管理戦略をテストし、ユースケースで最適な信号対雑音比を実現する戦略を評価します。
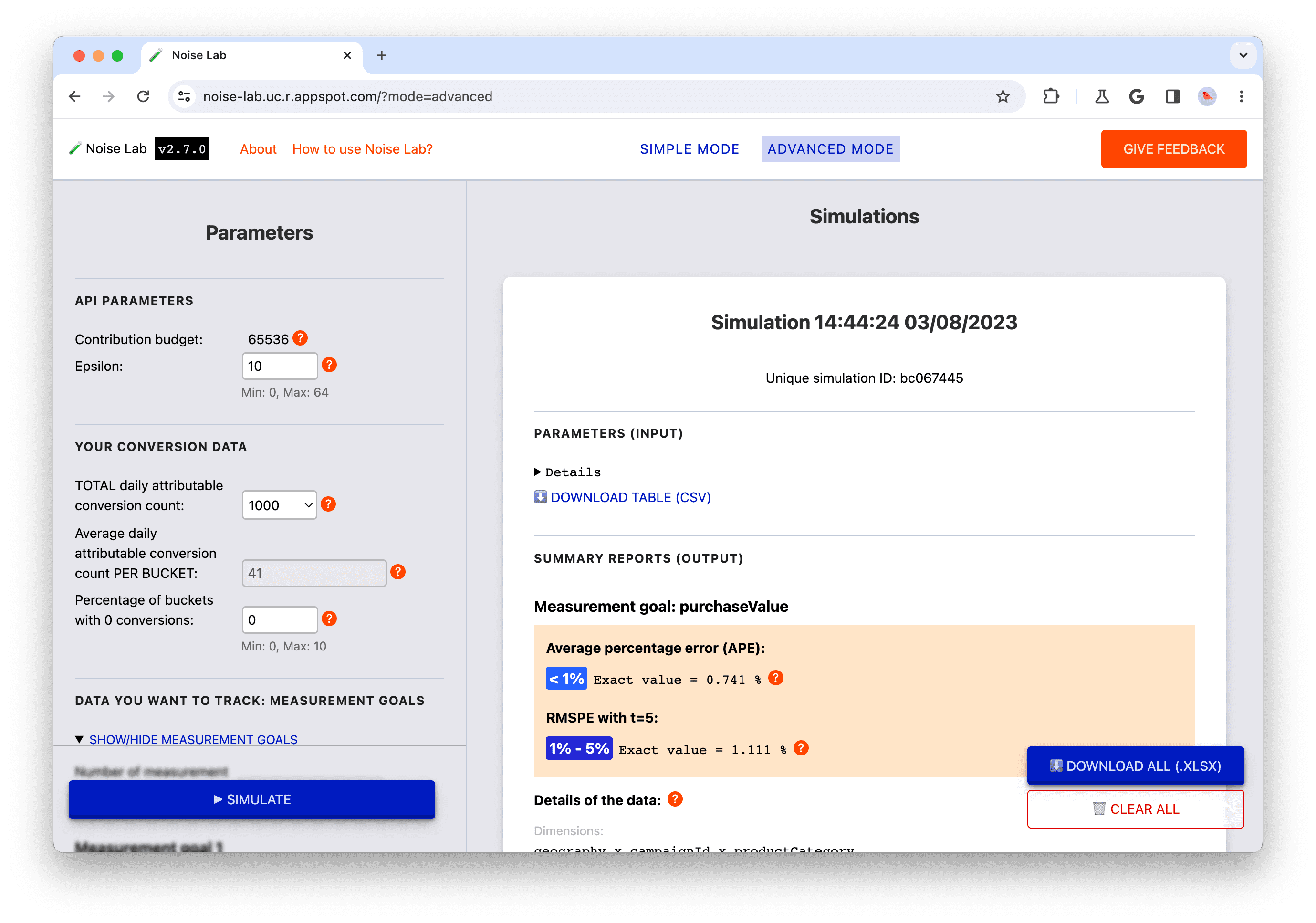
上部のメニューにあるボタンをクリックして、2 つのモードを切り替えます(次のスクリーンショットの#1)。
シンプル モード
- シンプルモードでは、イプシロンなどのパラメータ(左側、または次のスクリーンショットの#2)を制御し、ノイズにどのように影響するかを確認できます。
- 各パラメータにはツールチップ(`?` ボタン)があります。各パラメータの説明を表示するには、これらのパラメータをクリックします(次のスクリーンショットの#3)。
- まず、[シミュレート] ボタンをクリックして、出力がどのように表示されるかを確認します(次のスクリーンショットの#4)。
- [出力] セクションには、さまざまな詳細が表示されます。一部の要素には `?` が付いています。各 `?` をクリックして、さまざまな情報の説明を確認してください。
- [出力] セクションで、テーブルの展開バージョンを表示する場合は、[詳細] 切り替えをクリックします(次のスクリーンショットの#5)。
- 出力セクションの各データテーブルの下に、テーブルをダウンロードしてオフラインで使用するためのオプションがあります。また、右下にはすべてのデータテーブルをダウンロードするオプションがあります(次のスクリーンショットの#6)。
- [パラメータ] セクションでパラメータのさまざまな設定をテストし、[シミュレート] をクリックして出力への影響を確認します。
シンプル モードのノイズラボ インターフェース。
詳細モード
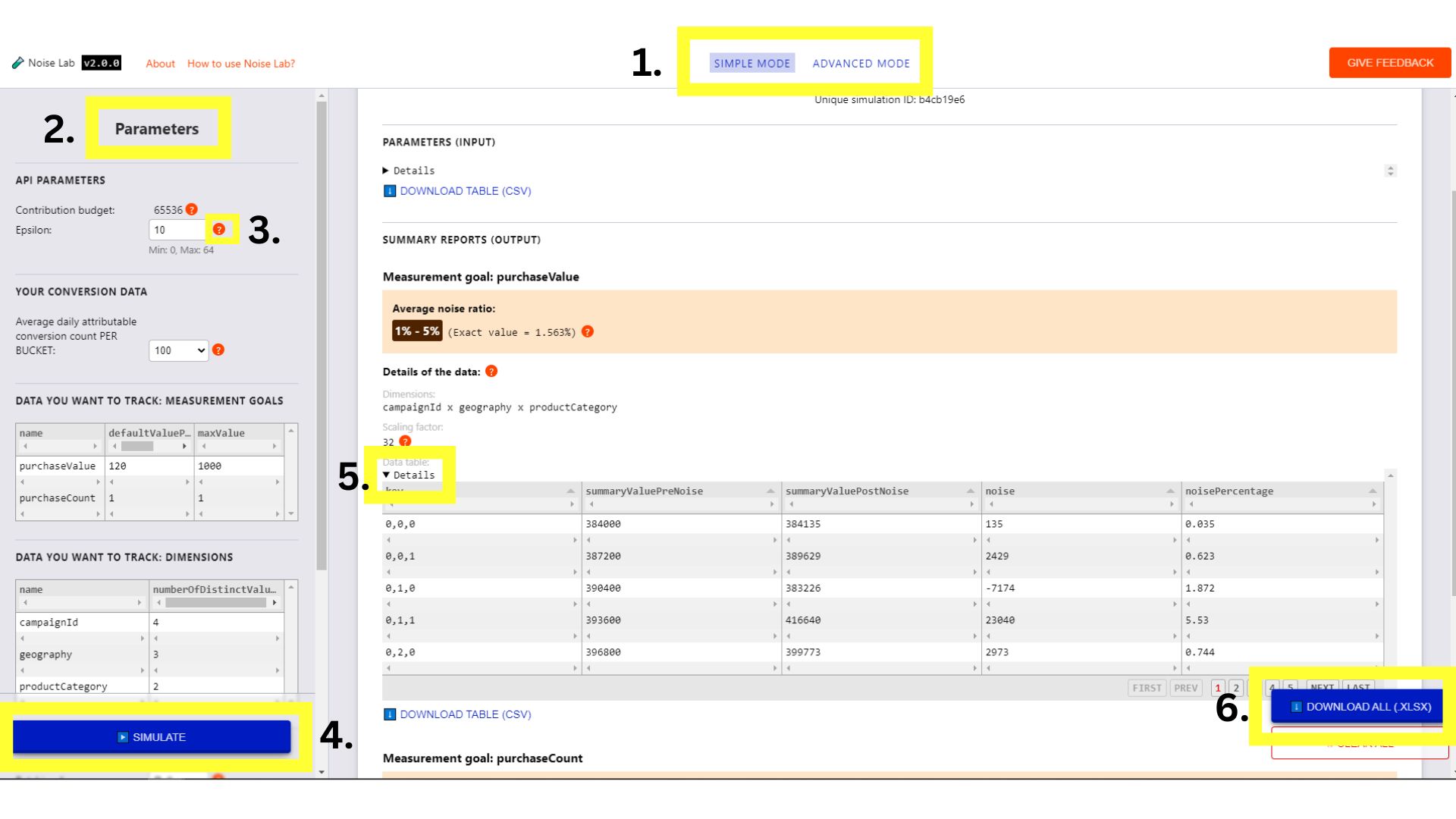
- [詳細] モードでは、パラメータをより詳細に制御できます。カスタムの測定目標とディメンションを追加できます(次のスクリーンショットの 1 と 2)。
- [パラメータ] セクションをさらに下にスクロールして、[主要な戦略] オプションを表示します。これは、さまざまなキー構造をテストするために使用できます(次のスクリーンショットの#3)。
- さまざまなキー構造をテストするには、キー戦略を「B」に切り替えます。
- 使用するさまざまなキー構造の数を入力します(デフォルトは「2」に設定されています)。
- [Generate Key Structures](キー構造を生成)をクリックします。
- 各鍵構造に含める鍵の横にあるチェックボックスをオンにすると、鍵構造を指定するオプションが表示されます。
- [シミュレート] をクリックして出力を確認します。
![[詳細設定] モードでは、測定目標とトラッキングするディメンションのコントロールが提供されます。これらはサイドバーでハイライト表示されます。](https://privacysandbox.google.com/static/private-advertising/attribution-reporting/design-decisions/advanced-mode-offers-cont-3b03a501807e6.jpg?authuser=002&hl=ja)
