
Dopo aver eseguito il deployment del servizio di aggregazione, puoi utilizzare gli endpoint createJob e getJob per interagire con il servizio. Il seguente diagramma fornisce una rappresentazione visiva dell'architettura di deployment per questi due endpoint:
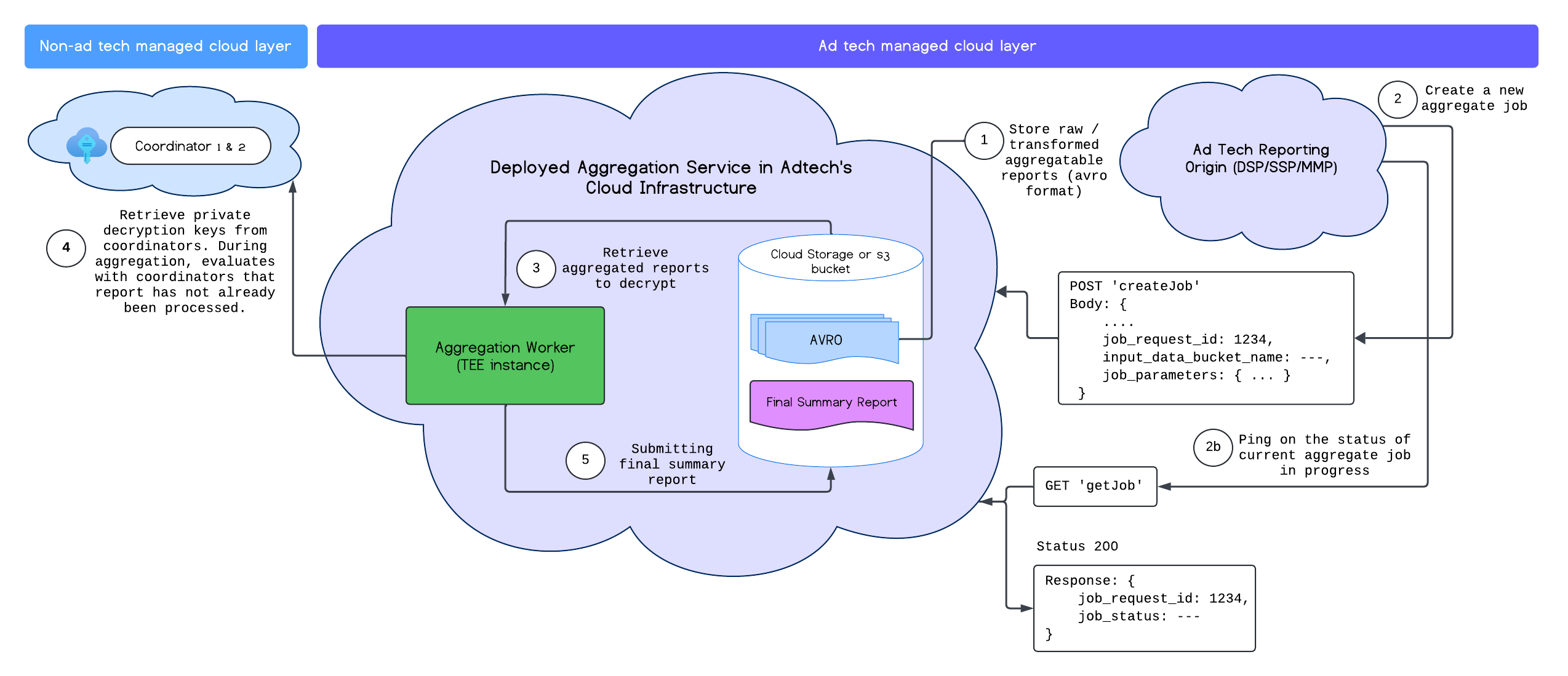
Puoi scoprire di più sugli endpoint createJob e getJob nella documentazione dell'API Aggregation Service.
