
O Serviço de agregação gera relatórios de resumo com dados detalhados de conversão e medições de alcance com base em relatórios agregáveis brutos. Para manter os dados do usuário privados e seguros, o serviço de agregação usa uma estrutura que oferece suporte à privacidade diferencial (DP) para quantificar e limitar a quantidade de informações que esses relatórios revelam sobre usuários individuais.
Este guia aborda ferramentas e estratégias para criar relatórios agregáveis que ajudam a manter os dados de usuários individuais seguros:
- Criar relatórios de resumo com ruído adicionado
- Definir um orçamento de contribuição
- Estratégias para agrupamento de relatórios
- Gerenciar relatórios duplicados em lotes
- Processar relatórios com um ID compartilhado comum
- Usar chaves de agregação pré-declaradas
Relatórios de resumo com ruído adicionado
Quando você agrupa relatórios agregáveis, o serviço de agregação cria um relatório de resumo. Esse relatório é um agregado de todas as contribuições de todas as chaves de domínio predefinidas, com ruído estatístico adicionado.
O ruído adicionado aos relatórios não depende do número de relatórios agregados, dos valores de relatórios individuais ou dos valores de relatórios agregados. O ruído é extraído de uma versão discreta da distribuição de Laplace e é dimensionado para o orçamento de contribuição (sensibilidade L1) imposto pelo cliente, dependendo da API de medição correspondente e do parâmetro de privacidade epsilon.
Para saber mais sobre o ruído e as implicações dele nos dados dos relatórios, consulte Entender o ruído nos relatórios de resumo.
Orçamento de contribuição
Para controlar a sensibilidade de um relatório de resumo, o número de contribuições transmitidas em uma chamada é vinculado a um limite específico, também conhecido como orçamento de contribuição. O orçamento de contribuição varia dependendo se você está usando a API Attribution Reporting ou a API Private Aggregation.
Para saber como definir orçamentos de contribuição para cada API, consulte as seguintes seções da documentação da API:
- Limites e orçamentos de contribuição da API Attribution Reporting
- Limites de contribuição da API Private Aggregation
- Limites e orçamento de contribuição da API Private Aggregation
Estratégias para agrupar relatórios
Ao agrupar relatórios agregáveis, é importante otimizar as estratégias de agrupamento para que os limites de privacidade não sejam excedidos. Dois conceitos importantes para agrupar relatórios corretamente são a regra"sem duplicados" e a ideia de agrupamentos disjuntos.
Regra "Sem duplicatas"
