
אחרי שמבצעים פריסה מוצלחת של שירות הצבירה, אפשר להשתמש בנקודות הקצה createJob ו-getJob כדי ליצור אינטראקציה עם השירות. התרשים הבא מציג ייצוג חזותי של ארכיטקטורת הפריסה של שתי נקודות הקצה האלה:
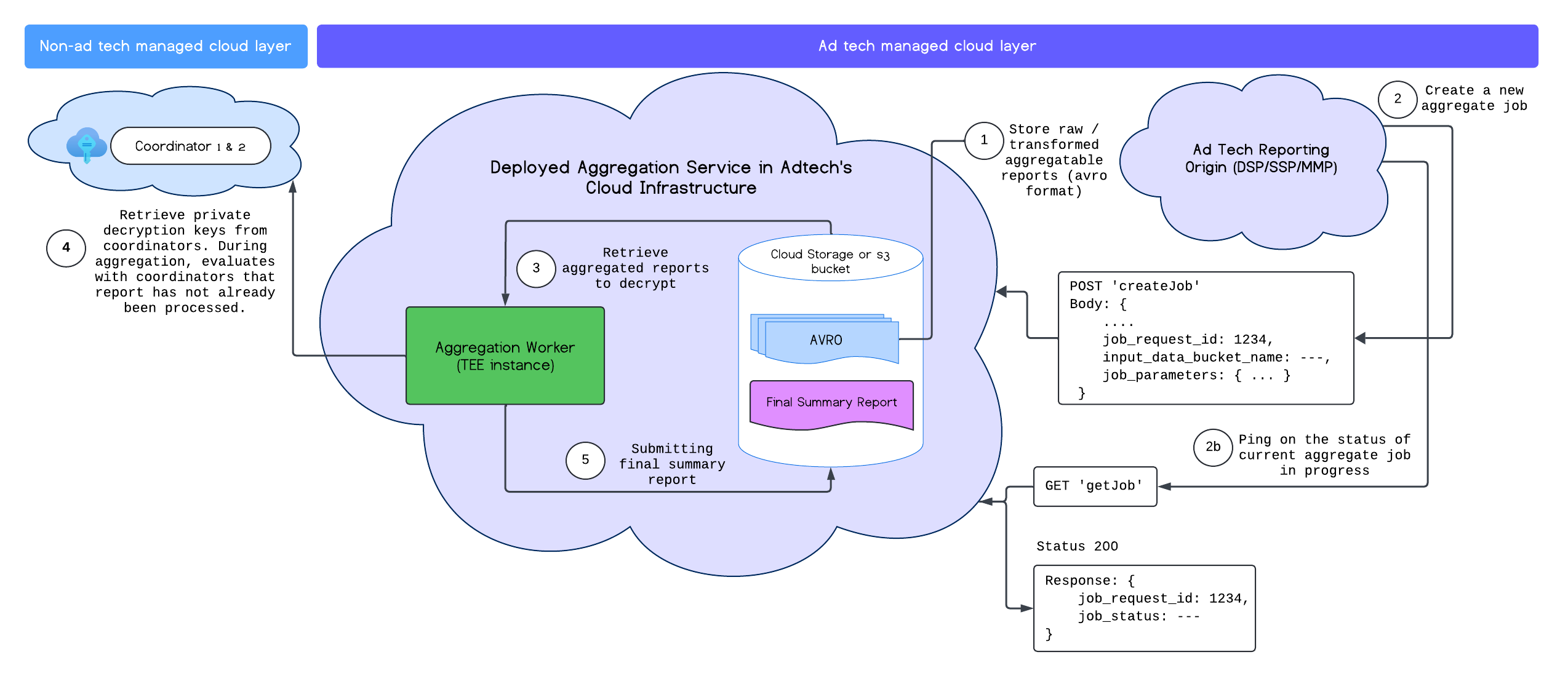
מידע נוסף על נקודות הקצה createJob ו-getJob זמין במסמכים של Aggregation Service API.
יצירת משרה
כדי ליצור משימה, שולחים בקשת POST לנקודת הקצה createJob.
bash
POST https://<api-gateway>/stage/v1alpha/createJob
-+
דוגמה לגוף הבקשה של createJob:
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>",
"reporting_site": "<host name of reporting origin>"
}
}
אם יצירת העבודה תצליח, יוחזר קוד סטטוס HTTP 202.
הערה: reporting_site ו-attribution_report_to הם מאפיינים שאי אפשר להשתמש בהם בו-זמנית, ונדרש רק אחד מהם.
אפשר גם להוסיף debug_run אל job_parameters כדי לבקש עבודת ניפוי באגים.
