
В настоящее время с помощью службы агрегации вы можете обрабатывать определенные измерения с разной периодичностью, используя идентификаторы фильтрации. Идентификаторы фильтрации теперь можно передавать при создании задания в вашей службе агрегации следующим образом:
POST createJob
Body: {
"job_parameters": {
"output_domain_blob_prefix": "domain/domain.avro",
"output_domain_bucket_name": "<data_bucket>",
"filtering_ids": [1, 3] // IDs to keep in the query
}
}
Для использования данной реализации фильтрации рекомендуется начать с API клиента измерений ( API отчетов по атрибуции или API частной агрегации ) и передать идентификаторы фильтрации. Они будут переданы в развернутую вами службу агрегации, чтобы в итоговом сводном отчете отображались ожидаемые результаты фильтрации.
Если вас беспокоит, как это повлияет на ваш бюджет, то бюджет вашего счета для сводных отчетов будет расходоваться только на фильтрацию по идентификаторам, указанным в job_parameters для отчетов. Таким образом, вы сможете повторно запускать задания для тех же отчетов, указывая другие идентификаторы фильтрации, без возникновения ошибок исчерпания бюджета.
Следующая схема демонстрирует, как вы можете использовать это в рамках API частной агрегации , API общего хранилища и в службе агрегации в вашем публичном облаке.
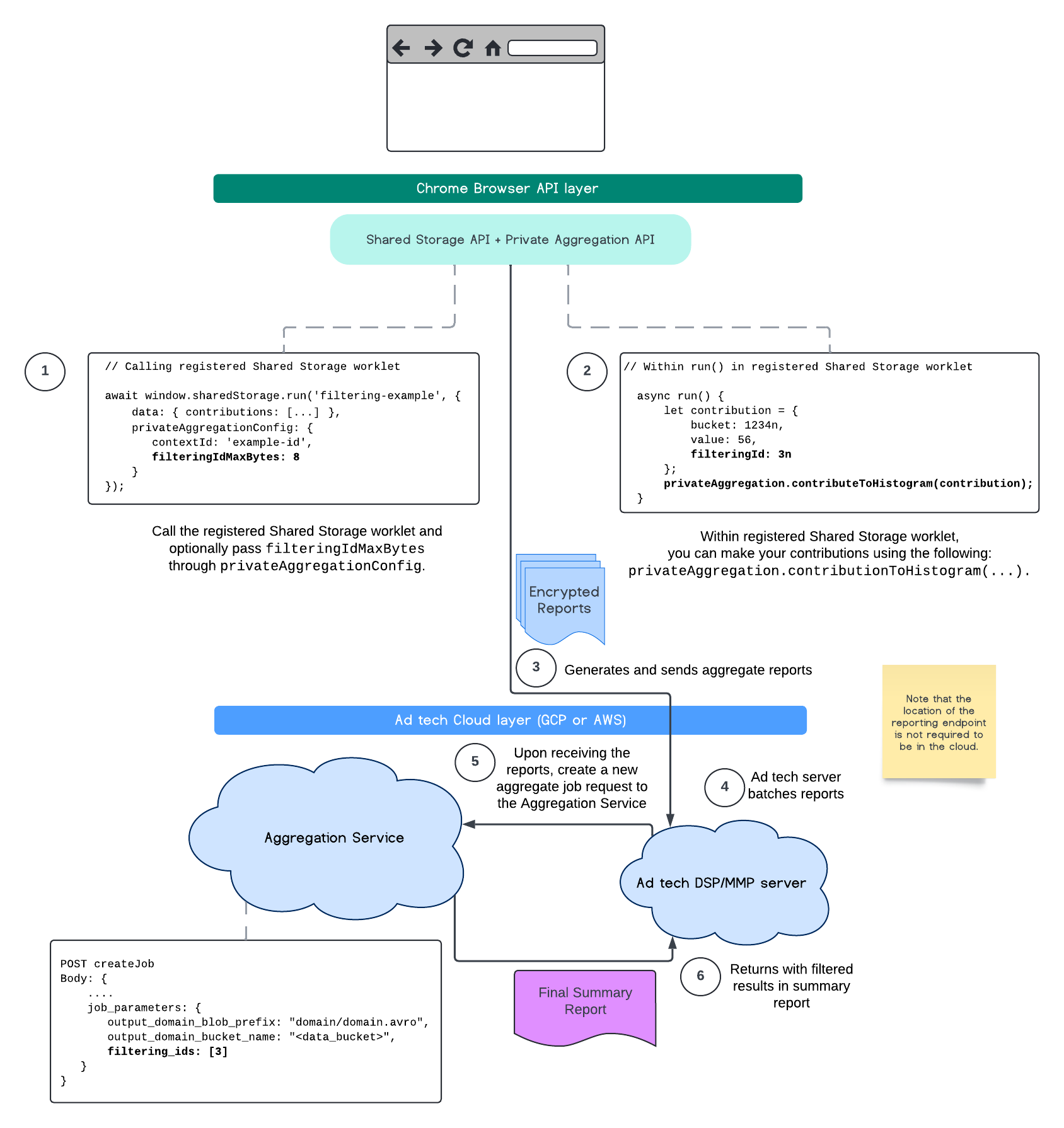
Данная схема демонстрирует, как использовать фильтрацию идентификаторов с помощью API отчетов по атрибуции и передавать данные в службу агрегации в вашем публичном облаке.
