
Usługa do agregacji generuje raporty podsumowujące szczegółowe dane o konwersjach i pomiarach zasięgu na podstawie surowych raportów podlegających agregacji. Aby zapewnić prywatność i bezpieczeństwo danych użytkowników, usługa Aggregation Service korzysta z platformy, która obsługuje prywatność różnicową. Pozwala ona określać i ograniczać ilość informacji, które te raporty ujawniają o poszczególnych użytkownikach.
W tym przewodniku omawiamy narzędzia i strategie tworzenia raportów zbiorczych, które pomagają chronić dane poszczególnych użytkowników:
- Tworzenie raportów podsumowujących z dodatkowym szumem
- Ustaw budżet na wpłaty
- Strategie grupowania raportów
- Używanie wcześniej zadeklarowanych kluczy agregacji
Raporty podsumowujące z dodatkowym szumem
Gdy zgrupujesz raporty podlegające agregacji, usługa do agregacji utworzy raport podsumowujący. Ten raport podsumowujący zawiera zagregowane dane ze wszystkich wstępnie zdefiniowanych kluczy domeny z dodatkowym szumem statystycznym.
Szum dodawany do raportów nie zależy od liczby agregowanych raportów, wartości poszczególnych raportów ani wartości agregowanych raportów. Szum jest generowany na podstawie dyskretnej wersji rozkładu Laplace’a i skalowany do budżetu na szum (L1 czułość) wymaganego przez klienta w zależności od odpowiedniego interfejsu API pomiarów i parametru prywatności epsilon.
Więcej informacji o szumie i jego wpływie na dane w raportach znajdziesz w artykule Szum w raportach podsumowujących.
Budżet na wspieranie
Aby kontrolować poziom szczegółowości raportu zbiorczego, liczba przekazywanych w wywołaniu danych jest powiązana z określonym limitem danych, zwanym też budżetem danych. Budżet na udział różni się w zależności od tego, czy używasz interfejsu Attribution Reporting API czy interfejsu Private Aggregation API.
Więcej informacji o ustawianiu budżetów na poszczególne interfejsy API znajdziesz w tych sekcjach dokumentacji interfejsu API:
- Ograniczanie i budżetowanie udziału w interfejsie Attribution Reporting API
- Limity dotyczące wkładu w interfejsie Private Aggregation API
- Ograniczanie i budżetowanie wkładu w interfejsie Private Aggregation API
Strategie grupowania raportów
Gdy tworzysz pakiety raportów z możliwością agregacji, ważne jest, aby zoptymalizować strategie tworzenia pakietów, tak aby nie przekraczać limitów prywatności. Dwa ważne pojęcia związane z prawidłowym grupowaniem raportów to reguła „bez duplikatów” i idea rozłącznych partii.
Reguła „Brak duplikatów”
