
W przypadku raportów zbiorczych, które można agregować, ważne jest optymalizowanie strategii tworzenia pakietów, aby nie przekraczać limitów prywatności. Poniżej znajdziesz kilka zalecanych strategii wysyłania do usługi do agregacji partii raportów.
Zbieranie raportów
Podczas zbierania raportów do uwzględnienia w partii pamiętaj o tych kwestiach:
Ponowne próby przesyłania raportu
Uwaga: kryteria ponownej próby mogą ulec zmianie. W takim przypadku informacje w tej sekcji zostaną zaktualizowane.
Zarówno w przypadku platform internetowych, jak i systemów operacyjnych platforma podejmie 3 próby wysłania raportu. Jeśli po trzeciej próbie nie uda się go wysłać, nie zostanie on wysłany. Oryginalna wartośćscheduled_report_time jest zachowywana niezależnie od tego, kiedy można wysłać raport. Harmonogram ponownych prób różni się w zależności od platformy:
- Przeglądarka internetowa będzie wysyłać raporty, gdy będzie online. Jeśli raport nie zostanie wysłany, system odczeka 5 minut przed drugą próbą, a potem 15 minut przed trzecią. Jeśli przeglądarka przejdzie w tryb offline, kolejna próba ponowienia nastąpi minutę po powrocie do trybu online. W przypadku wysyłania raportów w internecie nie ma maksymalnego opóźnienia. Oznacza to, że jeśli przeglądarka przejdzie w tryb offline, bez względu na to, jak dawno został wygenerowany raport, po powrocie do trybu online spróbuje go wysłać zgodnie z zasadami ponawiania prób.
- telefon z Androidem ma stabilne połączenie sieciowe, W związku z tym zadanie wysyłania raportów będzie uruchamiane raz na godzinę. Oznacza to, że jeśli raport nie zostanie wysłany, ponowimy próbę w następnej godzinie i jeszcze raz w godzinie po niej. Jeśli urządzenie nie ma połączenia, ponowi wysyłanie raportu podczas następnego zadania raportowania, które zostanie uruchomione po ponownym połączeniu urządzenia z siecią. Maksymalne opóźnienie wynosi 28 dni, co oznacza, że urządzenie nie wyśle raportu wygenerowanego ponad 28 dni temu.
Oczekiwanie na raporty
Podczas zbierania raportów do przetwarzania wsadowego zalecamy poczekać na raporty, które docierają z opóźnieniem. Opóźnione raporty można rozpoznać, porównując wartość scheduled_report_time z datą otrzymania raportu. Różnica czasu między tymi raportami pomoże Ci określić, jak długo warto czekać na raporty, które docierają z opóźnieniem. Na przykład w miarę zbierania opóźnionych raportów sprawdzaj pole scheduled_report_time i zapisuj opóźnienie w godzinach, gdy otrzymasz 90%, 95% i 99% raportów. Te dane mogą służyć do określania, jak długo należy czekać na raporty, które docierają z opóźnieniem.
Natychmiastowe raporty zbiorcze
mogą zmniejszyć ryzyko opóźnienia raportów.
Poniższa ilustracja pokazuje, jak opóźnione raporty są przechowywane w odpowiednich partiach zgodnie z zaplanowanym czasem raportu. Wartość T w przypadku przetwarzania zbiorczego oznacza scheduled_report_time, a T+X oznacza czas oczekiwania na opóźnione raporty. W rezultacie otrzymasz raport podsumowujący, który zawiera większość raportów uwzględnionych w partii, co odpowiada zaplanowanemu czasowi raportu.
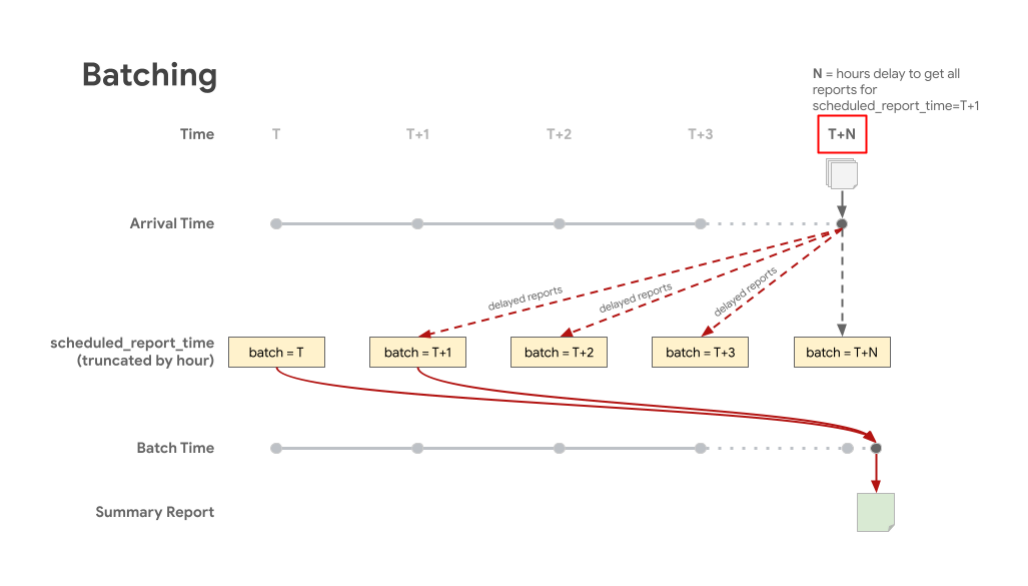
Rozliczanie raportów zbiorczych
Usługa do agregacji utrzymuje zasadę „bez duplikatów”. Ta reguła wymusza, aby wszystkie raporty możliwe do agregacji o tym samym udostępnionym identyfikatorze były uwzględniane w tej samej partii.
