
در حال حاضر، با سرویس تجمیع، میتوانید با استفاده از شناسههای فیلتر، اندازهگیریهای خاصی را در فواصل زمانی مختلف پردازش کنید. شناسههای فیلتر اکنون میتوانند در هنگام ایجاد شغل در سرویس تجمیع شما به صورت زیر ارسال شوند:
POST createJob
Body: {
"job_parameters": {
"output_domain_blob_prefix": "domain/domain.avro",
"output_domain_bucket_name": "<data_bucket>",
"filtering_ids": [1, 3] // IDs to keep in the query
}
}
برای استفاده از این پیادهسازی فیلترینگ، توصیه میشود از APIهای کلاینت اندازهگیری ( Attribution Reporting API یا Private Aggregation API ) شروع کنید و شناسههای فیلترینگ خود را وارد کنید. این شناسهها به سرویس تجمیع مستقر شده شما ارسال میشوند تا گزارش خلاصه نهایی شما با نتایج فیلتر شده مورد انتظار بازگردد.
اگر نگران این هستید که این موضوع چگونه بر بودجه شما تأثیر میگذارد، بودجه حساب گزارش تجمیعی شما فقط برای فیلتر کردن شناسههایی که در job_parameters برای گزارشها مشخص شدهاند، مصرف خواهد شد. به این ترتیب، میتوانید کارها را برای همان گزارشها با مشخص کردن شناسههای فیلترینگ متفاوت، بدون مواجهه با خطاهای اتمام بودجه، دوباره اجرا کنید.
روند زیر نحوه استفاده از این قابلیت را در API خصوصی تجمیع ، API اشتراکگذاری ذخیرهسازی و از طریق سرویس تجمیع در ابر عمومی شما نشان میدهد.
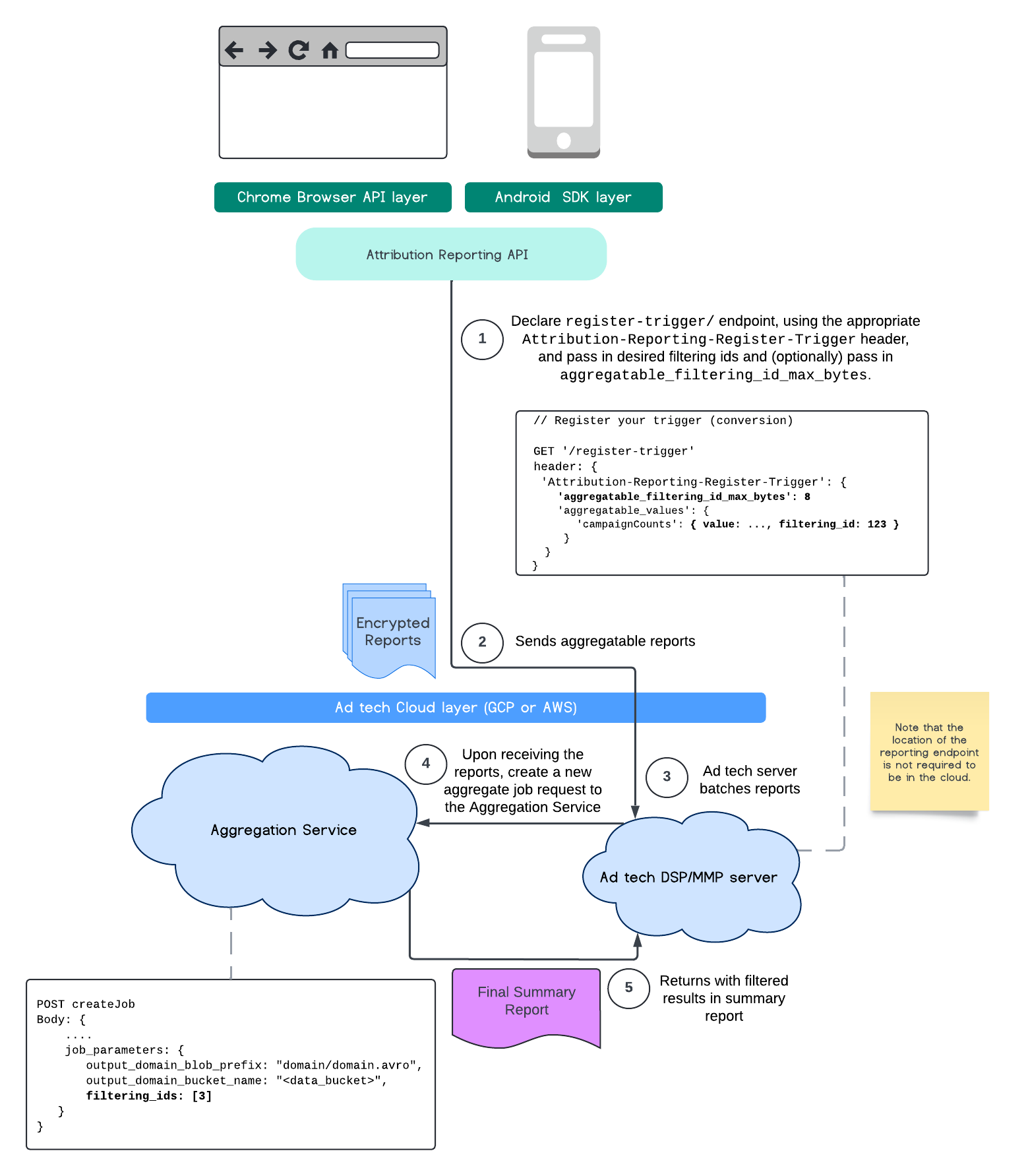
این جریان نحوه استفاده از فیلتر کردن شناسهها را با استفاده از API گزارشدهی نسبتدهی و از طریق سرویس تجمیع در ابر عمومی شما نشان میدهد.
