
Il servizio di aggregazione fornisce alle tecnologie pubblicitarie le informazioni sul rendimento necessarie per migliorare l'efficacia delle campagne con i clienti.
Questo documento tratta:
- Termini e concetti chiave
- Come funziona il servizio di aggregazione per fornirti dati dettagliati sulle conversioni e misurazioni della copertura dai report aggregabili non elaborati
- Panoramica concettuale del batching dei report aggregabili
- Panoramica concettuale dei componenti cloud
A chi è rivolto questo documento?
Questa pagina aiuta le tecnologie pubblicitarie e gli sviluppatori a capire in che modo le nostre API consentono una misurazione pubblicitaria efficace e rispettosa della privacy.
Questo documento presuppone che tu abbia familiarità con l'API Private Aggregation, l'API Attribution Reporting, l'API Protected Audience, l'API Shared Storage e gli ambienti di esecuzione attendibili.
Termini e concetti chiave
Prima di procedere, familiarizza con i termini chiave:
Glossario
- Ad tech
-
Una piattaforma pubblicitaria è un'azienda che fornisce servizi per pubblicare annunci.
- Report aggregabili
-
I report aggregabili sono report criptati inviati dai dispositivi dei singoli utenti. Questi report contengono dati sul comportamento e sulle conversioni degli utenti su più siti. Le conversioni (a volte chiamate eventi di attivazione dell'attribuzione) e le metriche associate sono definite dall'inserzionista o dall'ad tech. Ogni report è criptato per impedire a varie parti di accedere ai dati sottostanti.
- Contabilizzazione dei report aggregabili
-
Un ledger distribuito, presente in entrambi i coordinatori, che monitora il budget per la privacy allocato e applica la regola "Nessun duplicato". Si tratta del meccanismo di tutela della privacy, situato ed eseguito all'interno dei coordinatori, che garantisce che nessun report venga trasmesso al Servizio di aggregazione oltre il budget per la privacy allocato.
Scopri di più sul rapporto tra le strategie di raggruppamento e i report aggregabili.
- Budget di contabilità del report aggregabile
-
Riferimenti al budget che garantiscono che i singoli report non vengano elaborati più volte.
- Servizio di aggregazione
-
Un servizio gestito da ad tech che elabora report aggregabili per creare un report di riepilogo.
Scopri di più sulla storia del Servizio di aggregazione nel nostro articolo esplicativo e nell'elenco completo dei termini.
- Attestazione
-
Un meccanismo per autenticare l'identità del software, in genere con hash crittografici o firme. Per la proposta di servizio di aggregazione, l'attestazione corrisponde al codice eseguito nel servizio di aggregazione gestito da ad tech con il codice open source.
- Contributo di garanzia
- Coordinatore
-
Persone giuridiche responsabili della gestione delle chiavi e della contabilità dei report aggregabili. Un coordinatore gestisce un elenco di hash delle configurazioni del servizio di aggregazione approvate e configura l'accesso alle chiavi di decrittografia.
- Rumore e scalabilità
-
Rumore statistico aggiunto ai report di riepilogo durante la procedura di aggregazione per preservare la privacy e garantire che i report finali forniscano informazioni di misurazione anonimizzate.
Scopri di più sul meccanismo di rumore additivo, che viene estratto dalla distribuzione di Laplace.
- Origine della segnalazione
-
L'entità che riceve i report aggregabili, in altre parole tu o un fornitore di tecnologia pubblicitaria che ha chiamato l'API Attribution Reporting. I report aggregabili vengono inviati dai dispositivi degli utenti a un URL noto associato all'origine del report. L'origine report viene designata durante la registrazione.
- ID condiviso
-
Un valore calcolato composto da
shared_info,reporting_origin,destination_site(solo per l'API Attribution Reporting),source_registration-time(solo per l'API Attribution Reporting),scheduled_report_timee la versione.Più report che condividono gli stessi attributi nel campo
shared_infodevono avere lo stesso ID condiviso. Gli ID condivisi svolgono un ruolo importante nel reporting aggregabile. - Report di riepilogo
-
Un tipo di report dell'API Attribution Reporting e dell'API Private Aggregation. Un report di riepilogo include dati utente aggregati e può contenere dati sulle conversioni dettagliati con informazioni aggiuntive. I report di riepilogo sono costituiti da report aggregati. Offrono una maggiore flessibilità e forniscono un modello di dati più completo rispetto ai report a livello di evento, in particolare per alcuni casi d'uso come i valori di conversione.