Usługa do agregacji egzekwuje regułę „bez duplikatów”. Ta reguła mówi, że raport podlegający agregacji, który jest jednoznacznie identyfikowany przez parametr report_id, może pojawić się w jednej partii tylko raz. Jeśli raport podlegający agregacji pojawi się w partii więcej niż raz, do agregacji zostanie włączony pierwszy raport, a kolejne raporty z tym samym identyfikatorem report_id zostaną odrzucone. Partia zostanie przetworzona.
Zasady te stanowią również, że ten sam wspólny identyfikator nie może występować w więcej niż 1 partii. Jeśli udostępniony identyfikator został już uwzględniony w poprzedniej partii, późniejsza partia, która również zawiera ten sam udostępniony identyfikator, nie zostanie przetworzona.
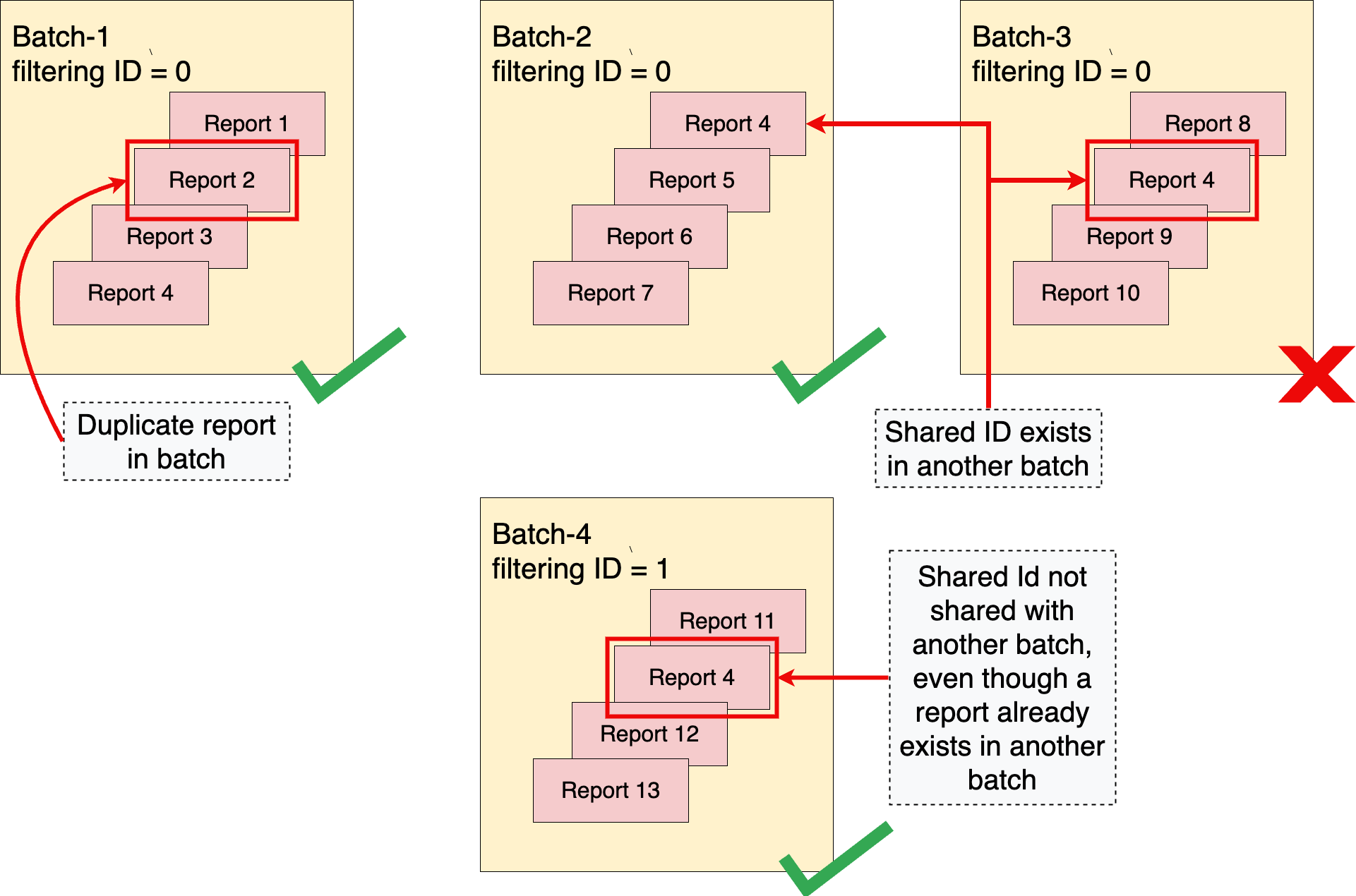
Bez reguły „bez duplikatów” haker może uzyskać wgląd w zawartość konkretnej partii, manipulując zawartością partii przez uwzględnienie zduplikowanych kopii raportu w jednej lub wielu partiach.
Więcej informacji o egzekwowaniu zasady „bez duplikatów” w ramach partii raportów lub w wielu partiach znajdziesz w artykule Duplikaty raportów w partiach.
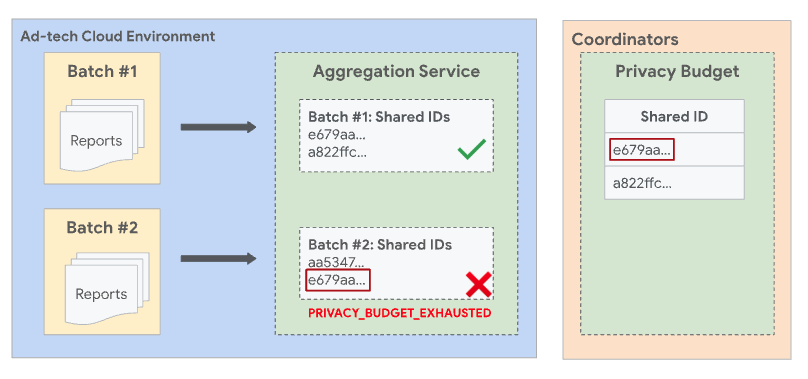
Rozłączne zbiory
Aby uniknąć sytuacji, w których pakiety się pokrywają, usługa Aggregation Service wymusza rozłączne pakiety. Oznacza to, że 2 lub więcej partii nie może zawierać raportów, które mają wspólny udostępniony identyfikator. Wspólny identyfikator to kombinacja danych zebranych z pola shared_info raportu podlegającego agregacji oraz identyfikatora filtrowania z żądania zadania. Jeśli nie podasz identyfikatora filtrowania, zostanie użyta wartość domyślna 0.
W tym przykładzie pola shared_info możesz zobaczyć interfejs API, attribution_destination (w przypadku interfejsu Attribution Reporting), reporting_origin, scheduled_report_time, source_registration_time (w przypadku interfejsu Attribution Reporting) i version. Te pola, z wyjątkiem report_id, wraz z identyfikatorem filtrowania z żądania zadania, składają się na wspólny identyfikator.
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://privacy-sandbox-demos-shop.dev",
"report_id": "5b052748-f5fb-4f14-b291-de03484ed59e",
"reporting_origin": "https://privacy-sandbox-demos-dsp.dev",
"scheduled_report_time": "1707786751",
"source_registration_time": "0",
"version": "0.1"
}
Ponieważ source_registration_time jest obcinany do dnia, a scheduled_report_time do godziny, niektóre raporty mają ten sam wspólny identyfikator. W tym przykładzie raporty Report1 i Report2 mają wspólne pola informacji. Oba raporty mają ten sam interfejs API, wersję, attribution_destination, reporting_origin i source_registration_time. Ponieważ report_id nie jest częścią udostępnionego identyfikatora, możesz zignorować tę różnicę.