Po zebraniu raportów należy je pogrupować w taki sposób, aby wszystkie raporty z tym samym identyfikatorem udostępnionym były częścią jednej grupy.
Jeśli raport został już przetworzony w ramach innej partii, przetwarzanie może spowodować błąd wyczerpania budżetu na potrzeby prywatności. Prawidłowe grupowanie raportów pomaga zapobiegać odrzucaniu partii z powodu reguły „bez duplikatów”.
Wspólny identyfikator to klucz generowany dla każdego raportu w celu śledzenia rozliczeń raportów z możliwością agregacji. Udostępniony identyfikator sprawia, że raporty z tym samym udostępnionym identyfikatorem są uwzględniane tylko w jednym raporcie podsumowującym. Oznacza to, że raporty, które są powiązane z jednym udostępnionym identyfikatorem, muszą być zawarte w jednej partii. Jeśli na przykład raport X i raport Y mają ten sam udostępniony identyfikator, muszą być uwzględnione w tej samej partii, aby uniknąć odrzucenia raportów z powodu duplikacji.
Obraz poniżej przedstawia komponenty shared_info, które są haszowane razem w celu wygenerowania wspólnego identyfikatora.
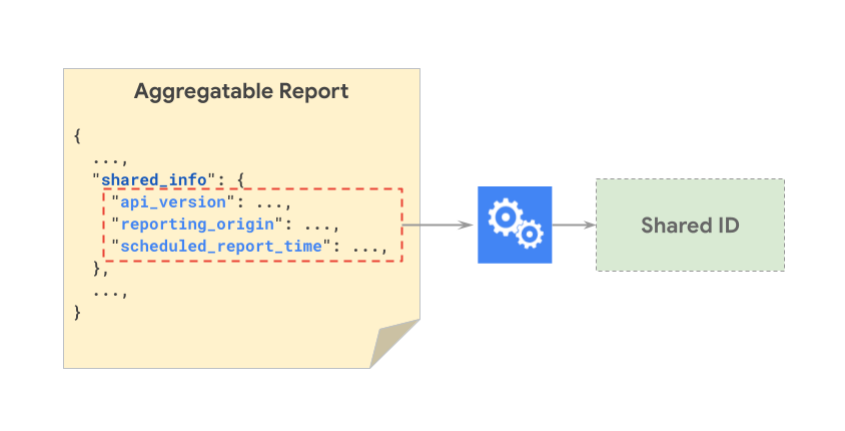
Ilustracja poniżej pokazuje, jak 2 różne raporty mogą mieć ten sam udostępniony identyfikator:

Uwaga: wartość scheduled_report_time jest skracana do godziny, a wartość source_registration_time – do dnia. Ponadto przy tworzeniu identyfikatora wspólnego nie używa się znaku report_id. Granulacja czasu może zostać w przyszłości zaktualizowana.
Duplikowanie raportów w ramach partii
Pole shared_info w raporcie z możliwością agregacji zawiera unikalny identyfikator użytkownika w polu report_id, który służy do identyfikowania zduplikowanych raportów w partii. Jeśli w partii znajduje się więcej niż 1 raport z tym samym report_id, tylko pierwszy z nich zostanie zagregowany, a pozostałe zostaną uznane za duplikaty i cicho odrzucone. Agregacja będzie przebiegać normalnie i nie zostaną wysłane żadne błędy.
Chociaż nie jest to wymagane, platformy reklamowe mogą spodziewać się wzrostu skuteczności, jeśli przed agregacją odfiltrują zduplikowane raporty o tych samych identyfikatorach.
Symbol report_id jest unikalny dla każdego raportu.
