
Aggregation Service को सही तरीके से डिप्लॉय करने के बाद, createJob और getJob एंडपॉइंट का इस्तेमाल करके, सेवा से इंटरैक्ट किया जा सकता है. यहां दिए गए डायग्राम में, इन दोनों एंडपॉइंट के लिए डिप्लॉयमेंट आर्किटेक्चर को विज़ुअल के तौर पर दिखाया गया है:
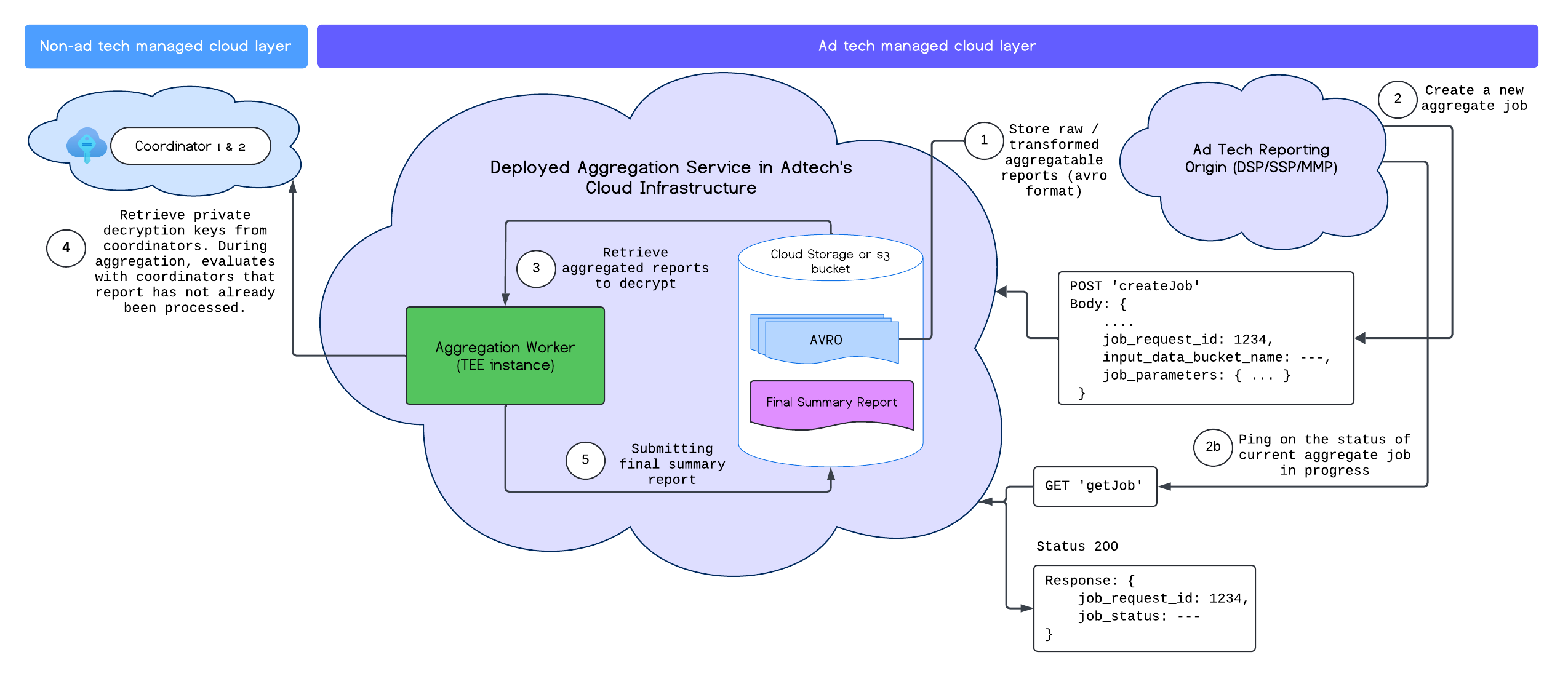
Aggregation Service API के दस्तावेज़ में, createJob और getJob एंडपॉइंट के बारे में ज़्यादा जानकारी दी गई है.
जॉब बनाना
कोई जॉब बनाने के लिए, createJob एंडपॉइंट पर POST अनुरोध भेजें.
bash
POST https://<api-gateway>/stage/v1alpha/createJob
-+
createJob के लिए अनुरोध के मुख्य भाग का उदाहरण:
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<host name of reporting origin>"
}
}
नौकरी की जानकारी पोस्ट करने पर, 202 एचटीटीपी स्टेटस कोड मिलता है.
