
پس از اینکه سرویس تجمیع (Aggregation Service) را با موفقیت مستقر کردید، میتوانید از نقاط پایانی createJob و getJob برای تعامل با سرویس استفاده کنید. نمودار زیر نمایش بصری از معماری استقرار برای این دو نقطه پایانی را ارائه میدهد:
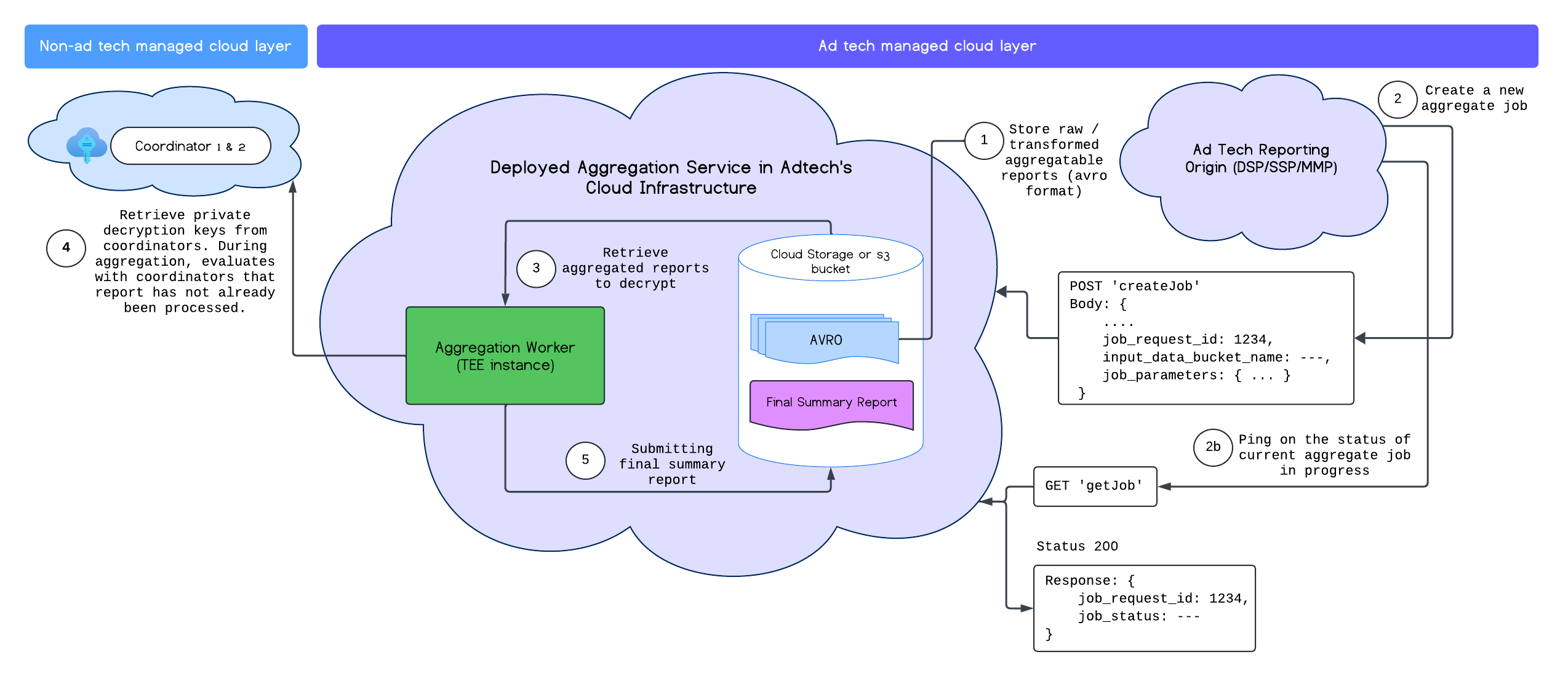
میتوانید اطلاعات بیشتر در مورد نقاط پایانی createJob و getJob را در مستندات API سرویس تجمیع مطالعه کنید.
ایجاد شغل
برای ایجاد یک شغل، یک درخواست POST به نقطه پایانی createJob ارسال کنید. bash POST https://<api-gateway>/stage/v1alpha/createJob -+ نمونهای از بدنه درخواست برای createJob :
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<host name of reporting origin>"
}
}
ایجاد شغل موفق منجر به کد وضعیت HTTP 202 میشود.
توجه داشته باشید که reporting_site و attribution_report_to منحصر به فرد هستند و فقط یکی از آنها مورد نیاز است.
