
בשלב הזה, באמצעות Aggregation Service, אפשר לעבד מדידות מסוימות במרווחי זמן שונים על ידי שימוש במזהים לסינון. מעכשיו אפשר להעביר סינון של מזהים במהלך יצירת משימה ב-Aggregation Service באופן הבא:
POST createJob
Body: {
"job_parameters": {
"output_domain_blob_prefix": "domain/domain.avro",
"output_domain_bucket_name": "<data_bucket>",
"filtering_ids": [1, 3] // IDs to keep in the query
}
}
כדי להשתמש ביישום הסינון הזה, מומלץ להתחיל עם ממשקי ה-API של לקוח המדידה (Attribution Reporting API או Private Aggregation API) ולהעביר את מזהי הסינון. הנתונים האלה יועברו לשירות הצבירה שהטמעתם, כדי שהדוח הסופי של הסיכום יחזור עם התוצאות המסוננות הצפויות.
אם אתם חוששים מההשפעה של השינוי הזה על התקציב שלכם, התקציב של חשבון הדוחות המצטברים ישמש רק לסינון מזהים שצוינו בjob_parameters לצורך דיווח. כך תוכלו להריץ מחדש עבודות עבור אותם דוחות, ולציין מזהי סינון שונים בלי להיתקל בשגיאות של חריגה מהתקציב.
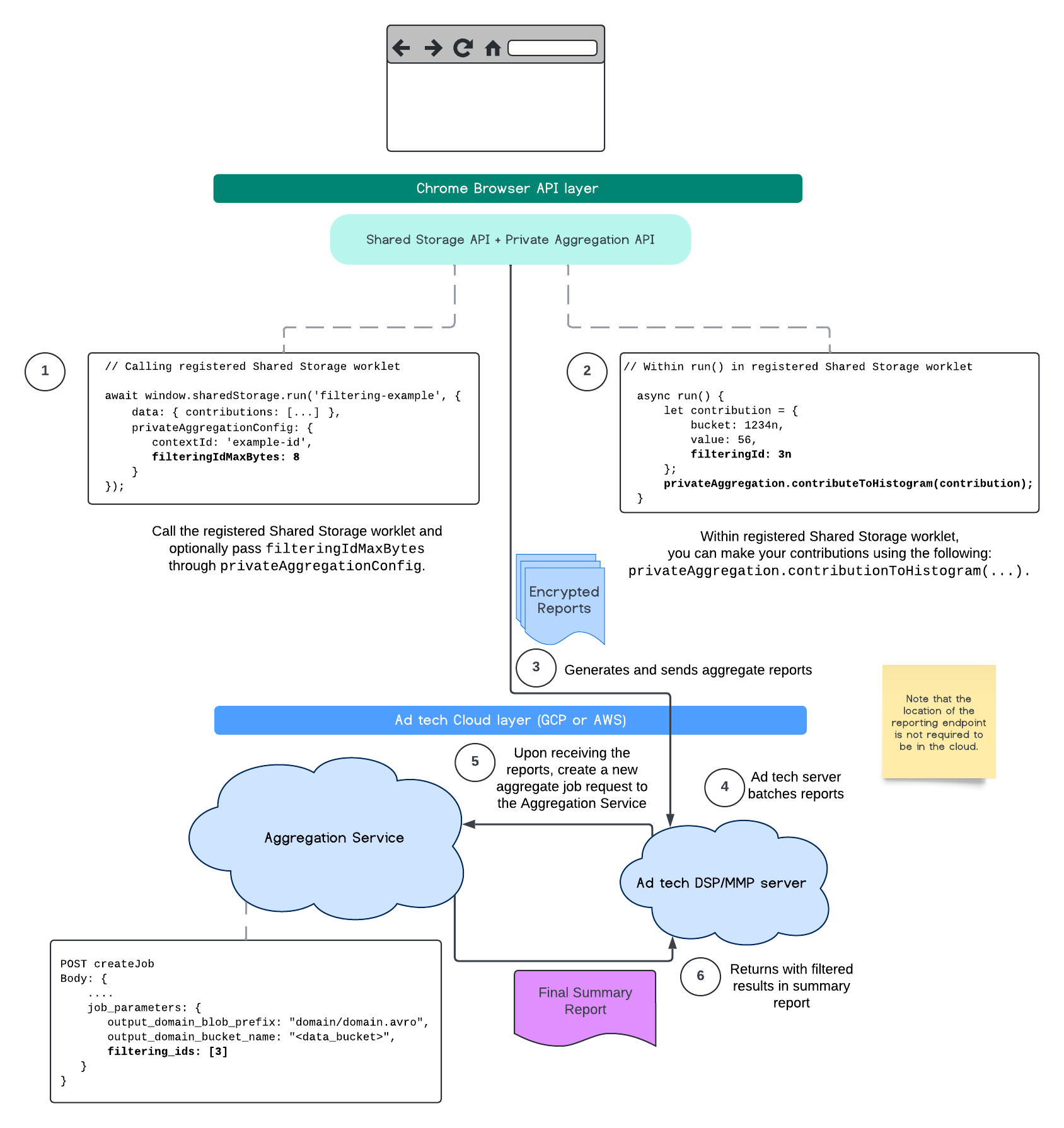
בתרשים הבא מוצג תהליך השימוש ב-Private Aggregation API, ב-Shared Storage API וב-Aggregation Service בענן ציבורי.