Crea un job
Per creare un job, invia una richiesta POST all'endpoint createJob.
bash
POST https://<api-gateway>/stage/v1alpha/createJob
-+
Un esempio di corpo della richiesta per createJob:
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<host name of reporting origin>"
}
}
La creazione di un job riuscita genera un codice di stato HTTP 202.
Tieni presente che reporting_site e attribution_report_to si escludono a vicenda ed è necessario solo uno dei due.
Puoi anche richiedere un job di debug aggiungendo debug_run a job_parameters.
Per ulteriori informazioni sulla modalità di debug, consulta la nostra documentazione sull'esecuzione del debug dell'aggregazione.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>"
"debug_run": "true"
}
}
Campi della richiesta
| Parametro | Tipo | Descrizione |
|---|---|---|
job_request_id |
Stringa |
Si tratta di un identificatore univoco generato dalla tecnologia pubblicitaria che deve essere composto da lettere ASCII e contenere al massimo 128 caratteri. Identifica la richiesta del job batch e prende tutti i report AVRO aggregabili specificati in `input_data_blob_prefix` dal bucket di input specificato in `input_data_bucket_name` ospitato nello spazio di archiviazione cloud della tecnologia pubblicitaria.
Caratteri: `a-z, A-Z, 0-9, !"#$%&'()*+,-./:;<=>?@[\]^_`{}~
|
input_data_blob_prefix |
Stringa |
Questo è il percorso del bucket. Per i singoli file, puoi utilizzare il percorso. Per più file, puoi utilizzare il prefisso nel percorso.
Esempio: la cartella/il file raccoglie tutti i report da folder/file1.avro, folder/file/file1.avro e folder/file1/test/file2.avro. |
input_data_bucket_name |
Stringa | Questo è il bucket di archiviazione per i dati di input o i report aggregabili. Si trova nello spazio di archiviazione sul cloud della tecnologia pubblicitaria. |
output_data_blob_prefix |
Stringa | Questo è il percorso di output nel bucket. È supportato un solo file di output. |
output_data_bucket_name |
Stringa |
Questo è il bucket di archiviazione in cui viene inviato output_data. Esiste nello spazio di archiviazione sul cloud della tecnologia pubblicitaria.
|
job_parameters |
Dizionario |
Campo obbligatorio. Questo campo contiene i diversi campi, ad esempio:
|
job_parameters.output_domain_blob_prefix |
Stringa |
Analogamente a input_data_blob_prefix, questo è il percorso in output_domain_bucket_name in cui si trova l'output AVRO del dominio. Per più file, puoi utilizzare il prefisso nel percorso. Una volta completato il batch, il servizio di aggregazione crea il report riepilogativo e lo inserisce nel bucket di output output_data_bucket_name con il nome output_data_blob_prefix.
|
job_parameters.output_domain_bucket_name |
Stringa | Questo è il bucket di archiviazione per il file AVRO del dominio di output. Si trova nello spazio di archiviazione sul cloud della tecnologia pubblicitaria. |
job_parameters.attribution_report_to |
Stringa | Questo valore è reciprocamente esclusivo di `reporting_site`. Si tratta dell'URL o dell'origine di reporting in cui è stato ricevuto il report. L'origine del sito è registrata nell'onboarding del servizio di aggregazione. |
job_parameters.reporting_site |
Stringa |
Si esclude a vicenda con attribution_report_to. Questo è l'hostname dell'URL di segnalazione o dell'origine di segnalazione in cui è stata ricevuta la segnalazione. L'origine del sito è registrata nell'onboarding del servizio di aggregazione.
