
집계 서비스는 원시 집계 가능 보고서에서 상세 전환 데이터와 도달범위 측정의 요약 보고서를 생성합니다. 사용자 데이터를 비공개로 안전하게 유지하기 위해 집계 서비스는 차등 개인 정보 보호 (DP)를 지원하는 프레임워크를 사용하여 이러한 보고서가 개별 사용자에 관해 공개하는 정보의 양을 정량화하고 제한합니다.
이 가이드에서는 개별 사용자 데이터를 안전하게 유지하는 데 도움이 되는 집계 가능한 보고서를 만들기 위한 도구와 전략을 설명합니다.
- 노이즈가 추가된 요약 보고서 만들기
- 기여 예산 설정
- 보고서 일괄 처리 전략
- 사전 선언된 집계 키 사용
노이즈가 추가된 요약 보고서
집계 가능한 보고서를 일괄 처리하면 집계 서비스에서 요약 보고서를 만듭니다. 이 요약 보고서는 사전 정의된 모든 도메인 키의 기여도를 합산한 것으로, 통계적 노이즈가 추가됩니다.
보고서에 추가되는 노이즈는 집계된 보고서 수, 개별 보고서 값 또는 집계된 보고서 값에 따라 달라지지 않습니다. 노이즈는 라플라스 분포의 이산 버전에서 추출되며, 해당 측정 API와 개인 정보 보호 매개변수 epsilon에 따라 클라이언트에서 적용되는 기여 예산 (L1 민감도)에 맞게 조정됩니다.
노이즈 및 노이즈가 보고서 데이터에 미치는 영향에 대해 자세히 알아보려면 요약 보고서의 노이즈 이해하기를 참고하세요.
기여 예산
요약 보고서의 민감도를 제어하기 위해 호출에서 전달되는 기여 수는 기여 예산이라고도 하는 특정 기여 상한과 연결됩니다. 기여 예산은 Attribution Reporting API를 사용하는지 또는 Private Aggregation API를 사용하는지에 따라 다릅니다.
각 API의 기여 예산을 설정하는 방법을 자세히 알아보려면 다음 API 문서 섹션을 참고하세요.
- Attribution Reporting API 기여도 제한 및 예산 책정
- Private Aggregation API 기여 한도
- Private Aggregation API 기여도 제한 및 예산 책정
보고서 일괄 처리 전략
집계 가능한 보고서를 일괄처리할 때는 개인 정보 보호 한도를 초과하지 않도록 일괄처리 전략을 최적화하는 것이 중요합니다. 보고서를 올바르게 일괄 처리하는 데 중요한 두 가지 개념은 '중복 없음' 규칙과 분리된 배치라는 아이디어입니다.
'중복 없음' 규칙
집계 서비스는 '중복 없음' 규칙을 적용합니다. 이 규칙에 따르면 report_id로 고유하게 식별되는 집계 가능한 보고서는 단일 배치에 한 번만 표시될 수 있습니다. 집계 가능한 보고서가 배치당 두 번 이상 표시되면 첫 번째 보고서가 집계에 포함되고 동일한 report_id를 사용하는 후속 보고서는 삭제되며 배치가 성공적으로 완료됩니다.
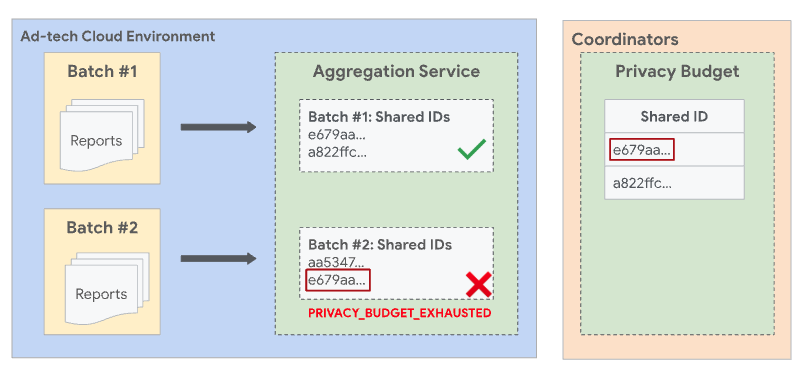
또한 동일한 공유 ID가 두 개 이상의 배치에 표시될 수 없다고 명시되어 있습니다. 공유 ID가 이미 이전의 성공적인 일괄 처리에 포함된 경우 동일한 공유 ID가 포함된 후속 일괄 처리는 실패합니다.
