
El Servicio de agregación genera informes de resumen de los datos detallados de conversiones y las mediciones de alcance a partir de informes agregables sin procesar. Para mantener la privacidad y la seguridad de los datos del usuario, Aggregation Service usa un framework que admite la privacidad diferencial (DP) para cuantificar y limitar la cantidad de información que revelan estos informes sobre los usuarios individuales.
En esta guía, se analizan las herramientas y estrategias para crear informes agregables que ayudan a mantener seguros los datos sobre usuarios individuales:
- Crea informes resumidos con ruido agregado
- Establece un presupuesto de contribución
- Estrategias para el procesamiento por lotes de informes
- Maneja informes duplicados en lotes
- Cómo controlar los informes con un ID compartido común
- Usa claves de agregación declaradas previamente
Informes de resumen con ruido agregado
Cuando generas informes agregables por lotes, el Servicio de agregación crea un informe de resumen. Este informe de resumen es un agregado de todas las contribuciones de todas las claves de dominio predefinidas, con ruido estadístico agregado.
El ruido que se agrega a los informes no depende de la cantidad de informes agregados, los valores de los informes individuales ni los valores de los informes agregados. El ruido se extrae de una versión discreta de la distribución de Laplace y se ajusta al presupuesto de contribución (sensibilidad de L1) que aplica el cliente según la API de medición correspondiente y el parámetro de privacidad epsilon.
Para obtener más información sobre el ruido y sus implicaciones en los datos de los informes, consulta Acerca del ruido en los informes de resumen.
Presupuesto de contribución
Para controlar la sensibilidad de un informe de resumen, la cantidad de contribuciones que se pasan en una llamada se vincula a un límite de vinculación de contribuciones específico, también conocido como presupuesto de contribuciones. El presupuesto de contribución varía según si usas la API de Attribution Reporting o la API de Private Aggregation.
Para obtener más información sobre cómo establecer presupuestos de contribución para cada API, consulta las siguientes secciones de la documentación de la API:
- Delimitación y asignación de presupuesto de la contribución de la API de Attribution Reporting
- Límites de contribución de la API de Private Aggregation
