
对可汇总报告进行批处理时,务必要优化批处理策略,以免超出隐私限制。以下是一些建议的策略,可用于向 Aggregation Service 发送批量报告。
收集报告
收集要纳入批次中的报告时,请注意以下几点:
报告上传重试
注意:重试条件可能会有变动。在这种情况下,本部分中的信息将会更新。
在 Web 平台和操作系统平台中,平台会尝试发送报告三次,但如果第三次尝试后仍无法发送报告,则不会再发送。无论何时能够发送报告,原始 scheduled_report_time 值都会保留。重试的时间表因平台而异:
- Web 浏览器会在联网时发送报告。如果报告发送失败,系统会等待 5 分钟后进行第二次重试,然后等待 15 分钟后进行第三次重试。如果浏览器离线,则会在浏览器恢复在线状态后一分钟进行下一次重试。在网络上发送报告时,没有最长延迟时间;这意味着,如果浏览器离线,无论报告是多久之前生成的,一旦浏览器重新上线,它都会尝试根据重试政策发送报告。
- Android 手机的网络连接稳定。因此,它将每小时运行一次作业以发送报告。这意味着,如果报告发送失败,系统会在下一小时重试,并在之后的一小时再次重试。如果设备没有连接,则设备会在下次报告作业运行时(在设备重新连接到网络后)重试发送报告。最长延迟时间为 28 天,这意味着设备不会发送 28 天前生成的报告。
等待报告
建议在收集报告以进行批处理时,等待迟到的报告。您可以通过将 scheduled_report_time 值与收到报告的时间进行比较,来确定报告是否延迟。这些报告之间的时间差将有助于确定您可能需要等待多长时间才能获得延迟到达的报告。例如,在收集延迟报告时,检查 scheduled_report_time 字段,并记录在收到 90%、95% 和 99% 的报告时的时间延迟(以小时为单位)。该数据可用于确定等待延迟到达的报告的时间。
即时汇总报告可用于降低报告延迟的几率。
下图显示了根据预定的报告时间,将延迟到达的报告存储在相应批次中的情况。批次 T 表示 scheduled_report_time,而 T+X 表示延迟报告的等待时间。这样一来,系统会生成一份汇总报告,其中包含批次中与预定报告时间相对应的绝大部分报告。
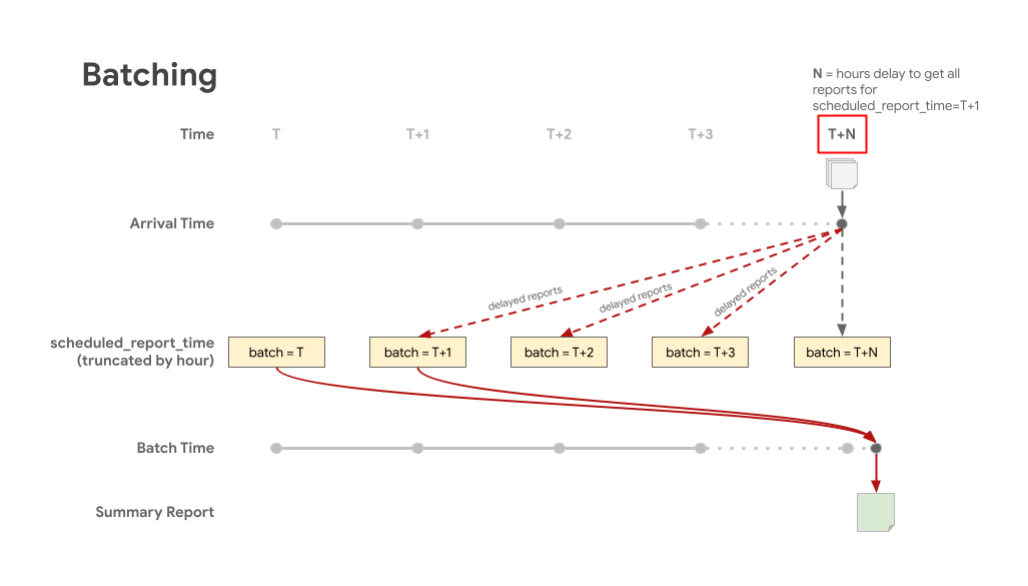
可汇总报告的会计核算
Aggregation Service 会维护“无重复项”规则。此规则强制规定,具有相同共享 ID 的所有可汇总报告都必须包含在同一批次中。
收集报告后,应将它们分批处理,以便具有相同共享 ID 的所有报告都属于一个批次。
如果报告已在另一个批次中处理过,则处理可能会导致隐私保护预算耗尽错误。 正确批处理报告有助于防止批次因“不得重复”规则而被拒绝。
共享 ID 是为每个报告生成的用于跟踪可汇总报告结算情况的密钥。共享 ID 可确保具有相同共享 ID 的报告仅贡献给一个汇总报告。这意味着,映射到同一共享 ID 的报告必须全部包含在单个批次中。例如,如果报告 X 和报告 Y 具有相同的共享 ID,则必须将它们包含在同一批次中,以避免因重复而丢弃报告。
下图展示了经过哈希处理后生成共享 ID 的 shared_info 组件。