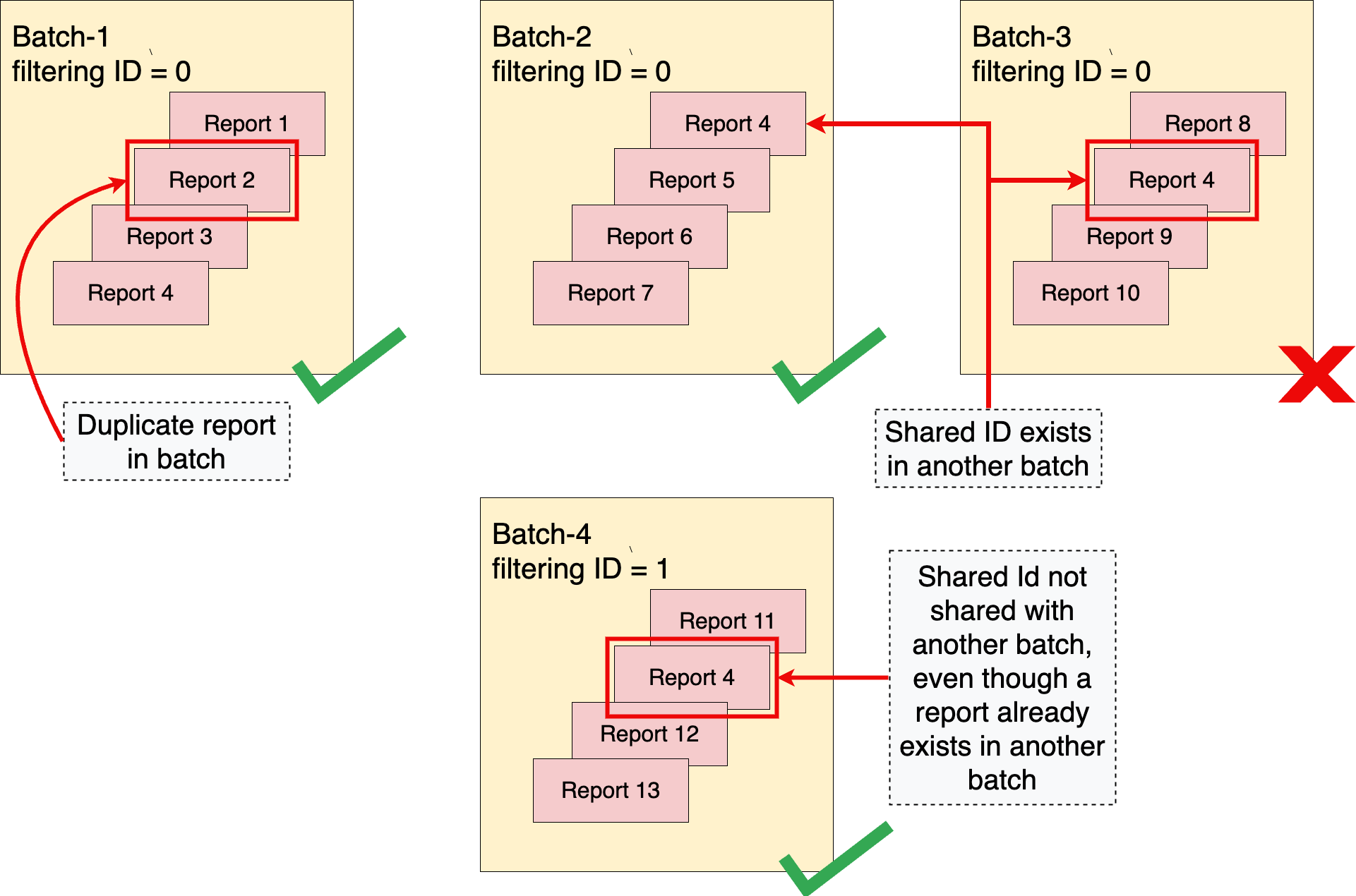
'중복 없음' 규칙이 없으면 공격자가 단일 배치 또는 여러 배치에 보고서의 중복 사본을 포함하여 배치의 콘텐츠를 조작함으로써 특정 배치의 콘텐츠에 대한 유용한 정보를 얻을 수 있습니다.
보고서 일괄 처리 내 또는 여러 일괄 처리 간에 '중복 없음' 규칙을 적용하는 방법을 자세히 알아보려면 일괄 처리 내 중복 보고서를 참고하세요.
겹치지 않는 배치
배치 간에 중복이 발생하는 상황을 방지하기 위해 집계 서비스는 분리된 배치를 적용합니다. 즉, 두 개 이상의 일괄 처리에는 공통 공유 ID를 공유하는 보고서가 포함될 수 없습니다. 공유 ID는 집계 가능한 보고서의 shared_info 필드에서 수집된 데이터와 작업 요청의 필터링 ID를 결합한 것입니다. 필터링 ID를 지정하지 않으면 기본값 0이 사용됩니다.
다음 shared_info 필드 예시에서 API, attribution_destination (Attribution Reporting용), reporting_origin, scheduled_report_time, source_registration_time (Attribution Reporting용), version를 확인할 수 있습니다. report_id를 제외한 이러한 필드는 채용 정보 요청의 필터링 ID와 함께 공유 ID에 기여합니다.
