
集計サービスは、広告技術プロバイダが顧客と協力してキャンペーンの効果を高めるために必要なパフォーマンスに関する分析情報を提供します。
このドキュメントでは、次の内容について説明します。
- 主な用語とコンセプト
- 集計サービスの仕組み: 詳細なコンバージョン データとリーチ測定を未加工の集計可能レポートから取得する
- 集計可能レポートのバッチ処理のコンセプトの概要
- Cloud コンポーネントのコンセプトの概要
このドキュメントの対象者
このページでは、広告技術プロバイダやデベロッパーが、Google の API を使用して効果的かつプライバシーを保護した広告測定を実現する方法について説明します。
このドキュメントは、Private Aggregation API、Attribution Reporting API、Protected Audience API、Shared Storage、Trusted Execution Environments について理解していることを前提としています。
主な用語と概念
先に進む前に、主な用語について理解しておきましょう。
用語集
- アドテック
-
広告プラットフォームとは、広告を配信するためのサービスを提供している企業です。
- 集計可能レポート
-
集計可能レポートは、個々のユーザーのデバイスから送信される暗号化されたレポートです。これらのレポートには、クロスサイトのユーザー行動とコンバージョンに関するデータが含まれます。コンバージョン(アトリビューション トリガー イベントと呼ばれることもあります)と関連する指標は、広告主または広告テクノロジーによって定義されます。各レポートは暗号化され、さまざまな関係者が基盤となるデータにアクセスできないようにしています。
詳しくは、集計可能なレポートについての記事をご覧ください。
- 集計可能レポートのアカウンティング
-
両方のコーディネーターにある分散レジャー。割り当てられたプライバシー バジェットを追跡し、「重複なし」ルールを適用します。これは、コーディネーター内に配置され、実行されるプライバシー保護メカニズムです。これにより、割り当てられたプライバシー バジェットを超えるレポートが集計サービスに渡されないようにします。
詳しくは、バッチ処理戦略と集計可能なレポートの関係をご覧ください。
- 集計可能レポートのアカウンティング予算
-
個々のレポートが複数回処理されないようにする予算への参照。
- 集計サービス
-
集計可能レポートを処理して概要レポートを作成する、広告テクノロジー運営のサービス。
集約サービスの背景については、説明と利用規約の全文リストをご覧ください。
- 宣誓
-
通常は暗号ハッシュまたは署名を使用して、ソフトウェアの ID を認証するメカニズム。集計サービスの提案では、構成証明は、広告テクノロジーが運用する集計サービスで実行されているコードとオープンソース コードを照合します。
- 貢献度ボンディング
- コーディネーター
-
鍵の管理と集計可能なレポートの処理を担当するエンティティ。コーディネーターは、承認済みの集計サービス構成のハッシュのリストを維持し、復号鍵へのアクセスを構成します。
- ノイズとスケーリング
-
集計プロセス中に概要レポートに追加される統計ノイズ。プライバシーを保護し、最終レポートで匿名化された測定情報を提供できるようにします。
ラプラス分布から取得される加算ノイズ メカニズムの詳細を確認する。
- レポートの送信元