מידע נוסף על מצב ניפוי הבאגים זמין במאמר בנושא הרצת ניפוי באגים של צבירה.
{
"job_request_id": "<job_request_id>",
"input_data_blob_prefix": "<report_folder>/<report_name>.avro",
"input_data_bucket_name": "<input_bucket_name>",
"output_data_blob_prefix": "<output_folder>/<summary_report_prefix>",
"output_data_bucket_name": "<output_bucket_name>",
"job_parameters": {
"output_domain_blob_prefix": "<output_domain_folder>/<output_domain>.avro",
"output_domain_bucket_name": "<output_domain_bucket_name>",
"attribution_report_to": "<reporting origin of report>"
"debug_run": "true"
}
}
שדות של בקשה
| פרמטר | סוג | תיאור |
|---|---|---|
job_request_id |
מחרוזת |
זהו מזהה ייחודי שנוצר על ידי טכנולוגיית פרסום, והוא צריך להיות אותיות ASCII באורך של עד 128 תווים. הפרמטר הזה מזהה את בקשת העבודה של האצווה, ומשתמש בכל דוחות ה-AVRO שניתנים לצבירה ומצוינים בפרמטר input_data_blob_prefix, מתוך קטגוריית הקלט שצוינה בפרמטר input_data_bucket_name, שמתארחת באחסון הענן של טכנולוגיית הפרסום.
תווים: `a-z, A-Z, 0-9, !"#$%&'()*+,-./:;<=>?@[\]^_`{}~
|
input_data_blob_prefix |
מחרוזת |
זוהי נתיב הדלי. אם מדובר בקובץ יחיד, אפשר להשתמש בנתיב. אם יש כמה קבצים, אפשר להשתמש בקידומת בנתיב.
דוגמה: התיקייה או הקובץ אוספים את כל הדוחות מהתיקייה או הקובץ folder/file1.avro, מהתיקייה או הקובץ folder/file/file1.avro ומהתיקייה או הקובץ folder/file1/test/file2.avro. |
input_data_bucket_name |
מחרוזת | זו קטגוריית האחסון של נתוני הקלט או של הדוחות מהנתונים הצבורים. הנתונים האלה נמצאים באחסון בענן של טכנולוגיית הפרסום. |
output_data_blob_prefix |
מחרוזת | זהו נתיב הפלט בדלי. יש תמיכה בקובץ פלט אחד. |
output_data_bucket_name |
מחרוזת |
זוהי קטגוריית האחסון שאליה נשלח output_data. הקובץ הזה נמצא באחסון הענן של טכנולוגיית הפרסום.
|
job_parameters |
מילון |
שדה חובה השדה הזה מכיל את השדות השונים, כמו:
|
job_parameters.output_domain_blob_prefix |
מחרוזת |
בדומה ל-input_data_blob_prefix, זהו הנתיב ב-output_domain_bucket_name שבו נמצא קובץ ה-AVRO של דומיין הפלט. אם יש כמה קבצים, אפשר להשתמש בקידומת בנתיב. אחרי ש-Aggregation Service מסיים את העיבוד של החבילה, נוצר דוח הסיכום והוא ממוקם בדלי הפלט output_data_bucket_name עם השם output_data_blob_prefix.
|
job_parameters.output_domain_bucket_name |
מחרוזת | זוהי קטגוריית האחסון של קובץ ה-AVRO של פלט הדומיין. הנתונים האלה נמצאים באחסון בענן של טכנולוגיית הפרסום. |
job_parameters.attribution_report_to |
מחרוזת | הערך הזה לא יכול להיות זהה לערך של `reporting_site`. זו כתובת ה-URL או המקור של הדיווח שבהם התקבל הדוח. מקור האתר רשום ב-Aggregation Service Onboarding. |
job_parameters.reporting_site |
מחרוזת |
בלעדי ל-attribution_report_to. זהו שם המארח של כתובת ה-URL של הדיווח או של מקור הדיווח שבו התקבל הדוח. מקור האתר רשום ב-Aggregation Service Onboarding.