詳細モードのノイズラボ インターフェース。 ![[詳細モード] は、サイドバーの [パラメータ] セクションの [キー戦略] オプションでもあります。](https://privacysandbox.google.com/static/private-advertising/attribution-reporting/design-decisions/advanced-mode-a-key-stra-281e1fb56a289.jpg?authuser=002&hl=ja)
詳細モードのノイズラボ インターフェース。
ノイズ指標
基本コンセプト
ノイズは個々のユーザーのプライバシーを保護するために付加されます。
ノイズ値が高い場合は、バケット/キーがスパースで、少数の機密性の高いイベントからの寄与が含まれていることを示します。これは Noise Lab によって自動的に行われ、個人が「群衆に紛れる」ことを可能にします。つまり、少数の個人のプライバシーを、より多くのノイズを追加することで保護します。
ノイズ値が小さい場合は、データ設定が、個人が「群衆に紛れる」ことをすでに可能にするように設計されていることを示します。つまり、バケットには、個々のユーザーのプライバシーが保護されていることを確認するのに十分な数のイベントからの投稿が含まれています。
このステートメントは、平均パーセンテージ誤差(APE)と RMSRE_T(しきい値付きの二乗平均平方根相対誤差)の両方に当てはまります。
APE(平均パーセント誤差)
APE は、ノイズとシグナル(真の要約値)の比率です。
APE 値が小さいほど、信号対雑音比が優れています。
数式
特定の概要レポートの APE は次のように計算されます。
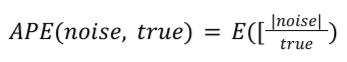
True は true の要約値です。APE は、各真の概要値に対するノイズの平均値であり、概要レポートのすべてのエントリで平均化されます。ノイズラボでは、この値を 100 倍してパーセンテージを算出します。
メリットとデメリット
サイズの小さいバケットは、APE の最終値に不釣り合いな影響を与えます。ノイズを評価する際に誤解を招く可能性があります。そのため、APE のこの制限を緩和するために、別の指標 RMSRE_T を追加しました。詳しくは、例をご覧ください。
コード
APE の計算のソースコードを確認します。
RMSRE_T(しきい値付きの二乗平均平方根相対誤差)
RMSRE_T(しきい値付きの二乗平均平方根相対誤差)は、ノイズの別の指標です。
RMSRE_T の解釈方法
RMSRE_T の値が小さいほど、信号対雑音比が優れていることを意味します。
たとえば、ユースケースで許容できるノイズ比率が 20% で、RMSRE_T が 0.2 の場合、ノイズレベルが許容範囲内にあると判断できます。
数式
特定の概要レポートの場合、RMSRE_T は次のように計算されます。
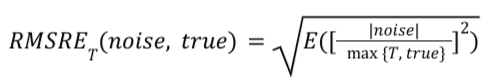
メリットとデメリット