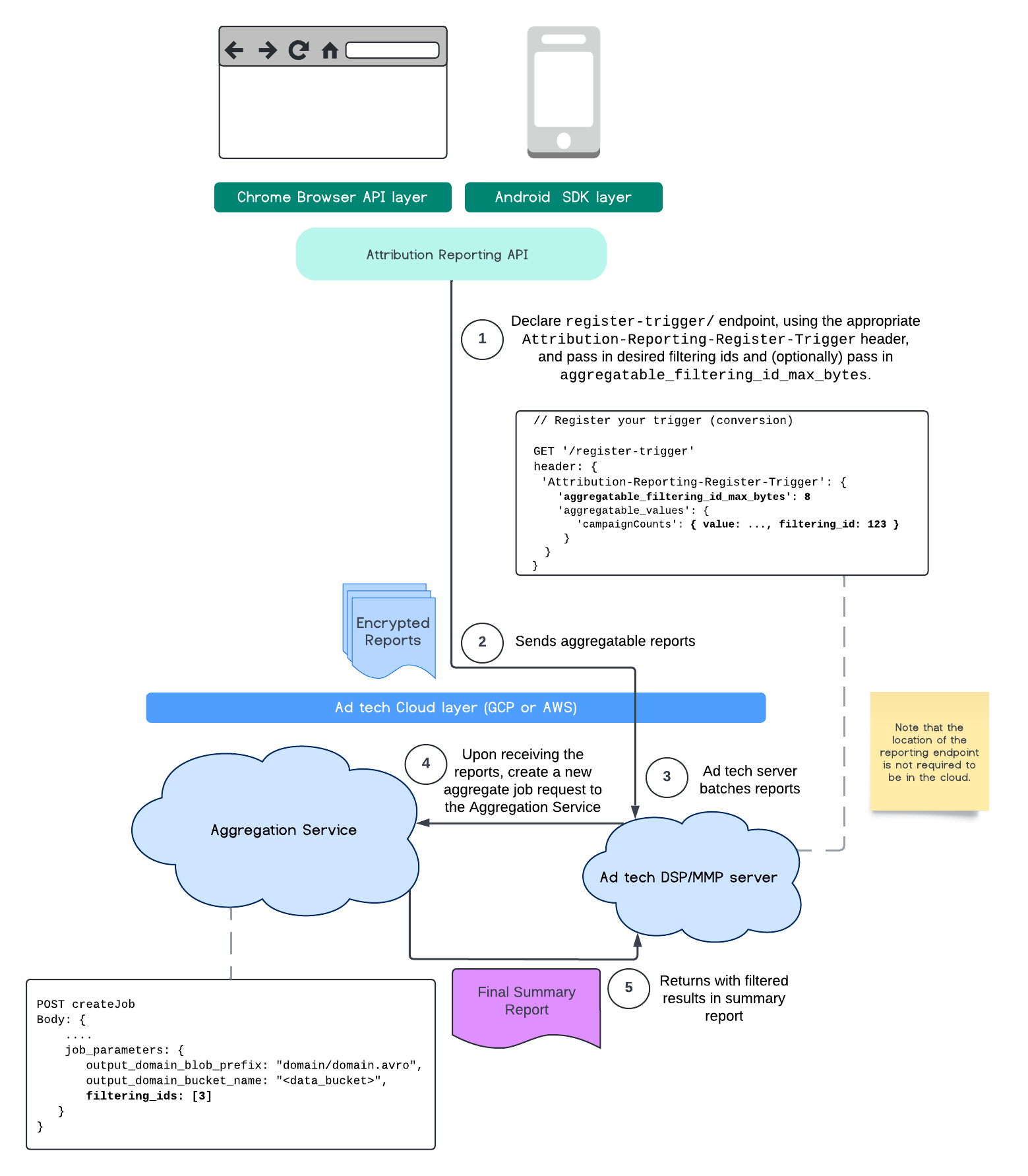
Для получения более подробной информации ознакомьтесь с пояснениями к API Attribution Reporting и Private Aggregation API , а также с первоначальным предложением .
Для получения более подробной информации перейдите к разделам «API для отчетов по атрибуции» или «API для частной агрегации» . Более подробную информацию о конечных точках createJob и getJob можно найти в документации по API службы агрегации .