
Depois de implantar o serviço de agregação, use os endpoints createJob e getJob para interagir com ele. O diagrama a seguir mostra uma representação visual da arquitetura de implantação desses dois endpoints:
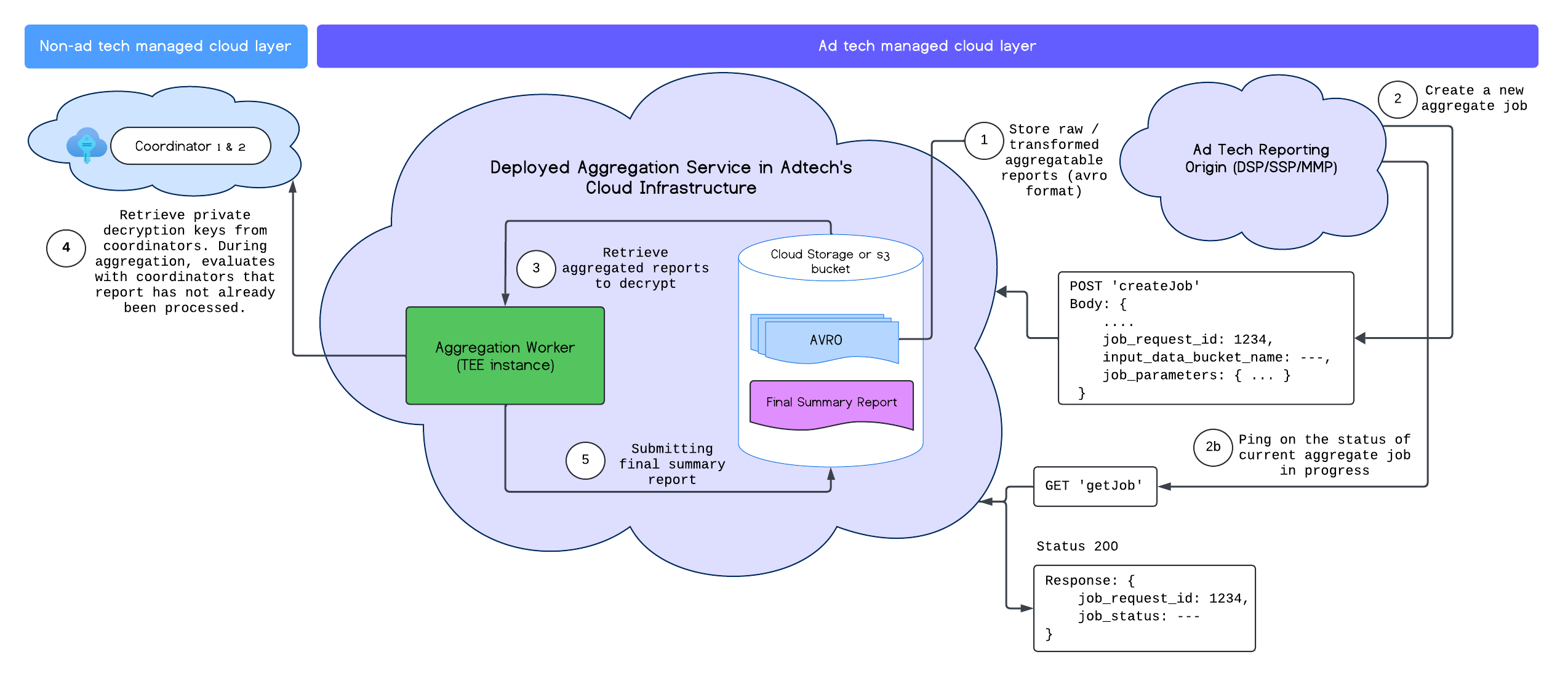
Leia mais sobre os endpoints createJob e getJob na documentação da API Aggregation Service.
Criar um job
Para criar um job, envie uma solicitação POST para o endpoint createJob.
bash
POST https://<api-gateway>/stage/v1alpha/createJob
-+
Exemplo do corpo da solicitação para createJob:
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<host name of reporting origin>"
}
}
A criação de um job bem-sucedida resulta em um código de status HTTP 202.
reporting_site e attribution_report_to são mutuamente exclusivos, e apenas um deles é obrigatório.
Também é possível solicitar um job de depuração adicionando debug_run ao job_parameters.
Para mais informações sobre o modo de depuração, confira nossa documentação de execução de depuração de agregação.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>"
"debug_run": "true"
}
}
Campos de solicitação
| Parâmetro | Tipo | Descrição |
|---|---|---|
job_request_id |
String |
É um identificador exclusivo gerado por adtech que precisa ter letras ASCII com até 128 caracteres. Isso identifica a solicitação de job em lote e extrai todos os relatórios AVRO agregáveis especificados em "input_data_blob_prefix" do bucket de entrada especificado em "input_data_bucket_name", que está hospedado no armazenamento em nuvem da adtech.
