
এই মুহূর্তে, অ্যাগ্রিগেশন সার্ভিসের মাধ্যমে, আপনি এখন ফিল্টারিং আইডি ব্যবহার করে বিভিন্ন ক্যাডেন্সে নির্দিষ্ট পরিমাপ প্রক্রিয়া করতে পারেন। ফিল্টারিং আইডি এখন আপনার অ্যাগ্রিগেশন সার্ভিসের মধ্যে চাকরি তৈরিতে এইভাবে প্রেরণ করা যেতে পারে:
POST createJob
Body: {
"job_parameters": {
"output_domain_blob_prefix": "domain/domain.avro",
"output_domain_bucket_name": "<data_bucket>",
"filtering_ids": [1, 3] // IDs to keep in the query
}
}
এই ফিল্টারিং বাস্তবায়ন ব্যবহার করার জন্য, পরিমাপ ক্লায়েন্ট API ( অ্যাট্রিবিউশন রিপোর্টিং API অথবা প্রাইভেট অ্যাগ্রিগেশন API ) থেকে শুরু করে আপনার ফিল্টারিং আইডিগুলি পাস করার পরামর্শ দেওয়া হচ্ছে। এগুলি আপনার ডিপ্লয় করা অ্যাগ্রিগেশন পরিষেবাতে পাঠানো হবে, যাতে আপনার চূড়ান্ত সারাংশ প্রতিবেদনটি প্রত্যাশিত ফিল্টার করা ফলাফল সহ ফিরে আসে।
যদি আপনি চিন্তিত হন যে এটি আপনার বাজেটকে কীভাবে প্রভাবিত করবে, তাহলে আপনার সামগ্রিক রিপোর্ট অ্যাকাউন্ট বাজেট শুধুমাত্র আপনার job_parameters এ রিপোর্টের জন্য নির্দিষ্ট