
Aggregation Service מספק לטכנולוגיות פרסום את התובנות לגבי הביצועים שדרושות כדי לשפר את יעילות הקמפיין עבור הלקוחות.
המסמך הזה כולל:
- מושגים והגדרות חשובים
- איך Aggregation Service פועל כדי לספק לכם נתוני המרות מפורטים ומדידת היקף החשיפה מדוחות גולמיים שניתנים לצבירה
- סקירה כללית של הוספת דוחות מצטברים לאצווה
- סקירה כללית על מושגים של רכיבי Cloud
למי המסמך הזה מיועד?
בדף הזה מוסבר לספקי טכנולוגיות פרסום ולמפתחים איך ממשקי ה-API שלנו מאפשרים מדידה יעילה של פרסום תוך שמירה על פרטיות המשתמשים.
במסמך הזה אנחנו מניחים שאתם מכירים את Private Aggregation API, Attribution Reporting API, Protected Audience API, Shared Storage ו-Trusted Execution Environments.
מונחים ומושגים מרכזיים
לפני שממשיכים, כדאי להכיר את המונחים הבאים:
מילון מונחים
- פרסום דיגיטלי
-
פלטפורמת מודעות היא חברה שמספקת שירותים להצגת מודעות.
- דוחות שניתן לצבור
-
דוחות שאפשר לצבור הם דוחות מוצפנים שנשלחים ממכשירים של משתמשים ספציפיים. הדוחות האלה מכילים נתונים על המרות ועל התנהגות משתמשים באתרים שונים. המפרסם או חברת טכנולוגיית הפרסום מגדירים את ההמרות (שנקראות לפעמים אירועי הפעלה של שיוך) והמדדים המשויכים. כל דוח מוצפן כדי למנוע מגורמים שונים לגשת לנתונים הבסיסיים.
- התחשבות בדוחות שניתן לצבור
-
ספר חשבון מבוזבז שנמצא בשני התאמים, ומעקב אחרי תקציב הפרטיות שהוקצה ואכיפת הכלל'אין כפילויות'. זהו המנגנון לשמירה על הפרטיות, שנמצא ומופעל בתוך מנהלים, ומבטיח שאף דוח לא יעבור דרך שירות הצבירה מעבר לתקציב הפרטיות שהוקצה.
מידע נוסף על הקשר בין שיטות ארגון קבוצות לבין דוחות שניתן לצבור
- תקציב חשבונאי של דוח שניתן לצבירה
-
הפניות לתקציב שמבטיחות שלא יתבצע עיבוד של דוחות ספציפיים יותר מפעם אחת.
- Aggregation Service
-
שירות שמופעל על ידי טכנולוגיית פרסום, שמטפל בדוחות שניתן לצבור כדי ליצור דוח סיכום.
מידע נוסף על הרקע של שירות הצבירה זמין במאמר ההסבר וברשימת התנאים המלאה.
- הצהרה
-
מנגנון לאימות הזהות של תוכנה, בדרך כלל באמצעות חתימה קריפטוגרפית או גיבוב קריפטוגרפית. בהצעה לשירות המצטבר, האימות מתבצע על ידי התאמה של הקוד שפועל בשירות המצטבר שמופעל על ידי חברת טכנולוגיית הפרסום לקוד בקוד המקור הפתוח.
- הדבקה של תרומות
- רכז
-
ישויות שאחראיות לניהול מפתחות ולניהול חשבונות של דוחות שניתן לצבור. רכז שומר רשימה של גיבובים של הגדרות שירות שאושרו, ומגדיר את הגישה למפתחות הפענוח.
- רעש ושינוי גודל
-
רעש סטטיסטי שנוסף לדוחות הסיכום במהלך תהליך הצבירה, כדי לשמור על הפרטיות ולוודא שהדוחות הסופיים כוללים נתוני מדידה אנונימיים.
מידע נוסף על מנגנון רעשי תוספת, שמבוסס על התפלגות Laplace
- מקור הדיווח
-
הישות שמקבלת דוחות שניתן לצבור – כלומר, אתם או חברת טכנולוגיית הפרסום שהפעילה את Attribution Reporting API. דוחות שניתן לצבור נשלחים ממכשירי המשתמשים לכתובת URL ידועה שמשויכת למקור הדיווח. מקור הדיווח מוגדר במהלך ההרשמה.
