
集計サービスを正常にデプロイしたら、createJob エンドポイントと getJob エンドポイントを使用してサービスを操作できます。次の図は、これら 2 つのエンドポイントのデプロイ アーキテクチャを視覚的に表しています。
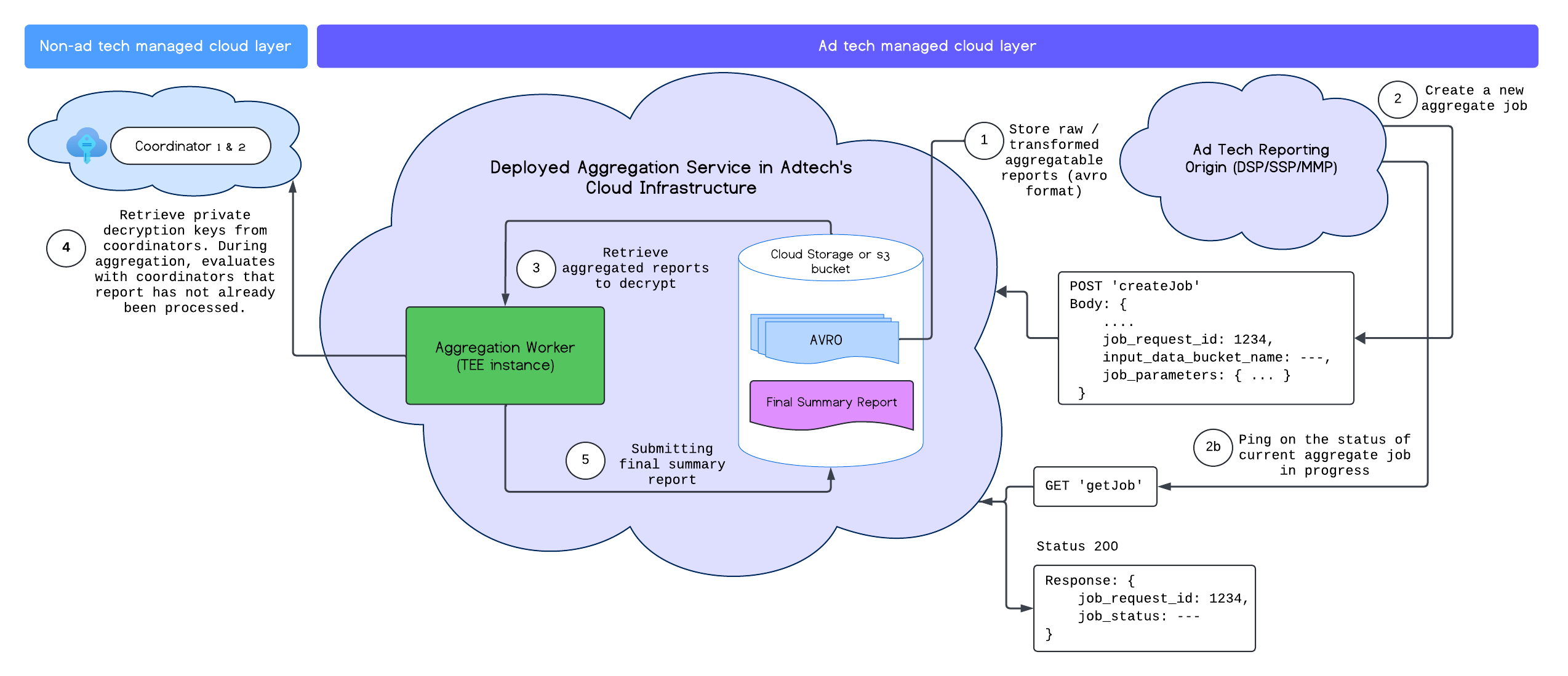
createJob エンドポイントと getJob エンドポイントの詳細については、集計サービス API ドキュメントをご覧ください。
ジョブを作成する
ジョブを作成するには、createJob エンドポイントに POST リクエストを送信します。bash
POST https://<api-gateway>/stage/v1alpha/createJob
-+
createJob のリクエスト本文の例:
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<host name of reporting origin>"
}
}
ジョブが正常に作成されると、202 HTTP ステータス コードが返されます。
reporting_site と attribution_report_to は相互に排他的であり、どちらか一方のみが必要です。
job_parameters に debug_run を追加して、デバッグジョブをリクエストすることもできます。デバッグモードの詳細については、集計デバッグ実行に関するドキュメントをご覧ください。
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>"
"debug_run": "true"
}
}
リクエスト フィールド
| パラメータ | 型 | 説明 |
|---|---|---|
job_request_id |
文字列 |
これは、広告テクノロジーによって生成される一意の識別子です。ASCII 文字で 128 文字以下にする必要があります。これにより、バッチジョブ リクエストが識別され、広告テクノロジーのクラウド ストレージでホストされている `input_data_bucket_name` で指定された入力バケットから、`input_data_blob_prefix` で指定された集計可能なすべての AVRO レポートが取得されます。 文字数: `a-z, A-Z, 0-9, !"#$%&'()*+,-./:;<=>?@[\]^_`{}~
|
input_data_blob_prefix |
文字列 |
これがバケットパスです。単一のファイルの場合は、パスを使用できます。複数のファイルの場合は、パスに接頭辞を使用できます。 例: フォルダ/ファイルは、folder/file1.avro、folder/file/file1.avro、folder/file1/test/file2.avro からすべてのレポートを収集します。 |
input_data_bucket_name |
文字列 | これは、入力データまたは集計可能なレポートのストレージ バケットです。これは広告テクノロジーのクラウド ストレージにあります。 |
output_data_blob_prefix |
文字列 | これはバケット内の出力パスです。単一の出力ファイルがサポートされています。 |
output_data_bucket_name |
文字列 |
これは、output_data が送信されるストレージ バケットです。これは、広告テクノロジーのクラウド ストレージに存在します。 |
job_parameters |
Dictionary |
必須フィールド。このフィールドには、次のようなさまざまなフィールドが含まれています。
|
job_parameters.output_domain_blob_prefix |
文字列 |
input_data_blob_prefix と同様に、これは出力ドメイン AVRO が配置されている output_domain_bucket_name のパスです。複数のファイルの場合は、パスに接頭辞を使用できます。集計サービスがバッチを完了すると、概要レポートが作成され、出力バケット output_data_bucket_name に output_data_blob_prefix という名前で配置されます。 |
job_parameters.output_domain_bucket_name |
文字列 | これは、出力ドメイン AVRO ファイルのストレージ バケットです。これは広告テクノロジーのクラウド ストレージにあります。 |
job_parameters.attribution_report_to |
文字列 | この値は `reporting_site` と相互に排他的です。これは、レポートが受信されたレポート URL またはレポート配信元です。サイトのオリジンが Aggregation Service Onboarding に登録されます。 |
job_parameters.reporting_site |
文字列 |
attribution_report_to とは相互に排他的です。これは、レポートが受信されたレポート URL またはレポート元のホスト名です。サイトのオリジンが Aggregation Service Onboarding に登録されます。注: このパラメータで指定されたレポートサイトにすべてのオリジンが属している場合、1 つのリクエスト内で異なるオリジンを含む複数のレポートを送信できます。 |
job_parameters.debug_privacy_epsilon |
