
Po wdrożeniu usługi agregacji możesz używać punktów końcowych createJob i getJob do interakcji z usługą. Na diagramie poniżej przedstawiono architekturę wdrożenia tych 2 punktów końcowych:
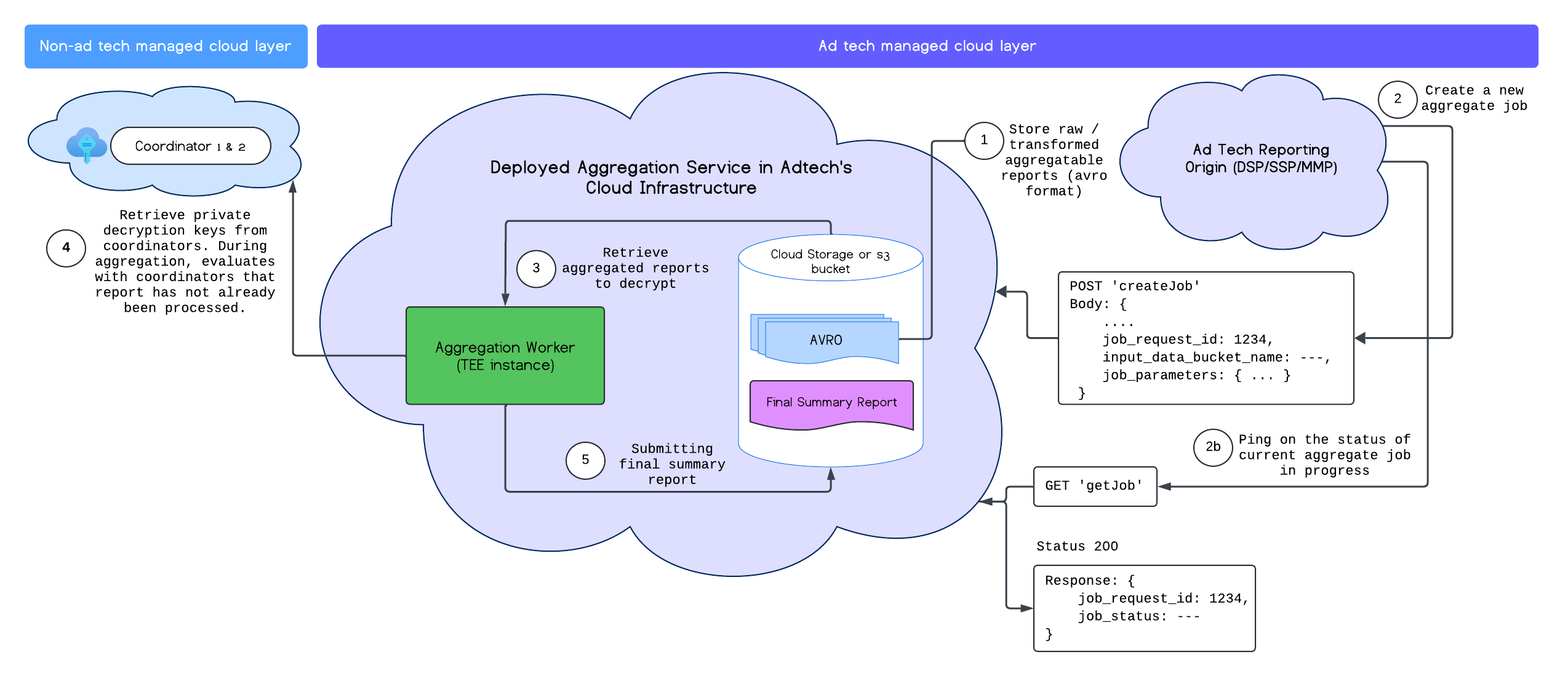
Więcej informacji o punktach końcowych createJob i getJob znajdziesz w dokumentacji interfejsu Aggregation Service API.
Tworzenie zadania
Aby utworzyć zadanie, wyślij żądanie POST do punktu końcowego createJob.
bash
POST https://<api-gateway>/stage/v1alpha/createJob
-+
Przykładowa treść żądania dla createJob:
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<host name of reporting origin>"
}
}
Utworzenie zadania zakończone powodzeniem zwraca kod stanu HTTP 202.
Pamiętaj, że atrybuty reporting_site i attribution_report_to wykluczają się nawzajem i wymagany jest tylko jeden z nich.
