
Der Aggregationsdienst generiert Zusammenfassungsberichte mit detaillierten Conversion-Daten und Reichweitenmessungen aus aggregierbaren Rohberichten. Um Nutzerdaten privat und sicher zu halten, verwendet der Aggregation Service ein Framework, das Differential Privacy (DP) unterstützt, um die Menge an Informationen, die in diesen Berichten über einzelne Nutzer offengelegt werden, zu quantifizieren und zu begrenzen.
In diesem Leitfaden werden Tools und Strategien zum Erstellen aggregierbarer Berichte beschrieben, mit denen Daten einzelner Nutzer geschützt werden:
- Zusammenfassungsberichte mit zusätzlichem Rauschen erstellen
- Budget für Beiträge festlegen
- Strategien für das Batching von Berichten
- Vorab deklarierte Aggregationsschlüssel verwenden
Zusammenfassende Berichte mit zusätzlichem Rauschen
Wenn Sie aggregierbare Berichte in Batches zusammenfassen, erstellt der Aggregationsdienst einen Zusammenfassungsbericht. Dieser Übersichtsbericht ist eine Zusammenfassung aller Beiträge aller vordefinierten Domainschlüssel mit zusätzlichem statistischen Rauschen.
Das den Berichten hinzugefügte Rauschen hängt nicht von der Anzahl der zusammengefassten Berichte, einzelnen Berichtswerten oder zusammengefassten Berichtswerten ab. Der Rauschenswert wird aus einer diskreten Version der Laplace-Verteilung gezogen und an das vom Client erzwungene Beitragsbudget (L1-Sensitivität) angepasst, das von der entsprechenden Measurement API und dem Datenschutzparameter epsilon abhängt.
Weitere Informationen zu Rauschen und seinen Auswirkungen auf Berichtsdaten
Budget für Beiträge
Um die Sensibilität eines Zusammenfassungsberichts zu steuern, ist die Anzahl der in einem Aufruf übergebenen Beiträge an ein bestimmtes Beitragslimit gebunden, das auch als Beitragsbudget bezeichnet wird. Das Beitragsbudget variiert je nachdem, ob Sie die Attribution Reporting API oder die Private Aggregation API verwenden.
Weitere Informationen zum Festlegen von Kontingenten für Beiträge für die einzelnen APIs finden Sie in den folgenden Abschnitten der API-Dokumentation:
- Beitragsobergrenzen und Budgetierung für die Attribution Reporting API
- Beitragslimits für die Private Aggregation API
- Beitragsobergrenzen und Budgetierung der Private Aggregation API
Strategien für das Batching von Berichten
Wenn Sie aggregierbare Berichte in Batches verarbeiten, ist es wichtig, die Batching-Strategien so zu optimieren, dass die Datenschutzlimits nicht überschritten werden. Zwei wichtige Konzepte für das korrekte Erstellen von Batchberichten sind die Regel „Keine Duplikate“ und das Konzept der disjunkten Batches.
Regel „Keine Duplikate“
Der Aggregationsdienst erzwingt die Regel „Keine Duplikate“. Gemäß dieser Regel darf ein aggregierbarer Bericht, der durch report_id eindeutig identifiziert wird, nur einmal in einem einzelnen Batch vorkommen. Wenn ein aggregierbarer Bericht mehrmals pro Batch vorkommt, wird der erste Bericht in die Aggregation einbezogen. Nachfolgende Berichte mit demselben report_id werden verworfen und der Batch wird erfolgreich abgeschlossen.