ध्यान दें कि reporting_site और attribution_report_to, एक-दूसरे से अलग होते हैं. इनमें से सिर्फ़ एक की ज़रूरत होती है.
debug_run में job_parameters जोड़कर, डीबग जॉब का अनुरोध भी किया जा सकता है.
डीबग मोड के बारे में ज़्यादा जानने के लिए, एग्रीगेशन डीबग रन का दस्तावेज़ देखें.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>"
"debug_run": "true"
}
}
अनुरोध फ़ील्ड
| पैरामीटर | टाइप | ब्यौरा |
|---|---|---|
job_request_id |
स्ट्रिंग |
यह विज्ञापन टेक्नोलॉजी से जनरेट किया गया यूनीक आइडेंटिफ़ायर है. इसमें ASCII वर्ण होने चाहिए. साथ ही, इसमें ज़्यादा से ज़्यादा 128 वर्ण होने चाहिए. इससे बैच जॉब के अनुरोध की पहचान होती है. साथ ही, यह `input_data_blob_prefix` में बताई गई सभी एग्रीगेट की जा सकने वाली AVRO रिपोर्ट को, `input_data_bucket_name` में बताए गए इनपुट बकेट से लेता है. यह बकेट, विज्ञापन टेक्नोलॉजी कंपनी के क्लाउड स्टोरेज पर होस्ट किया जाता है.
वर्ण: `a-z, A-Z, 0-9, !"#$%&'()*+,-./:;<=>?@[\]^_`{}~
|
input_data_blob_prefix |
स्ट्रिंग |
यह बकेट का पाथ है. सिंगल फ़ाइलों के लिए, पाथ का इस्तेमाल किया जा सकता है. एक से ज़्यादा फ़ाइलों के लिए, पाथ में प्रीफ़िक्स का इस्तेमाल किया जा सकता है.
उदाहरण: यह फ़ोल्डर/फ़ाइल, folder/file1.avro, folder/file/file1.avro, और folder/file1/test/file2.avro से सभी रिपोर्ट इकट्ठा करता है. |
input_data_bucket_name |
स्ट्रिंग | यह इनपुट डेटा या एग्रीगेट की जा सकने वाली रिपोर्ट के लिए स्टोरेज बकेट है. यह विज्ञापन टेक्नोलॉजी कंपनी के क्लाउड स्टोरेज पर होता है. |
output_data_blob_prefix |
स्ट्रिंग | यह बकेट में मौजूद आउटपुट पाथ है. सिर्फ़ एक आउटपुट फ़ाइल का इस्तेमाल किया जा सकता है. |
output_data_bucket_name |
स्ट्रिंग |
यह वह स्टोरेज बकेट है जहां output_data भेजा जाता है. यह विज्ञापन टेक्नोलॉजी कंपनी के क्लाउड स्टोरेज में मौजूद होता है.
|
job_parameters |
शब्दकोश |
आवश्यक फ़ील्ड. इस फ़ील्ड में अलग-अलग फ़ील्ड शामिल होते हैं, जैसे कि:
|
job_parameters.output_domain_blob_prefix |
स्ट्रिंग |
input_data_blob_prefix की तरह ही, यह output_domain_bucket_name में मौजूद वह पाथ है जहां आपका आउटपुट डोमेन AVRO मौजूद है. एक से ज़्यादा फ़ाइलों के लिए, पाथ में प्रीफ़िक्स का इस्तेमाल किया जा सकता है. एग्रीगेशन सेवा के बैच पूरा करने के बाद, खास जानकारी वाली रिपोर्ट बनाई जाती है. इसके बाद, इसे output_data_blob_prefix नाम वाले आउटपुट बकेट output_data_bucket_name में सेव कर दिया जाता है.
|
job_parameters.output_domain_bucket_name |
स्ट्रिंग | यह आपके आउटपुट डोमेन की AVRO फ़ाइल के लिए स्टोरेज बकेट है. यह विज्ञापन टेक्नोलॉजी कंपनी के क्लाउड स्टोरेज पर होता है. |
job_parameters.attribution_report_to |
स्ट्रिंग | यह वैल्यू, `reporting_site` से अलग होती है. यह रिपोर्टिंग यूआरएल या रिपोर्टिंग ऑरिजिन है, जहां रिपोर्ट मिली थी. साइट का ऑरिजिन, एग्रीगेशन सेवा के ऑनबोर्डिंग में रजिस्टर किया गया हो. |
job_parameters.reporting_site |
स्ट्रिंग |
attribution_report_to के साथ इस्तेमाल नहीं किया जा सकता. यह रिपोर्टिंग यूआरएल या रिपोर्टिंग ऑरिजिन का होस्टनेम है, जहां रिपोर्ट मिली थी. साइट का ऑरिजिन, एग्रीगेशन सेवा के ऑनबोर्डिंग में रजिस्टर किया गया हो.