Możesz też poprosić o zadanie debugowania, dodając debug_run do job_parameters.
Więcej informacji o trybie debugowania znajdziesz w dokumentacji dotyczącej debugowania agregacji.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>"
"debug_run": "true"
}
}
Pola żądania
| Parametr | Typ | Opis |
|---|---|---|
job_request_id |
Ciąg znaków |
Jest to unikalny identyfikator wygenerowany przez technologię reklamową, który powinien składać się z liter ASCII i mieć maksymalnie 128 znaków. Identyfikuje żądanie zadania wsadowego i pobiera wszystkie raporty AVRO, które można agregować, określone w parametrze „input_data_blob_prefix” z zasobnika wejściowego określonego w parametrze „input_data_bucket_name”, który jest hostowany w usłudze przechowywania w chmurze dostawcy technologii reklamowych.
Znaki: `a-z, A-Z, 0-9, !"#$%&'()*+,-./:;<=>?@[\]^_`{}~
|
input_data_blob_prefix |
Ciąg znaków |
To jest ścieżka do zasobnika. W przypadku pojedynczych plików możesz użyć ścieżki. W przypadku wielu plików możesz użyć prefiksu w ścieżce.
Przykład: folder/plik zbiera wszystkie raporty z folderu/pliku1.avro, folderu/pliku/pliku1.avro i folderu/pliku1/test/pliku2.avro. |
input_data_bucket_name |
Ciąg znaków | Jest to zasobnik pamięci na dane wejściowe lub raporty agregowane. Znajduje się on w miejscu w chmurze należącym do platformy reklamowej. |
output_data_blob_prefix |
Ciąg znaków | To ścieżka wyjściowa w zasobniku. Obsługiwany jest tylko 1 plik wyjściowy. |
output_data_bucket_name |
Ciąg znaków |
Jest to zasobnik na dane, do którego wysyłany jest output_data. Znajduje się on w miejscu w chmurze należącym do platformy reklamowej.
|
job_parameters |
Słownik |
Pole wymagane. To pole zawiera różne pola, takie jak:
|
job_parameters.output_domain_blob_prefix |
Ciąg znaków |
Podobnie jak w przypadku input_data_blob_prefix, jest to ścieżka w output_domain_bucket_name, w której znajduje się wyjściowy plik AVRO domeny. W przypadku wielu plików możesz użyć prefiksu w ścieżce. Gdy usługa do agregacji przetworzy partię, tworzony jest raport podsumowujący, który jest umieszczany w zasobniku wyjściowym output_data_bucket_name pod nazwą output_data_blob_prefix.
|
job_parameters.output_domain_bucket_name |
Ciąg znaków | Jest to zasobnik pamięci na plik AVRO domeny wyjściowej. Znajduje się on w miejscu w chmurze należącym do platformy reklamowej. |
job_parameters.attribution_report_to |
Ciąg znaków | Ta wartość wyklucza się wzajemnie z wartością `reporting_site`. Jest to adres URL lub źródło raportowania, z którego otrzymano raport. Pochodzenie witryny jest rejestrowane w ramach procesu wprowadzania do usługi do agregacji. |
job_parameters.reporting_site |
Ciąg znaków |
Wzajemnie wykluczające się z atrybutem attribution_report_to. Jest to nazwa hosta adresu URL raportowania lub źródła raportowania, z którego otrzymano raport. Pochodzenie witryny jest rejestrowane w ramach procesu wprowadzania do usługi do agregacji.
Uwaga: w ramach jednego żądania możesz przesłać kilka raportów z różnych źródeł, pod warunkiem że wszystkie źródła należą do tej samej witryny raportującej określonej w tym parametrze.
|
job_parameters.debug_privacy_epsilon |
Liczba zmiennoprzecinkowa, podwójna precyzja | Pole opcjonalne. Jeśli nie podasz żadnej wartości, zostanie użyta wartość domyślna 10. Możesz użyć wartości od 0 do 64. |
job_parameters.report_error_threshold_percentage |
Liczba zmiennoprzecinkowa | Pole opcjonalne. Jest to maksymalny odsetek nieudanych raportów, po którym zadanie zakończy się niepowodzeniem. Jeśli pozostawisz to pole puste, wartością domyślną będzie 10%. |
job_parameters.input_report_count |
długa wartość |
Pole opcjonalne. Łączna liczba raportów podanych jako dane wejściowe zadania. Ta wartość w połączeniu z parametrem report_error_threshold_percentage umożliwia wczesne przerwanie zadania, gdy raporty są wykluczane z powodu błędów.
