
Une fois le service d'agrégation déployé, vous pouvez utiliser les points de terminaison createJob et getJob pour interagir avec le service. Le schéma suivant fournit une représentation visuelle de l'architecture de déploiement pour ces deux points de terminaison :
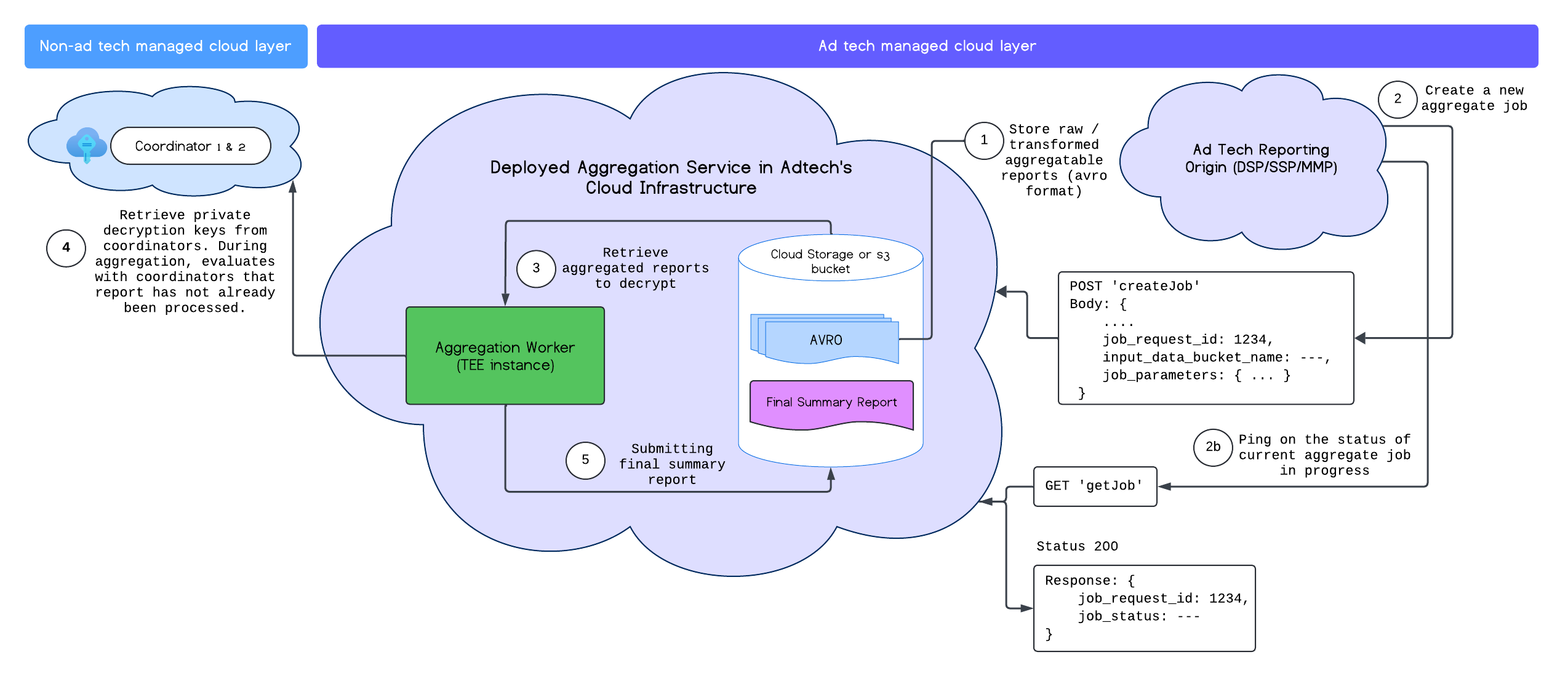
Pour en savoir plus sur les points de terminaison createJob et getJob, consultez la documentation de l'API Aggregation Service.
Créer une tâche
Pour créer un job, envoyez une requête POST au point de terminaison createJob.
bash
POST https://<api-gateway>/stage/v1alpha/createJob
-+
Exemple de corps de requête pour createJob :
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<host name of reporting origin>"
}
}
Si la création du job réussit, le code d'état HTTP 202 est renvoyé.