ध्यान दें: एक ही अनुरोध में, अलग-अलग ऑरिजिन की कई रिपोर्ट सबमिट की जा सकती हैं. हालांकि, यह ज़रूरी है कि सभी ऑरिजिन, इस पैरामीटर में बताई गई रिपोर्टिंग साइट से जुड़े हों.
|
job_parameters.debug_privacy_epsilon |
फ़्लोटिंग पॉइंट, डबल | यह फ़ील्ड ज़रूरी नहीं है. अगर कोई वैल्यू पास नहीं की जाती है, तो डिफ़ॉल्ट वैल्यू 10 होती है. इसकी वैल्यू 0 से 64 के बीच की कोई संख्या हो सकती है. |
job_parameters.report_error_threshold_percentage |
डबल | यह फ़ील्ड ज़रूरी नहीं है. यह उन रिपोर्ट का ज़्यादा से ज़्यादा प्रतिशत है जो जॉब के फ़ेल होने से पहले फ़ेल हो सकती हैं. अगर इसे खाली छोड़ दिया जाता है, तो डिफ़ॉल्ट वैल्यू 10% होती है. |
job_parameters.input_report_count |
long value |
यह फ़ील्ड ज़रूरी नहीं है. जॉब के लिए इनपुट डेटा के तौर पर दी गई रिपोर्ट की कुल संख्या. इस वैल्यू और report_error_threshold_percentage की मदद से, गड़बड़ियों की वजह से रिपोर्ट शामिल न किए जाने पर, जॉब के फ़ेल होने की जानकारी पहले ही मिल जाती है.
|
job_parameters.filtering_ids |
स्ट्रिंग |
यह फ़ील्ड ज़रूरी नहीं है. बिना हस्ताक्षर वाले फ़िल्टरिंग आईडी की सूची, जिन्हें कॉमा लगाकर अलग किया गया है. मिलते-जुलते फ़िल्टरिंग आईडी के अलावा, सभी योगदानों को फ़िल्टर कर दिया जाता है. (उदाहरण के लिए,"filtering_ids": "12345,34455,12"). डिफ़ॉल्ट वैल्यू 0 है.
|
job_parameters.debug_run |
बूलियन |
यह फ़ील्ड ज़रूरी नहीं है. डीबग रन को लागू करते समय, नॉइज़ और बिना नॉइज़ वाली डीबग की खास जानकारी वाली रिपोर्ट और एनोटेशन जोड़े जाते हैं. इससे यह पता चलता है कि डोमेन इनपुट और/या रिपोर्ट में कौनसी कुंजियां मौजूद हैं. इसके अलावा, बैच में डुप्लीकेट आइटम होने पर भी कोई पाबंदी नहीं लगाई जाती. ध्यान दें कि डीबग रन में सिर्फ़ उन रिपोर्ट को शामिल किया जाता है जिनमें "debug_mode": "enabled" फ़्लैग मौजूद होता है. v2.10.0 के मुताबिक, डीबग रन, निजता बजट का इस्तेमाल नहीं करते हैं.
|
कोई नौकरी कर लो ॥ कोई काम ढूंढ लो ॥ कोई नौकरी तलाश लो ॥ कुछ काम कर लो ॥ कोई काम कर लो ॥ कोई काम है कि नहीं
जब कोई विज्ञापन टेक्नोलॉजी कंपनी, अनुरोध किए गए बैच का स्टेटस जानना चाहती है, तो वह getJob एंडपॉइंट को कॉल कर सकती है. getJob एंडपॉइंट को, job_request_id पैरामीटर के साथ एचटीटीपीएस जीईटी अनुरोध का इस्तेमाल करके कॉल किया जाता है.
