
Nachdem Sie den Aggregationsdienst erfolgreich bereitgestellt haben, können Sie über die Endpunkte createJob und getJob mit dem Dienst interagieren. Das folgende Diagramm zeigt eine visuelle Darstellung der Bereitstellungsarchitektur für diese beiden Endpunkte:
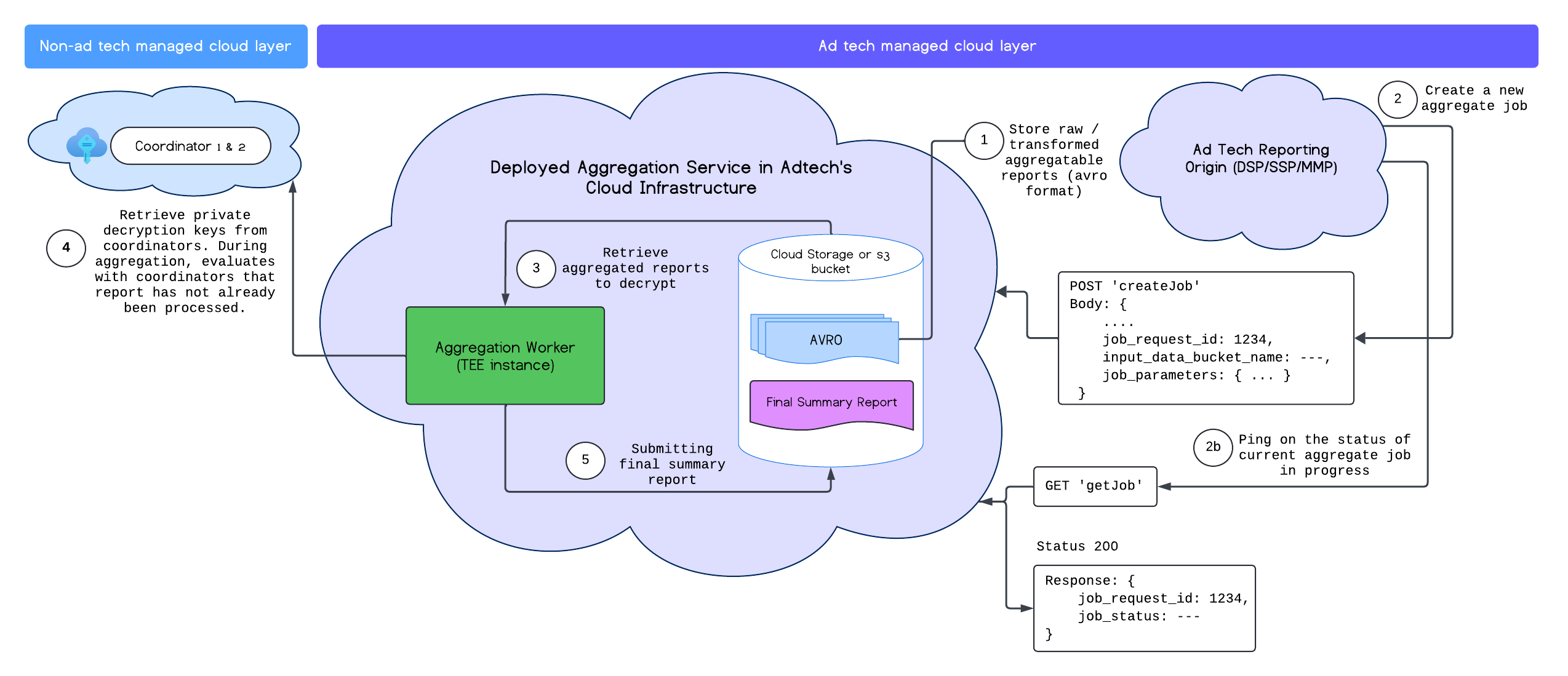
Weitere Informationen zu den Endpunkten createJob und getJob finden Sie in der Dokumentation zur Aggregation Service API.
Job erstellen
Senden Sie zum Erstellen eines Jobs eine POST-Anfrage an den Endpunkt createJob.
bash
POST https://<api-gateway>/stage/v1alpha/createJob
-+
Beispiel für den Anfragetext für createJob:
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<host name of reporting origin>"
}
}
Bei erfolgreicher Job-Erstellung wird der HTTP-Statuscode 202 zurückgegeben.
reporting_site und attribution_report_to schließen sich gegenseitig aus. Nur eines der beiden ist erforderlich.
Sie können auch einen Debug-Job anfordern, indem Sie debug_run in job_parameters einfügen.