همچنین میتوانید با اضافه کردن debug_run به job_parameters ، یک کار اشکالزدایی درخواست کنید. برای اطلاعات بیشتر در مورد حالت اشکالزدایی، مستندات اجرای اشکالزدایی تجمیعی ما را بررسی کنید.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>"
"debug_run": "true"
}
}
فیلدهای درخواست
| پارامتر | نوع | توضیحات |
|---|---|---|
job_request_id | رشته | این یک شناسه منحصر به فرد تولید شده توسط فناوری تبلیغات است که باید از حروف ASCII با ۱۲۸ کاراکتر یا کمتر باشد. این شناسه، درخواست کار دستهای را شناسایی میکند و تمام گزارشهای AVRO قابل جمعآوری مشخص شده در `input_data_blob_prefix` را از سطل ورودی مشخص شده در `input_data_bucket_name` که در فضای ذخیرهسازی ابری فناوری تبلیغات میزبانی میشود، دریافت میکند. کاراکترها: `az, AZ, 0-9, !"#$%&'()*+,-./:;<=>?@[\]^_`{}~ |
input_data_blob_prefix | رشته | این مسیر سطل است. برای فایلهای تکی، میتوانید از مسیر استفاده کنید. برای چندین فایل، میتوانید از پیشوند در مسیر استفاده کنید. مثال: پوشه/فایل تمام گزارشها را از پوشه/file1.avro، پوشه/file/file1.avro و پوشه/file1/test/file2.avro جمعآوری میکند. |
input_data_bucket_name | رشته | این محل ذخیرهسازی برای دادههای ورودی یا گزارشهای قابل جمعآوری است. این محل در فضای ذخیرهسازی ابری شرکت فناوری تبلیغات قرار دارد. |
output_data_blob_prefix | رشته | این مسیر خروجی در سطل است. یک فایل خروجی واحد پشتیبانی میشود. |
output_data_bucket_name | رشته | این سطل ذخیرهسازی است که output_data به آن ارسال میشود. این سطل در فضای ذخیرهسازی ابری شرکت تبلیغات وجود دارد. |
job_parameters | فرهنگ لغت | فیلد الزامی. این فیلد شامل فیلدهای مختلفی مانند موارد زیر است:
|
job_parameters.output_domain_blob_prefix | رشته | مشابه input_data_blob_prefix ، این مسیر در output_domain_bucket_name است که دامنه خروجی AVRO شما در آن قرار دارد. برای چندین فایل، میتوانید از پیشوند در مسیر استفاده کنید. پس از تکمیل دستهای توسط سرویس تجمیع، گزارش خلاصه ایجاد شده و در output_data_bucket_name با نام output_data_blob_prefix قرار میگیرد. |
job_parameters.output_domain_bucket_name | رشته | این سطل ذخیرهسازی برای فایل AVRO دامنه خروجی شماست. این در فضای ذخیرهسازی ابری شرکت فناوری تبلیغات قرار دارد. |
job_parameters.attribution_report_to | رشته | این مقدار منحصراً مختص به `reporting_site` است. این URL گزارش یا منبع گزارشدهی است که گزارش از آنجا دریافت شده است. منبع سایت در سرویس تجمیع ثبت شده است. |
job_parameters.reporting_site | رشته | منحصر به فرد برای attribution_report_to . این نام میزبان URL گزارش یا منبع گزارش است که گزارش از آنجا دریافت شده است. منبع سایت در Onboarding Service Aggregation ثبت شده است. توجه: میتوانید چندین گزارش با منابع مختلف را در یک درخواست واحد ارسال کنید، مشروط بر اینکه همه منابع متعلق به یک سایت گزارشدهی مشخص شده در این پارامتر باشند. |
job_parameters.debug_privacy_epsilon | ممیز شناور، دابل | فیلد اختیاری. اگر هیچ مقداری ارسال نشود، مقدار پیشفرض ۱۰ است. میتوان از مقداری بین ۰ تا ۶۴ استفاده کرد. |
job_parameters.report_error_threshold_percentage | دو برابر | فیلد اختیاری. این حداکثر درصد گزارشهای ناموفق مجاز قبل از شکست کار است. اگر خالی بماند، مقدار پیشفرض ۱۰٪ است. |
job_parameters.input_report_count | ارزش طولانی | فیلد اختیاری. تعداد کل گزارشهای ارائه شده به عنوان دادههای ورودی برای کار. این مقدار، همراه با report_error_threshold_percentage امکان شکست زودهنگام کار را در صورت حذف گزارشها به دلیل خطاها فراهم میکند. |
