
Ao agrupar relatórios agregáveis, é importante otimizar as estratégias de agrupamento para que os limites de privacidade não sejam excedidos. Confira algumas estratégias recomendadas para enviar lotes de relatórios ao serviço de agregação.
Coletar relatórios
Ao coletar relatórios para incluir em um lote, lembre-se do seguinte:
Tentativas de upload de relatórios
Observação:os critérios de nova tentativa estão sujeitos a mudanças. As informações nesta seção serão atualizadas nesse caso.
Nas plataformas da Web e do SO, uma plataforma tenta enviar o relatório três vezes. Se ele não for enviado após a terceira tentativa, não será enviado. O valor original de scheduled_report_time é preservado, não importa quando o relatório possa ser enviado. O
cronograma para novas tentativas é diferente em cada plataforma:
- Um navegador da Web envia relatórios quando está on-line. Se o envio falhar, o sistema vai esperar cinco minutos para a segunda tentativa e 15 minutos para a terceira. Se o navegador ficar off-line, a próxima tentativa será um minuto depois que ele voltar a ficar on-line. Não há um atraso máximo no envio de relatórios na Web. Isso significa que, se o navegador ficar off-line, não importa há quanto tempo o relatório foi gerado, assim que o navegador voltar a ficar on-line, ele tentará enviar o relatório de acordo com a política de novas tentativas.
- Um smartphone Android tem uma conexão de rede consistente. Assim, ele vai executar o job para enviar relatórios uma vez por hora. Isso significa que, se um relatório não for enviado, ele será reenviado na próxima hora e novamente na hora seguinte. Se o dispositivo não tiver uma conexão, ele vai tentar enviar o relatório novamente com o próximo job de geração de relatórios que for executado depois que o dispositivo se conectar à rede novamente. O atraso máximo é de 28 dias, o que significa que o dispositivo não vai enviar um relatório gerado há mais de 28 dias.
Aguardar relatórios
Recomendamos aguardar os relatórios que chegam atrasados ao coletar dados para o agrupamento em lote. Para saber se um relatório foi enviado com atraso, compare o valor de scheduled_report_time com a data de recebimento. A diferença de tempo entre esses relatórios ajuda a determinar quanto tempo você precisa esperar para receber os relatórios atrasados. Por exemplo, à medida que os relatórios atrasados são coletados, verifique o campo scheduled_report_time e observe o atraso em horas à medida que 90%, 95% e 99% dos relatórios são recebidos. Esses dados podem ser usados para determinar quanto tempo esperar pelos relatórios que chegam atrasados.
Os relatórios agregados instantâneos podem ser usados para reduzir a chance de atrasos.
A visualização a seguir mostra relatórios atrasados sendo armazenados nos lotes adequados de acordo com o horário programado. O lote T representa scheduled_report_time, e T+X representa o tempo de espera para relatórios atrasados. Isso resulta em um relatório de resumo que inclui a maioria dos relatórios incluídos no lote, que corresponde ao horário programado.
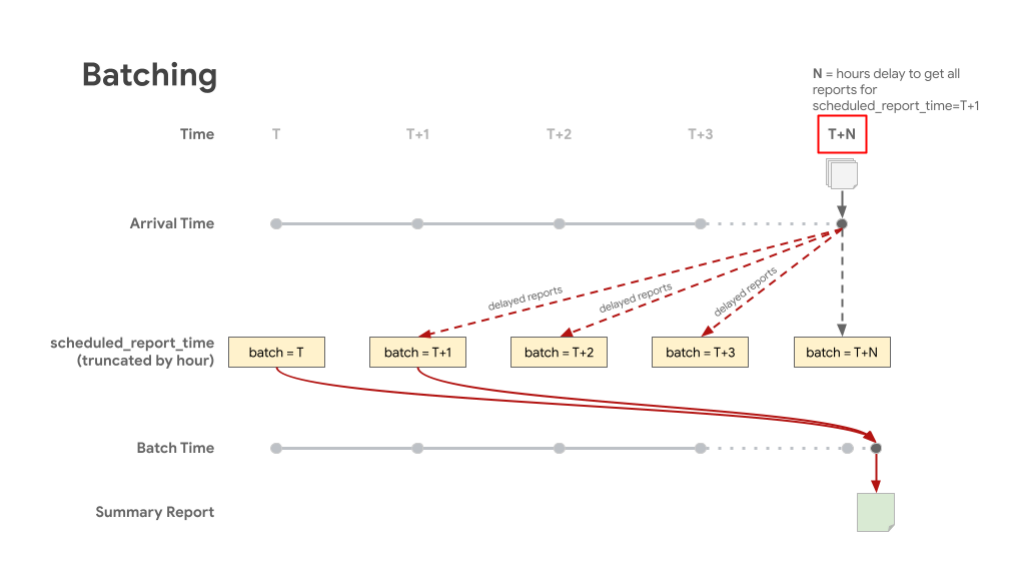
Contabilização de relatórios agregáveis
O Aggregation Service mantém uma regra de"sem duplicados". Essa regra exige que todos os relatórios agregáveis com o mesmo ID compartilhado sejam incluídos no mesmo lote.
Depois que os relatórios são coletados, eles precisam ser agrupados de forma que todos os relatórios com o mesmo ID compartilhado façam parte de um lote.
Se um relatório já foi processado em outro lote, o processamento pode resultar em um erro de orçamento de privacidade esgotado. O agrupamento correto de relatórios ajuda a evitar que eles sejam rejeitados devido à regra "sem duplicados".
