
Al momento, con il servizio di aggregazione, puoi elaborare determinate misurazioni a cadenze diverse utilizzando gli ID di filtro. Ora è possibile trasmettere gli ID di filtro durante la creazione del job all'interno del servizio di aggregazione nel seguente modo:
POST createJob
Body: {
"job_parameters": {
"output_domain_blob_prefix": "domain/domain.avro",
"output_domain_bucket_name": "<data_bucket>",
"filtering_ids": [1, 3] // IDs to keep in the query
}
}
Per utilizzare questa implementazione del filtro, ti consigliamo di iniziare dalle API client di misurazione (API Attribution Reporting o API Private Aggregation) e di passare gli ID filtro. Questi verranno passati al servizio di aggregazione di cui è stato eseguito il deployment, in modo che il report di riepilogo finale venga restituito con i risultati filtrati previsti.
Se ti preoccupa l'impatto sul budget, il budget dell'account report aggregato verrà utilizzato solo per filtrare gli ID specificati nel tuo job_parameters per i report. In questo modo, potrai eseguire di nuovo i job per gli stessi report specificando ID di filtro diversi senza riscontrare errori di esaurimento del budget.
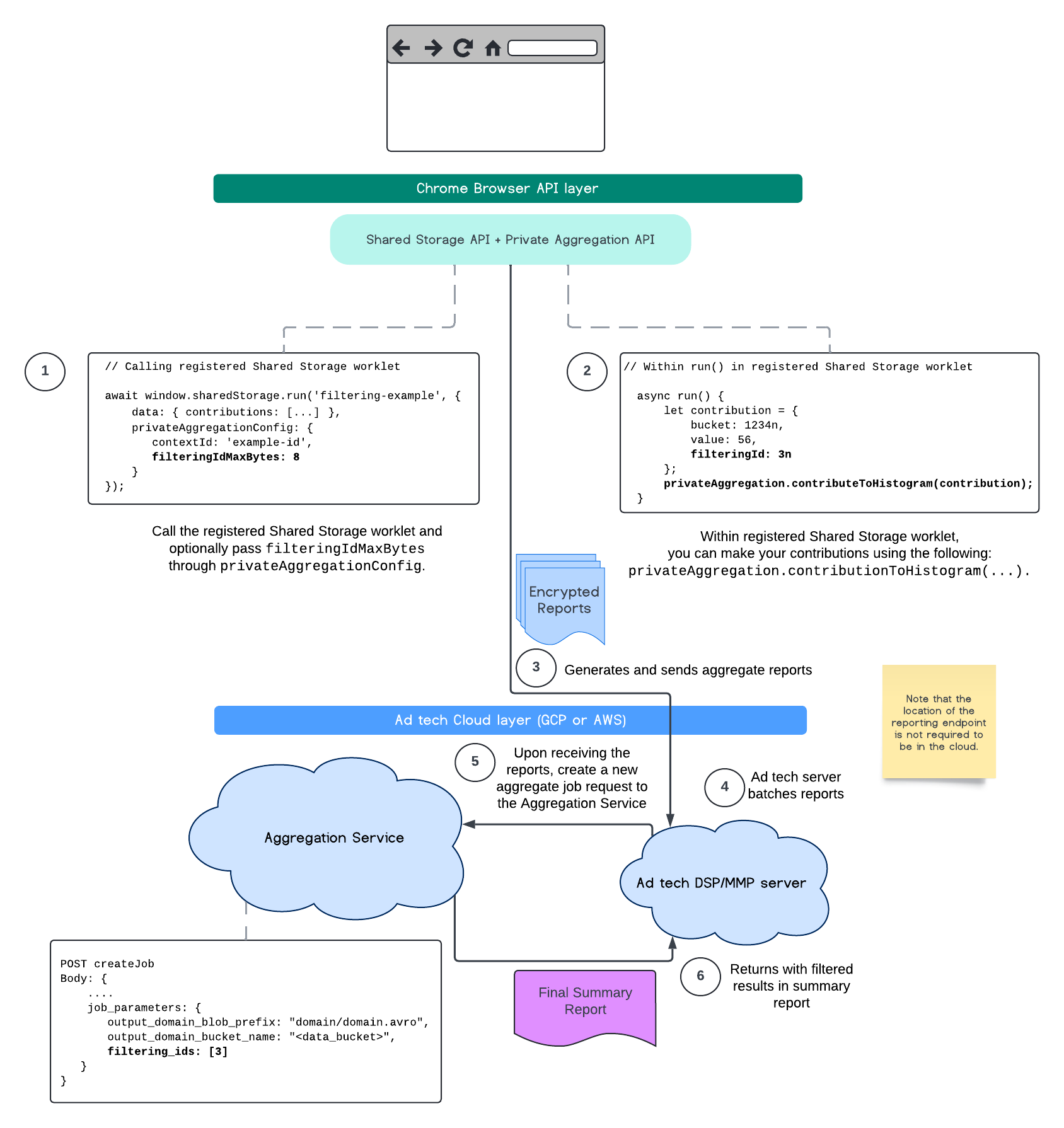
Il seguente flusso mostra come puoi utilizzare questa funzionalità all'interno dell'API Private Aggregation, dell'API Shared Storage e tramite il servizio di aggregazione nel tuo cloud pubblico.