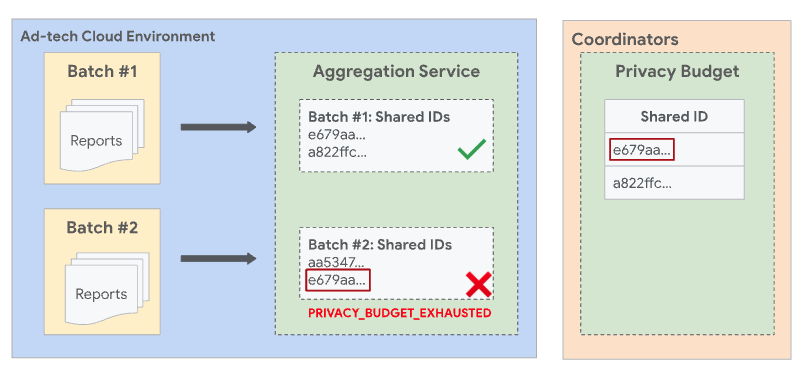
Außerdem darf dieselbe gemeinsame ID nicht in mehreren Batches vorkommen. Wenn eine gemeinsame ID bereits in einem vorherigen erfolgreichen Batch enthalten war, schlägt ein späterer Batch mit derselben gemeinsamen ID fehl.
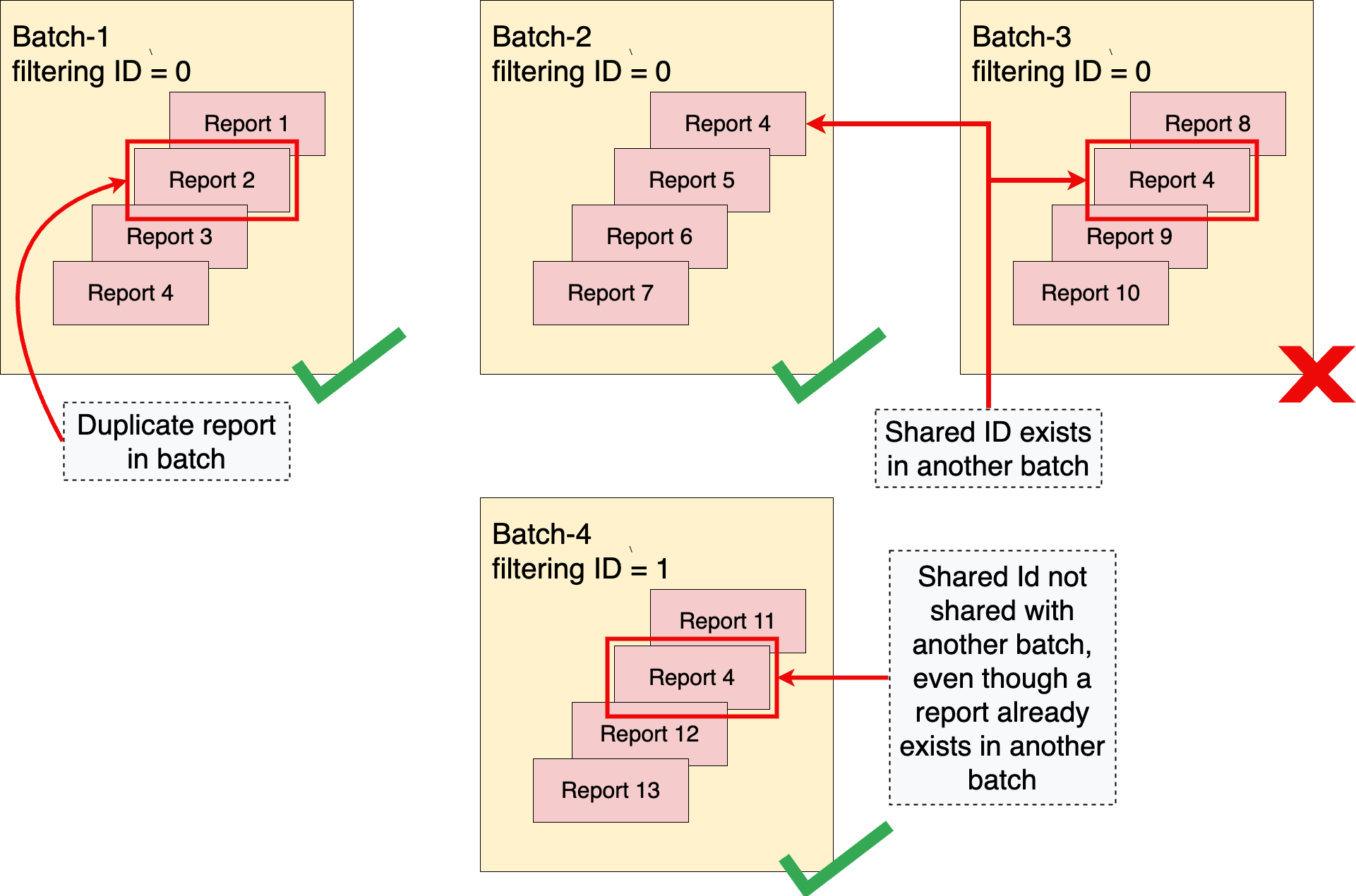
Ohne die Regel „Keine Duplikate“ könnte ein Angreifer Einblick in den Inhalt eines bestimmten Batches erhalten, indem er den Inhalt der Batches manipuliert, z. B. durch das Einfügen von Duplikaten eines Berichts in einen einzelnen oder mehrere Batches.