RMSRE_T は APE よりも少し理解しにくい指標です。ただし、概要レポートのノイズを分析するうえで、APE よりも適している場合があるというメリットがいくつかあります。
- RMSRE_T はより安定しています。「T」はしきい値です。「T」は、コンバージョン数が少なく、サイズが小さいためノイズの影響を受けやすいバケットの RMSRE_T 計算での重みを小さくするために使用されます。T では、コンバージョン数が少ないバケットで指標が急増することはありません。T が 5 の場合、コンバージョンが 0 のバケットのノイズ値が 1 であっても、1 を大幅に超える値として表示されることはありません。代わりに、T が 5 であるため、1/5 に相当する 0.2 に上限が設定されます。ノイズの影響を受けやすい小さなバケットの重みを小さくすることで、この指標はより安定し、2 つのシミュレーションを簡単に比較できるようになります。
- RMSRE_T を使用すると、簡単な集計が可能になります。複数のバケットの RMSRE_T と実際のカウントを把握することで、それらの合計の RMSRE_T を計算できます。また、これらの組み合わせた値に対して RMSRE_T を最適化することもできます。
APE の集計は可能ですが、ラプラス ノイズの合計の絶対値が含まれるため、式はかなり複雑になります。これにより、APE の最適化が難しくなります。
コード
RMSRE_T の計算のソースコードを確認します。
例
3 つのバケットを含む概要レポート:
- bucket_1 = ノイズ: 10、trueSummaryValue: 100
- bucket_2 = noise: 20, trueSummaryValue: 100
- bucket_3 = noise: 20, trueSummaryValue: 200
APE = (0.1 + 0.2 + 0.1) / 3 = 13%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,200))^2) / 3) = sqrt( (0.01 + 0.04 + 0.01) / 3) = 0.14
3 つのバケットを含む概要レポート:
- bucket_1 = ノイズ: 10、trueSummaryValue: 100
- bucket_2 = noise: 20, trueSummaryValue: 100
- bucket_3 = ノイズ: 20、trueSummaryValue: 20
APE = (0.1 + 0.2 + 1) / 3 = 43%
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,20))^2) / 3) = sqrt( (0.01 + 0.04 + 1.0) / 3) = 0.59
3 つのバケットを含む概要レポート:
- bucket_1 = ノイズ: 10、trueSummaryValue: 100
- bucket_2 = noise: 20, trueSummaryValue: 100
- bucket_3 = ノイズ: 20、trueSummaryValue: 0