Nota: puoi inviare più report con origini diverse in una singola richiesta, a condizione che tutte le origini appartengano allo stesso sito di reporting specificato in questo parametro.
|
job_parameters.debug_privacy_epsilon |
Virgola mobile, doppia precisione | Campo facoltativo. Se non viene passato alcun valore, il valore predefinito è 10. È possibile utilizzare un valore compreso tra 0 e 64. |
job_parameters.report_error_threshold_percentage |
Doppio | Campo facoltativo. Questa è la percentuale massima di report non riusciti consentita prima che il job non vada a buon fine. Se lasciato vuoto, il valore predefinito è 10%. |
job_parameters.input_report_count |
valore lungo |
Campo facoltativo. Il numero totale di report forniti come dati di input per il job. Questo valore, insieme a report_error_threshold_percentage, consente di rilevare errori nei job in anticipo quando i report vengono esclusi a causa di errori.
|
job_parameters.filtering_ids |
Stringa |
Campo facoltativo. Un elenco di ID di filtraggio non firmati separati da una virgola. Tutti i contributi diversi dall'ID filtro corrispondente vengono filtrati. (ad es."filtering_ids": "12345,34455,12"). Il valore predefinito è 0.
|
job_parameters.debug_run |
Booleano |
Campo facoltativo. Quando esegui un'esecuzione di debug, vengono aggiunti report di riepilogo di debug con e senza rumore e annotazioni per indicare quali chiavi sono presenti nell'input del dominio e/o nei report. Inoltre, non vengono applicati duplicati tra i batch. Tieni presente che l'esecuzione di debug prende in considerazione solo i report con il flag "debug_mode": "enabled". A partire dalla versione 2.10.0, le esecuzioni di debug non consumano il budget per la privacy.
|
Recupero di un job
Quando una tecnologia pubblicitaria vuole conoscere lo stato di un batch richiesto, può chiamare l'endpoint getJob. L'endpoint getJob viene chiamato utilizzando una richiesta HTTPS GET insieme al parametro job_request_id.
GET https://<api-gateway>/stage/v1alpha/getJob?job_request_id=<job_request_id>
Dovresti ricevere una risposta che restituisce lo stato del job insieme a eventuali messaggi di errore:
{
"job_status": "FINISHED",
"request_received_at": "2023-07-17T19:15:13.926530Z",
"request_updated_at": "2023-07-17T19:15:28.614942839Z",
"job_request_id": "PSD_0003",
"input_data_blob_prefix": "reports/output_reports_2023-07-17T19:11:27.315Z.avro",
"input_data_bucket_name": "ags-report-bucket",
"output_data_blob_prefix": "summary/summary.avro",
"output_data_bucket_name": "ags-report-bucket",
"postback_URL": "",
"result_info": {
"return_code": "SUCCESS",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-07-17T19:15:28.607802354Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "ags-report-bucket",
"output_domain_blob_prefix": "output_domain/output_domain.avro",
"attribution_report_to": "https://privacy-sandcastle-dev-dsp.web.app"
},
"request_processing_started_at": "2023-07-17T19:15:21.583759622Z"
}
Campi di risposta
| Parametro | Tipo | Descrizione |
|---|---|---|
job_request_id |
Stringa |
Si tratta dell'ID univoco del job/batch specificato nella richiesta createJob.
|
job_status |
Stringa | Questo è lo stato della richiesta di job. |
request_received_at |
Stringa | L'ora in cui è stata ricevuta la richiesta. |
request_updated_at |
Stringa | L'ora dell'ultimo aggiornamento del job. |
input_data_blob_prefix |
Stringa |
Questo è il prefisso dei dati di input impostato su createJob.
|
input_data_bucket_name |
Stringa |
Questo è il bucket di dati di input della tecnologia pubblicitaria in cui sono archiviati i report aggregabili. Questo campo è impostato su createJob.
|
output_data_blob_prefix |
Stringa |
Questo è il prefisso dei dati di output impostato su createJob.
|
output_data_bucket_name |
Stringa |
Questo è il bucket di dati di output della tecnologia pubblicitaria in cui vengono archiviati i report di riepilogo generati. Questo campo è impostato su createJob.
|
request_processing_started_at |
Stringa |
L'ora in cui è iniziato l'ultimo tentativo di elaborazione. Questo esclude il tempo di attesa nella coda dei job.
(Tempo di elaborazione totale = request_updated_at - request_processing_started_at)
|
result_info |
Dizionario |
Questo è il risultato della richiesta createJob e consiste in tutte le informazioni disponibili.