- Trusted Execution Environment (TEE)
-
Una configurazione sicura dell'hardware e del software del computer che consente a terze parti di verificare le versioni esatte del software in esecuzione sulla macchina senza temere l'esposizione. I TEE consentono a terze parti di verificare che il software faccia esattamente ciò che afferma il produttore, né più né meno.
Per scoprire di più sui TEE utilizzati per le proposte di Privacy Sandbox, leggi la spiegazione dei servizi dell'API Protected Audience e la spiegazione del servizio di aggregazione.
Flusso di lavoro del servizio di aggregazione
Il servizio di aggregazione genera report di riepilogo dei dati dettagliati su conversioni e copertura a partire dai report aggregabili non elaborati. Il flusso di generazione dei report è composto dai seguenti passaggi:
- Un browser recupera una chiave pubblica per generare report criptati.
- I report aggregabili criptati vengono inviati ai server di tecnologia pubblicitaria.
- Il server di tecnologia pubblicitaria raggruppa i report (in formato Avro) e li invia al servizio di aggregazione.
- Un worker di aggregazione recupera i report aggregati da decriptare.
- Il worker di aggregazione recupera le chiavi di decriptazione da un coordinatore.
- Il worker di aggregazione decripta i report per l'aggregazione e l'aggiunta di rumore.
- Il servizio di contabilità dei report aggregabili verifica se è disponibile un budget di privacy sufficiente per generare un report di riepilogo per i report aggregabili specificati.
- Il servizio di aggregazione invia un report di riepilogo finale.
Il seguente diagramma mostra il servizio di aggregazione in azione, dal momento in cui i report vengono ricevuti da dispositivi web e mobili al momento in cui viene creato un report di riepilogo dal servizio di aggregazione.
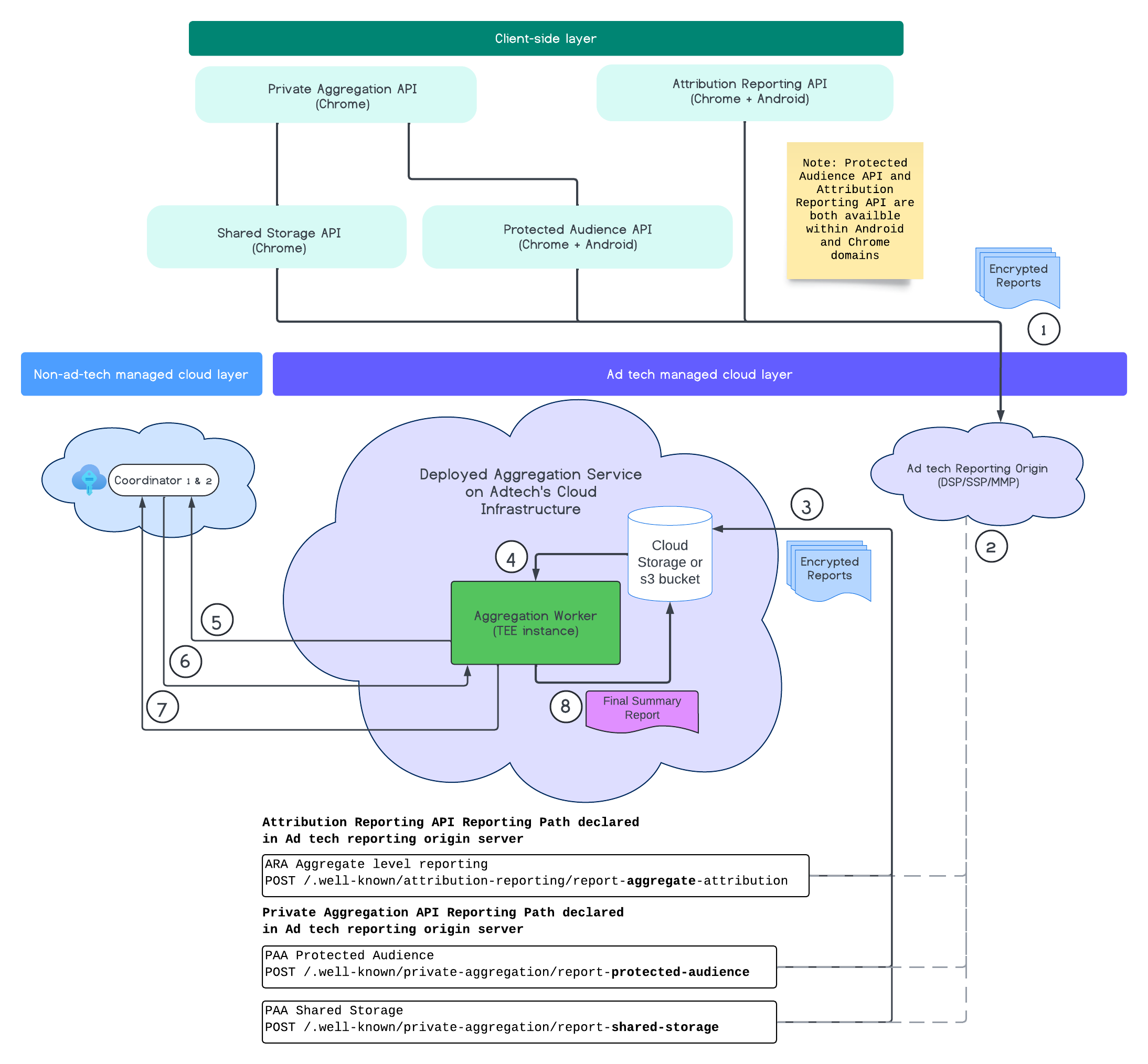
