
Il servizio di aggregazione genera report di riepilogo dei dati dettagliati sulle conversioni e delle misurazioni della copertura dai report aggregabili non elaborati. Per mantenere privati e sicuri i dati degli utenti, il servizio di aggregazione utilizza un framework che supporta la privacy differenziale (DP) per quantificare e limitare la quantità di informazioni che questi report rivelano sui singoli utenti.
Questa guida illustra strumenti e strategie per creare report aggregabili che contribuiscono a proteggere i dati dei singoli utenti:
- Creare report riepilogativi con rumore aggiunto
- Impostare un budget per i contributi
- Strategie per il raggruppamento dei report
- Gestire i report duplicati in batch
- Gestire i report con un ID condiviso comune
- Utilizzare chiavi di aggregazione dichiarate in precedenza
Report di riepilogo con rumore aggiunto
Quando raggruppi i report aggregabili, il servizio di aggregazione crea un report di riepilogo. Questo report di riepilogo è un aggregato di tutti i contributi di tutte le chiavi di dominio predefinite, con rumore statistico aggiunto.
Il rumore aggiunto ai report non dipende dal numero di report aggregati, dai valori dei singoli report o dai valori dei report aggregati. Il rumore viene estratto da una versione discreta della distribuzione di Laplace e viene scalato in base al budget di contributo (sensibilità L1) applicato dal client a seconda dell'API di misurazione corrispondente e del parametro di privacy epsilon.
Per saperne di più sul rumore e sulle sue implicazioni per i dati dei report, vedi Informazioni sul rumore nei report di riepilogo.
Budget per i contributi
Per controllare la sensibilità di un report riepilogativo, il numero di contributi passati in una chiamata è legato a un limite di bounding specifico per i contributi, noto anche come budget dei contributi. Il budget per i contributi varia a seconda che utilizzi l'API Attribution Reporting o l'API Private Aggregation.
Per scoprire di più su come impostare i budget di contributo per ogni API, consulta le seguenti sezioni della documentazione dell'API:
- Limiti e budget per il contributo dell'API Attribution Reporting
- Limiti di contributo dell'API Private Aggregation
- Limiti e budget per i contributi dell'API Private Aggregation
Strategie per il raggruppamento dei report