GET https://<api-gateway>/stage/v1alpha/getJob?job_request_id=<job_request_id>
आपको ऐसा जवाब मिलेगा जिसमें नौकरी की स्थिति के साथ-साथ गड़बड़ी के मैसेज भी दिखेंगे:
{
"job_status": "FINISHED",
"request_received_at": "2023-07-17T19:15:13.926530Z",
"request_updated_at": "2023-07-17T19:15:28.614942839Z",
"job_request_id": "PSD_0003",
"input_data_blob_prefix": "reports/output_reports_2023-07-17T19:11:27.315Z.avro",
"input_data_bucket_name": "ags-report-bucket",
"output_data_blob_prefix": "summary/summary.avro",
"output_data_bucket_name": "ags-report-bucket",
"postback_URL": "",
"result_info": {
"return_code": "SUCCESS",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-07-17T19:15:28.607802354Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "ags-report-bucket",
"output_domain_blob_prefix": "output_domain/output_domain.avro",
"attribution_report_to": "https://privacy-sandcastle-dev-dsp.web.app"
},
"request_processing_started_at": "2023-07-17T19:15:21.583759622Z"
}
जवाब वाले फ़ील्ड
| पैरामीटर | टाइप | ब्यौरा |
|---|---|---|
job_request_id |
स्ट्रिंग |
यह यूनीक जॉब/बैच आईडी है, जिसे createJob अनुरोध में बताया गया था.
|
job_status |
स्ट्रिंग | यह नौकरी के अनुरोध की स्थिति है. |
request_received_at |
स्ट्रिंग | अनुरोध मिलने का समय. |
request_updated_at |
स्ट्रिंग | जॉब को आखिरी बार अपडेट किए जाने का समय. |
input_data_blob_prefix |
स्ट्रिंग |
यह इनपुट डेटा प्रीफ़िक्स है, जिसे createJob पर सेट किया गया था.
|
input_data_bucket_name |
स्ट्रिंग |
यह विज्ञापन से जुड़ी टेक्नोलॉजी का इनपुट डेटा बकेट है. इसमें एग्रीगेट की जा सकने वाली रिपोर्ट सेव की जाती हैं. इस फ़ील्ड को createJob पर सेट किया गया है.
|
output_data_blob_prefix |
स्ट्रिंग |
यह आउटपुट डेटा का प्रीफ़िक्स है, जिसे createJob पर सेट किया गया था.
|
output_data_bucket_name |
स्ट्रिंग |
यह विज्ञापन टेक्नोलॉजी कंपनी का आउटपुट डेटा बकेट है. इसमें जनरेट की गई खास जानकारी वाली रिपोर्ट सेव की जाती हैं. इस फ़ील्ड को createJob पर सेट किया गया है.
|
request_processing_started_at |
स्ट्रिंग |
प्रोसेसिंग की सबसे हाल की कोशिश शुरू होने का समय. इसमें जॉब क्यू में इंतज़ार करने का समय शामिल नहीं है.
(प्रोसेसिंग में लगा कुल समय = request_updated_at - request_processing_started_at)
|
result_info |
शब्दकोश |
यह createJob अनुरोध का नतीजा है. इसमें उपलब्ध सभी जानकारी शामिल होती है.
इससे return_code, return_message, finished_at, और error_summary वैल्यू दिखती हैं.
|
result_info.return_code |
स्ट्रिंग | जॉब के नतीजे का रिस्पॉन्स कोड. अगर एग्रीगेशन सेवा में कोई समस्या आती है, तो इस जानकारी का इस्तेमाल समस्या को हल करने के लिए किया जाता है. |
result_info.return_message |
स्ट्रिंग | जॉब के पूरा होने या पूरा न होने की सूचना देने वाला मैसेज. इस जानकारी का इस्तेमाल, एग्रीगेशन सेवा से जुड़ी समस्याओं को हल करने के लिए भी किया जाता है. |
result_info.error_summary |
शब्दकोश | जॉब से मिलने वाली गड़बड़ियां. इसमें रिपोर्ट की संख्या के साथ-साथ, सामने आई गड़बड़ियों के टाइप की जानकारी भी होती है. |
result_info.finished_at |
टाइमस्टैम्प | यह टाइमस्टैंप, काम पूरा होने का समय दिखाता है. |
result_info.error_summary.error_counts |
सूची |
इससे गड़बड़ी के मैसेज की सूची मिलती है. साथ ही, यह भी पता चलता है कि एक ही गड़बड़ी के मैसेज की वजह से कितनी रिपोर्ट जनरेट नहीं हो पाईं. गड़बड़ियों की संख्या में, कैटगरी, error_count, और description शामिल होती हैं.
|
result_info.error_summary.error_messages |
सूची | इससे उन रिपोर्ट के गड़बड़ी वाले मैसेज की सूची मिलती है जिन्हें प्रोसेस नहीं किया जा सका. |
job_parameters |
शब्दकोश |
इसमें createJob अनुरोध में दिए गए नौकरी के पैरामीटर शामिल होते हैं. काम की प्रॉपर्टी, जैसे कि `output_domain_blob_prefix` और `output_domain_bucket_name`.