করা ফিল্টারিং আইডিগুলির জন্য ব্যয় করা হবে। এইভাবে, আপনি বাজেট নিষ্কাশনের ত্রুটি ছাড়াই বিভিন্ন ফিল্টারিং আইডি নির্দিষ্ট করে একই রিপোর্টের জন্য কাজগুলি পুনরায় চালাতে সক্ষম হবেন।
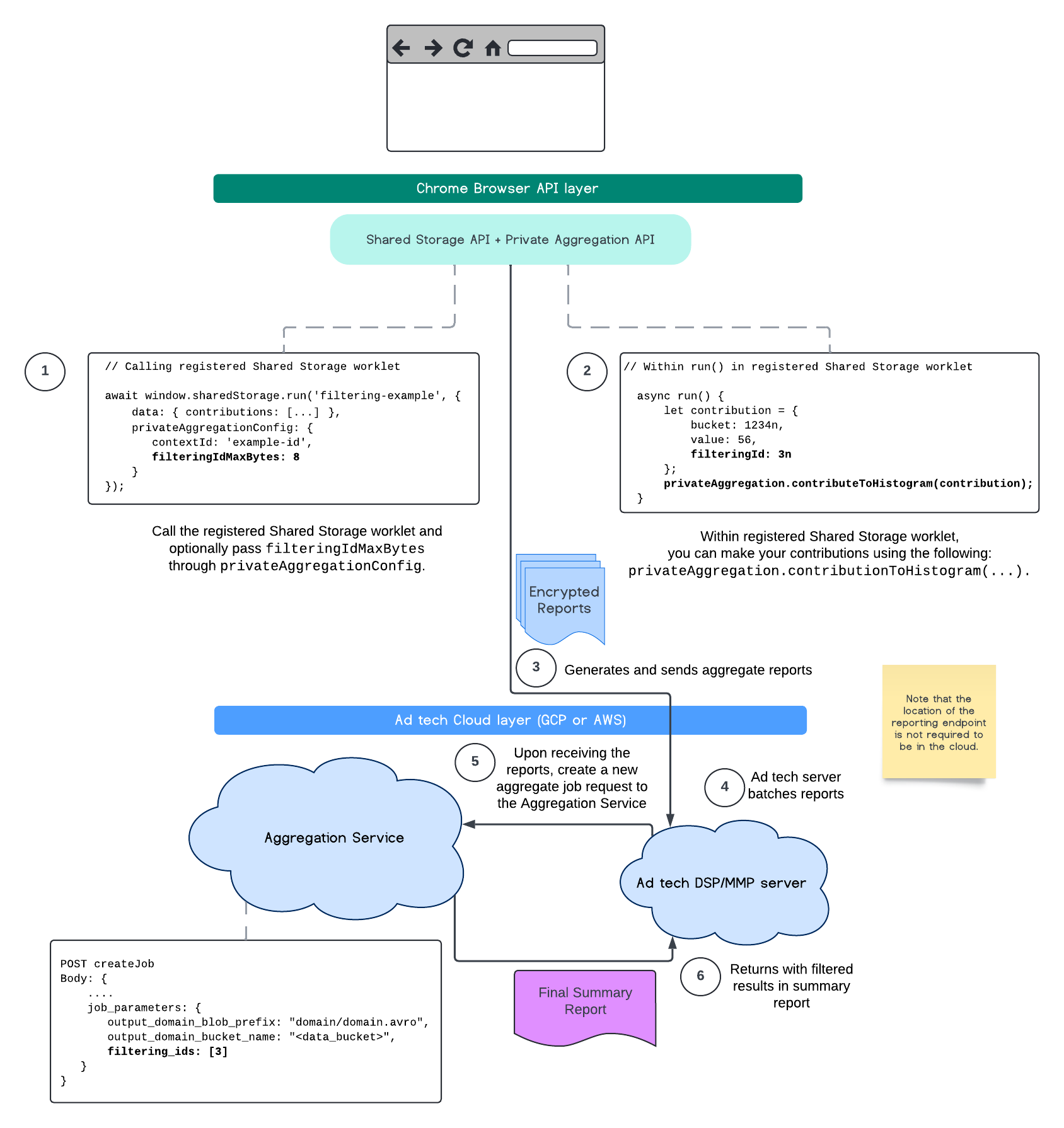
নিম্নলিখিত প্রবাহটি দেখায় যে কীভাবে আপনি এটিকে Private Aggregation API , Shared Storage API এবং আপনার পাবলিক ক্লাউডের Aggregation Service- এর মধ্যে ব্যবহার করতে পারেন।
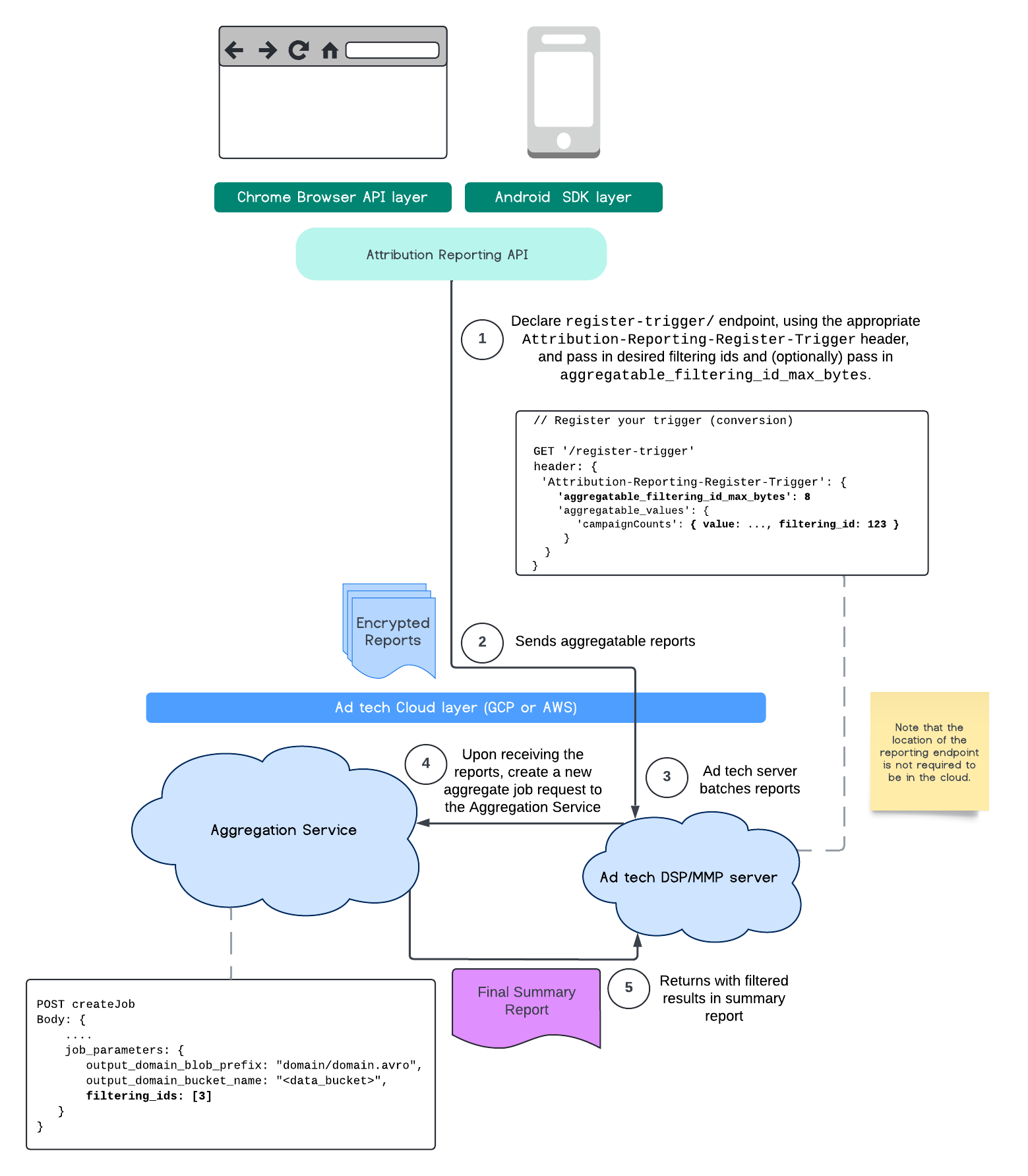
এই ফ্লোটি অ্যাট্রিবিউশন রিপোর্টিং API ব্যবহার করে ফিল্টারিং আইডি কীভাবে ব্যবহার করবেন এবং আপনার পাবলিক ক্লাউডে অ্যাগ্রিগেশন সার্ভিসে কীভাবে যাবেন তা দেখায়।
আরও পড়ার জন্য, অ্যাট্রিবিউশন রিপোর্টিং API ব্যাখ্যাকারী এবং Private Aggregation API ব্যাখ্যাকারী , সেইসাথে প্রাথমিক প্রস্তাবটি দেখুন।
আরও বিস্তারিত অ্যাকাউন্টের জন্য আমাদের অ্যাট্রিবিউশন রিপোর্টিং API অথবা প্রাইভেট অ্যাগ্রিগেশন API বিভাগগুলি পড়ুন। আপনি Aggregation Service API ডকুমেন্টেশনে createJob এবং getJob এন্ডপয়েন্ট সম্পর্কে আরও পড়তে পারেন।