
फ़िलहाल, एग्रीगेशन सेवा की मदद से, फ़िल्टर करने वाले आईडी का इस्तेमाल करके, अलग-अलग फ़्रीक्वेंसी पर कुछ मेज़रमेंट प्रोसेस किए जा सकते हैं. अब फ़िल्टर करने वाले आईडी को, एग्रीगेशन सेवा में नौकरी बनाते समय इस तरह पास किया जा सकता है:
POST createJob
Body: {
"job_parameters": {
"output_domain_blob_prefix": "domain/domain.avro",
"output_domain_bucket_name": "<data_bucket>",
"filtering_ids": [1, 3] // IDs to keep in the query
}
}
फ़िल्टर करने की इस सुविधा का इस्तेमाल करने के लिए, हमारा सुझाव है कि आप मेज़रमेंट क्लाइंट एपीआई (Attribution Reporting API या Private Aggregation API) से शुरुआत करें और फ़िल्टर करने के लिए आईडी पास करें. इन्हें आपकी डिप्लॉय की गई Aggregation Service को भेजा जाएगा, ताकि आपकी फ़ाइनल खास जानकारी वाली रिपोर्ट में फ़िल्टर किए गए अनुमानित नतीजे वापस मिल सकें.
अगर आपको इस बात की चिंता है कि इससे आपके बजट पर क्या असर पड़ेगा, तो एग्रीगेट रिपोर्ट खाते का बजट सिर्फ़ उन आईडी को फ़िल्टर करने के लिए इस्तेमाल किया जाएगा जो रिपोर्ट