|
job_parameters.attribution_report_to |
स्ट्रिंग |
reporting_site के साथ इस्तेमाल नहीं किया जा सकता. यह रिपोर्टिंग यूआरएल है या वह ऑरिजिन है जहां से रिपोर्ट मिली थी. ओरिजिन, उस साइट का हिस्सा है जिसे Aggregation Service Onboarding में रजिस्टर किया गया है. यह createJob अनुरोध में बताया गया है.
|
job_parameters.reporting_site |
स्ट्रिंग |
attribution_report_to के साथ इस्तेमाल नहीं किया जा सकता. यह रिपोर्टिंग यूआरएल का होस्टनेम है या वह ऑरिजिन है जहां से रिपोर्ट मिली है. ओरिजिन, उस साइट का हिस्सा है जिसे Aggregation Service Onboarding में रजिस्टर किया गया है. ध्यान दें कि एक ही अनुरोध में, कई रिपोर्टिंग ऑरिजिन वाली रिपोर्ट सबमिट की जा सकती हैं. हालांकि, यह ज़रूरी है कि सभी रिपोर्टिंग ऑरिजिन, इस पैरामीटर में बताई गई एक ही साइट से जुड़े हों. यह createJob अनुरोध में बताया गया है. इसके अलावा, यह भी पुष्टि करें कि बकेट में सिर्फ़ वे रिपोर्ट शामिल हों जिन्हें आपको जॉब बनाते समय एग्रीगेट करना है. इनपुट डेटा बकेट में जोड़ी गई ऐसी सभी रिपोर्ट प्रोसेस की जाती हैं जिनके रिपोर्टिंग ऑरिजिन, जॉब पैरामीटर में बताई गई रिपोर्टिंग साइट से मेल खाते हैं.
एग्रीगेशन सेवा, सिर्फ़ उन रिपोर्ट पर विचार करती है जो डेटा बकेट में मौजूद हैं. साथ ही, वे रिपोर्टिंग के उस ओरिजिन से मैच करती हैं जिसे नौकरी के लिए रजिस्टर किया गया है. उदाहरण के लिए, अगर रजिस्टर किया गया ऑरिजिन https://exampleabc.com है, तो सिर्फ़ https://exampleabc.com से मिली रिपोर्ट शामिल की जाती हैं. भले ही, बकेट में सबडोमेन (https://1.exampleabc.com वगैरह) या पूरी तरह से अलग डोमेन (https://3.examplexyz.com) से मिली रिपोर्ट शामिल हों.
|
job_parameters.debug_privacy_epsilon |
फ़्लोटिंग पॉइंट, डबल |
यह फ़ील्ड ज़रूरी नहीं है. अगर कोई वैल्यू नहीं दी जाती है, तो डिफ़ॉल्ट वैल्यू 10 का इस्तेमाल किया जाता है. वैल्यू 0 से 64 के बीच हो सकती हैं. यह वैल्यू, createJob अनुरोध में दी जाती है.
|
job_parameters.report_error_threshold_percentage |
डबल |
यह फ़ील्ड ज़रूरी नहीं है. यह रिपोर्ट का थ्रेशोल्ड प्रतिशत है. इससे पहले कि जॉब फ़ेल हो जाए, इतनी रिपोर्ट फ़ेल हो सकती हैं. अगर कोई वैल्यू असाइन नहीं की जाती है, तो 10% की डिफ़ॉल्ट वैल्यू का इस्तेमाल किया जाता है. यह createJob अनुरोध में बताया गया है.
|
job_parameters.input_report_count |
लंबा मान | यह फ़ील्ड ज़रूरी नहीं है. इस जॉब के लिए इनपुट डेटा के तौर पर दी गई रिपोर्ट की कुल संख्या. अगर गड़बड़ियों की वजह से बड़ी संख्या में रिपोर्ट शामिल नहीं की जाती हैं, तो `report_error_threshold_percentage` और इस वैल्यू को मिलाकर, जॉब के फ़ेल होने की सूचना पहले ही मिल जाती है. यह सेटिंग, `createJob` अनुरोध में दी जाती है. |
job_parameters.filtering_ids |
स्ट्रिंग |
यह फ़ील्ड ज़रूरी नहीं है. बिना हस्ताक्षर वाले फ़िल्टरिंग आईडी की सूची, जिन्हें कॉमा लगाकर अलग-अलग किया गया है. मिलते-जुलते फ़िल्टरिंग आईडी के अलावा, सभी योगदानों को फ़िल्टर कर दिया जाता है. यह createJob अनुरोध में बताया गया है.
(उदाहरण के लिए, "filtering_ids":"12345,34455,12". डिफ़ॉल्ट वैल्यू "0" है.)
|