O serviço de agregação aplica uma regra de "sem duplicados". Essa regra afirma que um relatório agregável, identificado exclusivamente por report_id, só pode aparecer uma vez em um único lote. Se um relatório agregável aparecer mais de uma vez por lote, o primeiro será incluído na agregação, os relatórios subsequentes com o mesmo report_id serão descartados, e o lote será concluído com sucesso.
A regra também afirma que o mesmo ID compartilhado não pode aparecer em mais de um lote. Se um ID compartilhado já tiver sido incluído em um lote anterior bem-sucedido, um lote posterior que também inclua o mesmo ID compartilhado vai falhar.
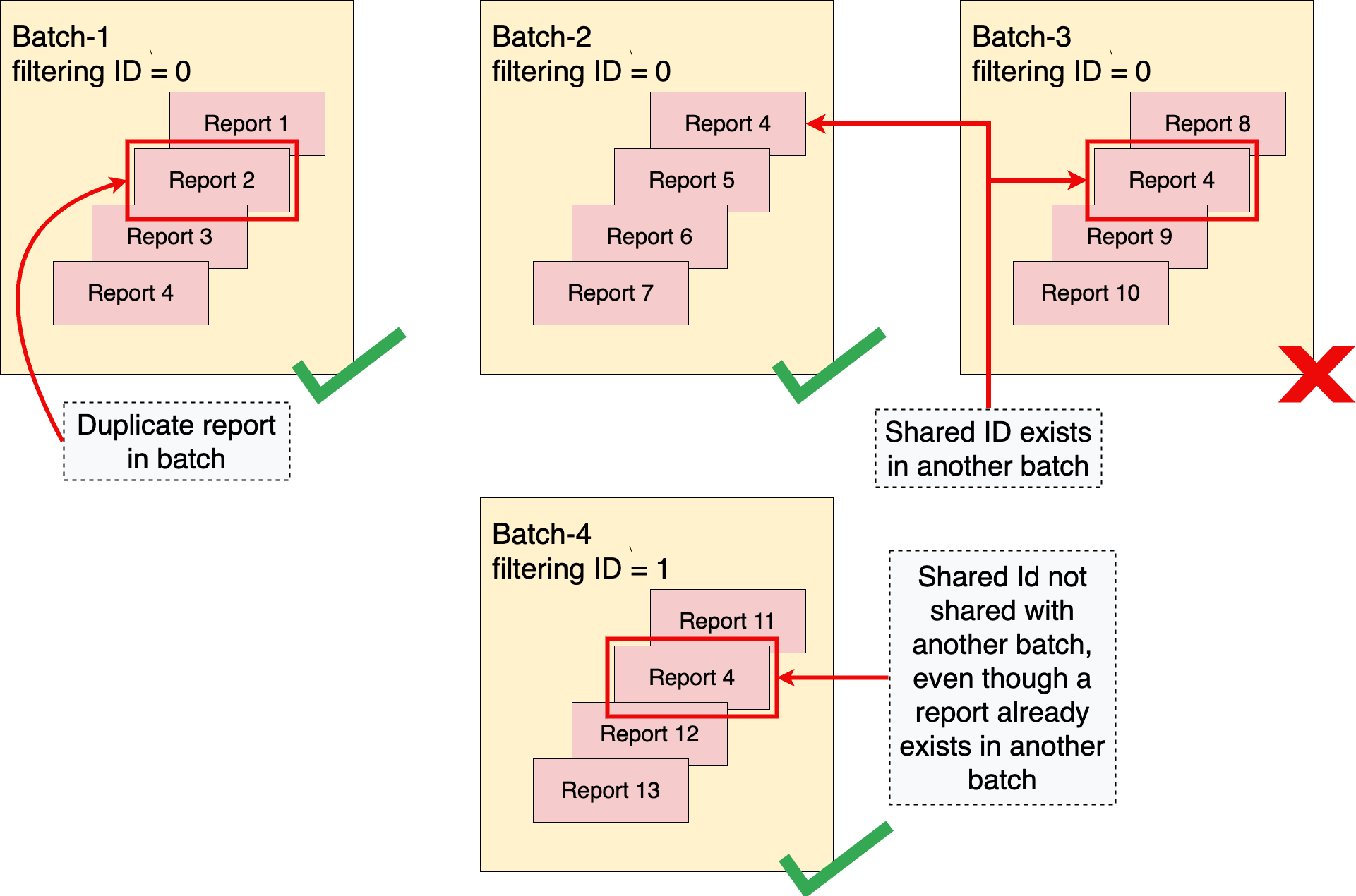
Sem a regra "sem duplicados", um invasor pode ter acesso ao conteúdo de um lote específico manipulando o conteúdo dos lotes ao incluir cópias duplicadas de um relatório em um ou vários lotes.
Para saber mais sobre como aplicar a regra "sem duplicados" em um lote de relatórios ou em vários lotes, consulte Relatórios duplicados em lotes.
Lotes separados
Para evitar situações em que há sobreposição entre lotes, o serviço de agregação impõe lotes disjuntos. Isso significa que dois ou mais lotes não podem conter relatórios que compartilham um ID compartilhado em comum. Um ID compartilhado é uma combinação de dados coletados do campo shared_info de um relatório agregável, junto com o ID de filtragem da solicitação de emprego. Se nenhum ID de filtragem for especificado, o valor padrão 0 será usado.
No exemplo de campo shared_info a seguir, você pode conferir a API, attribution_destination (para Attribution Reporting), reporting_origin, scheduled_report_time, source_registration_time (para Attribution Reporting) e version. Esses campos, exceto o report_id, junto com o ID de filtragem da solicitação de vaga, contribuem para o ID compartilhado.
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://privacy-sandbox-demos-shop.dev",
"report_id": "5b052748-f5fb-4f14-b291-de03484ed59e",
"reporting_origin": "https://privacy-sandbox-demos-dsp.dev",
"scheduled_report_time": "1707786751",
"source_registration_time": "0",
"version": "0.1"
}
Como source_registration_time é truncado por dia e scheduled_report_time é truncado por hora, há relatórios com o mesmo ID compartilhado. Neste exemplo, Relatório1 e Relatório2 têm campos de informações compartilhados. Os dois relatórios têm a mesma API, versão, attribution_destination, reporting_origin e source_registration_time. Como report_id não faz parte do ID compartilhado, você pode ignorar essa diferença.
Nos exemplos a seguir para Relatório1 e Relatório2, o valor de scheduled_report_time é o mesmo.