W przykładach Report1 i Report2 wartość scheduled_report_time jest taka sama.
Informacje udostępnione przez Report1:
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://shop.dev",
"report_id": "5b052748-...",
"reporting_origin": "https://dsp.dev",
"scheduled_report_time": "1708376890",
"source_registration_time": "0",
"version": "0.1"
}
Informacje udostępnione przez Report2:
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://shop.dev",
"report_id": "5b052748-...",
"reporting_origin": "https://dsp.dev",
"scheduled_report_time": "1708376890",
"source_registration_time": "0",
"version": "0.1"
}
Zaplanowane godziny wygenerowania raportów to „19 lutego 2024 r., 21:08:10” w przypadku Raportu 1 i „19 lutego 2024 r., 21:55:10” w przypadku Raportu 2. Wartość pola scheduled_report_time jest skracana do godziny, więc w obu raportach pole scheduled_report_time ma wartość 1708376890 (zakodowana wartość „19 lutego 2024 r., godz. 21:00”).
Jeśli wszystkie pozostałe pola i identyfikator filtrowania są takie same, oba raporty mają ten sam identyfikator udostępniania. A ponieważ oba raporty mają ten sam wspólny identyfikator, muszą być uwzględnione w tej samej partii.
Jeśli Raport1 został przetworzony w poprzedniej udanej partii, a Raport2 jest przetwarzany w kolejnej partii, partia z Raportem2 zakończy się niepowodzeniem z błędem PRIVACY_BUDGET_EXHAUSTED. W takim przypadku usuń raporty o wspólnym identyfikatorze, które zostały już wcześniej zgrupowane, i spróbuj ponownie. Więcej informacji o tym błędzie znajdziesz w artykule Kody błędów i sposoby ich eliminowania w usłudze agregacji.
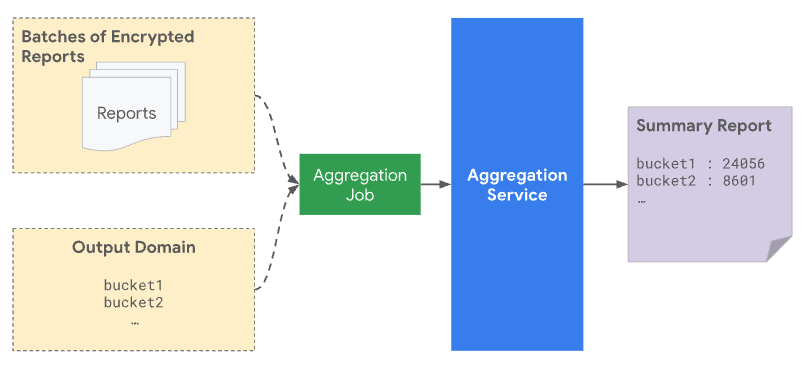
Wstępnie zadeklarowane klucze agregacji
Gdy przesyłasz partię do usługi do agregacji, musi ona zawierać zarówno raporty podlegające agregacji, które zostały otrzymane z pochodzenia raportowania, jak i plik domeny wyjściowej. Domena wyjściowa zawiera klucze lub przedziały pobierane z raportów z możliwością agregacji.
Z punktu widzenia ochrony prywatności szum jest dodawany do wszystkich kluczy zadeklarowanych wcześniej w domenie wyjściowej, nawet jeśli żaden rzeczywisty raport nie pasuje do danego klucza. Określenie domeny wyjściowej chroni przed atakiem, w którym obecność klucza w danych wyjściowych ujawnia informacje o pojedynczym użytkowniku lub zdarzeniu. Jeśli na przykład kampania była wyświetlana tylko jednemu użytkownikowi, otrzymanie klucza w danych wyjściowych ujawnia, że użytkownik dokonał później konwersji, nawet po dodaniu szumu. Określając najpierw tę domenę, możesz mieć pewność, że nie ujawni ona żadnych informacji o wkładzie użytkownika.
Możesz zadeklarować te 128-bitowe klucze w interfejsie Attribution Reporting API lub Private Aggregation API i używać ich do kodowania wymiarów, które chcesz śledzić.
Do agregacji brane są pod uwagę tylko wcześniej zadeklarowane klucze, które są też uwzględniane w raporcie podsumowującym. Do zagregowanych wartości przedziałów w raporcie podsumowującym dodawane są szumy statystyczne, co znajduje odzwierciedlenie w utworzonym raporcie podsumowującym.
Jeśli klucz agregacji jest uwzględniony w pliku domeny wyjściowej, ale nie znajduje się w raporcie zbiorczym, końcowy raport podsumowujący prawdopodobnie będzie miał wartość inną niż zero, nawet jeśli zagregowana wartość wynosi zero. Wynika to z dodania szumu w celu zachowania prywatności.