Questo flusso mostra come utilizzare gli ID di filtro con l'API Attribution Reporting e tramite il servizio di aggregazione nel cloud pubblico.
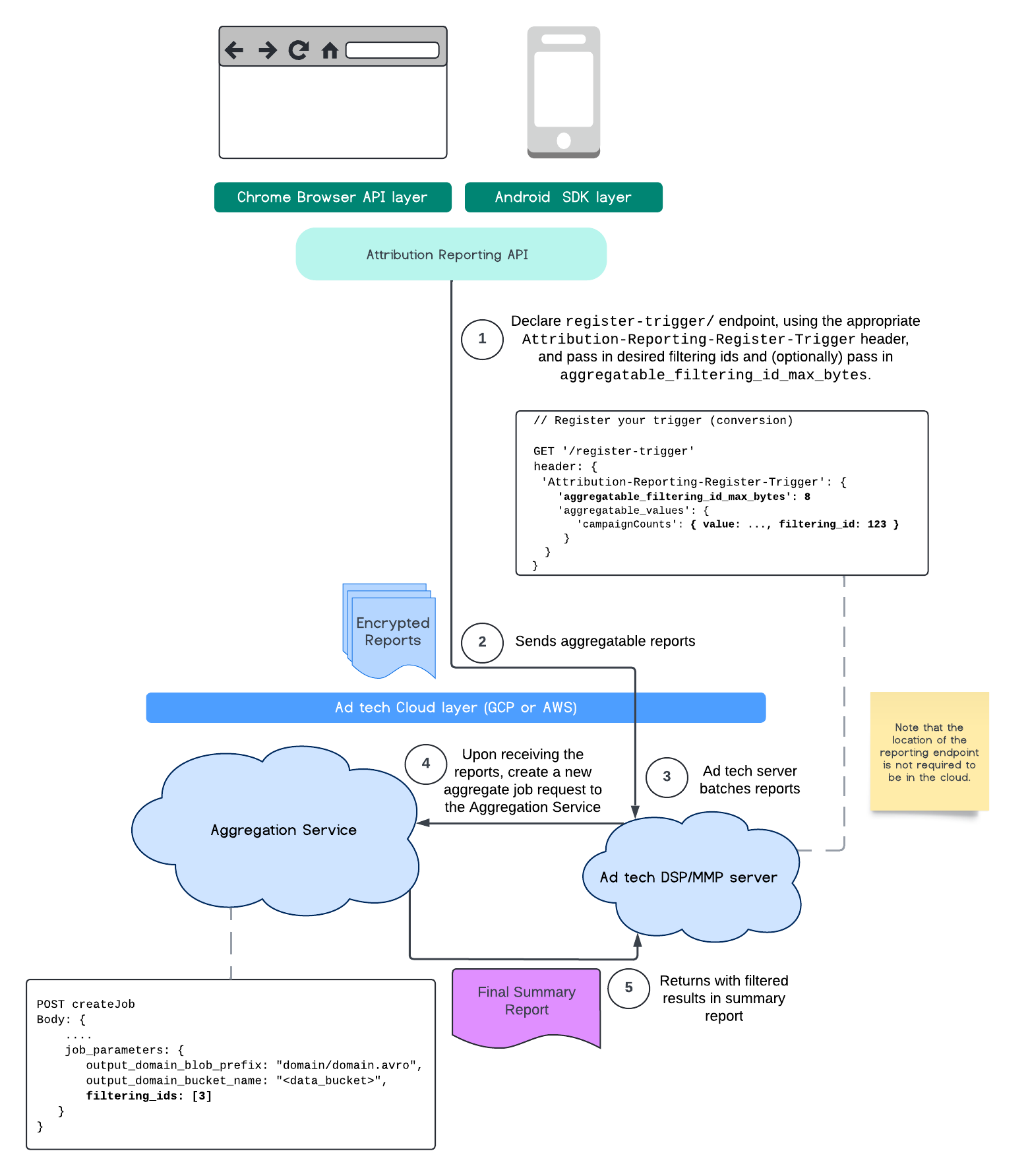
Per saperne di più, consulta l'explainer dell'API Attribution Reporting e l'explainer dell'API Private Aggregation, nonché la proposta iniziale.
Continua a leggere nelle sezioni relative all'API Attribution Reporting o all'API Private Aggregation per una descrizione più dettagliata. Puoi leggere di più sugli endpoint createJob e getJob nella documentazione dell'API Aggregation Service.