Duplikowanie raportów w różnych partiach
Każdy raport ma przypisany udostępniony identyfikator, który jest generowany na podstawie połączonych punktów danych pochodzących z pola shared_info raportu. Wiele raportów może mieć ten sam udostępniony identyfikator, a każda partia może zawierać wiele udostępnionych identyfikatorów. Wszystkie raporty z tym samym udostępnionym identyfikatorem muszą znajdować się w tej samej partii. Jeśli raporty z tym samym udostępnionym identyfikatorem trafią do kilku partii, tylko pierwsza z nich zostanie zaakceptowana, a pozostałe zostaną odrzucone jako duplikaty. Aby temu zapobiec, należy odpowiednio tworzyć partie.
Na poniższym obrazie widać przykład, w którym raporty z tym samym udostępnionym identyfikatorem w różnych partiach mogą spowodować niepowodzenie późniejszej partii. Na ilustracji widać, że co najmniej 2 raporty o tym samym udostępnionym identyfikatorzee679aa są dzielone na różne partie 1 i 2. Budżet wszystkich raportów z udostępnionym identyfikatorem
e679aa jest wykorzystywany podczas generowania raportu podsumowującego partię 1, więc partia 2 jest niedozwolona i kończy się błędem.
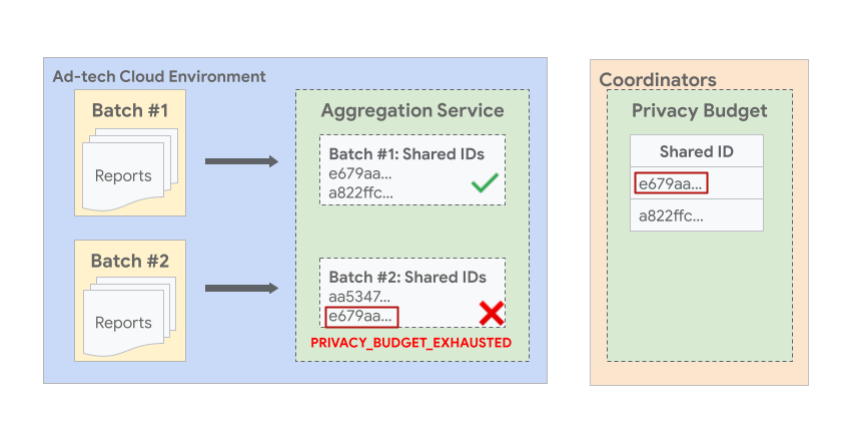
Raporty zbiorcze
Poniżej znajdziesz zalecane sposoby tworzenia raportów zbiorczych, które pozwolą uniknąć duplikatów i zoptymalizować rozliczanie raportów zbiorczych.
Grupowanie według reklamodawcy
Uwaga: ta strategia jest zalecana tylko w przypadku agregacji raportów atrybucji.
Interfejs Private Aggregation nie ma pola attribution_destination, które jest reklamodawcą. Zalecamy grupowanie raportów według reklamodawcy, co oznacza, że w tej samej grupie powinny się znajdować raporty należące do jednego reklamodawcy. Pozwoli to uniknąć osiągnięcia limitu konta raportu z możliwością agregacji w przypadku każdej grupy. Pole Reklamodawca jest brane pod uwagę podczas generowania udostępnionego identyfikatora, więc raporty dotyczące tego samego reklamodawcy mogą mieć ten sam udostępniony identyfikator, co wymaga umieszczenia ich w tej samej partii, aby uniknąć błędów.
Grupowanie według czasu
Podczas przetwarzania wsadowego zalecamy uwzględnianie zaplanowanego czasu raportushared_info.scheduled_report_time. Czas zaplanowanego raportu jest obcinany do godziny w procesie generowania udostępnionego identyfikatora, więc raporty powinny być grupowane co najmniej co godzinę. Oznacza to, że wszystkie raporty z czasem zaplanowanego raportu w tej samej godzinie powinny być umieszczane w tej samej partii, aby uniknąć sytuacji, w której raporty z tym samym udostępnionym identyfikatorem znajdują się w wielu partiach, co prowadzi do błędów zadań.
Częstotliwość i szum
Zalecamy uwzględnienie wpływu szumu na częstotliwość przetwarzania raportów z możliwością agregacji. Jeśli raporty zbiorcze są przetwarzane częściej, np. raz na godzinę, będzie w nich mniej zdarzeń konwersji, a szum będzie miał większy wpływ względny. Jeśli częstotliwość zostanie zmniejszona, a raporty będą przetwarzane raz w tygodniu, szum będzie miał mniejszy wpływ względny. Aby lepiej zrozumieć wpływ szumu na partie, przeprowadź eksperyment w Laboratorium szumu.