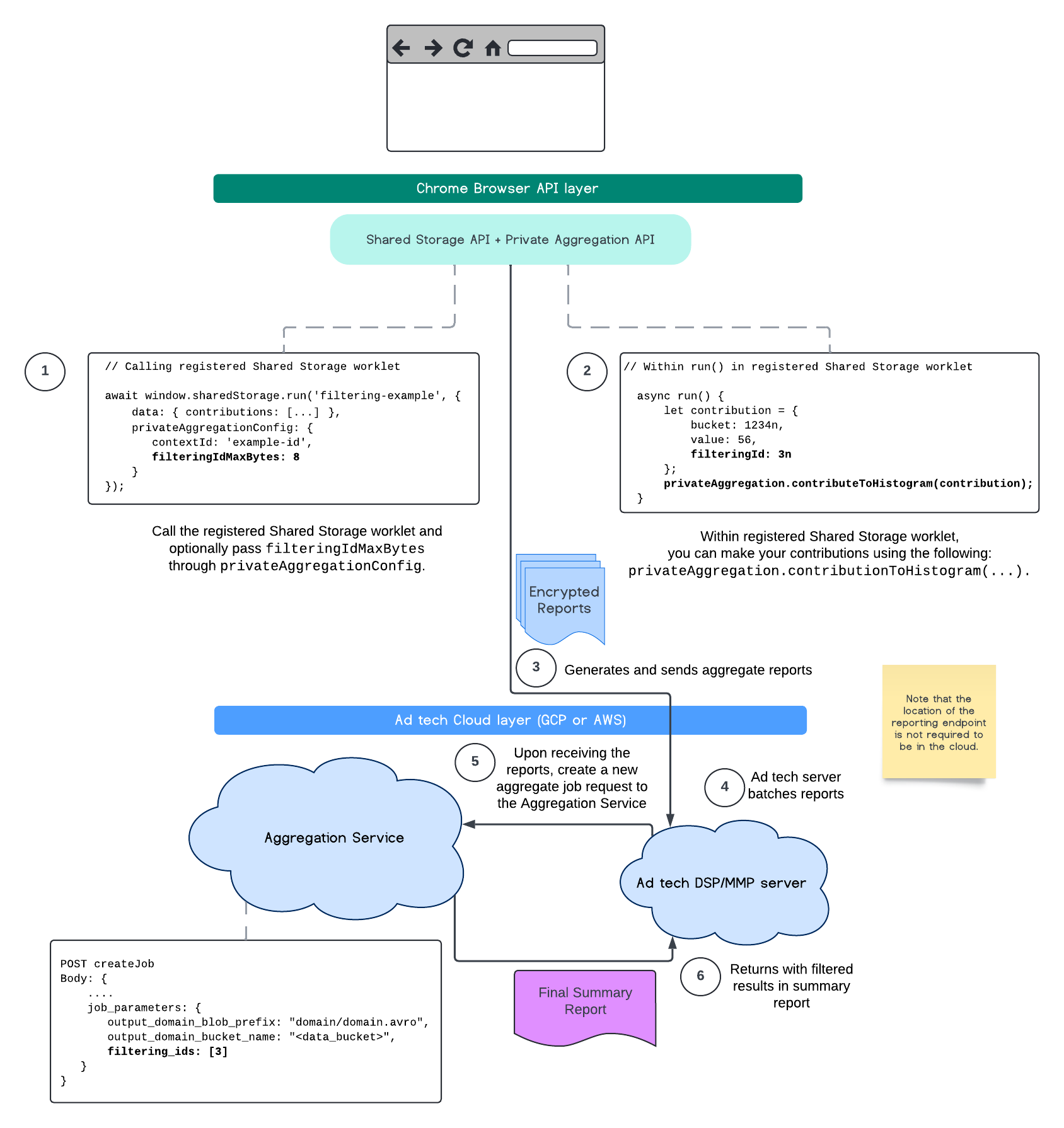
برای مطالعه بیشتر، به توضیح API گزارشدهی انتساب و توضیح API تجمیع خصوصی و همچنین پیشنهاد اولیه مراجعه کنید.
برای مطالعهی جزئیات بیشتر، به بخشهای API گزارشدهی انتساب یا API تجمیع خصوصی ما مراجعه کنید. میتوانید اطلاعات بیشتر در مورد نقاط پایانی createJob و getJob را در مستندات API سرویس تجمیع مطالعه کنید.