- מזהה משותף
-
ערך מחושב שמורכב מ-
shared_info,reporting_origin,destination_site(ל-Attribution Reporting API בלבד),source_registration-time(ל-Attribution Reporting API בלבד),scheduled_report_timeוגרסת ה-API.לדוחות שחולקים את אותם מאפיינים בשדה
shared_infoצריך להיות אותו מזהה משותף. למזהים משותפים יש תפקיד חשוב בדיווח על נתונים מצטברים. - דוח סיכום
-
סוג דוח של Attribution Reporting API ו-Private Aggregation API. דוח סיכום כולל נתוני משתמשים מצטברים, ויכול להכיל נתוני המרות מפורטים עם רעש נוסף. דוחות הסיכום מורכבים מדוחות צבירה. הם מאפשרים גמישות רבה יותר ומספקים מודל נתונים עשיר יותר מאשר דיווח ברמת האירוע, במיוחד בתרחישי שימוש מסוימים כמו ערכי המרות.
- סביבת מחשוב אמינה (TEE)
-
תצורה מאובטחת של חומרה ותוכנה במחשב, שמאפשרת לצדדים חיצוניים לאמת את הגרסאות המדויקות של התוכנות שפועלות במכונה בלי חשש לחשיפת המידע. סביבות TEE מאפשרות לצדדים חיצוניים לוודא שהתוכנה עושה בדיוק את מה שמפתח התוכנה טוען שהיא עושה – לא יותר ולא פחות.
למידע נוסף על סביבות TEE שמשמשות להצעות של 'ארגז החול לפרטיות', אפשר לקרוא את הסבר על שירותי Protected Audience API ואת הסבר על שירות האגרגציה.
תהליך העבודה של Aggregation Service
Aggregation Service יוצר דוחות סיכום של נתונים מפורטים על המרות והיקף חשיפה מדוחות גולמיים שניתן לצבור. תהליך הפקת הדוח כולל את השלבים הבאים:
- דפדפן מאחזר מפתח ציבורי כדי ליצור דוחות מוצפנים.
- דוחות עם נתונים שאפשר לצבור מוצפנים ונשלחים לשרתים של טכנולוגיית הפרסום.
- השרת של טכנולוגיית הפרסום מחלק את הדוחות (בפורמט avro) לקבוצות ושולח אותם אל Aggregation Service.
- תהליך Aggregation Worker מאחזר את הדוחות המצטברים כדי לפענח אותם.
- ה-Aggregation Worker מאחזר מפתחות פענוח מ-Coordinator.
- ה-Aggregation Worker מפענח את הדוחות לצורך צבירה והוספת רעש.
- שירות החשבונאות של הדוחות הניתנים לצבירה בודק אם יש מספיק מכסת פרטיות כדי ליצור דוח סיכום עבור הדוחות הניתנים לצבירה.
- Aggregation Service שולח דוח סיכום סופי.
בתרשים הבא אפשר לראות את Aggregation Service בפעולה, מהרגע שבו מתקבלים דוחות ממכשירים ניידים ומאתרים, ועד לרגע שבו נוצר דוח סיכום על ידי Aggregation Service.