APE = (0.1 + 0.2 + 無限大) / 3 = 無限大
RMSRE_T = sqrt( ( (10/max(5,100))^2 + (20/max(5,100))^2 + (20/max(5,0))^2) / 3) = sqrt( (0.01 + 0.04 + 16.0) / 3) = 2.31
高度な鍵管理
DSP や広告測定会社には、複数の業界、通貨、購入価格の可能性にまたがる、数千ものグローバル広告顧客が存在する可能性があります。つまり、広告主ごとに 1 つの集計キーを作成して管理することは、現実的ではない可能性が高くなります。また、世界中の数千もの広告主様全体でノイズの影響を制限できる最大集計可能値と集計予算を選択することも困難です。代わりに、次のシナリオについて考えてみましょう。
キー戦略 A
広告技術プロバイダは、すべての広告主に対して 1 つのキーを作成して管理することにしました。すべての広告主とすべての通貨において、購入の範囲は、少量の高級品から大量の低価格品まで多岐にわたります。これにより、次のキーが生成されます。
| キー(複数通貨) | |
|---|---|
| 集計可能な最大値 | 5,000,000 |
| 購入額の範囲 | [120 - 5000000] |
主要戦略 B
広告技術プロバイダは、すべての広告主様に対して 2 つのキーを作成して管理することにしました。通貨ごとにキーを分けることにしました。すべての広告主とすべての通貨において、購入の範囲は、購入量が少なく高額な購入から、購入量が多く低額な購入まで多岐にわたります。通貨ごとに分割して、2 つの鍵を作成します。
| キー 1(米ドル) | キー 2(¥) | |
|---|---|---|
| 集計可能な最大値 | $40,000 | ¥5,000,000 |
| 購入額の範囲 | [120 - 40,000] | [15,000 ~ 5,000,000] |
通貨の値は通貨間で均等に分布していないため、キー戦略 B の結果にはキー戦略 A よりもノイズが少なくなります。たとえば、円建ての購入と米ドル建ての購入が混在している場合、基盤となるデータとノイズの多い出力がどのように変化するかを考えてみましょう。
キー戦略 C
広告技術プロバイダは、すべての広告主様を対象に 4 つのキーを作成して管理し、通貨と広告主様の業種ごとにキーを分けることにしました。
| キー 1 (米ドル × 高級ジュエリー広告主) |
キー 2 (¥ × ハイエンド ジュエリー広告主) |
キー 3 (米ドル x 衣料品小売業の広告主) |
キー 4 (¥ x 衣料品小売業の広告主) |
|
|---|---|---|---|---|
| 集計可能な最大値 | $40,000 | ¥5,000,000 | $500 | ¥65,000 |
| 購入額の範囲 | [10,000 ~ 40,000] | [1,250,000 ~ 5,000,000] | [120 - 500] | [15,000 ~ 65,000] |