הערה: אפשר לשלוח כמה דוחות עם מקורות שונים בבקשה אחת, בתנאי שכל המקורות שייכים לאותו אתר דיווח שצוין בפרמטר הזה.
|
job_parameters.debug_privacy_epsilon |
נקודה צפה, Double | השדה הזה אופציונלי. אם לא מועבר ערך, ערך ברירת המחדל הוא 10. אפשר להשתמש בערך מ-0 עד 64. |
job_parameters.report_error_threshold_percentage |
כפול | השדה הזה אופציונלי. זהו אחוז הדוחות הכושלים המקסימלי שמותר לפני שהעבודה נכשלת. אם לא מציינים ערך, ערך ברירת המחדל הוא 10%. |
job_parameters.input_report_count |
ערך long |
השדה הזה אופציונלי. המספר הכולל של הדוחות שסופקו כנתוני קלט לעבודה. הערך הזה, בשילוב עם report_error_threshold_percentage מאפשר לזהות מוקדם יותר כשלים בעבודות כשדוחות מוחרגים בגלל שגיאות.
|
job_parameters.filtering_ids |
מחרוזת |
השדה הזה אופציונלי. רשימה של מזהי סינון לא חתומים, מופרדים בפסיקים. כל התוצאות שאין להן מזהה סינון תואם יסוננו. (לדוגמה,"filtering_ids": "12345,34455,12"). ערך ברירת המחדל הוא 0.
|
job_parameters.debug_run |
בוליאני |
השדה הזה אופציונלי. כשמריצים ניפוי באגים, מתווספים סיכומי ניפוי באגים עם רעשי רקע וסיכומי ניפוי באגים ללא רעשי רקע, וגם הערות שמציינות אילו מפתחות קיימים בקלט של הדומיין או בדוחות. בנוסף, לא נאכפות כפילויות בין קבוצות. שימו לב: בהרצת הניפוי באגים נלקחים בחשבון רק דוחות עם הדגל "debug_mode": "enabled". החל מגרסה 2.10.0, הפעלות של ניפוי באגים לא צורכות את תקציב הפרטיות.
|
חיפוש עבודה
כשחברה שמספקת טכנולוגיות פרסום רוצה לדעת את הסטטוס של קבוצת בקשות, היא יכולה להתקשר לנקודת הקצה getJob. נקודת הקצה getJob נקראת באמצעות בקשת HTTPS GET יחד עם הפרמטר job_request_id.
GET https://<api-gateway>/stage/v1alpha/getJob?job_request_id=<job_request_id>
אמורה להתקבל תגובה עם סטטוס העבודה והודעות שגיאה (אם יש):
{
"job_status": "FINISHED",
"request_received_at": "2023-07-17T19:15:13.926530Z",
"request_updated_at": "2023-07-17T19:15:28.614942839Z",
"job_request_id": "PSD_0003",
"input_data_blob_prefix": "reports/output_reports_2023-07-17T19:11:27.315Z.avro",
"input_data_bucket_name": "ags-report-bucket",
"output_data_blob_prefix": "summary/summary.avro",
"output_data_bucket_name": "ags-report-bucket",
"postback_URL": "",
"result_info": {
"return_code": "SUCCESS",
"return_message": "Aggregation job successfully processed",
"error_summary": {
"error_counts": [],
"error_messages": []
},
"finished_at": "2023-07-17T19:15:28.607802354Z"
},
"job_parameters": {
"debug_run": "true",
"output_domain_bucket_name": "ags-report-bucket",
"output_domain_blob_prefix": "output_domain/output_domain.avro",
"attribution_report_to": "https://privacy-sandcastle-dev-dsp.web.app"
},
"request_processing_started_at": "2023-07-17T19:15:21.583759622Z"
}
שדות תשובה
| פרמטר | סוג | תיאור |
|---|---|---|
job_request_id |
מחרוזת |
זהו המזהה הייחודי של העבודה או של קבוצת העבודות שצוין בבקשת createJob.
|
job_status |
מחרוזת | זהו הסטטוס של בקשת העבודה. |
request_received_at |
מחרוזת | השעה שבה הבקשה התקבלה. |
request_updated_at |
מחרוזת | המועד האחרון שבו העבודה עודכנה. |
input_data_blob_prefix |
מחרוזת |
זוהי הקידומת של נתוני הקלט שהוגדרה בשעה createJob.
|
input_data_bucket_name |
מחרוזת |
זו קטגוריית נתוני הקלט של טכנולוגיית הפרסום שבה מאוחסנים הדוחות מהנתונים הצבורים. השדה הזה מוגדר ל-createJob.
|
output_data_blob_prefix |
מחרוזת |
זוהי הקידומת של נתוני הפלט שהוגדרה בשעה createJob.
|
output_data_bucket_name |
מחרוזת |
זו קטגוריית נתוני הפלט של ספק טכנולוגיית הפרסום שבה נשמרים דוחות הסיכום שנוצרו. השדה הזה מוגדר ל-createJob.
|
request_processing_started_at |
מחרוזת |
הזמן שבו התחיל ניסיון העיבוד האחרון. הזמן הזה לא כולל את ההמתנה בתור העבודות.
(זמן העיבוד הכולל = request_updated_at – request_processing_started_at)
|
result_info |
מילון |
זו התוצאה של בקשת createJob והיא כוללת את כל המידע שזמין.