job_parameters.filtering_ids | رشته | فیلد اختیاری. فهرستی از شناسههای فیلترینگ بدون علامت که با کاما از هم جدا شدهاند. تمام موارد اضافه شده به جز شناسه فیلترینگ منطبق، فیلتر میشوند. (مثلاً "filtering_ids": "12345,34455,12" ). مقدار پیشفرض 0 است. |
job_parameters.debug_run | بولی | فیلد اختیاری. هنگام اجرای یک اجرای اشکالزدایی، گزارشها و حاشیهنویسیهای خلاصه اشکالزدایی نویزدار و بدون نویز اضافه میشوند تا نشان دهند کدام کلیدها در ورودی دامنه و/یا گزارشها وجود دارند. علاوه بر این، موارد تکراری در بین دستهها نیز اعمال نمیشوند. توجه داشته باشید که اجرای اشکالزدایی فقط گزارشهایی را در نظر میگیرد که دارای پرچم "debug_mode": "enabled" باشند. از نسخه ۲.۱۰.۰، اجرای اشکالزدایی > بودجه حریم خصوصی را مصرف نمیکند . |
شغل پیدا کنید
وقتی یک تکنسین تبلیغات میخواهد از وضعیت یک دسته درخواستی مطلع شود، میتواند نقطه پایانی getJob را فراخوانی کند. نقطه پایانی getJob با استفاده از یک درخواست HTTPS GET به همراه پارامتر job_request_id فراخوانی میشود.
GET https://<api-gateway>/stage/v1alpha/getJob?job_request_id=<job_request_id>
شما باید پاسخی دریافت کنید که وضعیت کار را به همراه هرگونه پیام خطا برمیگرداند:
{
"job_status": "FINISHED",
"request_received_at": "2023-07-17T19:15:13.926530Z",
"request_updated_at": "2023-07-17T19:15:28.614942839Z",
"job_request_id": "PSD_0003",
"input_data_blob_prefix": "reports/output_reports_2023-07-17T19:11:27.315Z.avro",
"input_data_bucket_name": "ags-report-bucket",
"output_data_blob_prefix": "summary/summary.avro",
"output_data_bucket_name": "ags-report-bucket",
"postback_URL": "",
"result_info": {
"return_code": "SUCCESS",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-07-17T19:15:28.607802354Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "ags-report-bucket",
"output_domain_blob_prefix": "output_domain/output_domain.avro",
"attribution_report_to": "https://privacy-sandcastle-dev-dsp.web.app"
},
"request_processing_started_at": "2023-07-17T19:15:21.583759622Z"
}
فیلدهای پاسخ
| پارامتر | نوع | توضیحات |
|---|---|---|
job_request_id | رشته | این شناسه منحصر به فرد job/batch است که در درخواست createJob مشخص شده است. |
job_status | رشته | این وضعیت درخواست کار است. |
request_received_at | رشته | زمان دریافت درخواست. |
request_updated_at | رشته | آخرین باری که شغل بهروزرسانی شده است. |
input_data_blob_prefix | رشته | این پیشوند داده ورودی است که در createJob تنظیم شده است. |
input_data_bucket_name | رشته | این بخش، محل ذخیرهی دادههای ورودی تکنسین تبلیغات است. این فیلد روی createJob تنظیم شده است. |
output_data_blob_prefix | رشته | این پیشوند داده خروجی است که در createJob تنظیم شده است. |
output_data_bucket_name | رشته | این بخش، محل ذخیرهی دادههای خروجی تکنسین تبلیغات است. گزارشهای خلاصهی تولید شده در این بخش ذخیره میشوند. این فیلد روی createJob تنظیم شده است. |
request_processing_started_at | رشته | زمانی که آخرین تلاش پردازش آغاز شده است. این زمان انتظار در صف کار را شامل نمیشود. (کل زمان پردازش = request_updated_at - request_processing_started_at ) |
result_info | فرهنگ لغت | این نتیجه درخواست createJob است و شامل تمام اطلاعات موجود است. این مقادیر return_code ، return_message ، finished_at و error_summary را نشان میدهد. |
result_info.return_code | رشته | کد برگشتی نتیجه کار. این اطلاعات برای عیبیابی در صورت وجود مشکل در سرویس تجمیع مورد نیاز است. |