Um ID compartilhado é uma chave gerada para cada relatório e rastreia a contabilidade de relatórios agregáveis. O ID compartilhado garante que os relatórios com o mesmo ID contribuam para apenas um relatório de resumo. Isso significa que os relatórios que mapeiam um ID compartilhado precisam ser incluídos em um único lote. Por exemplo, se o relatório X e o relatório Y tiverem o mesmo ID compartilhado, eles precisarão ser incluídos no mesmo lote para evitar que sejam descartados por duplicação.
A imagem a seguir demonstra os componentes shared_info que são combinados com hash para gerar um ID compartilhado.

A imagem a seguir demonstra como dois relatórios diferentes podem ter o mesmo ID compartilhado:

Observação:scheduled_report_time é truncado por hora, e source_registration_time é truncado por dia. Além disso, report_id não é usado na criação de IDs compartilhados. A granularidade de tempo pode ser atualizada no futuro.
Duplicar relatórios em lotes
O campo shared_info em um relatório agregável contém um UUID no campo report_id, que é
usado para identificar relatórios duplicados em um lote. Se houver mais de um relatório com o mesmo report_id em um lote, apenas o primeiro será agregado, e os outros serão considerados duplicados e descartados silenciosamente. A agregação vai continuar normalmente, e nenhum erro será enviado.
Embora não seja obrigatório, a tecnologia de publicidade pode esperar alguns ganhos de performance ao filtrar os relatórios duplicados com os mesmos IDs antes da agregação.
O report_id é exclusivo para cada relatório.
Duplicar relatórios em lotes
Cada relatório recebe um ID compartilhado, que é gerado com base em pontos de dados combinados do campo shared_info do relatório. Vários relatórios podem ter o mesmo ID compartilhado, e cada lote pode conter vários IDs compartilhados. Todos os relatórios com o mesmo ID compartilhado precisam estar no mesmo lote. Se relatórios com o mesmo ID compartilhado acabarem em vários lotes, apenas o primeiro será aceito, e os outros serão rejeitados como duplicados. Para evitar isso, os lotes precisam ser criados de maneira adequada.
A imagem a seguir mostra um exemplo em que relatórios com o mesmo ID compartilhado em lotes podem fazer com que o lote posterior falhe. Na imagem, é possível ver que dois ou mais relatórios com o mesmo ID compartilhado
e679aa são agrupados em lotes diferentes nº 1 e nº 2. Como o orçamento de todos os relatórios com o ID compartilhado e679aa é consumido durante a geração do relatório de resumo do lote 1, o lote 2 não é permitido e falha com um erro.
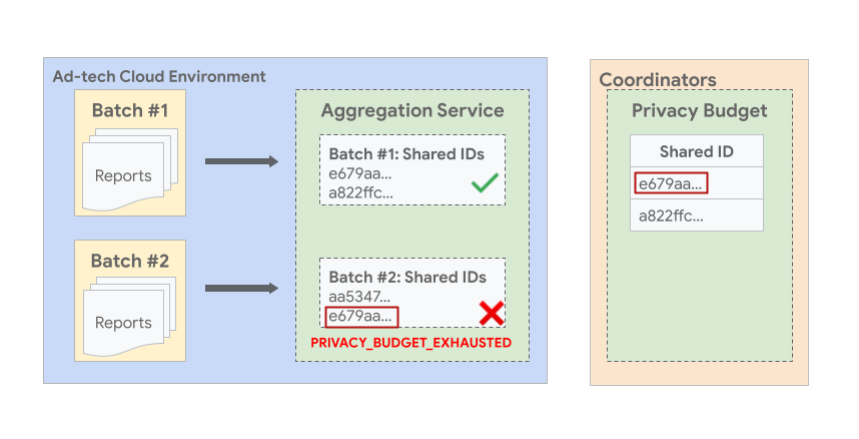
Relatórios em lote
Confira a seguir algumas maneiras recomendadas de agrupar relatórios para evitar duplicidades e otimizar a contabilidade de relatórios agregados.
Agrupar por anunciante
Observação:essa estratégia é recomendada apenas para agregação de relatórios de atribuição.
A Private Aggregation não tem um campo attribution_destination, que é o anunciante. Recomendamos o agrupamento por anunciante, ou seja, incluir relatórios de um único anunciante no mesmo lote para evitar atingir o limite de conta de relatório agregável para cada lote. "Anunciante" é um campo considerado na geração de IDs compartilhados. Portanto, relatórios com o mesmo anunciante também podem ter o mesmo ID compartilhado, o que exige que eles estejam no mesmo lote para evitar erros.
Agrupar por tempo
Recomendamos considerar o horário programado do relatório (shared_info.scheduled_report_time) ao fazer o agrupamento em lote. O horário do relatório programado é truncado por hora na geração de ID compartilhado. Portanto, os relatórios precisam ser agrupados em lotes com intervalos de uma hora. Isso significa que todos os relatórios com horário programado dentro da mesma hora precisam estar no mesmo lote para evitar que relatórios com o mesmo ID compartilhado apareçam em vários lotes, o que causa erros de job.
Frequência e ruído de lote
Recomendamos considerar o impacto do ruído na frequência com que os relatórios agregáveis são processados. Se os relatórios agregáveis forem agrupados com mais frequência (por exemplo, processados uma vez por hora), menos eventos de conversão serão incluídos, e o ruído terá um impacto relativo maior. Se a frequência for reduzida e os relatórios forem processados uma vez por semana, o ruído terá um impacto relativo menor. Para entender melhor o impacto do ruído nos lotes, faça um teste com o Noise Lab.