
Der Aggregationsdienst bietet Anzeigentechnologien die Leistungsstatistiken, die erforderlich sind, um die Kampagneneffektivität für Kunden zu verbessern.
In diesem Dokument wird Folgendes behandelt:
- Wichtige Begriffe und Konzepte
- So funktioniert der Aggregationsdienst, um detaillierte Conversion-Daten und Reichweitenmessungen aus aggregierbaren Rohberichten zu erhalten
- Batchverarbeitung von aggregierbaren Berichten – konzeptionelle Übersicht
- Cloud-Komponenten – Konzeptübersicht
An wen richtet sich dieses Dokument?
Auf dieser Seite erfahren Anzeigentechnologie-Anbieter und Entwickler, wie unsere APIs eine effektive, datenschutzfreundliche Werbemessung ermöglichen.
In diesem Dokument wird davon ausgegangen, dass Sie mit der Private Aggregation API, der Attribution Reporting API, der Protected Audience API, Shared Storage und Trusted Execution Environments vertraut sind.
Wichtige Begriffe und Konzepte
Machen Sie sich mit den wichtigsten Begriffen vertraut, bevor Sie fortfahren:
Glossar
- AdTech
-
Eine Werbeplattform ist ein Unternehmen, das Dienstleistungen zur Anzeigenauslieferung anbietet.
- Zusammenfassbare Berichte
-
Aggregierbare Berichte sind verschlüsselte Berichte, die von einzelnen Nutzergeräten gesendet werden. Diese Berichte enthalten Daten zum seitenübergreifenden Nutzerverhalten und zu Conversions. Conversions (manchmal auch Attributionstrigger-Ereignisse genannt) und zugehörige Messwerte werden vom Werbetreibenden oder der Anzeigentechnologie definiert. Jeder Bericht wird verschlüsselt, um zu verhindern, dass Dritte auf die zugrunde liegenden Daten zugreifen.
- Zusammenfassbare Berichte
-
Ein verteiltes Ledger, das sich in beiden Koordinatoren befindet, das das zugewiesene Datenschutzbudget erfasst und die Regel „Keine Duplikate“ erzwingt. Dieser Datenschutzmechanismus befindet sich in den Koordinatoren und wird dort ausgeführt. Er sorgt dafür, dass keine Berichte über den Aggregationsdienst hinausgehen, die das zugewiesene Datenschutzbudget überschreiten.
Weitere Informationen zum Zusammenhang zwischen Batch-Strategien und aggregierten Berichten
- Budget für aggregierbare Berichte
-
Verweise auf das Budget, die dafür sorgen, dass einzelne Berichte nicht mehrmals verarbeitet werden.
- Zusammenfassungsdienst
-
Ein von AdTech betriebener Dienst, der aggregierbare Berichte verarbeitet, um einen Zusammenfassungsbericht zu erstellen.
Weitere Informationen zur Entstehungsgeschichte des Aggregationsdiensts finden Sie in unserem Erläuterungsartikel und in der vollständigen Liste der Begriffe.
- Bestätigung
-
Ein Mechanismus zur Authentifizierung der Softwareidentität, in der Regel mit kryptografischen Hash-Werten oder Signaturen. Bei der Attestierung für den Aggregationsdienst wird der Code, der in Ihrem von AdTech betriebenen Aggregationsdienst ausgeführt wird, mit dem Open-Source-Code abgeglichen.
- Beitrag zur Bindung
- Koordinator
-
Entitäten, die für die Schlüsselverwaltung und die Berichtserfassung verantwortlich sind. Ein Koordinator verwaltet eine Liste von Hashes der genehmigten Aggregationsdienstkonfigurationen und konfiguriert den Zugriff auf Entschlüsselungsschlüssel.
- Rauschen und Skalierung
-
Statistisches Rauschen, das Zusammenfassungsberichten während des Aggregationsprozesses hinzugefügt wird, um den Datenschutz zu wahren und dafür zu sorgen, dass die endgültigen Berichte anonymisierte Messinformationen enthalten.
Weitere Informationen zum additiven Rauschmechanismus, der aus der Laplace-Verteilung abgeleitet wird
- Ursprung der Berichterstellung
-
Das Rechtssubjekt, das aggregierbare Berichte empfängt, also Sie oder eine Anzeigentechnologie, die die Attribution Reporting API aufgerufen hat. Aggregierbare Berichte werden von Nutzergeräten an eine bekannte URL gesendet, die mit dem Ursprung der Meldung verknüpft ist. Der Ursprung der Berichte wird bei der Registrierung festgelegt.
