
El servicio de agregación les brinda a las tecnologías publicitarias las estadísticas de rendimiento necesarias para mejorar la efectividad de las campañas con los clientes.
En este documento, se incluyen los siguientes temas:
- Términos y conceptos clave
- Cómo funciona el servicio de agregación para brindarte datos de conversiones detallados y mediciones de alcance a partir de informes agregables sin procesar
- Descripción general conceptual del procesamiento por lotes de informes agregables
- Descripción general conceptual de los componentes de la nube
¿A quién está dirigido este documento?
Esta página ayuda a las tecnologías publicitarias y a los desarrolladores a comprender cómo nuestras APIs permiten realizar mediciones publicitarias eficaces que preservan la privacidad.
En este documento, se da por sentado que conoces la API de Private Aggregation, la API de Attribution Reporting, la API de Protected Audience, Shared Storage y los entornos de ejecución de confianza.
Términos y conceptos clave
Familiarízate con los términos clave antes de continuar:
Glosario
- Tecnología de anuncios
-
Una plataforma de anuncios es una empresa que proporciona servicios para publicar anuncios.
- Informes agregables
-
Los informes agregables son informes encriptados que se envían desde dispositivos de usuarios individuales. Estos informes contienen datos sobre el comportamiento de los usuarios y las conversiones en varios sitios. El anunciante o la tecnología publicitaria definen las conversiones (a veces llamadas eventos activadores de atribución) y las métricas asociadas. Cada informe está encriptado para evitar que varias partes accedan a los datos subyacentes.
- Contabilidad de informes agregables
-
Un libro de contabilidad distribuido, ubicado en ambos coordinadores, que realiza un seguimiento del presupuesto de privacidad asignado y aplica la regla "Sin duplicados". Este es el mecanismo de preservación de la privacidad, ubicado y ejecutado dentro de los coordinadores, que garantiza que no se pasen informes a través del servicio de agregación más allá del presupuesto de privacidad asignado.
Obtén más información sobre cómo las estrategias de lotes se relacionan con los informes agregables.
- Presupuesto de la contabilidad de informes agregables
-
Referencias al presupuesto que garantizan que los informes individuales no se procesen más de una vez.
- Servicio de agregación
-
Un servicio operado por tecnología publicitaria que procesa informes agregables para crear un informe de resumen.
Obtén más información sobre los antecedentes del Servicio de agregación en nuestra explicación y en la lista completa de condiciones.
- Certificación
-
Es un mecanismo para autenticar la identidad del software, por lo general, con hashes criptográficos o firmas. En el caso de la propuesta de servicio de agregación, la certificación coincide con el código que se ejecuta en tu servicio de agregación operado por la tecnología publicitaria con el código de código abierto.
- Vinculación de contribuciones
- Coordinador
-
Son las entidades responsables de la administración de claves y la contabilización de informes agregables. Un coordinador mantiene una lista de valores hash de las configuraciones de servicios de agregación aprobadas y configura el acceso a las claves de desencriptación.
- Ruido y escalamiento
-
Es el ruido estadístico que se agrega a los informes de resumen durante el proceso de agregación para preservar la privacidad y garantizar que los informes finales proporcionen información de medición anonimizada.
Obtén más información sobre el mecanismo de ruido aditivo, que se extrae de la distribución de Laplace.
- Origen de los informes
-
La entidad que recibe informes agregables (es decir, tú o una tecnología publicitaria que llamó a la API de Attribution Reporting) Los informes agregables se envían desde los dispositivos de los usuarios a una URL conocida asociada con el origen de los informes. El origen de los informes se designa durante la inscripción.
- ID compartido
-
Un valor calculado que consta de
shared_info,reporting_origin,destination_site(solo para la API de Attribution Reporting),source_registration-time(solo para la API de Attribution Reporting),scheduled_report_timey la versión.Varios informes que comparten los mismos atributos en el campo
shared_infodeben tener el mismo ID compartido. Los IDs compartidos desempeñan un rol importante en la contabilidad de informes agregables. - Informe de resumen
-
Un tipo de informe de la API de Attribution Reporting y de la API de Private Aggregation. Un informe de resumen incluye datos agregados de los usuarios y puede contener datos de conversiones detallados con ruido agregado. Los informes de resumen se componen de informes agregados. Permiten una mayor flexibilidad y proporcionan un modelo de datos más rico que los informes a nivel del evento, en particular para algunos casos de uso, como los valores de conversión.