Weitere Informationen zum Erzwingen der Regel „Keine Duplikate“ in einem Batch von Berichten oder über mehrere Batches hinweg finden Sie unter Doppelte Berichte in Batches.
Disjunkte Batches
Um Situationen zu vermeiden, in denen sich Batches überschneiden, erzwingt der Aggregationsdienst disjunkte Batches. Das bedeutet, dass zwei oder mehr Batches keine Berichte mit einer gemeinsamen gemeinsamen ID enthalten dürfen. Eine gemeinsame ID ist eine Kombination aus Daten, die aus dem Feld shared_info eines aggregierbaren Berichts erhoben werden, und der Filter-ID aus der Jobanfrage. Wenn keine Filter-ID angegeben ist, wird der Standardwert 0 verwendet.
Im folgenden Beispiel für das Feld shared_info sehen Sie die API attribution_destination (für Attribution Reporting), reporting_origin, scheduled_report_time, source_registration_time (für Attribution Reporting) und version. Diese Felder, mit Ausnahme von report_id, sowie die Filter-ID aus der Jobanfrage tragen zur gemeinsamen ID bei.
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://privacy-sandbox-demos-shop.dev",
"report_id": "5b052748-f5fb-4f14-b291-de03484ed59e",
"reporting_origin": "https://privacy-sandbox-demos-dsp.dev",
"scheduled_report_time": "1707786751",
"source_registration_time": "0",
"version": "0.1"
}
Da source_registration_time nach Tag und scheduled_report_time nach Stunde gekürzt wird, gibt es Berichte mit derselben freigegebenen ID. In diesem Beispiel haben Report1 und Report2 gemeinsame Infofelder. Beide Berichte haben dieselbe API, Version, attribution_destination, reporting_origin und source_registration_time. Da report_id nicht Teil der gemeinsamen ID ist, können Sie diesen Unterschied ignorieren.
In den folgenden Beispielen für Report1 und Report2 ist der Wert scheduled_report_time identisch.
Geteilte Informationen in Report1:
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://shop.dev",
"report_id": "5b052748-...",
"reporting_origin": "https://dsp.dev",
"scheduled_report_time": "1708376890",
"source_registration_time": "0",
"version": "0.1"
}
Informationen zu Report2:
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://shop.dev",
"report_id": "5b052748-...",
"reporting_origin": "https://dsp.dev",
"scheduled_report_time": "1708376890",
"source_registration_time": "0",
"version": "0.1"
}
Die geplanten Berichtszeiten sind „19. Februar 2024, 21:08:10“ für Report1 und „19. Februar 2024, 21:55:10“ für Report2. Da der Wert für das Feld scheduled_report_time auf die Stunde gekürzt wird, haben beide Berichte 1708376890 (der codierte Wert für „19. Februar 2024, 21:00 Uhr“) als Wert für das Feld scheduled_report_time.