浮動小数点、倍精度 | 省略可能フィールド。値が渡されない場合、デフォルト値は 10 です。0 ~ 64 の値を使用できます。 |
job_parameters.report_error_threshold_percentage |
Double | 省略可能フィールド。これは、ジョブが失敗する前に許容される失敗したレポートの最大割合です。空のままにすると、デフォルト値は 10% になります。 |
job_parameters.input_report_count |
長い値 |
省略可能フィールド。ジョブの入力データとして提供されたレポートの合計数。この値と report_error_threshold_percentage を組み合わせることで、エラーによりレポートが除外された場合にジョブを早期に失敗させることができます。 |
job_parameters.filtering_ids |
文字列 |
省略可能フィールド。カンマで区切られた符号なしフィルタリング ID のリスト。一致するフィルタリング ID 以外のすべての投稿がフィルタで除外されます。(例: "filtering_ids": "12345,34455,12")。デフォルト値は 0 です。 |
job_parameters.debug_run |
ブール値 |
省略可能フィールド。デバッグ実行を行うと、ノイズありとノイズなしのデバッグ概要レポートとアノテーションが追加され、ドメイン入力やレポートにどのキーが存在するかが示されます。また、バッチ間の重複も適用されません。デバッグ実行では、"debug_mode": "enabled" フラグが設定されているレポートのみが考慮されます。v2.10.0 以降、デバッグ実行ではプライバシー バジェットは消費されません。> |
ジョブの取得
広告テクノロジーがリクエストされたバッチのステータスを確認したい場合は、getJob エンドポイントを呼び出すことができます。getJob エンドポイントは、job_request_id パラメータとともに HTTPS GET リクエストを使用して呼び出されます。
GET https://<api-gateway>/stage/v1alpha/getJob?job_request_id=<job_request_id>
ジョブのステータスとエラー メッセージが返されるレスポンスが返されます。
{
"job_status": "FINISHED",
"request_received_at": "2023-07-17T19:15:13.926530Z",
"request_updated_at": "2023-07-17T19:15:28.614942839Z",
"job_request_id": "PSD_0003",
"input_data_blob_prefix": "reports/output_reports_2023-07-17T19:11:27.315Z.avro",
"input_data_bucket_name": "ags-report-bucket",
"output_data_blob_prefix": "summary/summary.avro",
"output_data_bucket_name": "ags-report-bucket",
"postback_URL": "",
"result_info": {
"return_code": "SUCCESS",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-07-17T19:15:28.607802354Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "ags-report-bucket",
"output_domain_blob_prefix": "output_domain/output_domain.avro",
"attribution_report_to": "https://privacy-sandcastle-dev-dsp.web.app"
},
"request_processing_started_at": "2023-07-17T19:15:21.583759622Z"
}
レスポンスのフィールド
| パラメータ | 型 | 説明 |
|---|---|---|
job_request_id |
文字列 |
これは、createJob リクエストで指定された一意のジョブ/バッチ ID です。 |
job_status |
文字列 | ジョブ リクエストのステータスです。 |
request_received_at |
文字列 | リクエストを受信した時刻。 |
request_updated_at |
文字列 | ジョブが最後に更新された時刻。 |
input_data_blob_prefix |
文字列 |
これは、createJob で設定された入力データ接頭辞です。 |
input_data_bucket_name |
文字列 |
これは、集計可能レポートが保存される広告テクノロジーの入力データ バケットです。このフィールドは createJob に設定されています。 |
output_data_blob_prefix |
文字列 |
これは、createJob で設定された出力データ接頭辞です。 |
output_data_bucket_name |
文字列 |
これは、生成された概要レポートが保存される広告テクノロジーの出力データバケットです。このフィールドは createJob に設定されています。 |
request_processing_started_at |
文字列 |