- Entorno de ejecución confiable (TEE)
-
Es una configuración segura de hardware y software de computadoras que permite a terceros verificar las versiones exactas del software que se ejecuta en la máquina sin temor a la exposición. Los TEE permiten que las partes externas verifiquen que el software haga exactamente lo que el fabricante de software afirma que hace, ni más ni menos.
Para obtener más información sobre los TEE que se usan para las propuestas de Privacy Sandbox, lee la explicación de los servicios de la API de Protected Audience y la explicación del servicio de agregación.
Flujo de trabajo del servicio de agregación
El servicio de agregación genera informes de resumen de datos detallados de conversiones y alcance a partir de informes agregables sin procesar. El flujo de generación de informes consta de los siguientes pasos:
- Un navegador recupera una clave pública para generar informes encriptados.
- Los informes agregables encriptados se envían a los servidores de tecnología publicitaria.
- El servidor de tecnología publicitaria agrupa los informes (en formato avro) y los envía al servicio de agregación.
- Un trabajador de agregación recupera los informes agregados para desencriptarlos.
- El trabajador de agregación recupera las claves de desencriptación de un coordinador.
- El trabajador de agregación desencripta los informes para la agregación y el ruido.
- El servicio de contabilización de informes agregables verifica si hay suficiente presupuesto de privacidad para generar un informe de resumen de los informes agregables determinados.
- El servicio de agregación envía un informe de resumen final.
En el siguiente diagrama, se muestra el servicio de agregación en acción, desde el momento en que se reciben informes de dispositivos web y móviles hasta el momento en que el servicio de agregación crea un informe de resumen.
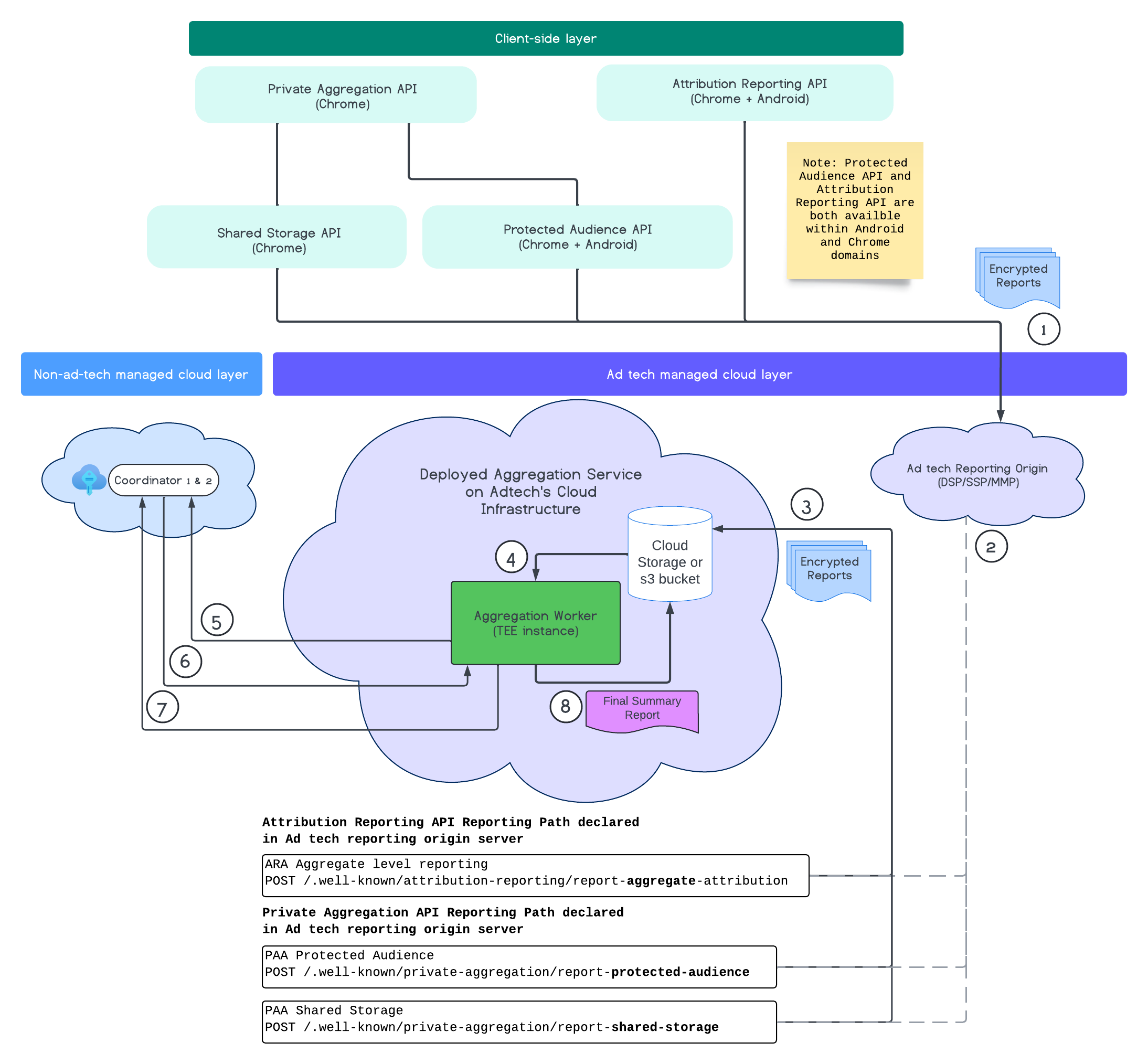