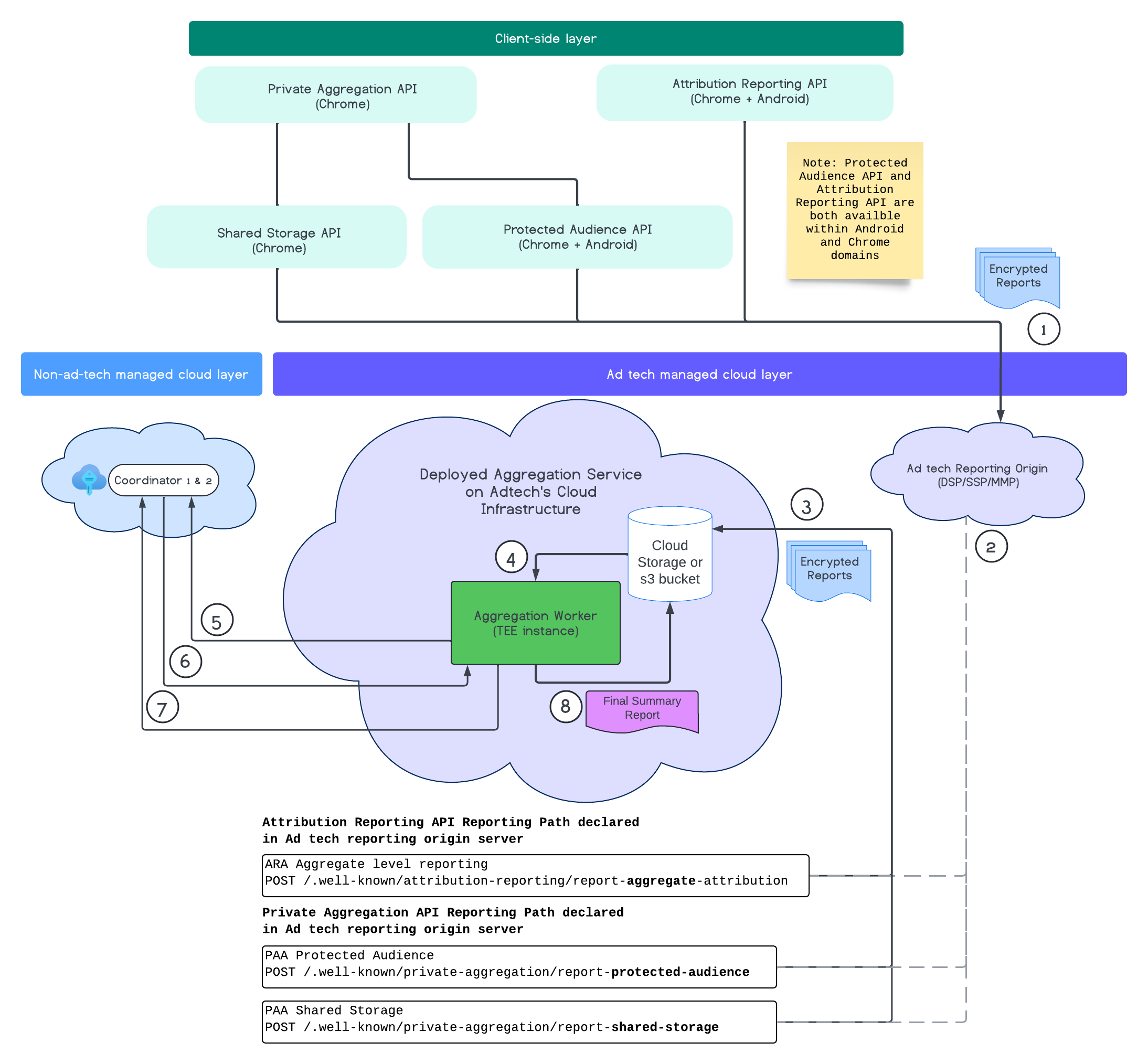
לסיכום, Attribution Reporting API או Private Aggregation API יוצרים דוחות מכמה מופעים של דפדפן. Chrome מקבל מפתח ציבורי, שמתחלף כל שבעה ימים, משירות אירוח המפתחות בתיאום, כדי להצפין את הדוחות לפני שליחתם למקור הדיווח של טכנולוגיית הפרסום. מקור הדיווח של טכנולוגיית הפרסום אוסף וממיר דוחות נכנסים לפורמט avro, ושולח אותם ל-Aggregation Service. כשבקשה לחבילת דוחות נשלחת אל Aggregation Service, השירות מאחזר מפתחות פענוח מ-Key Hosting Service, מפענח את הדוחות, מצטבר אותם ומוסיף להם רעש כדי ליצור דוח סיכום, כל עוד יש מספיק תקציב פרטיות כדי ליצור אותם.
בקטע ההטמעה מוסבר איך להכין דוחות מצטברים.