- Delimitación y asignación de presupuesto de contribuciones de la API de Private Aggregation
Estrategias para el procesamiento por lotes de informes
Cuando procesas informes agregables por lotes, es importante optimizar las estrategias de procesamiento por lotes para que no se excedan los límites de privacidad. Dos conceptos importantes para agrupar los informes correctamente son la regla de"sin duplicados" y la idea de lotes disjuntos.
Regla "Sin duplicados"
El Servicio de agregación aplica una regla de "sin duplicados". Esta regla indica que un informe agregable, que se identifica de forma única con report_id, solo puede aparecer una vez en un lote. Si un informe agregable aparece más de una vez por lote, el primer informe se incluye en la agregación, se descartan los informes posteriores con el mismo report_id y el lote se completa correctamente.
La regla también indica que el mismo ID compartido no puede aparecer en más de un lote. Si ya se incluyó un ID compartido en un lote anterior que se procesó correctamente, fallará un lote posterior que también incluya el mismo ID compartido.
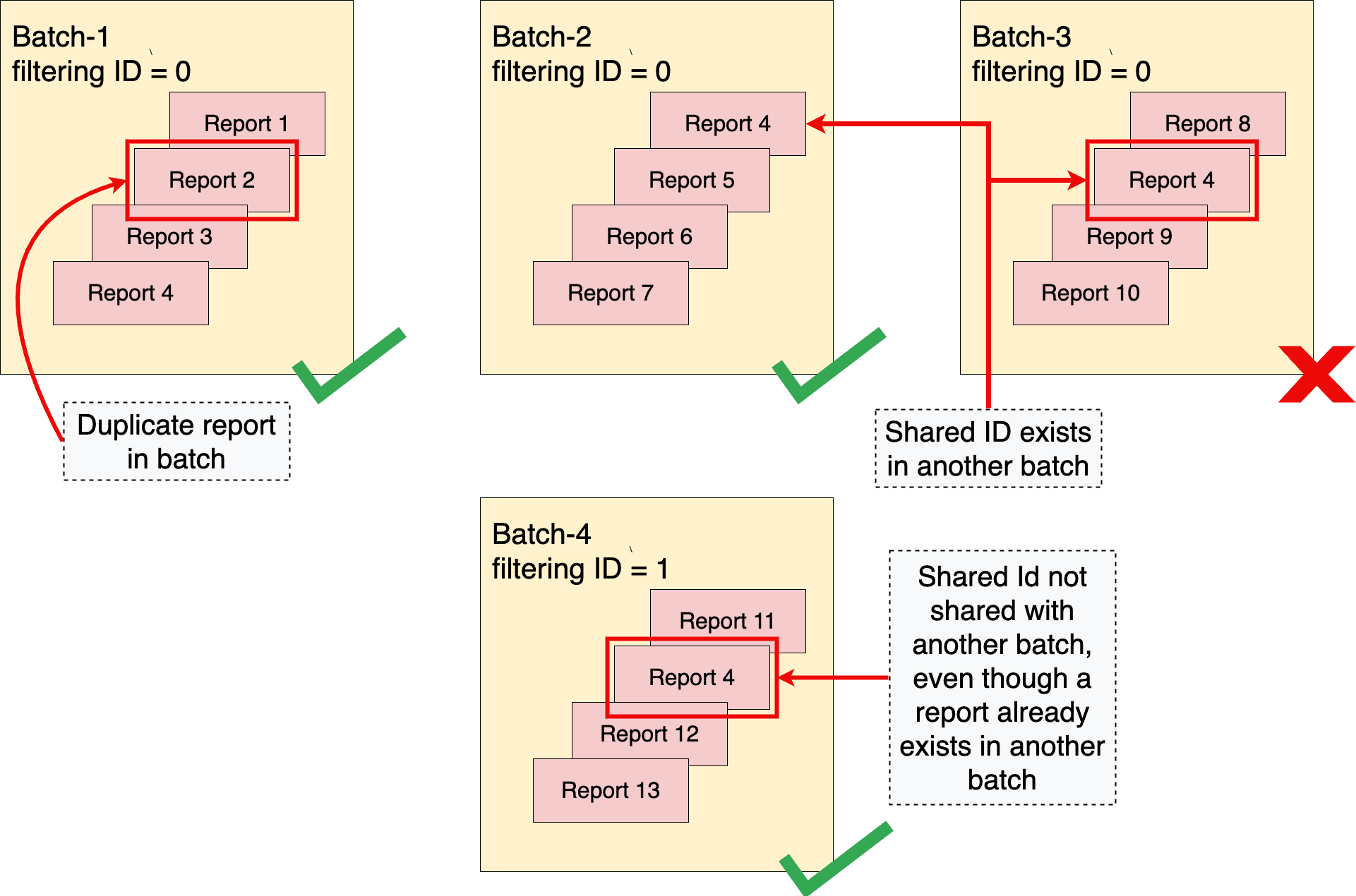
Sin la regla de "sin duplicados", un atacante podría obtener información sobre el contenido de un lote específico manipulando el contenido de los lotes, ya sea incluyendo copias duplicadas de un informe en un solo lote o en varios.
Para obtener más información sobre cómo aplicar la regla de "sin duplicados" en un lote de informes o en varios lotes, consulta Informes duplicados dentro de lotes.
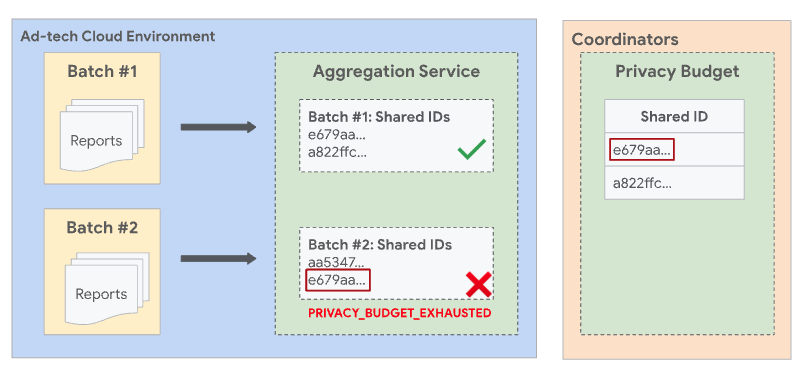
Lotes independientes
Para evitar situaciones en las que haya superposición entre lotes, el Servicio de agregación aplica lotes disjuntos. Esto significa que dos o más lotes no pueden contener informes que compartan un ID compartido común. Un ID compartido es una combinación de datos recopilados del campo shared_info de un informe agregable, junto con el ID de filtrado de la solicitud de trabajo. Si no se especifica un ID de filtrado, se usa el valor predeterminado 0.
En el siguiente ejemplo del campo shared_info, puedes ver la API, attribution_destination (para Attribution Reporting), reporting_origin, scheduled_report_time, source_registration_time (para Attribution Reporting) y version. Estos campos, excepto el report_id, junto con el ID de filtrado de la solicitud de trabajo, contribuyen al ID compartido.