- Freigegebene ID
-
Ein berechneter Wert, der aus
shared_info,reporting_origin,destination_site(nur Attribution Reporting API),source_registration-time(nur Attribution Reporting API),scheduled_report_timeund der Version besteht.Mehrere Berichte mit denselben Attributen im Feld
shared_infosollten dieselbe freigegebene ID haben. Gemeinsam genutzte IDs spielen bei der Berichtserfassung eine wichtige Rolle. - Zusammenfassender Bericht
-
Ein Berichtstyp für die Attribution Reporting API und die Private Aggregation API. Ein Zusammenfassungsbericht enthält aggregierte Nutzerdaten und kann detaillierte Conversion-Daten mit Rauschen enthalten. Zusammenfassende Berichte bestehen aus zusammengefassten Berichten. Sie bieten mehr Flexibilität und ein umfangreicheres Datenmodell als Berichte auf Ereignisebene, insbesondere für einige Anwendungsfälle wie Conversion-Werte.
- Vertrauenswürdige Ausführungsumgebung (TEE)
-
Eine sichere Konfiguration von Computerhardware und ‑software, die es externen Parteien ermöglicht, die genauen Versionen der Software zu prüfen, die auf dem Computer ausgeführt wird, ohne dass Sicherheitsrisiken bestehen. TEEs ermöglichen es externen Parteien, zu überprüfen, ob die Software genau das tut, was ihr Hersteller behauptet – nicht mehr und nicht weniger.
Weitere Informationen zu TEEs, die für die Privacy Sandbox-Vorschläge verwendet werden, finden Sie im Erläuterungsartikel zu Protected Audience API-Diensten und im Erläuterungsartikel zum Aggregationsdienst.
Workflow des Aggregationsdienstes
Der Aggregationsdienst erstellt Zusammenfassungsberichte mit detaillierten Conversion- und Reichweitendaten aus aggregierbaren Rohberichten. Der Ablauf der Berichterstellung umfasst die folgenden Schritte:
- Ein Browser ruft einen öffentlichen Schlüssel ab, um verschlüsselte Berichte zu generieren.
- Verschlüsselte aggregierbare Berichte werden an AdTech-Server gesendet.
- Der AdTech-Server bündelt Berichte im Avro-Format und sendet sie an den Aggregationsdienst.
- Ein Aggregation Worker ruft die zusammengefassten Berichte zum Entschlüsseln ab.
- Der Aggregation Worker ruft Entschlüsselungsschlüssel von einem Coordinator ab.
- Der Aggregation Worker entschlüsselt die Berichte für die Aggregation und fügt Rauschen hinzu.
- Der Aggregatable report accounting service (Dienst zur Abrechnung von aggregierbaren Berichten) prüft, ob genügend Privacy-Budget vorhanden ist, um einen Zusammenfassungsbericht für die angegebenen aggregierbaren Berichte zu erstellen.