-
集計可能レポートを受信するエンティティ(つまり、Attribution Reporting API を呼び出したお客様または広告テクノロジー)。集計可能レポートは、ユーザー デバイスから、レポート送信元に関連付けられた既知の URL に送信されます。報告元は登録時に指定します。
- 共有 ID
-
shared_info、reporting_origin、destination_site(Attribution Reporting API のみ)、source_registration-time(Attribution Reporting API のみ)、scheduled_report_time、バージョンで構成される計算値。shared_infoフィールドで同じ属性を共有する複数のレポートには、同じ共有 ID を設定する必要があります。共有 ID は、集計可能レポートのアカウンティングで重要な役割を果たします。詳しくは、信頼できるサーバーについての記事をご覧ください。
- 概要レポート
-
Attribution Reporting API と Private Aggregation API のレポート タイプ。サマリー レポートには、集計されたユーザーデータが含まれます。また、ノイズが追加された詳細なコンバージョン データも含まれる場合があります。概要レポートは集計レポートで構成されます。イベントレベル レポートよりも柔軟性が高く、より豊富なデータモデルを提供します。特に、コンバージョン値などのユースケースではその効果が顕著です。
- 高信頼実行環境(TEE)
-
コンピュータのハードウェアとソフトウェアの安全な構成。これにより、外部の関係者は、漏洩を恐れずにマシンで実行されているソフトウェアの正確なバージョンを確認できます。これにより外部関係者は、ソフトウェア メーカーが主張している動作を、ソフトウェアが、それ以上でもそれ以下でもなく正確に実行していることを確認できます。
プライバシー サンドボックスの提案で使用される TEE について詳しくは、Protected Audience API サービスの説明と集計サービスの説明をご覧ください。
集計サービスのワークフロー
集計サービスは、未加工の集計可能レポートから、詳細なコンバージョンとリーチのデータの概要レポートを生成します。レポート生成フローは、次のステップで構成されます。
- ブラウザは公開鍵を取得して暗号化されたレポートを生成します。
- 暗号化された集計可能レポートが広告テクノロジー サーバーに送信されます。
- 広告テクノロジー サーバーがレポート(avro 形式)をバッチ処理し、集計サービスに送信します。
- 集計ワーカーが、復号する集計レポートを取得します。
- 集計ワーカーは、コーディネーターから復号鍵を取得します。
- 集計ワーカーが、集計とノイズ付加のためにレポートを復号します。
- 集計可能レポート アカウンティング サービスは、指定された集計可能レポートの概要レポートを生成するのに十分なプライバシー バジェットがあるかどうかを確認します。
- 集計サービスが最終的な概要レポートを送信します。
次の図は、ウェブやモバイル デバイスからレポートが受信されてから、集計サービスによって概要レポートが作成されるまでの、集計サービスの動作を示しています。
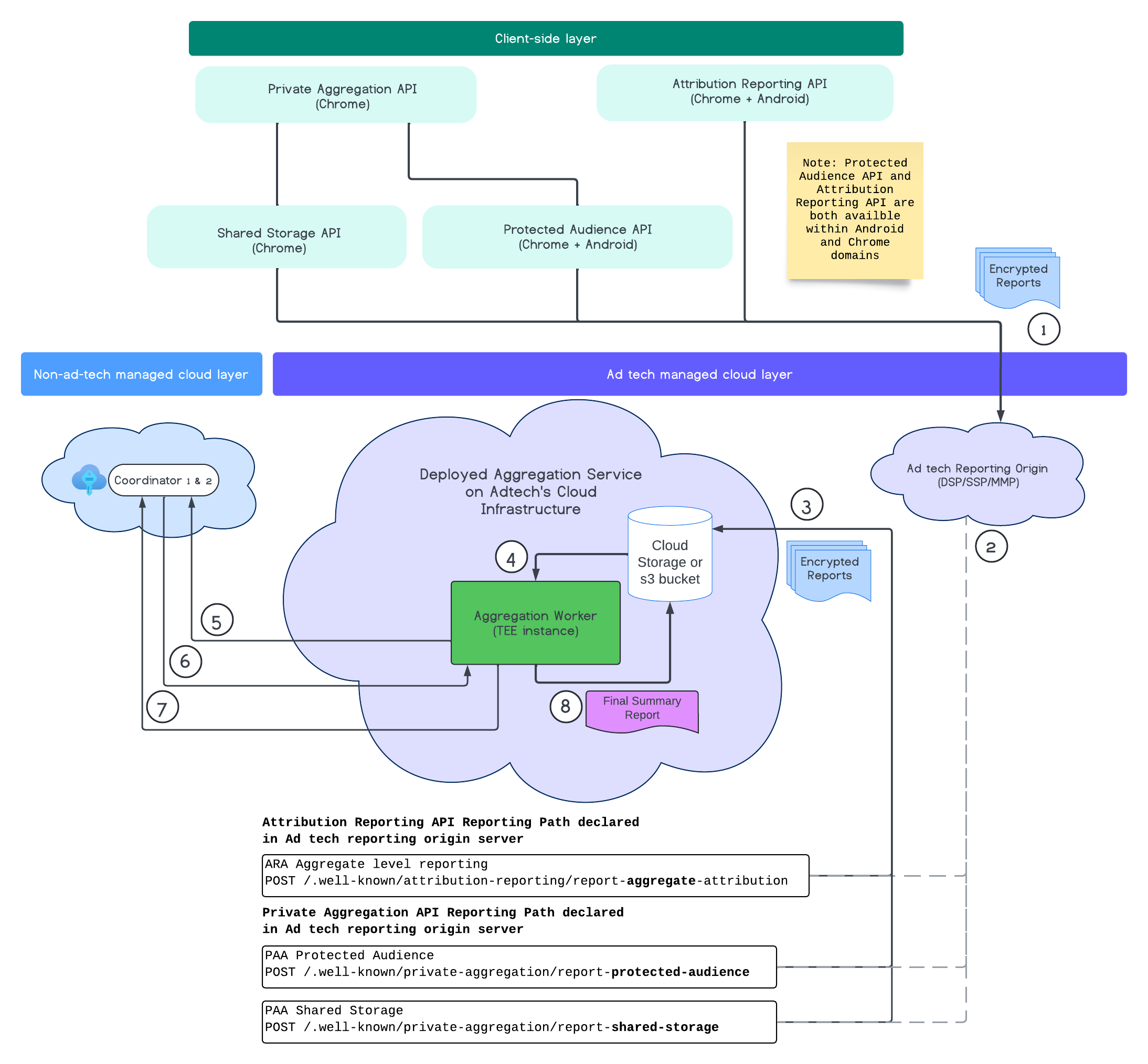