הערכים של return_code, return_message, finished_at ו-error_summary מוצגים.
|
result_info.return_code |
מחרוזת | קוד ההחזרה של תוצאת העבודה. המידע הזה נדרש לפתרון בעיות אם יש בעיה בשירות Aggregation Service. |
result_info.return_message |
מחרוזת | הודעת ההצלחה או הכישלון שהוחזרה כתוצאה מהעבודה. המידע הזה נדרש גם לפתרון בעיות בשירות הצבירה. |
result_info.error_summary |
מילון | השגיאות שמוחזרות מהעבודה. הדוח הזה כולל את מספר הדוחות ואת סוגי השגיאות שהכלי נתקל בהן. |
result_info.finished_at |
חותמת זמן | חותמת הזמן שמציינת את סיום העבודה. |
result_info.error_summary.error_counts |
רשימה |
הפונקציה מחזירה רשימה של הודעות השגיאה, לצד מספר הדוחות שנכשלו עם אותה הודעת שגיאה. כל ספירת שגיאות מכילה קטגוריה, error_count ו-description.
|
result_info.error_summary.error_messages |
רשימה | הפעולה הזו מחזירה רשימה של הודעות השגיאה מדוחות שלא הצליחו לעבור עיבוד. |
job_parameters |
מילון |
הוא מכיל את פרמטרים של העבודה שסופקו בבקשה createJob. מאפיינים רלוונטיים כמו `output_domain_blob_prefix` ו-`output_domain_bucket_name`.
|
job_parameters.attribution_report_to |
מחרוזת |
בלעדי ל-reporting_site. זו כתובת ה-URL של הדוח או המקור שממנו הדוח התקבל. המקור הוא חלק מהאתר שרשום ב-Aggregation Service Onboarding. הפרמטר הזה מצוין בבקשת createJob.
|
job_parameters.reporting_site |
מחרוזת |
בלעדי ל-attribution_report_to. זהו שם המארח של כתובת ה-URL של הדיווח או המקור שממנו התקבל הדוח. המקור הוא חלק מהאתר שרשום ב-Aggregation Service Onboarding. שימו לב: אפשר לשלוח דוחות עם כמה מקורות דיווח באותה בקשה, בתנאי שכל מקורות הדיווח שייכים לאותו אתר שמופיע בפרמטר הזה. הפרמטר הזה מצוין בבקשת createJob. בנוסף, צריך לוודא שבקטגוריה יש רק את הדוחות שרוצים לצבור בזמן יצירת המשימה. כל הדוחות שנוספו לקטגוריית המקור של נתוני הקלט עם מקורות דיווח שתואמים לאתר הדיווח שצוין בפרמטר המשימה יעברו עיבוד.
Aggregation Service מתייחס רק לדוחות שנמצאים ב-data bucket ומתאימים למקור הדיווח הרשום של העבודה. לדוגמה, אם המקור הרשום הוא https://exampleabc.com, רק דוחות מ-https://exampleabc.com ייכללו, גם אם המאגר מכיל דוחות מתת-דומיינים (https://1.exampleabc.com וכו') או מדומיינים שונים לחלוטין (https://3.examplexyz.com).
|
job_parameters.debug_privacy_epsilon |
נקודה צפה, Double |
השדה הזה אופציונלי. אם לא מועבר ערך, המערכת משתמשת בערך ברירת המחדל 10. הערכים יכולים להיות בין 0 ל-64. הערך הזה מצוין בבקשת createJob.
|
job_parameters.report_error_threshold_percentage |
כפול |
השדה הזה אופציונלי. זהו אחוז הסף של דוחות שיכולים להיכשל לפני שהעבודה נכשלת. אם לא מוקצה ערך, המערכת תשתמש בערך ברירת המחדל של 10%. הפרמטר הזה מצוין בבקשת createJob.
|
job_parameters.input_report_count |
ערך Long | השדה הזה אופציונלי. המספר הכולל של הדוחות שסופקו כנתוני קלט לעבודה הזו. הערך הזה, בשילוב עם הערך של `report_error_threshold_percentage`, גורם לכך שהעבודה תיכשל מוקדם אם מספר משמעותי של דוחות לא נכללים בגלל שגיאות. ההגדרה הזו מצוינת בבקשה `createJob`. |
job_parameters.filtering_ids |
מחרוזת |
השדה הזה אופציונלי. רשימה של מזהי סינון לא חתומים, מופרדים בפסיקים. כל התוצאות שאין להן מזהה סינון תואם יסוננו. הפרמטר הזה מצוין בבקשת createJob.
(לדוגמה, "filtering_ids":"12345,34455,12". ערך ברירת המחדל הוא 0.)
|