צירוף דוחות שאפשר לצבור
תהליך הדיווח לא יהיה שלם בלי העזרה של שרת המקור שמוגדר לדיווח, שציינתם במהלך תהליך ההרשמה. מקור הדיווח אחראי לאיסוף, לשינוי ולקיבוץ של דוחות שניתנים לצבירה, ולהכנתם לשליחה לשירות הצבירה ב-Google Cloud או ב-Amazon Web Services. מידע נוסף על הכנת דוחות שאפשר לצבור
רכיבי ענן
Aggregation Service מורכב מכמה רכיבי שירות ענן. אתם משתמשים בסקריפטים של Terraform שסופקו כדי להקצות ולהגדיר את כל רכיבי שירותי הענן הנדרשים.
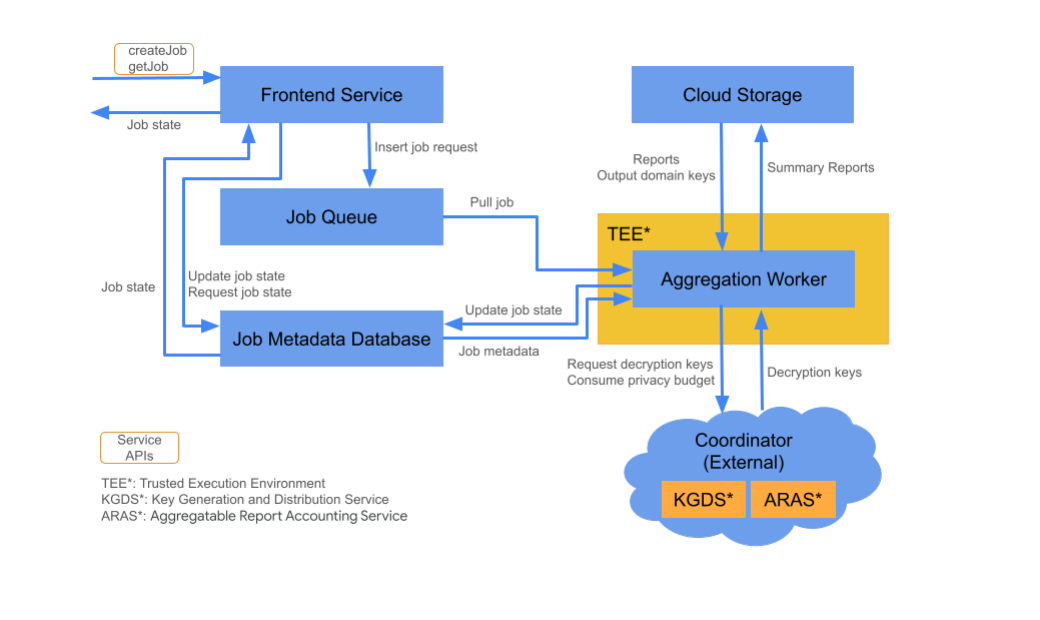
שירות לקצה הקדמי
שירות ענן מנוהל: Cloud Function (Google Cloud) / API Gateway (Amazon Web Services)
שירות ה-Frontend הוא שער ללא שרת שמשמש כנקודת הכניסה הראשית לקריאות ל-Aggregation API ליצירת משימות ולאחזור של מצב המשימות. הוא אחראי לקבלת בקשות ממשתמשי Aggregation Service, לאימות פרמטרים של קלט ולהתחלת תהליך התזמון של משימת הצבירה.
לשירות Frontend יש שני ממשקי API זמינים:
| נקודת קצה | תיאור |
|---|---|
createJob |
ממשק ה-API הזה מפעיל עבודה של Aggregation Service. כדי להפעיל את העבודה, צריך לספק מידע כמו מזהה העבודה, פרטי אחסון של קלט, פרטי אחסון של פלט ומקור הדיווח. |
getJob |
ה-API הזה מחזיר את הסטטוס של העבודה עם מזהה העבודה שצוין. הוא מספק מידע על מצב העבודה, כמו 'התקבל', 'בתהליך' או 'הסתיים'. אם העבודה הסתיימה, היא מחזירה גם את תוצאת העבודה, כולל הודעות שגיאה שהתקבלו במהלך ביצוע העבודה. |
אפשר לעיין במאמרי העזרה של Aggregation Service API.