要するに、Attribution Reporting API または Private Aggregation API は、複数のブラウザ インスタンスからレポートを生成します。Chrome は、コーディネーターの Key Hosting Service から 7 日ごとにローテーションされる公開鍵を取得し、レポートを暗号化してから広告テクノロジーのレポート作成元に送信します。広告テクノロジーのレポート作成元は、受信したレポートを収集して avro 形式に変換し、集計サービスに送信します。バッチ リクエストが Aggregation Service に送信されると、Key Hosting Service から復号鍵が取得され、レポートが復号されます。プライバシー バジェットが十分にあれば、レポートが集計され、ノイズが追加されて概要レポートが作成されます。
集計可能なレポートを準備する方法については、実装セクションをご覧ください。
集計可能レポートのバッチ処理
レポート フローは、登録プロセスで指定した指定レポート配信元サーバーの助けなしには完了しません。レポート作成元は、集計可能レポートの収集、変換、バッチ処理を行い、Google Cloud または Amazon Web Services の集計サービスに送信する準備を行います。集計可能なレポートの準備方法について詳しくは、こちらをご覧ください。
クラウド コンポーネント
集計サービスは、複数のクラウド サービス コンポーネントで構成されています。提供された Terraform スクリプトを使用して、必要なすべてのクラウド サービス コンポーネントをプロビジョニングして構成します。
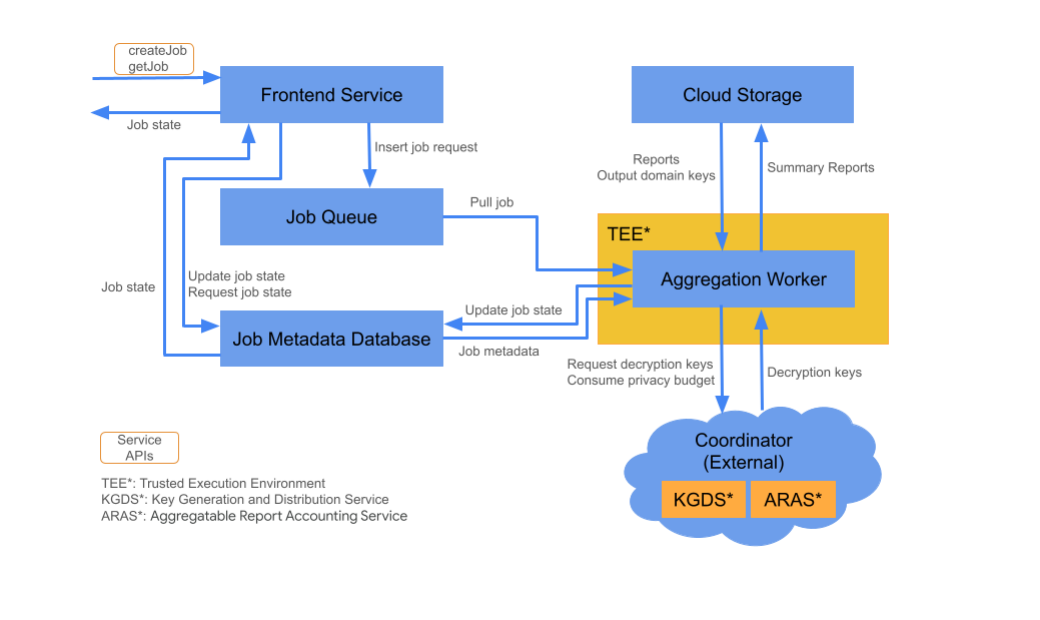
フロントエンド サービス
マネージド クラウド サービス: Cloud Functions(Google Cloud)/ API Gateway(Amazon Web Services)
フロントエンド サービスは、ジョブの作成とジョブの状態の取得のための Aggregation API 呼び出しのプライマリ エントリ ポイントとなるサーバーレス ゲートウェイです。これは、集計サービス ユーザーからのリクエストの受信、入力パラメータの検証、集計ジョブのスケジューリング プロセスの開始を担当します。
Frontend Service には、次の 2 つの API があります。
| エンドポイント | 説明 |
|---|---|
createJob |
この API は、集計サービス ジョブをトリガーします。ジョブをトリガーするには、ジョブ ID、入力ストレージの詳細、出力ストレージの詳細、レポートの送信元などの情報が必要です。 |
getJob |
この API は、指定されたジョブ ID を持つジョブのステータスを返します。ジョブの状態(「受信済み」、「進行中」、「完了」など)に関する情報が提供されます。ジョブが完了している場合は、ジョブの実行中に発生したエラー メッセージを含むジョブの結果も返します。 |
集計サービス API ドキュメントをご覧ください。
ジョブキュー
マネージド クラウド サービス: Pub/Sub(Google Cloud)/ Amazon SQS(Amazon Web Services)
ジョブキューは、集計サービスに対するジョブ リクエストを含むメッセージ キューです。フロントエンド サービスは、ジョブ リクエストをキューに挿入します。このキューは、ジョブ リクエストを処理する集計ワーカーによって使用されます。