Notez que reporting_site et attribution_report_to s'excluent mutuellement et qu'un seul est requis.
Vous pouvez également demander un job de débogage en ajoutant debug_run dans job_parameters.
Pour en savoir plus sur le mode débogage, consultez notre documentation sur l'exécution du débogage de l'agrégation.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>"
"debug_run": "true"
}
}
Champs des demandes
| Paramètre | Type | Description |
|---|---|---|
job_request_id |
Chaîne |
Il s'agit d'un identifiant unique généré par la technologie publicitaire. Il doit être composé de lettres ASCII et ne pas comporter plus de 128 caractères. Cela identifie la requête de tâche par lot et prend tous les rapports AVRO agrégables spécifiés dans le `input_data_blob_prefix` du bucket d'entrée spécifié dans le `input_data_bucket_name` hébergé sur le stockage cloud de l'ad tech.
Caractères : `a-z, A-Z, 0-9, !"#$%&'()*+,-./:;<=>?@[\]^_`{}~
|
input_data_blob_prefix |
Chaîne |
Il s'agit du chemin d'accès au bucket. Pour les fichiers individuels, vous pouvez utiliser le chemin d'accès. Pour plusieurs fichiers, vous pouvez utiliser le préfixe dans le chemin d'accès.
Exemple : Le dossier/fichier collecte tous les rapports de folder/file1.avro, folder/file/file1.avro et folder/file1/test/file2.avro. |
input_data_bucket_name |
Chaîne | Il s'agit du bucket de stockage pour les données d'entrée ou les rapports agrégables. Il s'agit du stockage cloud de l'ad tech. |
output_data_blob_prefix |
Chaîne | Il s'agit du chemin d'accès au fichier de sortie dans le bucket. Un seul fichier de sortie est accepté. |
output_data_bucket_name |
Chaîne |
Il s'agit du bucket de stockage dans lequel le output_data est envoyé. Il se trouve dans l'espace de stockage cloud de l'ad tech.
|
job_parameters |
Dictionnaire |
Champ obligatoire. Ce champ contient les différents champs, tels que :
|
job_parameters.output_domain_blob_prefix |
Chaîne |
Semblable à input_data_blob_prefix, il s'agit du chemin d'accès dans output_domain_bucket_name où se trouve votre fichier AVRO de domaine de sortie. Pour plusieurs fichiers, vous pouvez utiliser le préfixe dans le chemin d'accès. Une fois que le service d'agrégation a terminé le lot, le rapport récapitulatif est créé et placé dans le bucket de sortie output_data_bucket_name avec le nom output_data_blob_prefix.
|
job_parameters.output_domain_bucket_name |
Chaîne | Il s'agit du bucket de stockage pour votre fichier AVRO de domaine de sortie. Il s'agit du stockage cloud de l'ad tech. |
job_parameters.attribution_report_to |
Chaîne | Cette valeur est mutuellement exclusive à `reporting_site`. Il s'agit de l'URL ou de l'origine du site de signalement où le rapport a été reçu. L'origine du site est enregistrée dans l'intégration d'Aggregation Service. |
job_parameters.reporting_site |
Chaîne |
S'exclut mutuellement avec attribution_report_to. Il s'agit du nom d'hôte de l'URL ou de l'origine du rapport où le rapport a été reçu. L'origine du site est enregistrée dans l'intégration d'Aggregation Service.
Remarque : Vous pouvez envoyer plusieurs rapports avec des origines différentes dans une même demande, à condition que toutes les origines appartiennent au même site de signalement spécifié dans ce paramètre.
|
job_parameters.debug_privacy_epsilon |
Virgule flottante, double | Champ facultatif. Si aucune valeur n'est transmise, la valeur par défaut est 10. Vous pouvez utiliser une valeur comprise entre 0 et 64. |
job_parameters.report_error_threshold_percentage |
Double | Champ facultatif. Il s'agit du pourcentage maximal de rapports ayant échoué autorisé avant l'échec du job. Si vous ne spécifiez pas de valeur, la valeur par défaut est de 10 %. |
job_parameters.input_report_count |
valeur longue |
Champ facultatif. Nombre total de rapports fournis comme données d'entrée pour le job. Cette valeur, associée à report_error_threshold_percentage, permet d'identifier rapidement les échecs de tâches lorsque des rapports sont exclus en raison d'erreurs.