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://privacy-sandbox-demos-shop.dev",
"report_id": "5b052748-f5fb-4f14-b291-de03484ed59e",
"reporting_origin": "https://privacy-sandbox-demos-dsp.dev",
"scheduled_report_time": "1707786751",
"source_registration_time": "0",
"version": "0.1"
}
Dado que source_registration_time se trunca por día y scheduled_report_time se trunca por hora, hay informes que tienen el mismo ID compartido. En este ejemplo, Informe1 y Informe2 tienen campos de información compartidos. Ambos informes tienen la misma API, versión, attribution_destination, reporting_origin y source_registration_time. Como report_id no forma parte del ID compartido, puedes ignorar esta diferencia.
En los siguientes ejemplos de Informe1 y Informe2, el valor de scheduled_report_time es el mismo.
Información compartida de Report1:
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://shop.dev",
"report_id": "5b052748-...",
"reporting_origin": "https://dsp.dev",
"scheduled_report_time": "1708376890",
"source_registration_time": "0",
"version": "0.1"
}
Información compartida de Report2:
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://shop.dev",
"report_id": "5b052748-...",
"reporting_origin": "https://dsp.dev",
"scheduled_report_time": "1708376890",
"source_registration_time": "0",
"version": "0.1"
}
Los horarios programados para los informes son "19 de febrero de 2024, 21:08:10" para Informe1 y "19 de febrero de 2024, 21:55:10" para Informe2. Dado que el valor del campo scheduled_report_time se trunca a la hora, ambos informes tienen 1708376890 (el valor codificado para "19 de febrero de 2024, 21:00") como el valor del campo scheduled_report_time.
Con todos los demás campos y el ID de filtrado iguales, ambos informes tienen el mismo ID compartido. Como ambos informes tienen el mismo ID compartido, deben incluirse en el mismo lote.
Si Report1 se procesó por lotes en un lote anterior exitoso y Report2 se procesa en un lote posterior, el lote con Report2 falla con un error PRIVACY_BUDGET_EXHAUSTED. Si esto sucede, quita los informes con el ID compartido que se hayan agrupado correctamente en lotes anteriores y vuelve a intentarlo. Para obtener más información sobre este error, consulta Códigos de error y mitigaciones para el Servicio de agregación.
Claves de agregación declaradas previamente
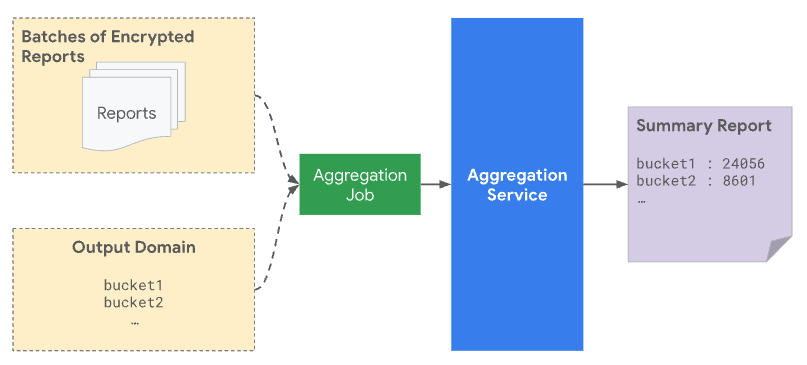
Cuando envías un lote al servicio de agregación, este debe incluir los informes agregables que se reciben del origen de informes y el archivo de dominio de salida. El dominio de salida contiene las claves o los buckets que se recuperan de los informes agregables.
Desde el punto de vista de la privacidad, se agrega ruido a todas las claves declaradas previamente en el dominio de salida, incluso cuando ningún informe real coincide con una clave en particular. Especificar el dominio de salida protege contra un ataque en el que la presencia de una clave en la salida revela información sobre un solo usuario o evento. Por ejemplo, si solo mostraste una campaña a un usuario, recibir una clave en el resultado revela que el usuario generó una conversión más tarde, incluso con el ruido agregado. Si especificas este dominio primero, puedes tener la certeza de que no revela nada sobre las contribuciones de los usuarios.
Puedes declarar estas claves de 128 bits en la API de Attribution Reporting o en la API de Private Aggregation y usarlas para codificar las dimensiones que deseas hacer un seguimiento.
Solo se consideran las claves declaradas previamente para la agregación y se incluyen en el informe de resumen. Los valores agregados de los discretizaciones en el informe de resumen tienen ruido estadístico agregado, lo que se refleja en el informe de resumen creado.
Si se incluye una clave de agregación en el archivo de dominio de salida, pero no se encuentra en un informe por lotes, incluso si el valor agregado es cero, es probable que el informe de resumen final no sea cero debido al ruido agregado para preservar la privacidad.