クラウド ストレージ
マネージド クラウド サービス: Google Cloud Storage(Google Cloud)/ Amazon S3(Amazon Web Services)
暗号化されたレポート ファイルや出力サマリー レポートなど、集計サービスで使用される入力ファイルと出力ファイルは、クラウド ストレージに保存されます。
ジョブ メタデータ データベース
マネージド クラウド サービス: Spanner(Google Cloud)/ DynamoDB(Amazon Web Services)
ジョブ メタデータ データベースは、集計ジョブのステータスを保存して追跡するために使用されます。作成時間、リクエスト時間、更新時間、状態(Received、In Progress、Finished など)などのメタデータを記録します。集計ワーカーは、ジョブの進行に応じてジョブ メタデータ データベースを更新します。
集計ワーカー
マネージド クラウド サービス: Confidential Space を使用した Compute Engine(Google Cloud)/ Nitro Enclave を使用した Amazon Web Services EC2(Amazon Web Services)。
集計ワーカーは、ジョブキュー内のジョブ リクエストを処理し、コーディネーターのキー生成および配布サービス(KGDS)から取得したキーを使用して暗号化された入力を復号します。ジョブ処理のレイテンシを最小限に抑えるため、集計ワーカーは復号鍵を 8 時間キャッシュに保存し、処理するジョブ全体で使用します。
集計ワーカーは、高信頼実行環境(TEE)インスタンス内で動作します。ワーカーは一度に 1 つのジョブのみを処理します。自動スケーリング構成を設定することで、複数のワーカーがジョブを並行して処理するように構成できます。自動スケーリングを使用すると、ジョブキュー内のメッセージ数に応じてワーカーの数が動的に調整されます。Terraform 環境ファイルを使用して、自動スケーリングのワーカーの最小数と最大数を構成できます。自動スケーリングの詳細については、Terraform スクリプト(Amazon Web Services または Google Cloud)をご覧ください。
集計ワーカーは、集計可能レポートのアカウンティングのために集計可能レポート アカウンティング サービスを呼び出します。このサービスは、プライバシー バジェットの上限を超えていない場合にのみジョブが実行されることを確認します。(「重複なし」ルールを参照)。予算が利用可能な場合は、ノイズの多い集計を使用して概要レポートが生成されます。集計可能なレポートの会計処理に関する詳細をご覧ください。
集計ワーカーは、ジョブ メタデータ データベースでジョブ メタデータを更新します。この情報には、ジョブの戻りコードと、レポートが部分的に失敗した場合のレポート エラー カウンタが含まれます。ユーザーは、getJob ジョブ状態取得 API を使用して状態を取得できます。
Aggregation Service の詳細については、こちらの説明をご覧ください。
次のステップ
集計サービスの仕組みを理解したら、スタートガイドに沿って、Google Cloud または Amazon Web Services を介して独自のインスタンスをデプロイします。