Quando raggruppi i report aggregabili, è importante ottimizzare le strategie di raggruppamento in modo che non vengano superati i limiti della privacy. Due concetti importanti per raggruppare correttamente i report sono la regola "Nessun duplicato" e l'idea di batch disgiunti.
Regola "Nessun duplicato"
Il servizio di aggregazione applica una regola "nessun duplicato". Questa regola stabilisce che un report aggregabile, identificato in modo univoco da report_id, può essere visualizzato una sola volta in un singolo batch. Se un report aggregabile viene visualizzato più di una volta per batch, il primo report viene incluso nell'aggregazione, i report successivi con lo stesso report_id vengono eliminati e il batch viene completato correttamente.
La regola stabilisce inoltre che lo stesso ID condiviso non può essere visualizzato in più di un batch. Se un ID condiviso è già stato incluso in un batch precedente riuscito, un batch successivo che include lo stesso ID condiviso non andrà a buon fine.
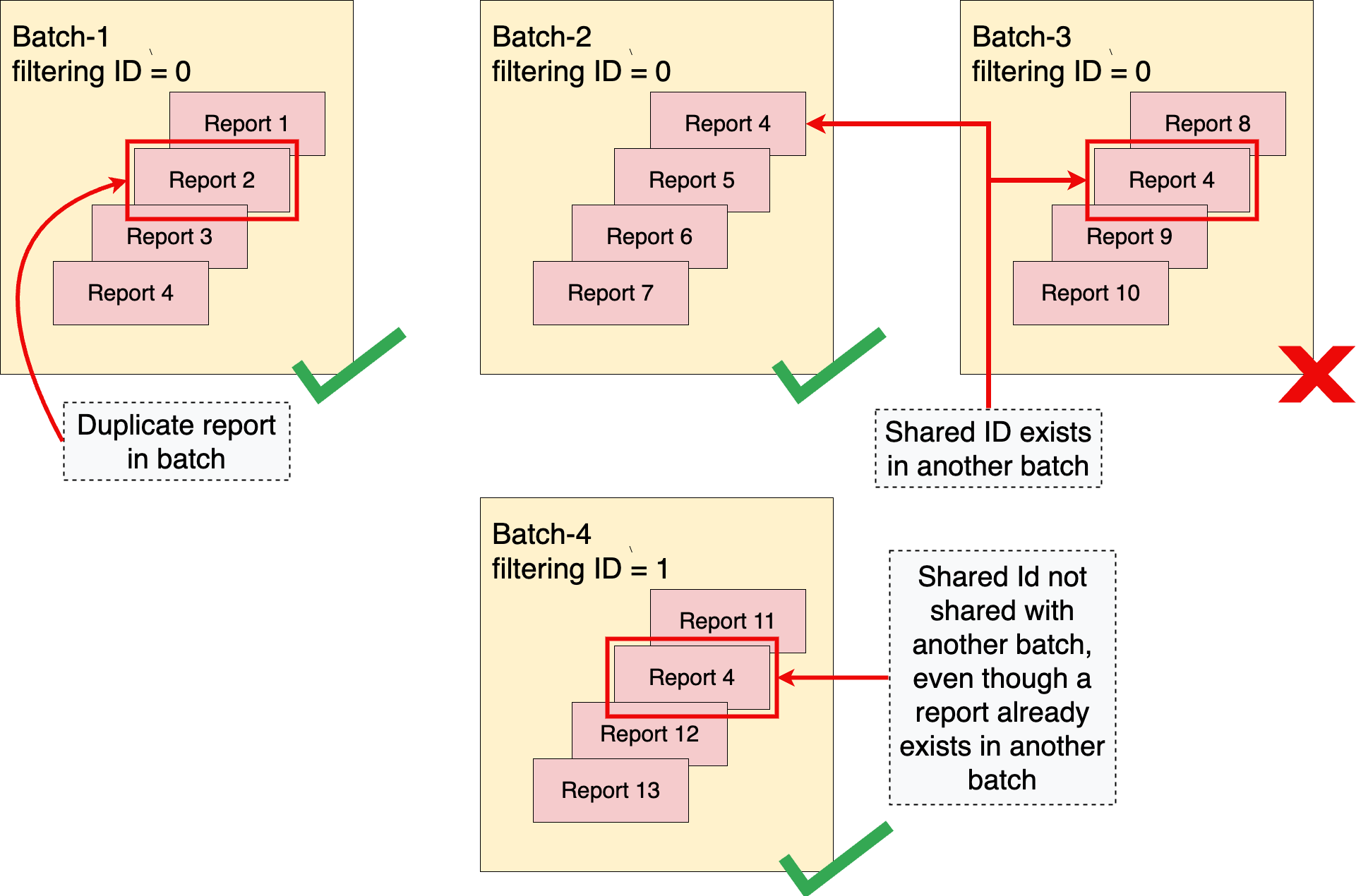
Senza la regola "Nessun duplicato", un malintenzionato potrebbe ottenere informazioni sui contenuti di un batch specifico manipolando i contenuti dei batch includendo copie duplicate di un report in un singolo batch o in più batch.
Per saperne di più sull'applicazione della regola "Nessun duplicato" all'interno di un batch di report o in più batch, consulta Report duplicati all'interno dei batch.
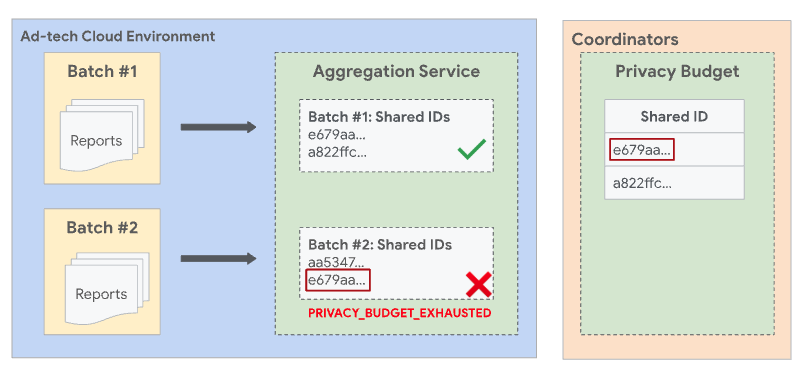
Batch disgiunti
Per evitare situazioni in cui si verifica una sovrapposizione tra i batch, il servizio di aggregazione applica batch disgiunti. Ciò significa che due o più batch non possono contenere report che condividono un ID condiviso. Un ID condiviso è una combinazione di dati raccolti dal campo shared_info di un report aggregabile, insieme all'ID filtro della richiesta di lavoro. Se non viene specificato alcun ID filtro, viene utilizzato il valore predefinito 0.
Nell'esempio di campo shared_info riportato di seguito, puoi vedere l'API, attribution_destination (per Attribution Reporting), reporting_origin, scheduled_report_time, source_registration_time (per Attribution Reporting) e version. Questi campi, ad eccezione di report_id, insieme all'ID filtro della richiesta di job, contribuiscono all'ID condiviso.