Weitere Informationen zum Debug-Modus finden Sie in unserer Dokumentation zum Debug-Lauf für die Aggregation.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>"
"debug_run": "true"
}
}
Anfragefelder
| Parameter | Typ | Beschreibung |
|---|---|---|
job_request_id |
String |
Dies ist eine von Ad-Tech-Unternehmen generierte eindeutige Kennung, die aus ASCII-Buchstaben mit maximal 128 Zeichen bestehen sollte. Dadurch wird die Batchjobanfrage identifiziert und alle aggregierbaren AVRO-Berichte, die im `input_data_blob_prefix` angegeben sind, aus dem Eingabe-Bucket abgerufen, der im `input_data_bucket_name` angegeben ist und im Cloud-Speicher des Ad-Tech-Unternehmens gehostet wird.
Zeichen: `a-z, A-Z, 0-9, !"#$%&'()*+,-./:;<=>?@[\]^_`{}~
|
input_data_blob_prefix |
String |
Dies ist der Bucket-Pfad. Bei einzelnen Dateien können Sie den Pfad verwenden. Bei mehreren Dateien können Sie das Präfix im Pfad verwenden.
Beispiel: Im Ordner/in der Datei werden alle Berichte aus folder/file1.avro, folder/file/file1.avro und folder/file1/test/file2.avro zusammengefasst. |
input_data_bucket_name |
String | Dies ist der Speicher-Bucket für die Eingabedaten oder aggregierbaren Berichte. Die Daten werden im Cloud-Speicher des Ad-Tech-Unternehmens gespeichert. |
output_data_blob_prefix |
String | Dies ist der Ausgabepfad im Bucket. Es wird nur eine Ausgabedatei unterstützt. |
output_data_bucket_name |
String |
Dies ist der Speicher-Bucket, an den output_data gesendet wird. Diese Daten sind im Cloud-Speicher des Ad-Tech-Unternehmens vorhanden.
|
job_parameters |
Wörterbuch |
Pflichtfeld. Dieses Feld enthält die verschiedenen Felder, z. B.:
|
job_parameters.output_domain_blob_prefix |
String |
Ähnlich wie bei input_data_blob_prefix ist dies der Pfad in output_domain_bucket_name, in dem sich Ihr AVRO für die Ausgabedomäne befindet. Bei mehreren Dateien können Sie das Präfix im Pfad verwenden. Sobald der Aggregationsdienst den Batch verarbeitet hat, wird der Zusammenfassungsbericht erstellt und mit dem Namen output_data_blob_prefix im Ausgabebucket output_data_bucket_name abgelegt.
|
job_parameters.output_domain_bucket_name |
String | Dies ist der Speicher-Bucket für Ihre AVRO-Datei für die Ausgabedomäne. Die Daten werden im Cloud-Speicher des Ad-Tech-Unternehmens gespeichert. |
job_parameters.attribution_report_to |
String | Dieser Wert schließt sich gegenseitig mit `reporting_site` aus. Dies ist die Berichts-URL oder der Berichtsursprung, über die bzw. den der Bericht empfangen wurde. Der Website-Ursprung ist im Aggregationsdienst-Onboarding registriert. |
job_parameters.reporting_site |
String |
Schließt sich mit attribution_report_to gegenseitig aus. Dies ist der Hostname der Melde-URL oder des Meldeursprungs, über den der Bericht empfangen wurde. Der Website-Ursprung ist im Aggregationsdienst-Onboarding registriert.
Hinweis: Sie können in einer einzelnen Anfrage mehrere Berichte mit unterschiedlichen Ursprüngen einreichen, sofern alle Ursprünge zur selben Berichtswebsite gehören, die in diesem Parameter angegeben ist.
|
job_parameters.debug_privacy_epsilon |
Gleitkomma, Double | Optionales Feld. Wenn kein Wert übergeben wird, ist der Standardwert 10. Es kann ein Wert zwischen 0 und 64 verwendet werden. |
job_parameters.report_error_threshold_percentage |
Doppelt | Optionales Feld. Dies ist der maximale Prozentsatz fehlgeschlagener Berichte, der zulässig ist, bevor der Job fehlschlägt. Wenn das Feld leer gelassen wird, beträgt der Standardwert 10%. |
job_parameters.input_report_count |
Langer Wert |
Optionales Feld. Die Gesamtzahl der Berichte, die als Eingabedaten für den Job bereitgestellt wurden. In Kombination mit report_error_threshold_percentage ermöglicht dieser Wert, dass Jobs frühzeitig fehlschlagen, wenn Berichte aufgrund von Fehlern ausgeschlossen werden.