- Der Aggregationsdienst sendet einen endgültigen Zusammenfassungsbericht.
Das folgende Diagramm zeigt den Aggregationsdienst in Aktion, von dem Zeitpunkt an, an dem Berichte von Web- und Mobilgeräten empfangen werden, bis zu dem Zeitpunkt, an dem ein Zusammenfassungsbericht vom Aggregationsdienst erstellt wird.
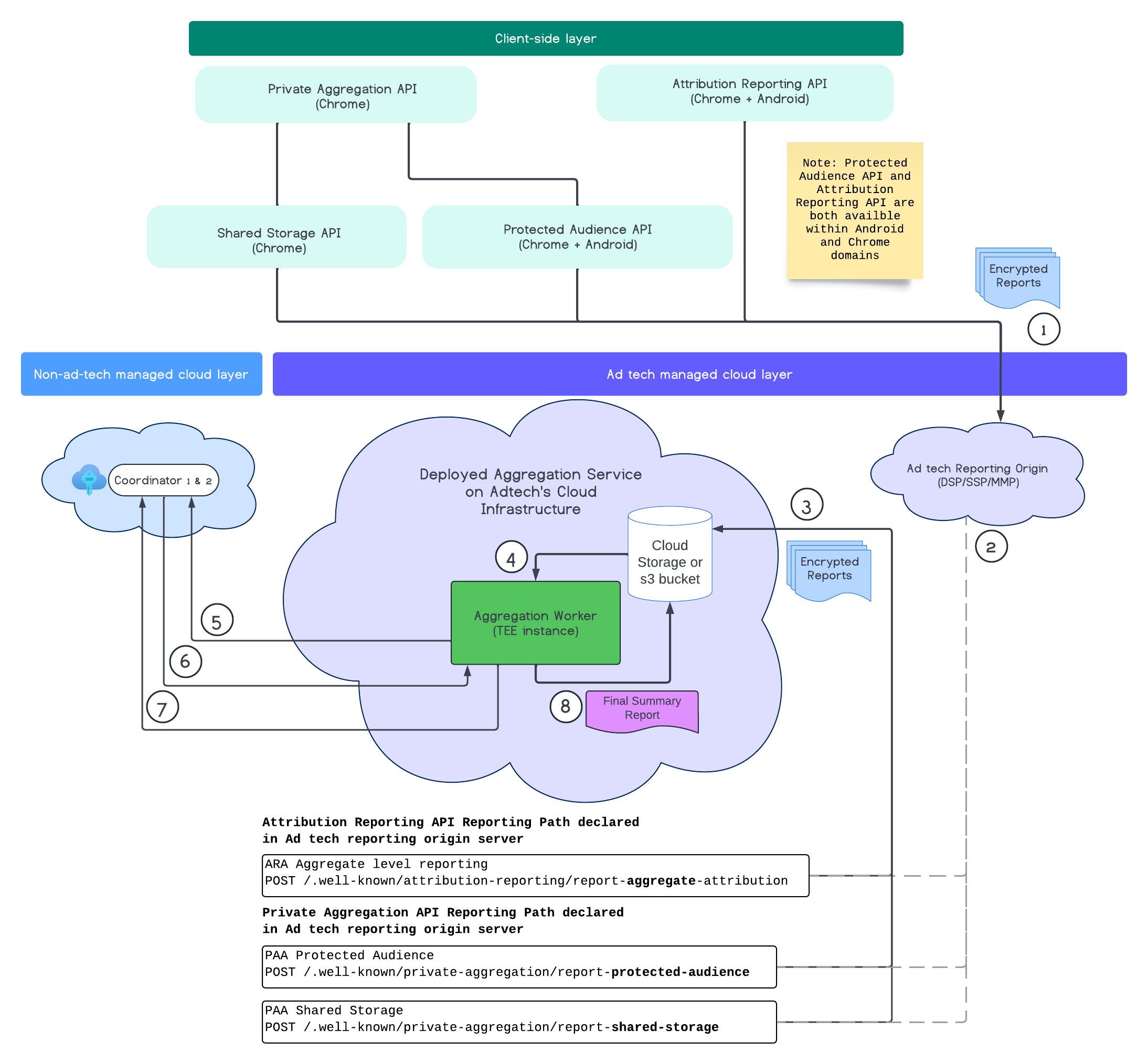
Zusammenfassend lässt sich sagen, dass mit der Attribution Reporting API oder der Private Aggregation API Berichte aus mehreren Browserinstanzen generiert werden. Chrome ruft einen öffentlichen Schlüssel, der alle sieben Tage rotiert wird, vom Key Hosting Service im Coordinator ab, um die Berichte zu verschlüsseln, bevor sie an den Ursprung für Ad-Tech-Berichte gesendet werden. Der Ursprung für AdTech-Berichte erfasst und konvertiert eingehende Berichte in das Avro-Format und sendet sie an den Aggregationsdienst. Wenn dann eine Batchanfrage an den Aggregationsdienst gesendet wird, ruft dieser Entschlüsselungsschlüssel vom Schlüssel-Hosting-Dienst ab, entschlüsselt die Berichte und aggregiert und anonymisiert sie, um einen Zusammenfassungsbericht zu erstellen, sofern genügend Datenschutzbudget dafür vorhanden ist.
Weitere Informationen zum Vorbereiten aggregierbarer Berichte finden Sie im Implementierungsabschnitt.
Batch-Verarbeitung von aggregierbaren Berichten
Der Meldevorgang wäre ohne den dafür vorgesehenen Ursprungsserver, den Sie während der Registrierung angegeben haben, nicht vollständig. Der Berichterstellungsursprung ist für das Erfassen, Transformieren und Batching von aggregierbaren Berichten sowie für die Vorbereitung des Sendens an Ihren Aggregationsdienst in Google Cloud oder Amazon Web Services verantwortlich. Weitere Informationen zum Vorbereiten von aggregierbaren Berichten
Cloud-Komponenten
Der Aggregationsdienst besteht aus mehreren Cloud-Dienstkomponenten. Sie verwenden die bereitgestellten Terraform-Skripts, um alle erforderlichen Cloud-Dienstkomponenten bereitzustellen und zu konfigurieren.

Frontend-Dienst
Verwalteter Cloud-Dienst:Cloud Function (Google Cloud) / API Gateway (Amazon Web Services)
Der Frontend-Dienst ist ein serverloses Gateway, das den primären Einstiegspunkt für Aggregation API-Aufrufe zum Erstellen von Jobs und zum Abrufen des Jobstatus darstellt. Es ist dafür verantwortlich, Anfragen von Nutzern des Aggregationsdienstes zu empfangen, Eingabeparameter zu validieren und die Planung des Aggregationsjobs zu initiieren.