|
job_parameters.filtering_ids |
Chaîne |
Champ facultatif. Liste d'ID de filtrage non signés séparés par une virgule. Toutes les contributions autres que l'ID de filtrage correspondant sont filtrées. (par exemple, "filtering_ids": "12345,34455,12"). La valeur par défaut est 0.
|
job_parameters.debug_run |
Booléen |
Champ facultatif. Lorsque vous exécutez un débogage, des rapports récapitulatifs de débogage avec et sans bruit, ainsi que des annotations, sont ajoutés pour indiquer les clés présentes dans l'entrée et/ou les rapports de domaine. De plus, les doublons entre les lots ne sont pas non plus appliqués. Notez que l'exécution de débogage ne prend en compte que les rapports comportant l'indicateur "debug_mode": "enabled". Depuis la version 2.10.0, les exécutions de débogage ne consomment pas de budget de confidentialité.
|
Obtenir une tâche
Lorsqu'une technologie publicitaire souhaite connaître l'état d'un lot demandé, elle peut appeler le point de terminaison getJob. Le point de terminaison getJob est appelé à l'aide d'une requête HTTPS GET avec le paramètre job_request_id.
GET https://<api-gateway>/stage/v1alpha/getJob?job_request_id=<job_request_id>
Vous devriez obtenir une réponse qui renvoie l'état du job ainsi que les éventuels messages d'erreur :
{
"job_status": "FINISHED",
"request_received_at": "2023-07-17T19:15:13.926530Z",
"request_updated_at": "2023-07-17T19:15:28.614942839Z",
"job_request_id": "PSD_0003",
"input_data_blob_prefix": "reports/output_reports_2023-07-17T19:11:27.315Z.avro",
"input_data_bucket_name": "ags-report-bucket",
"output_data_blob_prefix": "summary/summary.avro",
"output_data_bucket_name": "ags-report-bucket",
"postback_URL": "",
"result_info": {
"return_code": "SUCCESS",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-07-17T19:15:28.607802354Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "ags-report-bucket",
"output_domain_blob_prefix": "output_domain/output_domain.avro",
"attribution_report_to": "https://privacy-sandcastle-dev-dsp.web.app"
},
"request_processing_started_at": "2023-07-17T19:15:21.583759622Z"
}
Champs de réponse
| Paramètre | Type | Description |
|---|---|---|
job_request_id |
Chaîne |
Il s'agit de l'ID de job/de lot unique spécifié dans la requête createJob.
|
job_status |
Chaîne | Il s'agit de l'état de la demande de tâche. |
request_received_at |
Chaîne | Heure à laquelle la demande a été reçue. |
request_updated_at |
Chaîne | Heure de la dernière mise à jour du job. |
input_data_blob_prefix |
Chaîne |
Il s'agit du préfixe des données d'entrée qui a été défini sur createJob.
|
input_data_bucket_name |
Chaîne |
Il s'agit du bucket de données d'entrée de l'ad tech dans lequel sont stockés les rapports agrégables. Ce champ est défini sur createJob.
|
output_data_blob_prefix |
Chaîne |
Il s'agit du préfixe des données de sortie défini sur createJob.
|
output_data_bucket_name |
Chaîne |
Il s'agit du bucket de données de sortie de l'ad tech dans lequel sont stockés les rapports récapitulatifs générés. Ce champ est défini sur createJob.
|
request_processing_started_at |
Chaîne |
Heure de début de la dernière tentative de traitement. Le temps d'attente dans la file d'attente des tâches n'est pas inclus.
(Temps de traitement total = request_updated_at - request_processing_started_at)
|
result_info |
Dictionnaire |
Il s'agit du résultat de la requête createJob et il contient toutes les informations disponibles.