In sintesi, l'API Attribution Reporting o l'API Private Aggregation generano report da più istanze del browser. Chrome ottiene una chiave pubblica, ruotata ogni sette giorni, dal servizio di hosting delle chiavi nel coordinatore, per criptare i report prima di inviarli all'origine dei report di tecnologia pubblicitaria. L'origine dei report di tecnologia pubblicitaria raccoglie e converte i report in arrivo nel formato Avro e li invia al servizio di aggregazione. Quando una richiesta batch viene inviata al servizio di aggregazione, questo recupera le chiavi di decrittografia dal servizio di hosting delle chiavi, decrittografa i report e li aggrega e disturba per creare un report di riepilogo, a condizione che il budget per la privacy sia sufficiente per crearli.
Scopri di più su come preparare i report aggregabili nella sezione di implementazione.
Batching dei report aggregabili
Il flusso di generazione dei report non sarebbe completo senza l'aiuto del server di origine dei report designato, che hai specificato durante la procedura di registrazione. L'origine dei report è responsabile della raccolta, della trasformazione e del raggruppamento in batch dei report aggregabili e della loro preparazione per l'invio al servizio di aggregazione in Google Cloud o Amazon Web Services. Scopri di più su come preparare i report aggregabili.
Componenti cloud
Il servizio di aggregazione è composto da diversi componenti del servizio cloud. Utilizzi gli script Terraform forniti per eseguire il provisioning e configurare tutti i componenti necessari del servizio cloud.
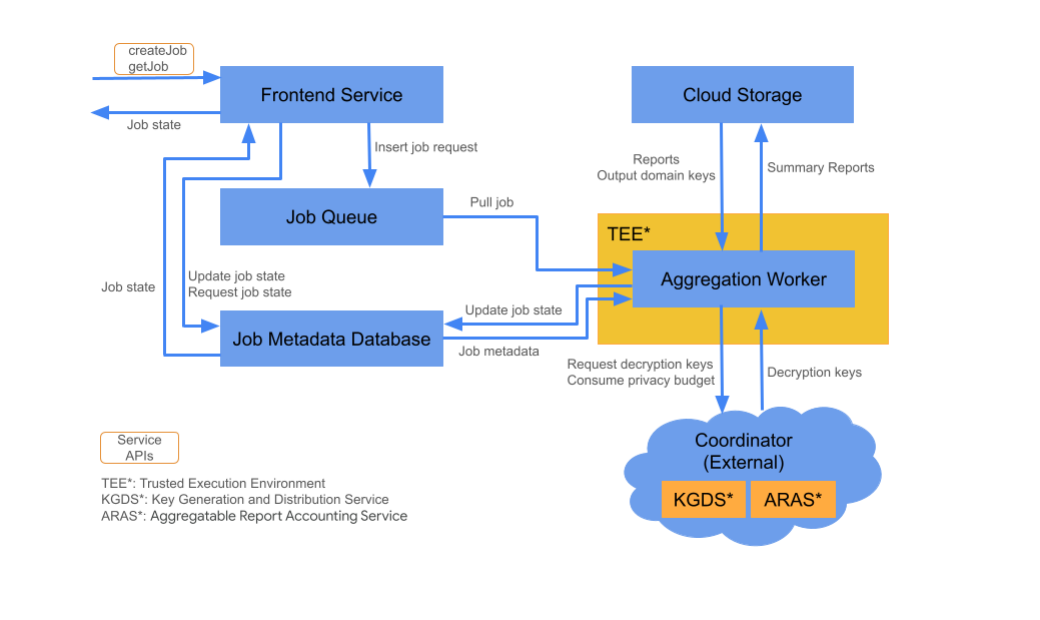
Servizio frontend
Servizio cloud gestito:Cloud Functions (Google Cloud) / API Gateway (Amazon Web Services)
Il servizio frontend è un gateway serverless che rappresenta il punto di accesso principale per le chiamate all'API Aggregation per la creazione di job e il recupero dello stato dei job. È responsabile della ricezione delle richieste degli utenti del servizio di aggregazione, della convalida dei parametri di input e dell'avvio della procedura di pianificazione dei job di aggregazione.