|
job_parameters.filtering_ids |
Ciąg znaków |
Pole opcjonalne. Lista niepodpisanych identyfikatorów filtrowania rozdzielonych przecinkami. Wszystkie wpisy inne niż pasujący identyfikator filtrowania są odfiltrowywane. (np."filtering_ids": "12345,34455,12"). Wartością domyślną jest 0.
|
job_parameters.debug_run |
Wartość logiczna |
Pole opcjonalne. Podczas wykonywania testu debugowania dodawane są raporty podsumowujące debugowanie z zaszumionymi i niezaszumionymi danymi oraz adnotacje wskazujące, które klucze są obecne w danych wejściowych domeny lub w raportach. Ponadto nie są egzekwowane duplikaty w różnych partiach. Pamiętaj, że uruchomienie debugowania uwzględnia tylko raporty oznaczone flagą "debug_mode": "enabled". Od wersji 2.10.0 uruchomienia debugowania nie wykorzystują budżetu prywatności.
|
Znajdź pracę
Jeśli dostawca technologii reklamowych chce poznać stan żądanego pakietu, może wywołać punkt końcowy getJob. Punkt końcowy getJob jest wywoływany za pomocą żądania HTTPS GET wraz z parametrem job_request_id.
GET https://<api-gateway>/stage/v1alpha/getJob?job_request_id=<job_request_id>
Powinna wyświetlić się odpowiedź ze stanem zadania i wszelkimi komunikatami o błędach:
{
"job_status": "FINISHED",
"request_received_at": "2023-07-17T19:15:13.926530Z",
"request_updated_at": "2023-07-17T19:15:28.614942839Z",
"job_request_id": "PSD_0003",
"input_data_blob_prefix": "reports/output_reports_2023-07-17T19:11:27.315Z.avro",
"input_data_bucket_name": "ags-report-bucket",
"output_data_blob_prefix": "summary/summary.avro",
"output_data_bucket_name": "ags-report-bucket",
"postback_URL": "",
"result_info": {
"return_code": "SUCCESS",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-07-17T19:15:28.607802354Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "ags-report-bucket",
"output_domain_blob_prefix": "output_domain/output_domain.avro",
"attribution_report_to": "https://privacy-sandcastle-dev-dsp.web.app"
},
"request_processing_started_at": "2023-07-17T19:15:21.583759622Z"
}
Pola odpowiedzi
| Parametr | Typ | Opis |
|---|---|---|
job_request_id |
Ciąg znaków |
Jest to unikalny identyfikator zadania lub partii określony w żądaniu createJob.
|
job_status |
Ciąg znaków | To stan żądania zadania. |
request_received_at |
Ciąg znaków | Czas odebrania żądania. |
request_updated_at |
Ciąg znaków | Czas ostatniej aktualizacji zadania. |
input_data_blob_prefix |
Ciąg znaków |
Jest to prefiks danych wejściowych, który został ustawiony na createJob.
|
input_data_bucket_name |
Ciąg znaków |
Jest to zasobnik danych wejściowych dostawcy technologii reklamowych, w którym przechowywane są raporty agregowane. To pole jest ustawione na createJob.
|
output_data_blob_prefix |
Ciąg znaków |
Jest to prefiks danych wyjściowych, który został ustawiony createJob.
|
output_data_bucket_name |
Ciąg znaków |
Jest to zasobnik danych wyjściowych firmy zajmującej się technologiami reklamowymi, w którym są przechowywane wygenerowane raporty podsumowujące. To pole jest ustawione na createJob.
|
request_processing_started_at |
Ciąg znaków |
Czas rozpoczęcia ostatniej próby przetwarzania. Nie obejmuje to czasu oczekiwania w kolejce zadań.
(Całkowity czas przetwarzania = request_updated_at – request_processing_started_at)
|
result_info |
Słownik |
Jest to wynik createJob i zawiera wszystkie dostępne informacje.