Der Frontend-Dienst hat zwei verfügbare APIs:
| Endpunkt | Beschreibung |
|---|---|
createJob |
Mit dieser API wird ein Aggregationsdienst-Job ausgelöst. Zum Auslösen des Jobs sind Informationen wie Job-ID, Details zum Eingabespeicher, Details zum Ausgabespeicher und Berichterstellungsursprung erforderlich. |
getJob |
Diese API gibt den Status des Jobs mit der angegebenen Job-ID zurück. Sie enthält Informationen zum Status des Jobs, z. B. „Empfangen“, „Wird verarbeitet“ oder „Abgeschlossen“. Wenn der Job abgeschlossen ist, wird auch das Job-Ergebnis zurückgegeben, einschließlich aller Fehlermeldungen, die während der Job-Ausführung aufgetreten sind. |
Dokumentation zur Aggregation Service API
Jobwarteschlange
Verwalteter Cloud-Dienst:Pub/Sub (Google Cloud) / Amazon SQS (Amazon Web Services)
Die Jobwarteschlange ist eine Nachrichtenwarteschlange, die Jobanfragen für den Aggregationsdienst enthält. Der Frontend-Dienst fügt Jobanfragen in die Warteschlange ein, die dann von Aggregations-Workern verarbeitet werden.
Cloud-Speicher
Verwalteter Cloud-Dienst:Google Cloud Storage (Google Cloud) / Amazon S3 (Amazon Web Services)
Ein- und Ausgabedateien, die vom Aggregation Service verwendet werden, z. B. verschlüsselte Berichtsdateien und Ausgabezusammenfassungsberichte, werden in Cloud Storage gespeichert.
Job-Metadatendatenbank
Verwalteter Cloud-Dienst:Spanner (Google Cloud) / DynamoDB (Amazon Web Services)
In der Job-Metadatenbank wird der Status von Aggregationsjobs gespeichert und nachverfolgt. Darin werden Metadaten wie Erstellungszeit, angeforderte Zeit, Aktualisierungszeit und Status wie „Empfangen“, „Wird bearbeitet“ oder „Abgeschlossen“ aufgezeichnet. Aggregation Workers aktualisieren die Job-Metadatendatenbank im Laufe der Jobs.
Aggregation Worker
Managed Cloud Service:Compute Engine mit Confidential Space (Google Cloud) / Amazon Web Services EC2 mit Nitro Enclave (Amazon Web Services).
Ein Aggregation Worker verarbeitet Jobanfragen in der Job Queue und entschlüsselt die verschlüsselten Eingaben mit Schlüsseln, die er vom Key Generation and Distribution Service (KGDS) in Coordinators abruft. Um die Latenz bei der Jobverarbeitung zu minimieren, speichern Aggregation Workers Entschlüsselungsschlüssel für einen Zeitraum von acht Stunden im Cache und verwenden sie für alle Jobs, die sie verarbeiten.
Aggregation-Worker werden in einer Trusted Execution Environment (TEE)-Instanz ausgeführt. Ein Worker kann jeweils nur einen Job verarbeiten. Sie können mehrere Worker für die parallele Verarbeitung von Jobs konfigurieren, indem Sie die Autoscaling-Konfiguration festlegen. Wenn Autoscaling verwendet wird, wird die Anzahl der Worker dynamisch an die Anzahl der Nachrichten in der Job-Warteschlange angepasst. Sie können die Mindest- und Höchstanzahl an Workern für das Autoscaling über die Terraform-Umgebungsdatei konfigurieren. Weitere Informationen zum Autoscaling finden Sie in diesen Terraform-Scripts: Amazon Web Services oder Google Cloud.
Aggregation Workers rufen den Aggregatable Report Accounting Service für die Abrechnung von aggregierbaren Berichten auf. Dieser Dienst prüft, ob Jobs nur ausgeführt werden, wenn das Datenschutzbudgetlimit nicht überschritten wurde. Regel „Keine Duplikate“ Wenn das Budget verfügbar ist, wird ein Zusammenfassungsbericht mit den verrauschten Aggregaten erstellt. Weitere Informationen zur Abrechnung von aggregierbaren Berichten
Aggregation Workers aktualisieren Jobmetadaten in der Job Metadata Database. Dazu gehören Job-Rückgabecodes und Fehlerzähler für Berichte bei teilweisen Berichtsausfällen. Nutzer können den Status mit der getJob-API zum Abrufen des Jobstatus abrufen.
Eine detailliertere Beschreibung des Aggregationsdienstes finden Sie in dieser Erläuterung.
Nächste Schritte
Nachdem Sie nun wissen, wie der Aggregation Service funktioniert, können Sie diesem Leitfaden folgen, um Ihre eigene Instanz über Google Cloud oder Amazon Web Services bereitzustellen.