Les valeurs return_code, return_message, finished_at et error_summary s'affichent.
|
result_info.return_code |
Chaîne | Code de retour du résultat du job. Ces informations sont nécessaires pour le dépannage en cas de problème dans le service d'agrégation. |
result_info.return_message |
Chaîne | Message de réussite ou d'échec renvoyé à la suite du job. Ces informations sont également nécessaires pour résoudre les problèmes liés au service d'agrégation. |
result_info.error_summary |
Dictionnaire | Erreurs renvoyées par le job. Il indique le nombre de rapports ainsi que les types d'erreurs rencontrées. |
result_info.finished_at |
Horodatage | Code temporel indiquant la fin du job. |
result_info.error_summary.error_counts |
Liste |
Cette commande renvoie une liste des messages d'erreur ainsi que le nombre de rapports ayant échoué avec le même message d'erreur. Chaque nombre d'erreurs contient une catégorie, error_count et description.
|
result_info.error_summary.error_messages |
Liste | Cette fonction renvoie une liste des messages d'erreur des rapports qui n'ont pas pu être traités. |
job_parameters |
Dictionnaire |
Il contient les paramètres de job fournis dans la requête createJob. Propriétés pertinentes telles que "output_domain_blob_prefix" et "output_domain_bucket_name".
|
job_parameters.attribution_report_to |
Chaîne |
S'exclut mutuellement avec reporting_site. Il s'agit de l'URL de signalement ou de l'origine du signalement. L'origine fait partie du site enregistré dans l'intégration d'Aggregation Service. Cette valeur est spécifiée dans la requête createJob.
|
job_parameters.reporting_site |
Chaîne |
S'exclut mutuellement avec attribution_report_to. Il s'agit du nom d'hôte de l'URL de signalement ou de l'origine du signalement reçu. L'origine fait partie du site enregistré dans l'intégration d'Aggregation Service. Notez que vous pouvez envoyer des rapports avec plusieurs origines de signalement dans la même demande, à condition que toutes les origines de signalement appartiennent au même site mentionné dans ce paramètre. Cette valeur est spécifiée dans la requête createJob. Vérifiez également que le bucket ne contient que les rapports que vous souhaitez agréger au moment de la création du job. Tous les rapports ajoutés au bucket de données d'entrée dont les origines de reporting correspondent au site de reporting spécifié dans le paramètre du job sont traités.
Le service d'agrégation ne prend en compte que les rapports du bucket de données qui correspondent à l'origine de reporting enregistrée pour le job. Par exemple, si l'origine enregistrée est https://exampleabc.com, seuls les rapports provenant de https://exampleabc.com sont inclus, même si le bucket contient des rapports provenant de sous-domaines (https://1.exampleabc.com, etc.) ou de domaines entièrement différents (https://3.examplexyz.com).
|
job_parameters.debug_privacy_epsilon |
Virgule flottante, double |
Champ facultatif. Si aucune valeur n'est transmise, la valeur par défaut de 10 est utilisée. Les valeurs peuvent être comprises entre 0 et 64. Cette valeur est spécifiée dans la requête createJob.
|
job_parameters.report_error_threshold_percentage |
Double |
Champ facultatif. Il s'agit du pourcentage seuil de rapports pouvant échouer avant l'échec du job. Si aucune valeur n'est attribuée, la valeur par défaut de 10 % est utilisée. Cette valeur est spécifiée dans la requête createJob.
|
job_parameters.input_report_count |
Valeur longue | Champ facultatif. Nombre total de rapports fournis en tant que données d'entrée pour ce job. Combinée à cette valeur, la variable `report_error_threshold_percentage` déclenche l'échec précoce du job si un nombre important de rapports sont exclus en raison d'erreurs. Ce paramètre est spécifié dans la requête `createJob`. |
job_parameters.filtering_ids |
Chaîne |
Champ facultatif. Liste d'ID de filtrage non signés séparés par une virgule. Toutes les contributions autres que l'ID de filtrage correspondant sont filtrées. Cette valeur est spécifiée dans la requête createJob.
(par exemple, "filtering_ids":"12345,34455,12". La valeur par défaut est "0".)
|