בתרשים הזה מוצג תהליך השימוש במסנני מזהים באמצעות Attribution Reporting API ועד ל-Aggregation Service בענן הציבורי.
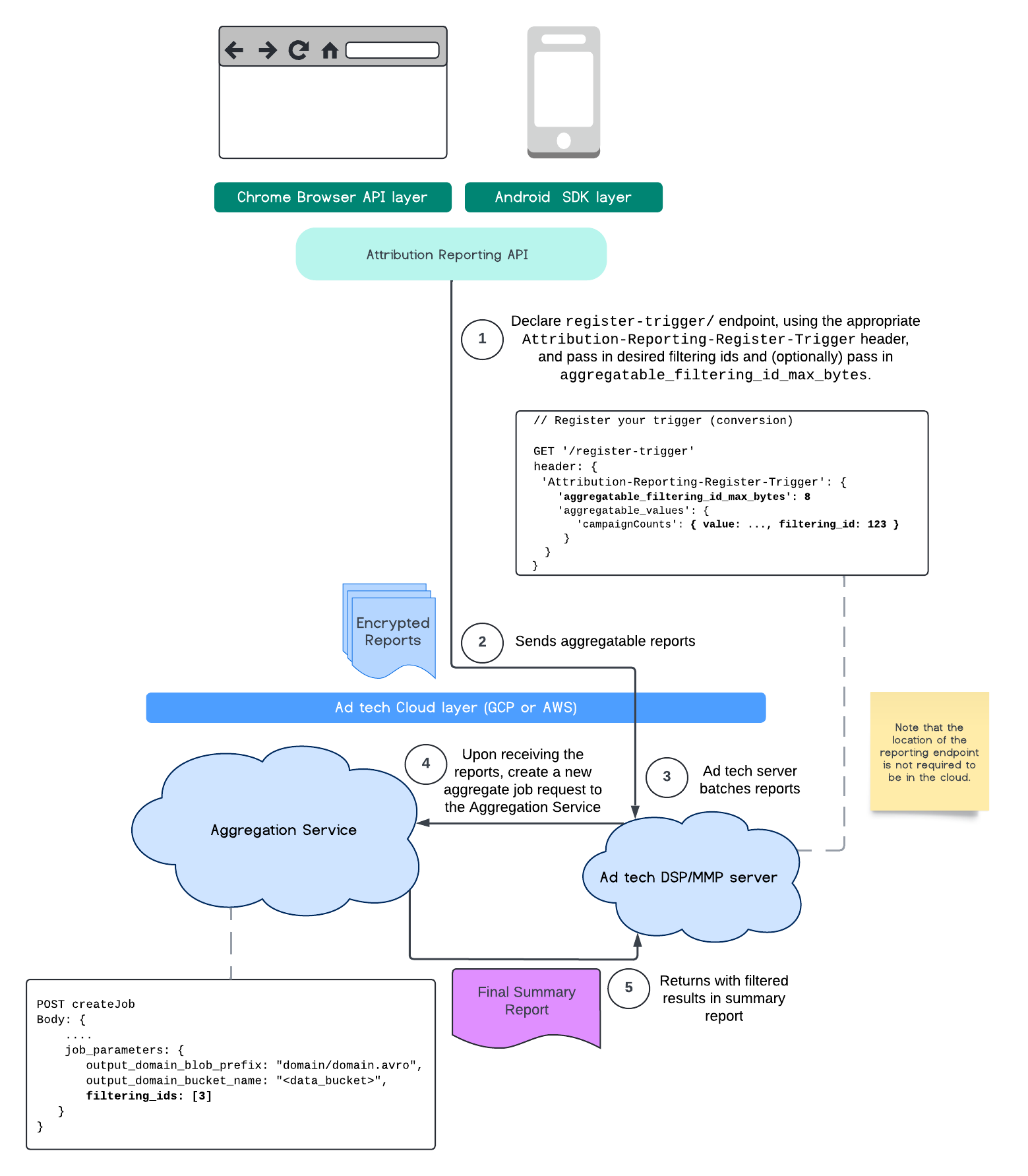
למידע נוסף, אפשר לעיין בהסבר על Attribution Reporting API, בהסבר על Private Aggregation API ובהצעה הראשונית.
אפשר להמשיך לקטעים Attribution Reporting API או Private Aggregation API כדי לקרוא הסבר מפורט יותר. מידע נוסף על נקודות הקצה createJob ו-getJob זמין במסמכי התיעוד של Aggregation Service API.