Informações compartilhadas do Report1:
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://shop.dev",
"report_id": "5b052748-...",
"reporting_origin": "https://dsp.dev",
"scheduled_report_time": "1708376890",
"source_registration_time": "0",
"version": "0.1"
}
Informações compartilhadas do Report2:
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://shop.dev",
"report_id": "5b052748-...",
"reporting_origin": "https://dsp.dev",
"scheduled_report_time": "1708376890",
"source_registration_time": "0",
"version": "0.1"
}
Os horários dos relatórios programados são "19 de fevereiro de 2024, 21:08:10" para Relatório1 e "19 de fevereiro de 2024, 21:55:10" para Relatório2. Como o valor do campo scheduled_report_time é truncado para a hora, os dois relatórios têm 1708376890 (o valor codificado de "19 de fevereiro de 2024, 21h") como o valor do campo scheduled_report_time.
Com todos os outros campos e o ID de filtragem iguais, os dois relatórios têm o mesmo ID compartilhado. Como os dois relatórios têm o mesmo ID compartilhado, eles precisam ser incluídos no mesmo lote.
Se Report1 foi agrupado em um lote anterior bem-sucedido e Report2 for processado em um lote subsequente, o lote com Report2 vai falhar com um erro PRIVACY_BUDGET_EXHAUSTED. Se isso acontecer, remova os relatórios com o ID compartilhado que foram agrupados em lotes anteriores e tente de novo. Para mais informações sobre esse erro, consulte Códigos de erro e soluções para o serviço de agregação.
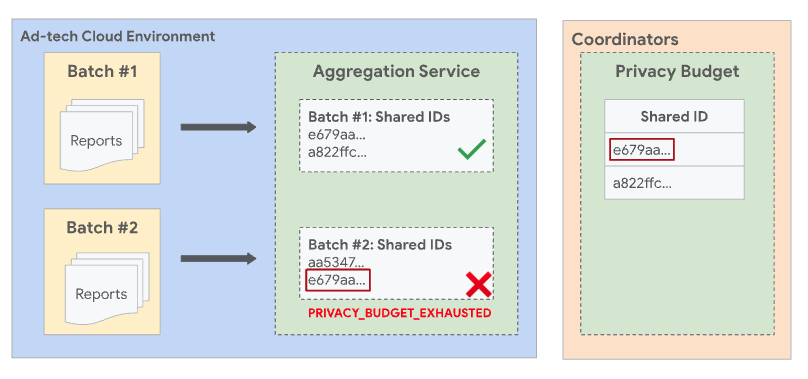
Chaves de agregação pré-declaradas
Quando você envia um lote ao serviço de agregação, ele precisa incluir os relatórios agregáveis recebidos da origem de relatórios e o arquivo de domínio de saída. O domínio de saída contém as chaves ou os buckets recuperados dos relatórios agregáveis.
Do ponto de vista da privacidade, o ruído é adicionado a todas as chaves pré-declaradas no domínio de saída, mesmo quando nenhum relatório real corresponde a uma chave específica. Especificar o domínio de saída protege contra um ataque em que a presença de uma chave na saída revela algo sobre um único usuário ou evento. Por exemplo, se você mostrou uma campanha para apenas um usuário, receber uma chave na saída revela que o usuário fez uma conversão depois, mesmo com ruído adicionado. Ao especificar esse domínio primeiro, você garante que ele não vai revelar nada sobre as contribuições do usuário.
É possível declarar essas chaves de 128 bits na API Attribution Reporting ou na API Private Aggregation e usá-las para codificar as dimensões que você quer rastrear.
Somente as chaves pré-declaradas são consideradas para agregação e incluídas no relatório de resumo. Os valores agregados dos agrupamentos no relatório de resumo têm ruído estatístico adicionado, que é refletido no relatório criado.
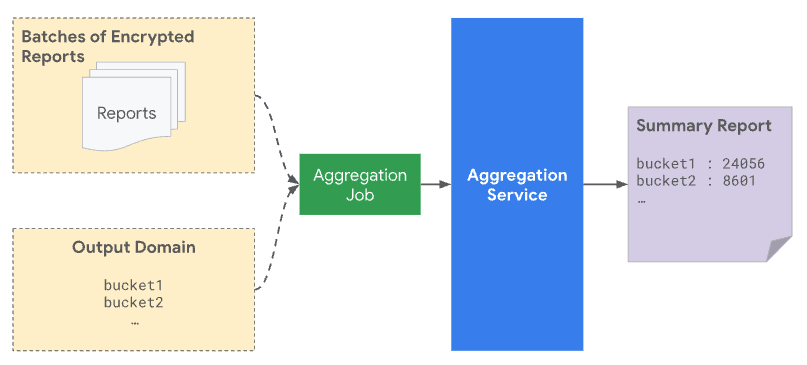
Se uma chave de agregação for incluída no arquivo de domínio de saída, mas não estiver localizada em um relatório em lote, mesmo que o valor agregado seja zero, o relatório resumido final provavelmente não será zero devido ao ruído adicionado para preservar a privacidade.