|
job_parameters.filtering_ids |
String |
Optionales Feld. Eine durch Kommas getrennte Liste von IDs für die ungezeichnete Filterung. Alle Beiträge, die nicht der entsprechenden Filter-ID entsprechen, werden herausgefiltert. (z.B."filtering_ids": "12345,34455,12"). Der Standardwert ist 0.
|
job_parameters.debug_run |
Boolesch |
Optionales Feld. Bei einem Debug-Lauf werden Debug-Zusammenfassungsberichte mit und ohne Rauschen sowie Anmerkungen hinzugefügt, um anzugeben, welche Schlüssel in der Domain-Eingabe und/oder in den Berichten vorhanden sind. Außerdem werden Duplikate in Batches nicht erzwungen. Beim Debug-Lauf werden nur Berichte mit dem Flag "debug_mode": "enabled" berücksichtigt. Ab Version 2.10.0 wird bei Debug-Läufen kein Datenschutzbudget verbraucht.
|
Job abrufen
Wenn ein Ad-Tech-Unternehmen den Status eines angeforderten Batches wissen möchte, kann es den getJob-Endpunkt aufrufen. Der getJob-Endpunkt wird mit einer HTTPS GET-Anfrage und dem Parameter job_request_id aufgerufen.
GET https://<api-gateway>/stage/v1alpha/getJob?job_request_id=<job_request_id>
Sie sollten eine Antwort mit dem Jobstatus und allen Fehlermeldungen erhalten:
{
"job_status": "FINISHED",
"request_received_at": "2023-07-17T19:15:13.926530Z",
"request_updated_at": "2023-07-17T19:15:28.614942839Z",
"job_request_id": "PSD_0003",
"input_data_blob_prefix": "reports/output_reports_2023-07-17T19:11:27.315Z.avro",
"input_data_bucket_name": "ags-report-bucket",
"output_data_blob_prefix": "summary/summary.avro",
"output_data_bucket_name": "ags-report-bucket",
"postback_URL": "",
"result_info": {
"return_code": "SUCCESS",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-07-17T19:15:28.607802354Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "ags-report-bucket",
"output_domain_blob_prefix": "output_domain/output_domain.avro",
"attribution_report_to": "https://privacy-sandcastle-dev-dsp.web.app"
},
"request_processing_started_at": "2023-07-17T19:15:21.583759622Z"
}
Antwortfelder
| Parameter | Typ | Beschreibung |
|---|---|---|
job_request_id |
String |
Dies ist die eindeutige Job-/Batch-ID, die in der createJob-Anfrage angegeben wurde.
|
job_status |
String | Dies ist der Status der Jobanfrage. |
request_received_at |
String | Der Zeitpunkt, zu dem die Anfrage empfangen wurde. |
request_updated_at |
String | Der Zeitpunkt, zu dem der Job zuletzt aktualisiert wurde. |
input_data_blob_prefix |
String |
Dies ist das Präfix für Eingabedaten, das unter createJob festgelegt wurde.
|
input_data_bucket_name |
String |
Dies ist der Bucket für Eingabedaten der Ad-Tech-Plattform, in dem die aggregierbaren Berichte gespeichert werden. Dieses Feld ist auf createJob gesetzt.
|
output_data_blob_prefix |
String |
Dies ist das Ausgabedatenpräfix, das unter createJob festgelegt wurde.
|
output_data_bucket_name |
String |
Dies ist der Ausgabedaten-Bucket des Anbieters von Anzeigentechnologien, in dem die generierten Zusammenfassungsberichte gespeichert werden. Dieses Feld ist auf createJob gesetzt.
|
request_processing_started_at |
String |
Der Zeitpunkt, zu dem der letzte Verarbeitungsversuch gestartet wurde. Die Wartezeit in der Jobwarteschlange ist nicht enthalten.
(Gesamtbearbeitungszeit = request_updated_at – request_processing_started_at)
|
result_info |
Wörterbuch |
Dies ist das Ergebnis der createJob-Anfrage und enthält alle verfügbaren Informationen.