Caracteres: `a-z, A-Z, 0-9, !"#$%&'()*+,-./:;<=>?@[\]^_`{}~
|
input_data_blob_prefix |
String |
Esse é o caminho do bucket. Para arquivos únicos, use o caminho. Para vários arquivos, use o prefixo no caminho.
Exemplo: a pasta/arquivo coleta todos os relatórios de pasta/arquivo1.avro, pasta/arquivo/arquivo1.avro e pasta/arquivo1/test/arquivo2.avro. |
input_data_bucket_name |
String | Esse é o bucket de armazenamento para os dados de entrada ou relatórios agregáveis. Isso fica no armazenamento em nuvem da adtech. |
output_data_blob_prefix |
String | Esse é o caminho de saída no bucket. É possível usar apenas um arquivo de saída. |
output_data_bucket_name |
String |
Esse é o bucket de armazenamento para onde o output_data é enviado. Ele fica no armazenamento em nuvem da adtech.
|
job_parameters |
Dicionário |
Campo obrigatório. Esse campo contém os diferentes campos, como:
|
job_parameters.output_domain_blob_prefix |
String |
Semelhante a input_data_blob_prefix, este é o caminho no output_domain_bucket_name em que o AVRO do domínio de saída está localizado. Para vários arquivos, use o prefixo no caminho. Quando o serviço de agregação conclui o lote, o relatório de resumo é criado e colocado no bucket de saída output_data_bucket_name com o nome output_data_blob_prefix.
|
job_parameters.output_domain_bucket_name |
String | Este é o bucket de armazenamento do arquivo AVRO do domínio de saída. Isso fica no armazenamento em nuvem da adtech. |
job_parameters.attribution_report_to |
String | Esse valor é mutuamente exclusivo de "reporting_site". É o URL ou a origem de geração de relatórios em que o relatório foi recebido. A origem do site está registrada na integração do serviço de agregação. |
job_parameters.reporting_site |
String |
Mutuamente exclusivo de attribution_report_to. É o nome do host do URL ou da origem de relatório em que o relatório foi recebido. A origem do site está registrada na integração do serviço de agregação.
Observação: é possível enviar vários relatórios com origens diferentes em uma única solicitação, desde que todas as origens pertençam ao mesmo site de geração de relatórios especificado neste parâmetro.
|
job_parameters.debug_privacy_epsilon |
Ponto flutuante, duplo | Campo opcional. Se nenhum valor for transmitido, o padrão será 10. Um valor de 0 a 64 pode ser usado. |
job_parameters.report_error_threshold_percentage |
Duplo | Campo opcional. Essa é a porcentagem máxima de relatórios com falha permitida antes da falha do job. Se ficar em branco, o valor padrão será 10%. |
job_parameters.input_report_count |
valor longo |
Campo opcional. O número total de relatórios fornecidos como dados de entrada para o job. Esse valor, em conjunto com report_error_threshold_percentage, permite a falha antecipada do job quando os relatórios são excluídos devido a erros.
|
job_parameters.filtering_ids |
String |
Campo opcional. Uma lista de IDs de filtragem não assinados separados por vírgula. Todas as contribuições, exceto o ID de filtragem correspondente, são filtradas. (por exemplo, "filtering_ids": "12345,34455,12"). O valor padrão é 0.
|
job_parameters.debug_run |
Booleano |
Campo opcional. Ao executar uma depuração, os relatórios e as anotações de resumo de depuração com e sem ruído são adicionados para indicar quais chaves estão presentes na entrada de domínio e/ou nos relatórios. Além disso, não há aplicação de duplicatas em lotes. A execução de depuração só considera relatórios com a flag "debug_mode": "enabled". A partir da v2.10.0, as execuções de depuração não consomem o orçamento de privacidade.
|
Receber um job
Quando uma adtech quer saber o status de um lote solicitado, ela pode chamar o endpoint getJob. O endpoint getJob é chamado usando uma solicitação HTTPS GET com o parâmetro job_request_id.
GET https://<api-gateway>/stage/v1alpha/getJob?job_request_id=<job_request_id>
Você vai receber uma resposta que retorna o status do job e as mensagens de erro:
{
"job_status": "FINISHED",
"request_received_at": "2023-07-17T19:15:13.926530Z",
"request_updated_at": "2023-07-17T19:15:28.614942839Z",
"job_request_id": "PSD_0003",
"input_data_blob_prefix": "reports/output_reports_2023-07-17T19:11:27.315Z.avro",
"input_data_bucket_name": "ags-report-bucket",
"output_data_blob_prefix": "summary/summary.avro",
"output_data_bucket_name": "ags-report-bucket",
"postback_URL": "",
"result_info": {
"return_code": "SUCCESS",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-07-17T19:15:28.607802354Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "ags-report-bucket",
"output_domain_blob_prefix": "output_domain/output_domain.avro",
"attribution_report_to": "https://privacy-sandcastle-dev-dsp.web.app"
},
"request_processing_started_at": "2023-07-17T19:15:21.583759622Z"
}
Campos de resposta
| Parâmetro | Tipo | Descrição |
|---|---|---|
job_request_id |
String |
É o ID exclusivo do job/lote especificado na solicitação createJob.