Wyświetla wartości return_code, return_message, finished_at i error_summary.
|
result_info.return_code |
Ciąg znaków | Kod wyniku zadania. Te informacje są potrzebne do rozwiązywania problemów, jeśli w usłudze do agregacji wystąpi błąd. |
result_info.return_message |
Ciąg znaków | Komunikat o powodzeniu lub niepowodzeniu zwrócony w wyniku zadania. Te informacje są też potrzebne do rozwiązywania problemów z usługą agregacji. |
result_info.error_summary |
Słownik | Błędy zwracane przez zadanie. Zawiera liczbę raportów wraz z typami napotkanych błędów. |
result_info.finished_at |
Sygnatura czasowa | Sygnatura czasowa wskazująca zakończenie zadania. |
result_info.error_summary.error_counts |
Lista |
Zwraca listę komunikatów o błędach wraz z liczbą raportów, których nie udało się wygenerować z powodu tego samego komunikatu o błędzie. Każda liczba błędów zawiera kategorię error_count i description.
|
result_info.error_summary.error_messages |
Lista | Zwraca listę komunikatów o błędach z raportów, których nie udało się przetworzyć. |
job_parameters |
Słownik |
Zawiera parametry zadania podane w żądaniu createJob. Odpowiednie właściwości, takie jak „output_domain_blob_prefix” i „output_domain_bucket_name”.
|
job_parameters.attribution_report_to |
Ciąg znaków |
Wzajemnie wykluczające się z atrybutem reporting_site. To adres URL zgłoszenia lub źródło, z którego zostało ono otrzymane. Pochodzenie jest częścią witryny zarejestrowanej w ramach procesu wprowadzania do usługi agregacji. Jest to określone w createJobżądaniu.
|
job_parameters.reporting_site |
Ciąg znaków |
Wzajemnie wykluczające się z atrybutem attribution_report_to. Jest to nazwa hosta adresu URL raportu lub źródło, z którego otrzymano raport. Pochodzenie jest częścią witryny zarejestrowanej w ramach procesu wprowadzania do usługi agregacji. Pamiętaj, że w tym samym żądaniu możesz przesyłać raporty z wieloma źródłami raportowania, o ile wszystkie należą do tej samej witryny wymienionej w tym parametrze. Jest to określone w createJobżądaniu. Sprawdź też, czy w momencie tworzenia zadania zasobnik zawiera tylko raporty, które chcesz zagregować. Przetwarzane są wszystkie raporty dodane do zasobnika danych wejściowych, których źródła raportowania są zgodne z witryną raportowania określoną w parametrze zadania.
Usługa do agregacji uwzględnia tylko raporty w zasobniku danych, które pasują do zarejestrowanego źródła raportowania zadania. Jeśli na przykład zarejestrowane źródło to https://exampleabc.com, uwzględniane są tylko raporty z https://exampleabc.com, nawet jeśli zasobnik zawiera raporty z subdomen (https://1.exampleabc.com itp.) lub zupełnie innych domen (https://3.examplexyz.com).
|
job_parameters.debug_privacy_epsilon |
Liczba zmiennoprzecinkowa, podwójna precyzja |
Pole opcjonalne. Jeśli nie podasz żadnej wartości, zostanie użyta wartość domyślna 10. Wartości mogą wynosić od 0 do 64. Ta wartość jest określona w żądaniu createJob.
|
job_parameters.report_error_threshold_percentage |
Liczba zmiennoprzecinkowa |
Pole opcjonalne. Jest to próg procentowy raportów, które mogą zakończyć się niepowodzeniem przed niepowodzeniem zadania. Jeśli nie przypiszesz żadnej wartości, zostanie użyta wartość domyślna 10%. Jest to określone w createJobżądaniu.
|
job_parameters.input_report_count |
Długa wartość | Pole opcjonalne. Łączna liczba raportów dostarczonych jako dane wejściowe dla tego zadania. Wartość `report_error_threshold_percentage` w połączeniu z tą wartością powoduje wcześniejsze zakończenie zadania, jeśli z powodu błędów zostanie wykluczona znaczna liczba raportów. To ustawienie jest określone w żądaniu `createJob`. |
job_parameters.filtering_ids |
Ciąg znaków |
Pole opcjonalne. Lista niepodpisanych identyfikatorów filtrowania rozdzielonych przecinkami. Wszystkie treści inne niż pasujący identyfikator filtrowania są odfiltrowywane. Jest to określone w createJobżądaniu.
(np. "filtering_ids":"12345,34455,12". Wartość domyślna to „0”).
|