Hier werden die Werte return_code, return_message, finished_at und error_summary angezeigt.
|
result_info.return_code |
String | Der Rückgabecode des Job-Ergebnisses. Diese Informationen sind für die Fehlerbehebung erforderlich, wenn es ein Problem im Aggregationsdienst gibt. |
result_info.return_message |
String | Die Erfolgs- oder Fehlermeldung, die als Ergebnis des Jobs zurückgegeben wird. Diese Informationen sind auch für die Fehlerbehebung bei Problemen mit dem Aggregationsdienst erforderlich. |
result_info.error_summary |
Wörterbuch | Die Fehler, die vom Job zurückgegeben werden. Hier finden Sie die Anzahl der Berichte sowie die Art der aufgetretenen Fehler. |
result_info.finished_at |
Zeitstempel | Der Zeitstempel für den Abschluss des Jobs. |
result_info.error_summary.error_counts |
Liste |
Daraufhin wird eine Liste der Fehlermeldungen zusammen mit der Anzahl der Berichte zurückgegeben, die mit derselben Fehlermeldung fehlgeschlagen sind. Jede Fehleranzahl enthält eine Kategorie, error_count und description.
|
result_info.error_summary.error_messages |
Liste | Dadurch wird eine Liste der Fehlermeldungen aus Berichten zurückgegeben, die nicht verarbeitet werden konnten. |
job_parameters |
Wörterbuch |
Dieser enthält die Jobparameter, die in der createJob-Anfrage angegeben wurden. Relevante Properties wie „output_domain_blob_prefix“ und „output_domain_bucket_name“.
|
job_parameters.attribution_report_to |
String |
Schließt sich mit reporting_site gegenseitig aus. Dies ist die Berichts-URL oder der Ursprung des Berichts. Der Ursprung ist Teil der Website, die bei der Registrierung des Aggregationsdienstes registriert wurde. Dies wird in der createJob-Anfrage angegeben.
|
job_parameters.reporting_site |
String |
Schließt sich mit attribution_report_to gegenseitig aus. Dies ist der Hostname der Melde-URL oder der Ursprung, von dem der Bericht empfangen wurde. Der Ursprung ist Teil der Website, die bei der Registrierung des Aggregationsdienstes registriert wurde. Sie können Berichte mit mehreren Ursprüngen in derselben Anfrage einreichen, sofern alle Ursprünge zur selben Website gehören, die in diesem Parameter angegeben ist. Dies wird in der createJob-Anfrage angegeben. Prüfen Sie außerdem, ob der Bucket zum Zeitpunkt der Job-Erstellung nur die Berichte enthält, die Sie aggregieren möchten. Alle Berichte, die dem Eingabedaten-Bucket hinzugefügt werden und deren Berichterstellungsursprung mit der im Jobparameter angegebenen Berichterstellungswebsite übereinstimmt, werden verarbeitet.
Der Aggregationsdienst berücksichtigt nur Berichte im Daten-Bucket, die dem registrierten Berichterstellungsursprung des Jobs entsprechen. Wenn der registrierte Ursprung beispielsweise https://beispielabc.de ist, werden nur Berichte von https://beispielabc.de berücksichtigt, auch wenn der Bucket Berichte von Subdomains (https://1.exampleabc.com usw.) oder völlig anderen Domains (https://3.examplexyz.com) enthält.
|
job_parameters.debug_privacy_epsilon |
Gleitkomma, Double |
Optionales Feld. Wenn kein Wert übergeben wird, wird der Standardwert 10 verwendet. Die Werte können zwischen 0 und 64 liegen. Dieser Wert wird in der createJob-Anfrage angegeben.
|
job_parameters.report_error_threshold_percentage |
Doppelt |
Optionales Feld. Dies ist der Grenzwert für den Prozentsatz der Berichte, die fehlschlagen können, bevor der Job fehlschlägt. Wenn kein Wert zugewiesen ist, wird der Standardwert von 10% verwendet. Dies wird in der createJob-Anfrage angegeben.
|
job_parameters.input_report_count |
Langer Wert | Optionales Feld. Die Gesamtzahl der Berichte, die als Eingabedaten für diesen Job bereitgestellt wurden. Der Wert für `report_error_threshold_percentage` in Kombination mit diesem Wert führt zu einem vorzeitigen Jobfehler, wenn eine erhebliche Anzahl von Berichten aufgrund von Fehlern ausgeschlossen wird. Diese Einstellung wird in der `createJob`-Anfrage angegeben. |
job_parameters.filtering_ids |
String |
Optionales Feld. Eine durch Kommas getrennte Liste von IDs für die ungekennzeichnete Filterung. Alle Beiträge mit Ausnahme der übereinstimmenden Filter-ID werden herausgefiltert. Dies wird in der createJob-Anfrage angegeben.
z.B. "filtering_ids":"12345,34455,12". Der Standardwert ist „0“.)
|