En resumen, la API de Attribution Reporting o la API de Private Aggregation generan informes a partir de varias instancias de navegador. Chrome obtiene una clave pública, que se rota cada siete días, del servicio de alojamiento de claves en el coordinador para encriptar los informes antes de enviarlos al origen de informes de la tecnología publicitaria. El origen de informes de la tecnología publicitaria recopila y convierte los informes entrantes al formato avro, y los envía al servicio de agregación. Cuando se envía una solicitud por lotes al servicio de agregación, este recupera las claves de desencriptación del servicio de alojamiento de claves, desencripta los informes y los agrega y genera ruido para crear un informe de resumen, siempre y cuando haya suficiente presupuesto de privacidad para crearlos.
Obtén más información para preparar tus informes agregables en la sección de implementación.
Procesamiento por lotes de informes agregables
El flujo de informes no se completaría sin la ayuda del servidor de origen de informes designado, que especificaste durante el proceso de inscripción. El origen de los informes es responsable de recopilar, transformar y agrupar informes agregables, y prepararlos para que se envíen a tu servicio de agregación en Google Cloud o Amazon Web Services. Obtén más información para preparar tus informes agregables.
Componentes de la nube
El servicio de agregación consta de varios componentes de servicios en la nube. Usarás las secuencias de comandos de Terraform proporcionadas para aprovisionar y configurar todos los componentes necesarios del servicio en la nube.
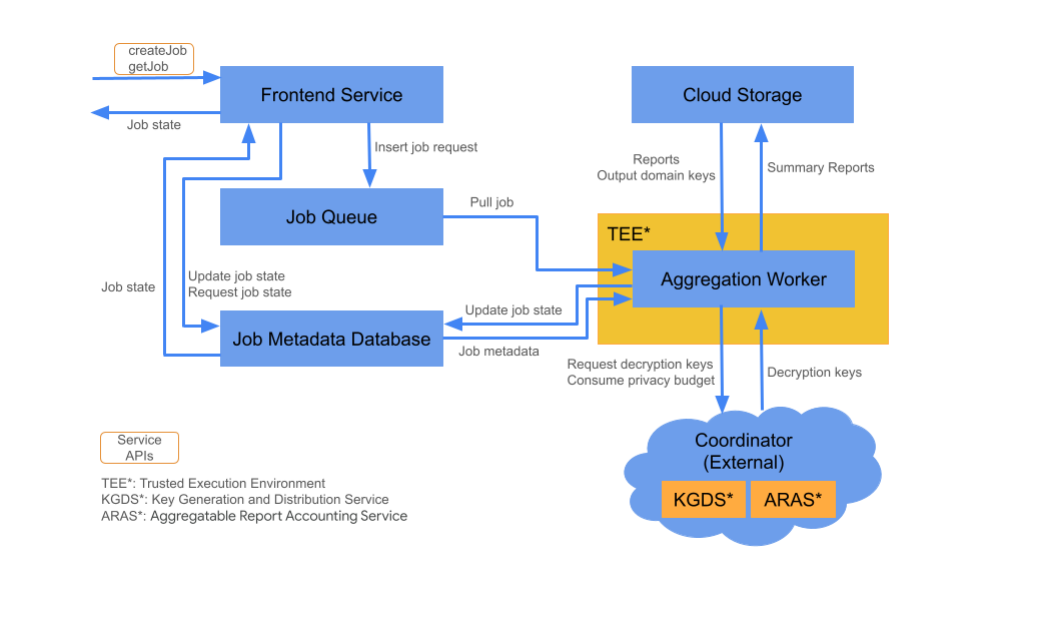
Servicio de frontend
Servicio en la nube administrado: Cloud Function (Google Cloud) o API Gateway (Amazon Web Services)
El servicio de frontend es una puerta de enlace sin servidores que es el punto de entrada principal para las llamadas a la API de Aggregation para la creación de trabajos y la recuperación de su estado. Es responsable de recibir solicitudes de los usuarios del servicio de agregación, validar los parámetros de entrada y comenzar el proceso de programación de tareas de agregación.
