
この時点で、集計サービスを使用すると、フィルタリング ID を活用して、特定の測定値を異なるケイデンスで処理できるようになります。フィルタリング ID は、次のように 集計サービス内でジョブの作成時に渡せるようになりました。
POST createJob
Body: {
"job_parameters": {
"output_domain_blob_prefix": "domain/domain.avro",
"output_domain_bucket_name": "<data_bucket>",
"filtering_ids": [1, 3] // IDs to keep in the query
}
}
このフィルタリング実装を使用するには、測定クライアント API(Attribution Reporting API または Private Aggregation API)から開始して、フィルタリング ID を渡すことをおすすめします。これらはデプロイされた集計サービスに渡され、最終的な概要レポートが期待どおりのフィルタリングされた結果とともに返されます。
予算への影響がご心配な場合は、レポートの job_parameters で指定されたフィルタリング ID に対してのみ、集計レポート アカウントの予算が消費されることをご承知おきください。これにより、予算不足エラーが発生することなく、同じレポートのジョブを再実行して、異なるフィルタリング ID を指定できます。
次のフローは、パブリック クラウドの Private Aggregation API、Shared Storage API、Aggregation Service でこの機能を使用する方法を示しています。

このフローは、アトリビューション レポーティング API を使用して ID をフィルタリングし、パブリック クラウドの集計サービスに渡す方法を示しています。
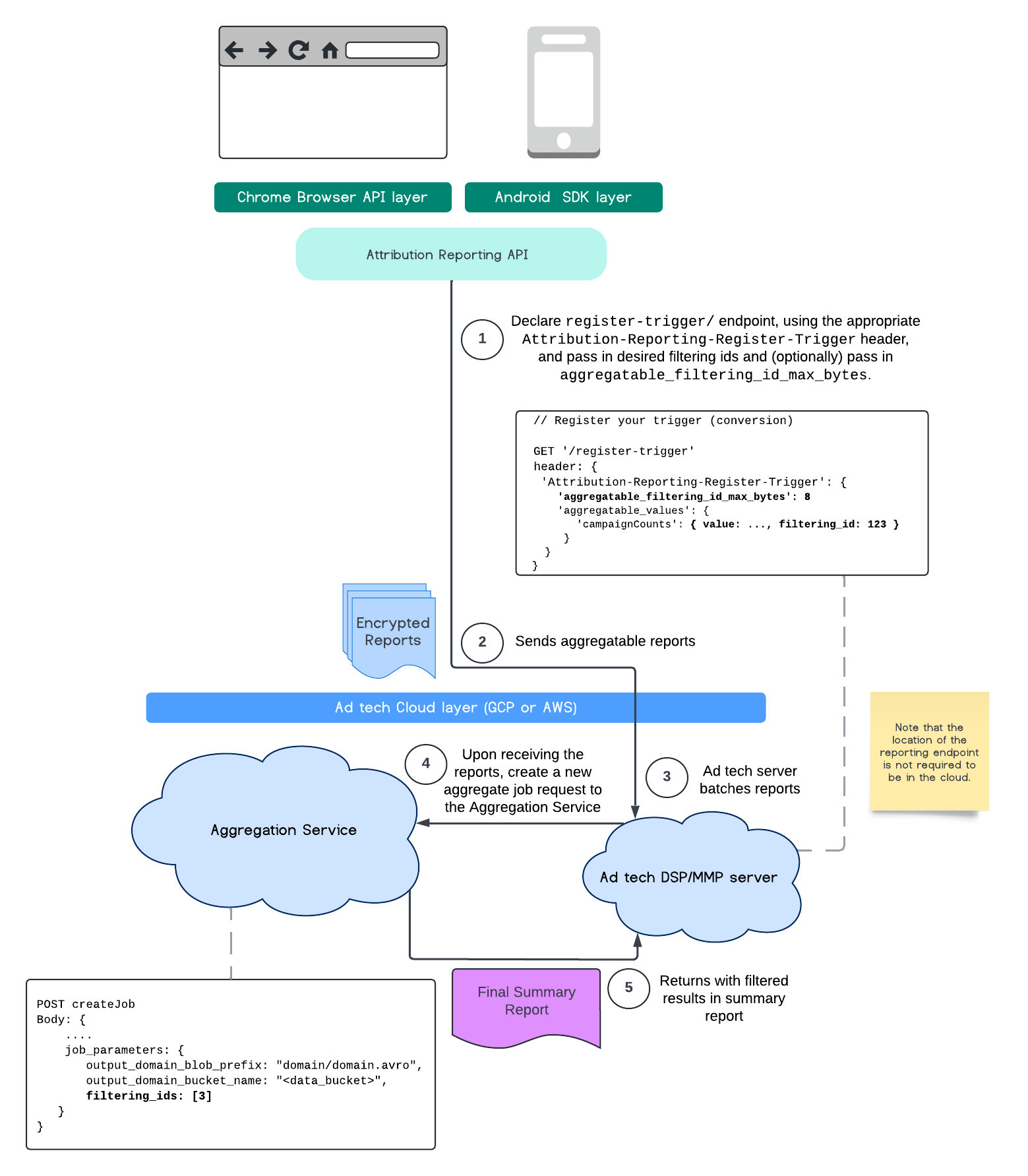
詳細については、Attribution Reporting API の説明、Private Aggregation API の説明、最初の提案をご覧ください。
詳細については、Attribution Reporting API または Private Aggregation API のセクションをご覧ください。createJob エンドポイントと getJob エンドポイントの詳細については、集計サービス API のドキュメントをご覧ください。