|
job_status |
String | É o status da solicitação de job. |
request_received_at |
String | A hora em que a solicitação foi recebida. |
request_updated_at |
String | A hora em que o job foi atualizado pela última vez. |
input_data_blob_prefix |
String |
Esse é o prefixo dos dados de entrada definido em createJob.
|
input_data_bucket_name |
String |
Esse é o bucket de dados de entrada da adtech em que os relatórios agregáveis são armazenados. Esse campo está definido como createJob.
|
output_data_blob_prefix |
String |
Esse é o prefixo de dados de saída definido em createJob.
|
output_data_bucket_name |
String |
Esse é o bucket de dados de saída da adtech em que os relatórios de resumo gerados são armazenados. Esse campo está definido como createJob.
|
request_processing_started_at |
String |
O horário em que a última tentativa de processamento foi iniciada. Isso exclui o tempo de espera na fila de jobs.
(Tempo total de processamento = request_updated_at - request_processing_started_at)
|
result_info |
Dicionário |
Esse é o resultado da solicitação createJob e consiste em todas as informações disponíveis.
Isso mostra os valores return_code, return_message, finished_at e error_summary.
|
result_info.return_code |
String | O código de retorno do resultado do job. Essas informações são necessárias para a solução de problemas se houver um problema no serviço de agregação. |
result_info.return_message |
String | A mensagem de sucesso ou falha retornada como resultado do job. Essas informações também são necessárias para resolver problemas do Serviço de agregação. |
result_info.error_summary |
Dicionário | Os erros retornados pelo job. Ele contém o número de relatórios e o tipo de erros encontrados. |
result_info.finished_at |
Carimbo de data/hora | O carimbo de data/hora que indica a conclusão do job. |
result_info.error_summary.error_counts |
Lista |
Isso retorna uma lista das mensagens de erro e o número de relatórios que falharam com a mesma mensagem. Cada contagem de erros contém uma categoria, error_count e description.
|
result_info.error_summary.error_messages |
Lista | Isso retorna uma lista das mensagens de erro dos relatórios que não foram processados. |
job_parameters |
Dicionário |
Contém os parâmetros do job fornecidos na solicitação createJob. Propriedades relevantes, como "output_domain_blob_prefix" e "output_domain_bucket_name".
|
job_parameters.attribution_report_to |
String |
Mutuamente exclusivo de reporting_site. É o URL de relatório ou a origem de onde o relatório foi recebido. A origem faz parte do site registrado na integração do serviço de agregação. Isso é especificado na solicitação createJob.
|
job_parameters.reporting_site |
String |
Mutuamente exclusivo de attribution_report_to. É o nome do host do URL de relatório ou a origem de onde o relatório foi recebido. A origem faz parte do site registrado na integração do serviço de agregação. É possível enviar relatórios com várias origens de relatórios na mesma solicitação, desde que todas as origens pertençam ao mesmo site mencionado nesse parâmetro. Isso é especificado na solicitação createJob. Além disso, verifique se o bucket contém apenas os relatórios que você quer agregar no momento da criação do job. Todos os relatórios adicionados ao bucket de dados de entrada com origens de relatórios correspondentes ao site especificado no parâmetro do job são processados.
O serviço de agregação considera apenas os relatórios no bucket de dados que correspondem à origem de relatórios registrada do job. Por exemplo, se a origem registrada for https://exampleabc.com, somente os relatórios de https://exampleabc.com serão incluídos, mesmo que o bucket contenha relatórios de subdomínios (https://1.exampleabc.com etc.) ou domínios totalmente diferentes (https://3.examplexyz.com).
|
job_parameters.debug_privacy_epsilon |
Ponto flutuante, duplo |
Campo opcional. Se nenhum valor for transmitido, o valor padrão de 10 será usado. Os valores podem variar de 0 a 64. Esse valor é especificado na solicitação createJob.
|
job_parameters.report_error_threshold_percentage |
Duplo |
Campo opcional. Essa é a porcentagem limite de relatórios que podem falhar antes da falha do job. Se nenhum valor for atribuído, o valor padrão de 10% será usado. Isso é especificado na solicitação createJob.
|
job_parameters.input_report_count |
Valor longo | Campo opcional. O número total de relatórios fornecidos como dados de entrada para este job. O `report_error_threshold_percentage`, combinado com esse valor, aciona a falha antecipada do job se um número significativo de relatórios for excluído devido a erros. Essa configuração é especificada na solicitação "createJob". |
job_parameters.filtering_ids |
String |
Campo opcional. Uma lista de IDs de filtragem não assinados separados por vírgula. Todas as contribuições, exceto o ID de filtragem correspondente, são filtradas. Isso é especificado na solicitação createJob.
(por exemplo, "filtering_ids":"12345,34455,12". O valor padrão é "0".)
|