result_info.return_message | رشته | پیام موفقیت یا شکست که در نتیجهی کار برگردانده میشود. این اطلاعات همچنین برای عیبیابی مشکلات سرویس تجمیع مورد نیاز است. |
result_info.error_summary | فرهنگ لغت | خطاهایی که از کار برمیگردند. این شامل تعداد گزارشها به همراه نوع خطاهایی است که با آنها مواجه شدهاید. |
result_info.finished_at | مهر زمانی | مهر زمانی که نشان دهنده تکمیل کار است. |
result_info.error_summary.error_counts | فهرست | این دستور لیستی از پیامهای خطا به همراه تعداد گزارشهایی که با همان پیام خطا ناموفق بودهاند را برمیگرداند. هر تعداد خطا شامل یک دستهبندی، error_count و description است. |
result_info.error_summary.error_messages | فهرست | این دستور لیستی از پیامهای خطا از گزارشهایی که پردازش آنها با شکست مواجه شده است را برمیگرداند. |
job_parameters | فرهنگ لغت | این شامل پارامترهای job ارائه شده در درخواست createJob است. ویژگیهای مرتبط مانند `output_domain_blob_prefix` و `output_domain_bucket_name`. |
job_parameters.attribution_report_to | رشته | منحصر به reporting_site . این آدرس گزارش یا مبدا دریافت گزارش است. مبدا بخشی از سایتی است که در Aggregation Service Onboarding ثبت شده است. این در درخواست createJob مشخص شده است. |
job_parameters.reporting_site | رشته | منحصر به فرد متقابل برای attribution_report_to . این نام میزبان URL گزارش یا مبدا دریافت گزارش است. مبدا بخشی از سایتی است که در Aggregation Service Onboarding ثبت شده است. توجه داشته باشید که میتوانید گزارشهایی با چندین مبدا گزارش را در یک درخواست ارسال کنید، مادامی که همه مبداهای گزارش متعلق به یک سایت ذکر شده در این پارامتر باشند. این در درخواست createJob مشخص شده است. علاوه بر این، تأیید کنید که سطل فقط شامل گزارشهایی است که میخواهید در زمان ایجاد شغل جمعآوری شوند. هر گزارشی که به سطل داده ورودی اضافه شود و مبداهای گزارش آن با سایت گزارش مشخص شده در پارامتر شغل مطابقت داشته باشد، پردازش میشود. سرویس تجمیع فقط گزارشهایی را در سطل داده در نظر میگیرد که با مبدا گزارش ثبت شده شغل مطابقت دارند. به عنوان مثال، اگر مبدا ثبت شده https://exampleabc.com باشد، فقط گزارشهایی از https://exampleabc.com گنجانده میشوند، حتی اگر سطل شامل گزارشهایی از زیر دامنهها ( https://1.exampleabc.com و غیره) یا دامنههای کاملاً متفاوت ( https://3.examplexyz.com ) باشد. |
job_parameters.debug_privacy_epsilon | ممیز شناور، دابل | فیلد اختیاری. اگر مقداری ارسال نشود، مقدار پیشفرض ۱۰ استفاده میشود. مقادیر میتوانند از ۰ تا ۶۴ باشند. این مقدار در درخواست createJob مشخص شده است. |
job_parameters.report_error_threshold_percentage | دو برابر | فیلد اختیاری. این درصد آستانه گزارشهایی است که میتوانند قبل از شکست کار، با شکست مواجه شوند. اگر هیچ مقداری اختصاص داده نشود، از مقدار پیشفرض ۱۰٪ استفاده میشود. این مقدار در درخواست createJob مشخص شده است. |
job_parameters.input_report_count | ارزش خرید | فیلد اختیاری. تعداد کل گزارشهای ارائه شده به عنوان دادههای ورودی برای این کار. `report_error_threshold_percentage`، همراه با این مقدار، در صورت حذف تعداد قابل توجهی از گزارشها به دلیل خطا، باعث شکست زودهنگام کار میشود. این تنظیم در درخواست `createJob` مشخص شده است. |
job_parameters.filtering_ids | رشته | فیلد اختیاری. فهرستی از شناسههای فیلترینگ بدون علامت که با کاما از هم جدا شدهاند. تمام مشارکتها به جز شناسه فیلترینگ منطبق، فیلتر میشوند. این مورد در درخواست createJob مشخص شده است. (مثلاً "filtering_ids":"12345,34455,12" . مقدار پیشفرض "0" است.) |