広告主様の購入額は広告主様全体で均等に分布していないため、キー戦略 C の結果はキー戦略 B よりもノイズが少なくなります。たとえば、高級ジュエリーの購入と野球帽の購入が混在すると、基盤となるデータと結果として得られるノイズの多い出力がどのように変化するかを考えてみましょう。
出力のノイズを減らすために、複数の広告主間の共通性に対して、共有の最大集計値と共有のスケーリング ファクタを作成することを検討してください。たとえば、広告主様向けに次の戦略を試すことができます。
- 通貨(USD、¥、CAD など)ごとに 1 つの戦略
- 広告主の業種(保険、自動車、小売など)ごとに 1 つの戦略
- 購入額の範囲が類似する戦略を 1 つにまとめる([100]、[1000]、[10000] など)
広告主様の共通点に基づいてキー戦略を作成することで、キーと対応するコードの管理が容易になり、シグナル対ノイズ比が高くなります。さまざまな広告主様の共通点に基づいてさまざまな戦略を試し、ノイズの影響を最大化することとコード管理のバランスが取れる転換点を見つけます。
外れ値の詳細管理
2 つの広告主様を対象としたシナリオを考えてみましょう。
- 広告主 A:
- 広告主 A のサイトのすべての商品で、購入価格の可能性は [$120 - $1,000] の範囲で、幅は $880 です。
- 購入価格は 880 ドルの範囲に均等に分布しており、購入価格の中央値から 2 標準偏差を超える外れ値はありません。
- 広告主 B:
- 広告主 B のサイトのすべての商品で、購入価格の可能性は [$120 - $1,000] の範囲で、880 ドルです。
- 購入価格は 120 ~ 500 ドルの範囲に大きく偏っており、500 ~ 1,000 ドルの範囲での購入はわずか 5% です。
貢献度予算の要件と、最終結果にノイズを適用する手法を考慮すると、広告主 B は、広告主 A よりもノイズの多い結果をデフォルトで取得します。これは、広告主 B の方が、外れ値が基盤となる計算に影響を与える可能性が高いためです。
特定のキー設定でこの問題を軽減できます。外れ値データの管理と、キーの購入範囲全体での購入額のより均等な分布に役立つ主要な戦略をテストします。
広告主 B の場合は、2 つの異なる購入額の範囲をキャプチャするために、2 つの別々のキーを作成できます。この例では、広告テクノロジーは、購入額が $500 を超えると外れ値が現れることを確認しています。この広告主に対して 2 つの別々のキーを実装してみてください。
- キー構造 1 : 120 ~ 500 ドルの範囲の購入のみをキャプチャするキー(合計購入量の約 95% をカバー)。
- キー構造 2: 500 ドルを超える購入のみをキャプチャするキー(購入総数の約 5% をカバー)。
この重要な戦略を実装することで、広告主 B のノイズをより適切に管理し、概要レポートから得られる有用性を最大限に高めることができます。新しい範囲が小さくなったため、キー A とキー B のデータは、以前の単一キーよりも各キーに均等に分散されるようになりました。これにより、各キーの出力におけるノイズの影響が、以前の単一キーの場合よりも小さくなります。