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://privacy-sandbox-demos-shop.dev",
"report_id": "5b052748-f5fb-4f14-b291-de03484ed59e",
"reporting_origin": "https://privacy-sandbox-demos-dsp.dev",
"scheduled_report_time": "1707786751",
"source_registration_time": "0",
"version": "0.1"
}
source_registration_time은 일별로 잘리고 scheduled_report_time은 시간별로 잘리므로 공유 ID가 동일한 보고서가 있습니다. 이 예시에서 Report1과 Report2에는 공유 정보 필드가 있습니다. 두 보고서의 API, 버전, attribution_destination, reporting_origin, source_registration_time가 동일합니다. report_id는 공유 ID에 포함되지 않으므로 이 차이는 무시해도 됩니다.
Report1 및 Report2의 다음 예시에서 scheduled_report_time 값은 동일합니다.
Report1 공유 정보:
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://shop.dev",
"report_id": "5b052748-...",
"reporting_origin": "https://dsp.dev",
"scheduled_report_time": "1708376890",
"source_registration_time": "0",
"version": "0.1"
}
Report2 공유 정보:
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://shop.dev",
"report_id": "5b052748-...",
"reporting_origin": "https://dsp.dev",
"scheduled_report_time": "1708376890",
"source_registration_time": "0",
"version": "0.1"
}
예약된 보고 시간은 Report1의 경우 '2024년 2월 19일 오후 9시 8분 10초', Report2의 경우 '2024년 2월 19일 오후 9시 55분 10초'입니다. scheduled_report_time 필드의 값이 시간으로 잘리기 때문에 두 보고서 모두 scheduled_report_time 필드의 값이 1708376890('2024년 2월 19일 오후 9시'의 인코딩된 값)입니다.
다른 모든 필드와 필터링 ID가 동일하므로 두 보고서의 공유 ID가 동일합니다. 두 보고서의 공유 ID가 동일하므로 동일한 일괄 처리에 포함되어야 합니다.
Report1이 이전에 성공한 배치에서 일괄 처리되고 Report2가 후속 배치에서 처리되면 Report2가 포함된 배치가 PRIVACY_BUDGET_EXHAUSTED 오류와 함께 실패합니다. 이 경우 이전 배치에서 일괄 처리된 공유 ID가 있는 보고서를 삭제하고 다시 시도하세요. 이 오류에 대한 자세한 내용은 집계 서비스의 오류 코드 및 완화 조치를 참고하세요.
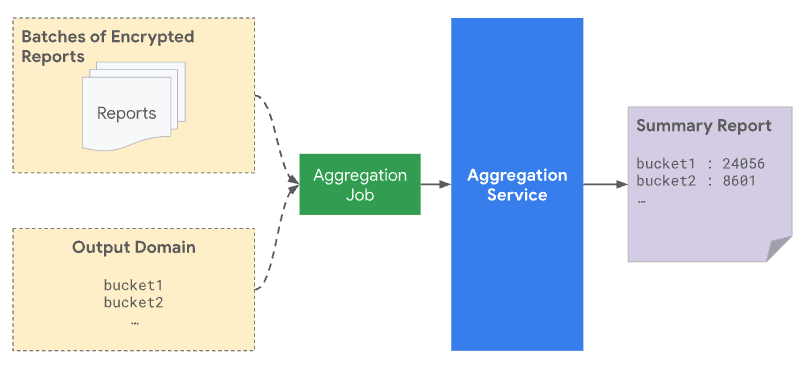
사전 선언된 집계 키
집계 서비스에 배치를 제출할 때는 보고 출처에서 수신한 집계 가능한 보고서와 출력 도메인 파일을 모두 포함해야 합니다. 출력 도메인에는 집계 가능한 보고서에서 가져온 키 또는 버킷이 포함됩니다.
개인 정보 보호 관점에서 실제 보고서가 특정 키와 일치하지 않는 경우에도 출력 도메인에 미리 선언된 모든 키에 노이즈가 추가됩니다. 출력 도메인을 지정하면 출력에 키가 있으면 단일 사용자 또는 이벤트에 관한 정보가 드러나는 공격을 방지할 수 있습니다. 예를 들어 한 사용자에게만 캠페인을 표시한 경우 출력에서 키를 수신하면 노이즈가 추가되더라도 사용자가 나중에 전환했음을 알 수 있습니다. 이 도메인을 먼저 지정하면 사용자 기여에 관한 정보가 공개되지 않습니다.
Attribution Reporting API 또는 Private Aggregation API에서 이러한 128비트 키를 선언하고 이를 사용하여 추적하려는 측정기준을 인코딩할 수 있습니다.
사전 선언된 키만 집계에 고려되고 요약 보고서에 포함됩니다. 요약 보고서의 버킷 집계 값에 통계적 노이즈가 추가되며, 이는 생성된 요약 보고서에 반영됩니다.
집계 키가 출력 도메인 파일에 포함되어 있지만 일괄 보고서에 없는 경우 집계된 값이 0이라도 개인 정보 보호를 위해 추가된 노이즈로 인해 최종 요약 보고서가 0이 아닐 수 있습니다.