El servicio de frontend tiene dos APIs disponibles:
| Extremo | Descripción |
|---|---|
createJob |
Esta API activa un trabajo del servicio de agregación. Para activar el trabajo, se requiere información como el ID del trabajo, los detalles del almacenamiento de entrada, los detalles del almacenamiento de salida y el origen de los informes. |
getJob |
Esta API muestra el estado de la tarea que tiene un ID de tarea especificado. Proporciona información sobre el estado del trabajo, como "Recibido", "En curso" o "Finalizado". Si el trabajo está terminado, también muestra el resultado, incluidos los mensajes de error que se encontraron durante la ejecución. |
Consulta la documentación de la API de Aggregation Service.
Lista de tareas en cola
Servicio en la nube administrado: Pub/Sub (Google Cloud) o Amazon SQS (Amazon Web Services)
La lista de tareas en cola es una lista de mensajes que contiene solicitudes de trabajo para el servicio de agregación. El servicio de frontend inserta solicitudes de trabajo en la cola, que luego consumen los trabajadores de agregación que las procesan.
Almacenamiento en la nube
Servicio en la nube administrado: Google Cloud Storage (Google Cloud) / Amazon S3 (Amazon Web Services)
Los archivos de entrada y salida que usa el servicio de agregación, como los archivos de informes encriptados y los informes de resumen de salida, se guardan en el almacenamiento en la nube.
Base de datos de metadatos de trabajos
Servicio de nube administrado: Spanner (Google Cloud) o DynamoDB (Amazon Web Services)
La base de datos de metadatos de trabajo se usa para almacenar y hacer un seguimiento del estado de los trabajos de agregación. Registra metadatos, como la hora de creación, la hora solicitada, la hora actualizada y el estado, como Recibido, En curso o Finalizado. Los trabajadores de agregación actualizan la base de datos de metadatos de trabajos a medida que avanzan los trabajos.
Trabajador de agregación
Servicio de nube administrado: Compute Engine con espacio confidencial (Google Cloud) o Amazon Web Services EC2 con Nitro Enclave (Amazon Web Services).
Un trabajador de agregación procesa las solicitudes de trabajo en la cola de trabajo y desencripta las entradas encriptadas con claves que recupera del servicio de generación y distribución de claves (KGDS) en los coordinadores. Para minimizar la latencia de procesamiento de trabajos, los trabajadores de agregación almacenan en caché las claves de desencriptación durante un período de ocho horas y las usan en todos los trabajos que procesan.
Los trabajadores de agregación operan dentro de una instancia de entorno de ejecución confiable (TEE). Un trabajador solo controla un trabajo a la vez. Puedes configurar varios trabajadores para que procesen trabajos en paralelo si estableces la configuración de escalamiento automático. Si se usa, el ajuste de escala automático ajusta de forma dinámica la cantidad de trabajadores según la cantidad de mensajes en la cola de trabajos. Puedes configurar la cantidad mínima y máxima de trabajadores para el ajuste de escala automático a través del archivo de entorno de Terraform. Puedes encontrar más información sobre el ajuste automático de escala en estas secuencias de comandos de Terraform: Amazon Web Services o Google Cloud.
Los trabajadores de agregación llaman al servicio de contabilización de informes agregables para la contabilización de informes agregables. Este servicio verifica que las tareas solo se ejecuten si no se superó el límite del presupuesto de privacidad. (consulta la regla"Sin duplicados"). Si el presupuesto está disponible, se genera un informe de resumen con los agregados con ruido. Lee detalles adicionales sobre la contabilidad de informes agregables.
Los trabajadores de agregación actualizan los metadatos de los trabajos en la base de datos de metadatos de trabajos. Esta información incluye los códigos de devolución de trabajos y los contadores de errores de informes en caso de fallas parciales de informes. Los usuarios pueden recuperar el estado con la API de recuperación de estado de trabajo getJob.
Consulta esta explicación para obtener una descripción más detallada del servicio de agregación.
Próximos pasos
Ahora que sabes cómo funciona el servicio de agregación, sigue la guía de introducción para implementar tu propia instancia a través de Google Cloud o Amazon Web Services.