Il servizio frontend ha due API disponibili:
| Endpoint | Descrizione |
|---|---|
createJob |
Questa API attiva un job del servizio di aggregazione. Per attivare il job, sono necessarie informazioni quali ID job, dettagli dello spazio di archiviazione di input, dettagli dello spazio di archiviazione di output e origine dei report. |
getJob |
Questa API restituisce lo stato del job con un ID job specificato. Fornisce informazioni sullo stato del lavoro, ad esempio "Ricevuto", "In corso" o "Terminato". Se il job è terminato, restituisce anche il risultato, inclusi eventuali messaggi di errore riscontrati durante l'esecuzione. |
Consulta la documentazione dell'API Aggregation Service.
Coda dei job
Servizio cloud gestito:Pub/Sub (Google Cloud) / Amazon SQS (Amazon Web Services)
La coda dei job è una coda di messaggi contenente le richieste di job per il servizio di aggregazione. Il servizio frontend inserisce le richieste di lavoro nella coda, che vengono poi utilizzate dai worker di aggregazione che le elaborano.
Cloud Storage
Servizio cloud gestito:Google Cloud Storage (Google Cloud) / Amazon S3 (Amazon Web Services)
I file di input e di output utilizzati dal servizio di aggregazione, come i file di report criptati e i report di riepilogo dell'output, vengono conservati nell'archiviazione cloud.
Database dei metadati dei job
Servizio cloud gestito:Spanner (Google Cloud) / DynamoDB (Amazon Web Services)
Il database dei metadati dei job viene utilizzato per archiviare e monitorare lo stato dei job di aggregazione. Registra metadati come ora di creazione, ora richiesta, ora di aggiornamento e stato, ad esempio Ricevuto, In corso o Terminato. I worker di aggregazione aggiornano il database dei metadati dei job man mano che i job avanzano.
Worker di aggregazione
Servizio cloud gestito:Compute Engine con spazio confidenziale (Google Cloud) / Amazon Web Services EC2 con Nitro Enclave (Amazon Web Services).
Un worker di aggregazione elabora le richieste di job nella coda di job e decripta gli input criptati utilizzando le chiavi recuperate dal servizio di generazione e distribuzione delle chiavi (KGDS) nei coordinatori. Per ridurre al minimo la latenza di elaborazione dei job, i worker di aggregazione memorizzano nella cache le chiavi di decrittografia per un periodo di otto ore e le utilizzano nei job che elaborano.
I worker di aggregazione operano all'interno di un'istanza di Trusted Execution Environment (TEE). Un worker gestisce un solo job alla volta. Puoi configurare più worker per elaborare i job in parallelo impostando la configurazione di scalabilità automatica. Se utilizzata, la scalabilità automatica regola dinamicamente il numero di worker in base al numero di messaggi nella coda dei job. Puoi configurare il numero minimo e massimo di worker per la scalabilità automatica tramite il file di ambiente Terraform. Per ulteriori informazioni sulla scalabilità automatica, consulta questi script Terraform: Amazon Web Services o Google Cloud.
I worker di aggregazione chiamano il servizio di contabilità dei report aggregabili per la contabilità dei report aggregabili. Questo servizio verifica che i job vengano eseguiti solo se il limite del budget per la privacy non è stato superato. (vedi la regola"Nessun duplicato"). Se il budget è disponibile, viene generato un report di riepilogo utilizzando gli aggregati con rumore. Leggi ulteriori dettagli sulla contabilità dei report aggregabili.
I worker di aggregazione aggiornano i metadati dei job nel database dei metadati dei job. Queste informazioni includono i codici di ritorno del job e i contatori degli errori del report in caso di errori parziali del report. Gli utenti possono recuperare lo stato utilizzando l'API di recupero dello stato del job getJob.
Consulta questa spiegazione per una descrizione più dettagliata del servizio di aggregazione.
Passaggi successivi
Ora che sai come funziona il servizio di aggregazione, segui la guida introduttiva per eseguire il deployment della tua istanza tramite Google Cloud o Amazon Web Services.