Vengono visualizzati i valori return_code, return_message, finished_at e error_summary.
|
result_info.return_code |
Stringa | Il codice restituito del risultato del job. Queste informazioni sono necessarie per la risoluzione dei problemi in caso di problemi nel servizio di aggregazione. |
result_info.return_message |
Stringa | Il messaggio di esito positivo o negativo restituito come risultato del job. Queste informazioni sono necessarie anche per la risoluzione dei problemi del servizio di aggregazione. |
result_info.error_summary |
Dizionario | Gli errori restituiti dal job. Contiene il numero di report e il tipo di errori riscontrati. |
result_info.finished_at |
Timestamp | Il timestamp che indica il completamento del job. |
result_info.error_summary.error_counts |
Elenco |
Viene restituito un elenco dei messaggi di errore insieme al numero di report per i quali l'operazione non è riuscita con lo stesso messaggio di errore. Ogni conteggio degli errori contiene una categoria, error_count e description.
|
result_info.error_summary.error_messages |
Elenco | Viene restituito un elenco dei messaggi di errore dei report la cui elaborazione non è riuscita. |
job_parameters |
Dizionario |
Contiene i parametri del job forniti nella richiesta createJob. Proprietà pertinenti come `output_domain_blob_prefix` e `output_domain_bucket_name`.
|
job_parameters.attribution_report_to |
Stringa |
Si esclude a vicenda con reporting_site. Questo è l'URL di segnalazione o l'origine da cui è stata ricevuta la segnalazione. L'origine fa parte del sito registrato nell'onboarding del servizio di aggregazione. Questo valore è specificato nella richiesta createJob.
|
job_parameters.reporting_site |
Stringa |
Si esclude a vicenda con attribution_report_to. Questo è il nome host dell'URL di segnalazione o l'origine da cui è stata ricevuta la segnalazione. L'origine fa parte del sito registrato nell'onboarding del servizio di aggregazione. Tieni presente che puoi inviare report con più origini di reporting nella stessa richiesta, a condizione che tutte le origini di reporting appartengano allo stesso sito menzionato in questo parametro. Questo valore è specificato nella richiesta createJob. Inoltre, verifica che il bucket contenga solo i report che vuoi aggregare al momento della creazione del job. Vengono elaborati tutti i report aggiunti al bucket dei dati di input con origini dei report corrispondenti al sito di report specificato nel parametro del job.
Il servizio di aggregazione prende in considerazione solo i report all'interno del bucket di dati che corrispondono all'origine di generazione dei report registrata del job. Ad esempio, se l'origine registrata è https://exampleabc.com, vengono inclusi solo i report provenienti da https://exampleabc.com, anche se il bucket contiene report provenienti da sottodomini (https://1.exampleabc.com e così via) o da domini completamente diversi (https://3.examplexyz.com).
|
job_parameters.debug_privacy_epsilon |
Virgola mobile, doppia precisione |
Campo facoltativo. Se non viene passato alcun valore, viene utilizzato il valore predefinito 10. I valori possono essere compresi tra 0 e 64. Questo valore è specificato nella richiesta createJob.
|
job_parameters.report_error_threshold_percentage |
Doppio |
Campo facoltativo. Questa è la percentuale di soglia di report che possono non riuscire prima dell'errore del job. Se non viene assegnato alcun valore, viene utilizzato il valore predefinito del 10%. Questo valore è specificato nella richiesta createJob.
|
job_parameters.input_report_count |
Valore lungo | Campo facoltativo. Il numero totale di report forniti come dati di input per questo job. `report_error_threshold_percentage`, combinato con questo valore, attiva l'interruzione anticipata del job se un numero significativo di report viene escluso a causa di errori. Questa impostazione è specificata nella richiesta `createJob`. |
job_parameters.filtering_ids |
Stringa |
Campo facoltativo. Un elenco di ID di filtro non firmati separati da virgole. Tutti i contributi diversi dall'ID filtro corrispondente vengono filtrati. Questo valore è specificato nella richiesta createJob.
(ad es. "filtering_ids":"12345,34455,12". Il valore predefinito è "0".)
|