תור משימות
שירות ענן מנוהל: Pub/Sub (Google Cloud) / Amazon SQS (Amazon Web Services)
תור המשימות הוא תור הודעות שמכיל בקשות למשימות עבור Aggregation Service. השירות לקצה הקדמי מוסיף בקשות לעיבוד נתונים לתור, ואז הן נצרכות על ידי Aggregation Workers שמעבדים אותן.
אחסון בענן
שירות ענן מנוהל: Google Cloud Storage (Google Cloud) / Amazon S3 (Amazon Web Services)
קבצי הקלט והפלט שבהם משתמשים בשירות הצבירה, כמו קבצי דוחות מוצפנים ודוחות סיכום של פלט, נשמרים באחסון בענן.
מסד נתונים של מטא-נתונים של משרות
שירות ענן מנוהל: Spanner (Google Cloud) / DynamoDB (Amazon Web Services)
מסד הנתונים של מטא-נתונים של משימות משמש לאחסון ולמעקב אחרי הסטטוס של משימות צבירה. הוא מתעד מטא-נתונים כמו זמן היצירה, זמן הבקשה, זמן העדכון והמצב, למשל Received (התקבלה), In Progress (בתהליך) או Finished (הסתיימה). תהליך העדכון של מסד הנתונים של מטא-נתוני המשימות מתבצע על ידי Aggregation Workers ככל שהמשימות מתקדמות.
Aggregations Worker
שירות ענן מנוהל: Compute Engine עם סביבה פרטית (Google Cloud) / Amazon Web Services EC2 עם Nitro Enclave (Amazon Web Services).
תהליך Aggregation Worker מעבד בקשות למשימות בתור המשימות ומפענח את נתוני הקלט המוצפנים באמצעות מפתחות שהוא מאחזר משירות יצירת המפתחות והפצתם (KGDS) ב-Coordinators. כדי לצמצם את זמן האחזור של עיבוד המשימות, עובדי הצבירה שומרים במטמון מפתחות פענוח למשך שמונה שעות, ומשתמשים בהם במשימות שהם מעבדים.
ה-Aggregation Workers פועלים בתוך מופע של סביבת מחשוב אמינה (TEE). כל worker מטפל רק במשימה אחת בכל פעם. אפשר להגדיר כמה עובדים לעיבוד משימות במקביל על ידי הגדרת תצורת שינוי הגודל האוטומטי. אם משתמשים בה, התכונה 'שינוי גודל אוטומטי' משנה באופן דינמי את מספר העובדים בהתאם למספר ההודעות בתור המשימות. אפשר להגדיר את המספר המינימלי והמקסימלי של העובדים להתאמה אוטומטית לעומס באמצעות קובץ הסביבה של Terraform. מידע נוסף על שינוי גודל אוטומטי זמין בסקריפטים של Terraform: Amazon Web Services או Google Cloud.
תהליכי העבודה של הצבירה קוראים לשירות ניהול השימוש בדוחות הנתונים הנצברים כדי לנהל את השימוש בדוחות הנתונים הנצברים. השירות הזה מוודא שהמשימות יופעלו רק אם לא חרגתם ממגבלת תקציב הפרטיות. (ראו כלל 'ללא כפילויות'). אם התקציב זמין, מופק דוח סיכום באמצעות הצבירות עם הרעש. מידע נוסף על הנהלת חשבונות של דוחות מצטברים
תהליכי העבודה של הצבירה מעדכנים את המטא-נתונים של המשימה במסד הנתונים של המטא-נתונים של המשימה. המידע הזה כולל קודי החזרה של עבודות ומונים של שגיאות בדוחות במקרה של כשלים חלקיים בדוחות. המשתמשים יכולים לאחזר את המצב באמצעות getJob job state retrieval API.
במאמר הזה מוסבר בפירוט על Aggregation Service.
השלבים הבאים
עכשיו, אחרי שהבנתם איך פועל שירות הצבירה, תוכלו לעיין במדריך לתחילת העבודה כדי לפרוס מופע משלכם דרך Google Cloud או Amazon Web Services.