Wenn alle anderen Felder und die Filter-ID gleich sind, haben beide Berichte dieselbe gemeinsame ID. Da beide Berichte dieselbe gemeinsame ID haben, müssen sie beide im selben Batch enthalten sein.
Wenn Report1 in einem zuvor erfolgreichen Batch verarbeitet wurde und Report2 in einem nachfolgenden Batch verarbeitet wird, schlägt der Batch mit Report2 mit einem PRIVACY_BUDGET_EXHAUSTED-Fehler fehl. Entfernen Sie in diesem Fall die Berichte mit der freigegebenen ID, die in vorherigen Batches erfolgreich zusammengefasst wurden, und versuchen Sie es noch einmal. Weitere Informationen zu diesem Fehler finden Sie unter Fehlercodes und Maßnahmen für den Aggregationsdienst.
Vorab deklarierte Aggregationsschlüssel
Wenn Sie einen Batch an den Aggregationsdienst senden, muss er sowohl die aggregierbaren Berichte, die vom Berichterstellungsursprung empfangen werden, als auch die Ausgabedomaindatei enthalten. Die Ausgabedomäne enthält die Schlüssel oder Buckets, die aus den aggregierbaren Berichten abgerufen werden.
Aus Datenschutzgründen wird allen Schlüsseln, die in der Ausgabedomäne vorab deklariert wurden, Rauschen hinzugefügt, auch wenn kein tatsächlicher Bericht einem bestimmten Schlüssel entspricht. Durch die Angabe der Ausgabedomäne wird ein Angriff verhindert, bei dem das Vorhandensein eines Schlüssels in der Ausgabe etwas über einen einzelnen Nutzer oder ein einzelnes Ereignis verrät. Wenn Sie beispielsweise nur einem Nutzer eine Kampagne präsentiert haben, zeigt ein Schlüssel in der Ausgabe, dass der Nutzer später eine Conversion durchgeführt hat, auch wenn Rauschen hinzugefügt wurde. Wenn Sie diese Domain zuerst angeben, können Sie sicher sein, dass nichts über die Nutzerbeiträge preisgegeben wird.
Sie können diese 128-Bit-Schlüssel entweder in der Attribution Reporting API oder in der Private Aggregation API deklarieren und damit Dimensionen codieren, die Sie erfassen möchten.
Nur vorab deklarierte Schlüssel werden für die Aggregation berücksichtigt und in den Zusammenfassungsbericht aufgenommen. Den aggregierten Werten der Gruppen im Übersichtsbericht wird statistisches Rauschen hinzugefügt. Das spiegelt sich im erstellten Übersichtsbericht wider.
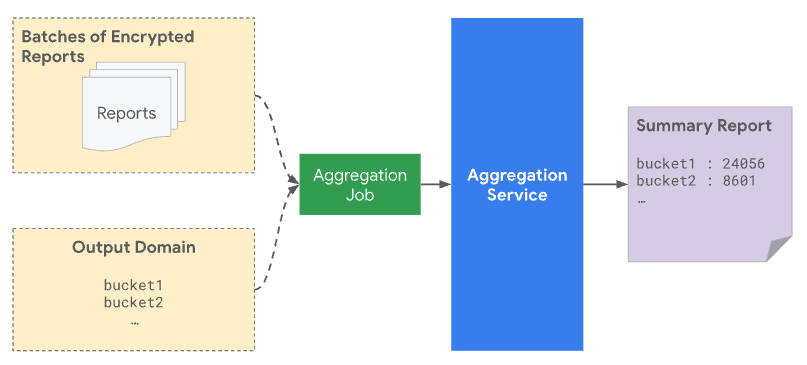
Wenn ein Aggregationsschlüssel in der Ausgabedomänendatei enthalten ist, aber nicht in einem Batchbericht, ist der endgültige Zusammenfassungsbericht wahrscheinlich ungleich null, auch wenn der aggregierte Wert null ist. Das liegt daran, dass Rauschen hinzugefügt wird, um den Datenschutz zu wahren.