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://privacy-sandbox-demos-shop.dev",
"report_id": "5b052748-f5fb-4f14-b291-de03484ed59e",
"reporting_origin": "https://privacy-sandbox-demos-dsp.dev",
"scheduled_report_time": "1707786751",
"source_registration_time": "0",
"version": "0.1"
}
Poiché source_registration_time è troncato per giorno e scheduled_report_time è troncato per ora, esistono report con lo stesso ID condiviso. In questo esempio, Report1 e Report2 hanno campi di informazioni condivisi. Entrambi i report hanno la stessa API, versione, attribution_destination, reporting_origin e source_registration_time. Poiché report_id non fa parte dell'ID condiviso, puoi ignorare questa differenza.
Negli esempi seguenti per Report1 e Report2, il valore di scheduled_report_time è lo stesso.
Informazioni condivise di Report1:
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://shop.dev",
"report_id": "5b052748-...",
"reporting_origin": "https://dsp.dev",
"scheduled_report_time": "1708376890",
"source_registration_time": "0",
"version": "0.1"
}
Informazioni condivise da Report2:
"shared_info": {
"API": "attribution-reporting",
"attribution_destination": "https://shop.dev",
"report_id": "5b052748-...",
"reporting_origin": "https://dsp.dev",
"scheduled_report_time": "1708376890",
"source_registration_time": "0",
"version": "0.1"
}
Gli orari dei report pianificati sono "19 febbraio 2024 21:08:10" per Report1 e "19 febbraio 2024 21:55:10" per Report2. Poiché il valore del campo scheduled_report_time viene troncato all'ora, entrambi i report hanno 1708376890 (il valore codificato per "19 febbraio 2024 ore 21:00") come valore del campo scheduled_report_time.
Con tutti gli altri campi e l'ID filtro uguali, entrambi i report hanno lo stesso ID condiviso. Poiché entrambi i report hanno lo stesso ID condiviso, devono essere inclusi nello stesso batch.
Se Report1 è stato raggruppato in un batch precedente riuscito e Report2 viene elaborato in un batch successivo, il batch con Report2 non riesce e viene visualizzato un errore PRIVACY_BUDGET_EXHAUSTED. In questo caso, rimuovi i report con l'ID condiviso che sono stati raggruppati correttamente nei batch precedenti e riprova. Per saperne di più su questo errore, consulta Codici di errore e mitigazioni per il servizio di aggregazione.
Chiavi di aggregazione dichiarate in anticipo
Quando invii un batch al servizio di aggregazione, questo deve includere sia i report aggregabili ricevuti dall'origine dei report sia il file di dominio di output. Il dominio di output contiene le chiavi o i bucket recuperati dai report aggregabili.
Dal punto di vista della privacy, viene aggiunto rumore a tutte le chiavi dichiarate in precedenza nel dominio di output, anche quando nessun report reale corrisponde a una determinata chiave. La specifica del dominio di output protegge da un attacco in cui la presenza di una chiave nell'output rivela qualcosa su un singolo utente o evento. Ad esempio, se hai mostrato una campagna a un solo utente, la ricezione di una chiave nell'output rivela che l'utente ha generato una conversione in un secondo momento, anche con l'aggiunta di rumore. Se specifichi prima questo dominio, puoi essere certo che non riveli nulla sui contributi dell'utente.
Puoi dichiarare queste chiavi a 128 bit nell'API Attribution Reporting o nell'API Private Aggregation e utilizzarle per codificare le dimensioni che vuoi monitorare.
Solo le chiavi dichiarate in anticipo vengono prese in considerazione per l'aggregazione e incluse nel report di riepilogo. Ai valori aggregati dei bucket nel report di riepilogo viene aggiunto rumore statistico, che si riflette nel report di riepilogo creato.
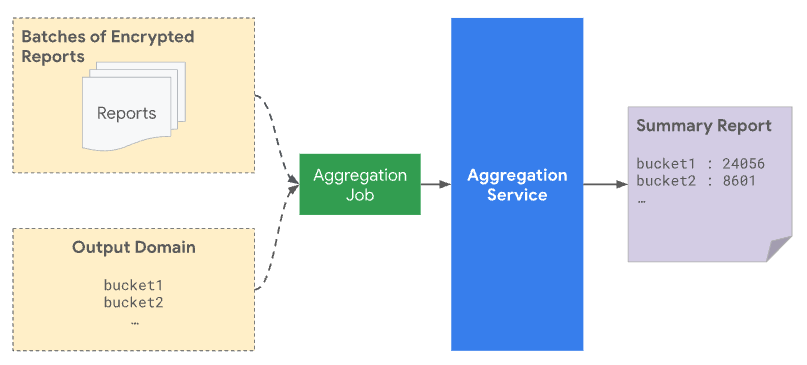
Se una chiave di aggregazione è inclusa nel file di dominio di output, ma non si trova in un report batch, anche se il valore aggregato è zero, è probabile che il report di riepilogo finale sia diverso da zero a causa del rumore aggiunto per preservare la privacy.