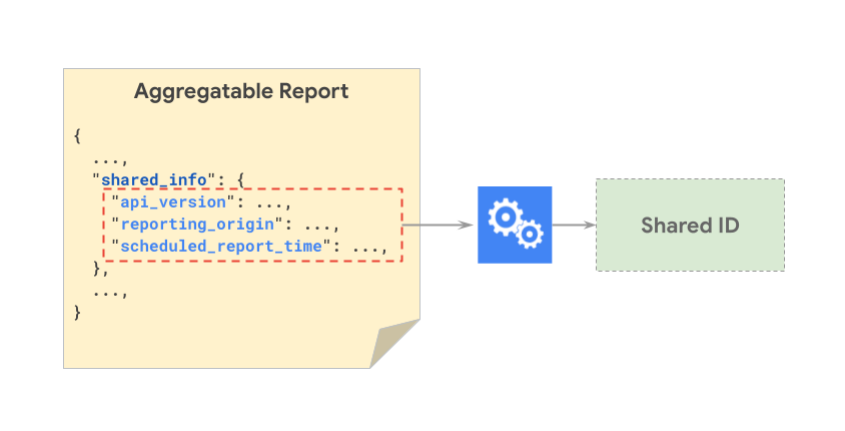
下图展示了两个不同的报告如何具有相同的共享 ID:

注意: scheduled_report_time 按小时截断,source_registration_time 按天截断。此外,共享 ID 的创建过程中不使用 report_id。时间粒度未来可能会更新。
批次中的重复报告
可汇总报告中的 shared_info 字段包含 report_id 字段中的 UUID,用于识别批次中的重复报告。如果批次中存在多个具有相同 report_id 的报告,则系统只会汇总第一个报告,其余报告将被视为重复报告并被静默舍弃;汇总将正常进行,不会发送任何错误。
虽然不是必需的,但广告技术平台可以通过在聚合之前过滤掉具有相同报告 ID 的重复报告,来获得一定的效果提升。
report_id 对于每份报告都是唯一的。
批次间的重复报告
每份报告都会获得一个共享 ID,该 ID 是根据报告的 shared_info 字段中的组合数据点生成的。多个报告可以具有相同的共享 ID,并且每个批次可以包含多个共享 ID。具有相同共享 ID 的所有报告都必须位于同一批次中。如果具有相同共享 ID 的报告最终出现在多个批次中,系统只会接受第一个批次,而其余批次会被拒绝,因为它们是重复的。为防止这种情况,必须正确创建批次。
下图显示了一个示例,其中批次之间具有相同共享 ID 的报告可能会导致后续批次失败。在图片中,您可以看到具有相同共享 ID e679aa 的两个或更多个报告被分批处理为不同的批次 #1 和 #2。由于在生成批次 1 摘要报告期间,系统会消耗具有共享 ID e679aa 的所有报告的预算,因此不允许生成批次 2,并且会因错误而失败。
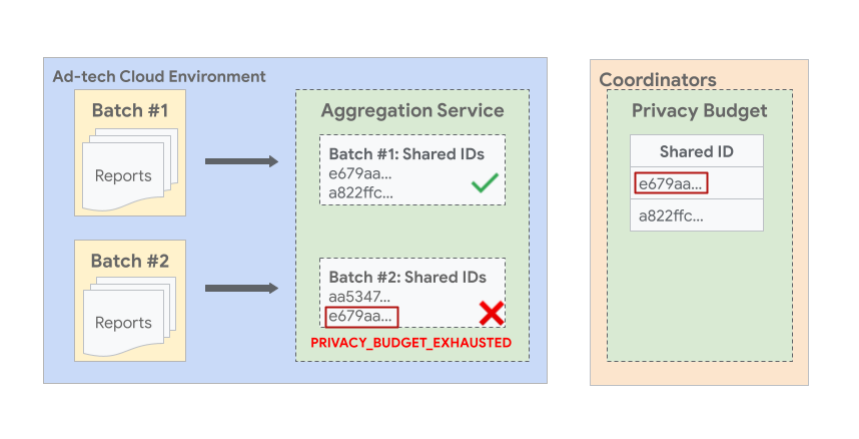
批量报告
以下是建议的报告批处理方式,可避免重复并优化汇总报告的统计。
按广告客户批量处理
注意:此策略仅建议用于 Attribution Reporting 汇总。
Private Aggregation 没有 attribution_destination 字段(即广告客户)。建议按广告客户进行批处理,即在同一批处理中包含属于同一广告客户的报告,以避免达到每个批处理的可汇总报告账号限制。广告客户是生成共享 ID 时考虑的字段,因此具有相同广告客户的报告也可能具有相同的共享 ID,这要求它们必须位于同一批次中,以避免出现错误。
按时间分批
建议在进行批处理时考虑报告的预定报告时间 (shared_info.scheduled_report_time)。在共享 ID 生成过程中,系统会将预定报告时间截断到小时,因此报告至少应按小时间隔进行批处理,这意味着预定报告时间在同一小时内的所有报告都应放在同一批中,以避免多个批次中出现具有相同共享 ID 的报告,从而导致作业错误。
批次频率和噪声
建议您考虑噪声对可汇总报告处理频率的影响。如果可汇总报告的批处理频率更高(例如,每小时处理一次报告),则包含的转化事件会更少,噪声的相对影响也会更大。如果降低频率并每周处理一次报告,噪声的相对影响会更小。如需更好地了解噪声对批次的影响,请尝试使用 Noise Lab。