最新の処理試行が開始された時刻。これには、ジョブキューでの待機時間は含まれません。(合計処理時間 = request_updated_at - request_processing_started_at)
|
result_info |
Dictionary |
これは createJob リクエストの結果であり、利用可能なすべての情報で構成されています。return_code、return_message、finished_at、error_summary の値が表示されます。 |
result_info.return_code |
文字列 | ジョブ結果の戻りコード。この情報は、集計サービスで問題が発生した場合のトラブルシューティングに必要です。 |
result_info.return_message |
文字列 | ジョブの結果として返される成功または失敗のメッセージ。この情報は、集計サービスの問題のトラブルシューティングにも必要です。 |
result_info.error_summary |
Dictionary | ジョブから返されるエラー。これには、レポートの数と発生したエラーの種類が含まれます。 |
result_info.finished_at |
タイムスタンプ | ジョブの完了を示すタイムスタンプ。 |
result_info.error_summary.error_counts |
リスト |
これにより、エラー メッセージのリストと、同じエラー メッセージで失敗したレポートの数が返されます。各エラーカウントには、カテゴリ、error_count、description が含まれます。 |
result_info.error_summary.error_messages |
リスト | これにより、処理に失敗したレポートのエラー メッセージのリストが返されます。 |
job_parameters |
Dictionary |
これには、createJob リクエストで指定されたジョブ パラメータが含まれます。`output_domain_blob_prefix` や `output_domain_bucket_name` などの関連プロパティ。 |
job_parameters.attribution_report_to |
文字列 |
reporting_site とは相互に排他的です。これは、レポートが受信されたレポート URL またはオリジンです。オリジンは、Aggregation Service Onboarding に登録されているサイトの一部です。これは createJob リクエストで指定されます。 |
job_parameters.reporting_site |
文字列 |
attribution_report_to とは相互に排他的です。これは、レポート URL のホスト名またはレポートが受信されたオリジンです。オリジンは、Aggregation Service Onboarding に登録されているサイトの一部です。すべてのレポート オリジンがこのパラメータで指定された同じサイトに属している限り、同じリクエストで複数のレポート オリジンを含むレポートを送信できます。これは createJob リクエストで指定されます。また、ジョブの作成時に集計するレポートのみがバケットに含まれていることを確認します。ジョブ パラメータで指定されたレポートサイトと一致するレポート配信元を持つレポートが、入力データバケットに追加されると、処理されます。集計サービスは、ジョブの登録済みレポート作成元と一致するデータバケット内のレポートのみを考慮します。たとえば、登録されたオリジンが https://exampleabc.com の場合、バケットにサブドメイン(https://1.exampleabc.com など)やまったく異なるドメイン(https://3.examplexyz.com)からのレポートが含まれていても、https://exampleabc.com からのレポートのみが含まれます。 |
job_parameters.debug_privacy_epsilon |
浮動小数点、倍精度 |
省略可能フィールド。値が渡されない場合は、デフォルト値の 10 が使用されます。値は 0 ~ 64 の範囲で指定できます。この値は createJob リクエストで指定されます。 |
job_parameters.report_error_threshold_percentage |
Double |
省略可能フィールド。これは、ジョブの失敗前に失敗が許容されるレポートのしきい値の割合です。値が割り当てられていない場合は、デフォルト値の 10% が使用されます。これは createJob リクエストで指定されます。 |
job_parameters.input_report_count |
長い値 | 省略可能フィールド。このジョブの入力データとして提供されたレポートの合計数。`report_error_threshold_percentage` は、この値と組み合わせて使用され、エラーが原因で除外されるレポートの数が著しく多い場合にジョブの早期失敗をトリガーします。この設定は、`createJob` リクエストで指定します。 |
job_parameters.filtering_ids |
文字列 |
省略可能フィールド。カンマで区切られた署名なしフィルタリング ID のリスト。一致するフィルタリング ID 以外のすべての投稿がフィルタで除外されます。これは createJob リクエストで指定されます。(例: "filtering_ids":"12345,34455,12"。デフォルト値は「0」です)。 |