के लिए आपके job_parameters में बताए गए हैं. इस तरह, बजट खत्म होने की गड़बड़ियों का सामना किए बिना, एक ही रिपोर्ट के लिए अलग-अलग फ़िल्टरिंग आईडी तय करके, फिर से जॉब चलाई जा सकेंगी.
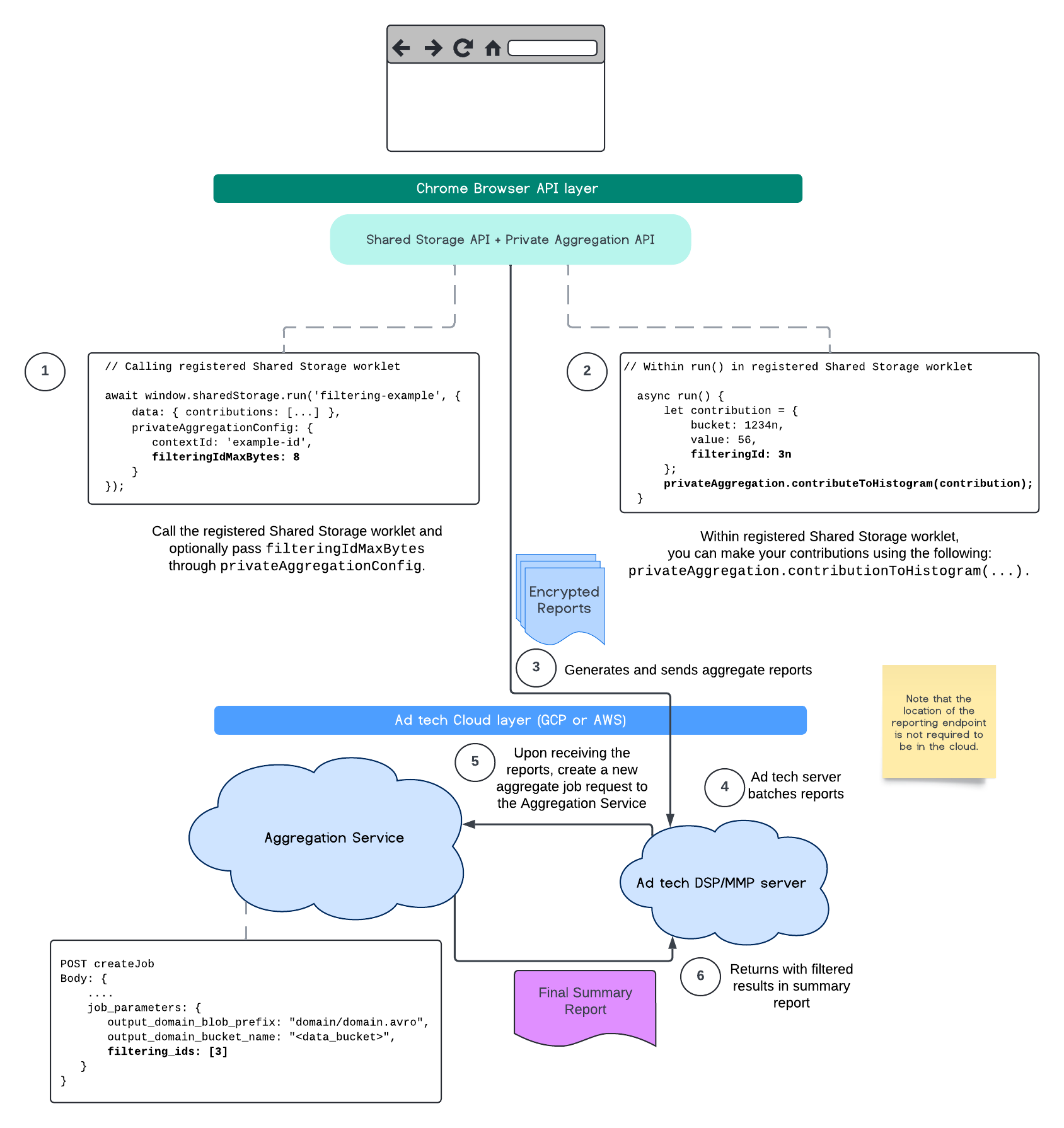
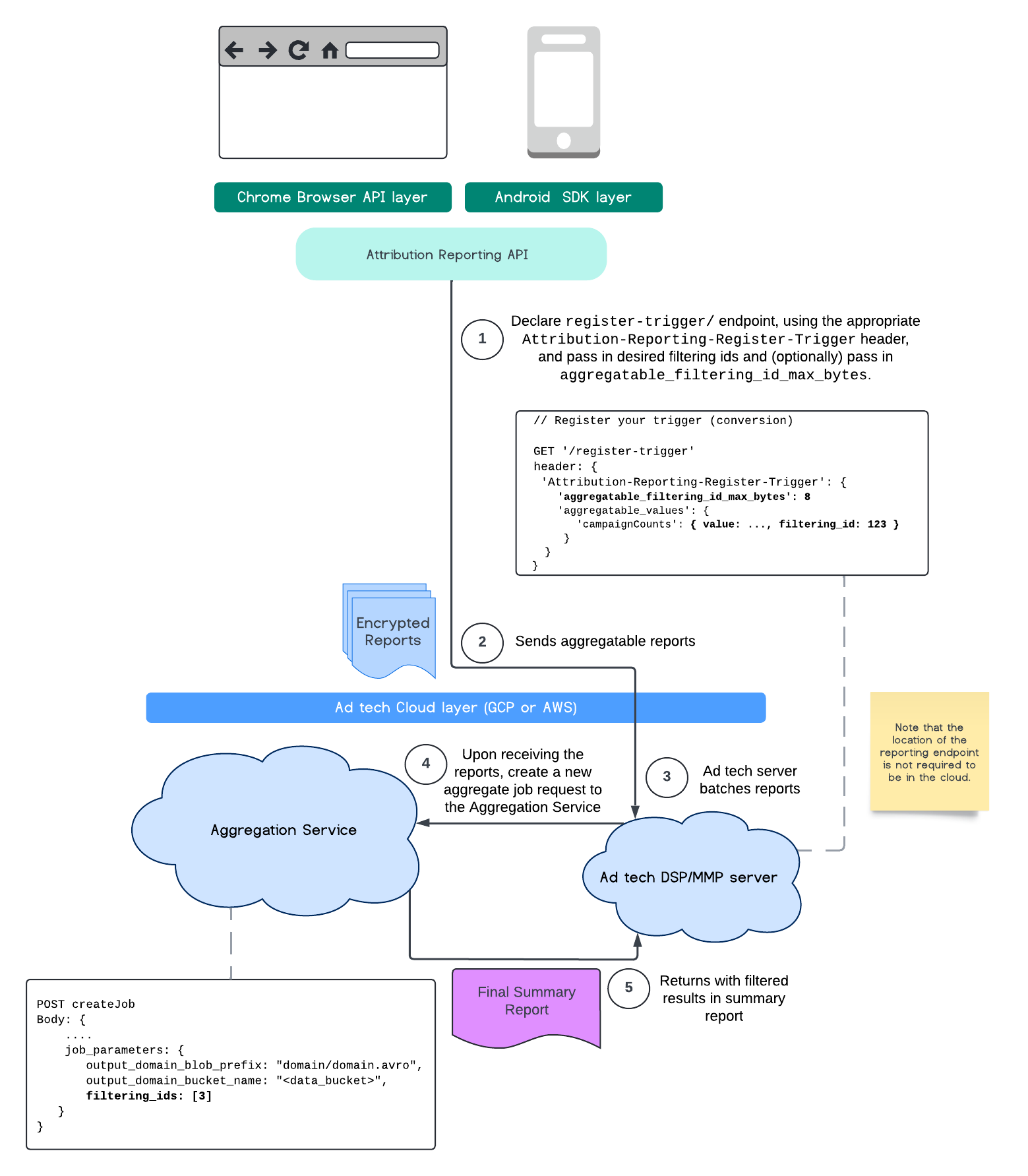
यहां दिए गए फ़्लो से पता चलता है कि Private Aggregation API, Shared Storage API, और Aggregation Service के साथ इसका इस्तेमाल कैसे किया जा सकता है.
इस फ़्लो में बताया गया है कि अपने सार्वजनिक क्लाउड में, एट्रिब्यूशन रिपोर्टिंग एपीआई और एग्रीगेशन सेवा के साथ फ़िल्टरिंग आईडी का इस्तेमाल कैसे किया जाता है.
ज़्यादा जानकारी के लिए, Attribution Reporting API के बारे में जानकारी और Private Aggregation API के बारे में जानकारी पढ़ें. साथ ही, प्रस्ताव के बारे में शुरुआती जानकारी भी पढ़ें.
ज़्यादा जानकारी के लिए, हमारे Attribution Reporting API या Private Aggregation API सेक्शन पर जाएं. Aggregation Service API के दस्तावेज़ में, createJob और getJob एंडपॉइंट के बारे में ज़्यादा जानकारी दी गई है.