
เอกสารนี้สรุปแนวทางด้านความเป็นส่วนตัวสำหรับการปรับเปลี่ยนในแบบของคุณบนอุปกรณ์ (ODP) โดยเฉพาะในบริบทของความเป็นส่วนตัวเชิงอนุพันธ์ เราไม่ได้กล่าวถึงผลกระทบด้านความเป็นส่วนตัวอื่นๆ และการตัดสินใจด้านการออกแบบ เช่น การลดข้อมูลโดยเจตนา เพื่อให้เอกสารนี้มุ่งเน้นไปที่หัวข้อที่ต้องการ
Differential Privacy
ความเป็นส่วนตัวเชิงแตกต่าง 1 เป็นมาตรฐานการปกป้องความเป็นส่วนตัวที่ใช้กันอย่างแพร่หลายในการวิเคราะห์ข้อมูลทางสถิติและแมชชีนเลิร์นนิง 2 3 กล่าวอย่างไม่เป็นทางการคือ ศัตรูจะเรียนรู้สิ่งเดียวกันเกือบทั้งหมดเกี่ยวกับผู้ใช้จากเอาต์พุตของอัลกอริทึม Differential Privacy ไม่ว่าบันทึกของผู้ใช้จะปรากฏในชุดข้อมูลพื้นฐานหรือไม่ก็ตาม ซึ่งหมายถึงการคุ้มครองบุคคลอย่างเข้มงวด โดยการอนุมานเกี่ยวกับบุคคลใดก็ตามจะเกิดขึ้นได้ก็ต่อเมื่อเป็นคุณสมบัติรวมของชุดข้อมูลที่คงอยู่ไม่ว่าจะมีหรือไม่มีบันทึกของบุคคลนั้นก็ตาม
ในบริบทของแมชชีนเลิร์นนิง ควรพิจารณาผลลัพธ์ของอัลกอริทึมเป็นพารามิเตอร์ของโมเดลที่ฝึกแล้ว วลีที่ว่าเกือบจะเหมือนกันจะได้รับการวัดค่าทางคณิตศาสตร์ด้วยพารามิเตอร์ 2 รายการ (ε, δ) โดยปกติแล้ว ε จะเป็นค่าคงที่ขนาดเล็ก และ δ≪1/(จำนวนผู้ใช้)
ความหมายของความเป็นส่วนตัว
การออกแบบ ODP มีเป้าหมายเพื่อให้แน่ใจว่าการฝึกแต่ละครั้งเป็นแบบ (ε,δ) ที่มีความเป็นส่วนตัวแบบ Differential Privacy ระดับผู้ใช้ ต่อไปนี้คือแนวทางของเราในการเข้าถึงความหมายนี้
โมเดลภัยคุกคาม
เรากำหนดบทบาทของบุคคลต่างๆ และระบุสมมติฐานเกี่ยวกับแต่ละบทบาทดังนี้
- ผู้ใช้: ผู้ใช้ที่เป็นเจ้าของอุปกรณ์และเป็นผู้บริโภคผลิตภัณฑ์หรือบริการที่นักพัฒนาแอปให้บริการ โดยข้อมูลส่วนตัวของบุคคลดังกล่าวจะพร้อมให้บุคคลนั้นเข้าถึงได้อย่างเต็มที่
- สภาพแวดล้อมการดำเนินการที่เชื่อถือได้ (TEE): ข้อมูลและการคำนวณที่เชื่อถือได้ซึ่งเกิดขึ้นภายใน TEE จะได้รับการปกป้องจากผู้โจมตีโดยใช้เทคโนโลยีที่หลากหลาย ดังนั้นการคำนวณและข้อมูลจึงไม่จำเป็นต้องมีการป้องกันเพิ่มเติม TEE ที่มีอยู่อาจอนุญาตให้ผู้ดูแลโปรเจ็กต์เข้าถึงข้อมูลภายในได้ เราขอเสนอความสามารถที่กำหนดเองเพื่อไม่อนุญาตและตรวจสอบว่าผู้ดูแลระบบไม่สามารถเข้าถึงได้
- ผู้โจมตี: อาจมีข้อมูลด้านข้างเกี่ยวกับผู้ใช้และมีสิทธิ์เข้าถึงข้อมูลทั้งหมดที่ออกจาก TEE (เช่น พารามิเตอร์ของโมเดลที่เผยแพร่)
- นักพัฒนาโมเดล: ผู้ที่กำหนดและฝึกโมเดล ถือว่าไม่น่าเชื่อถือ (และมีความสามารถของแฮ็กเกอร์อย่างเต็มรูปแบบ)
เราพยายามออกแบบ ODP โดยใช้ความหมายของ Differential Privacy ดังต่อไปนี้
- ขอบเขตความน่าเชื่อถือ: จากมุมมองของผู้ใช้รายหนึ่ง ขอบเขตความน่าเชื่อถือประกอบด้วยอุปกรณ์ของผู้ใช้เองพร้อมกับ TEE ข้อมูลใดๆ ที่ออกจากขอบเขตความน่าเชื่อถือนี้ควรได้รับการปกป้องโดย Differential Privacy
- ผู้โจมตี: การปกป้องความเป็นส่วนตัวแบบ Differential Privacy อย่างเต็มรูปแบบเมื่อเทียบกับผู้โจมตี เอนทิตีใดก็ตามที่อยู่นอกขอบเขตความน่าเชื่อถืออาจเป็นผู้โจมตีได้ (ซึ่งรวมถึงนักพัฒนาแอปและผู้ใช้รายอื่นๆ ซึ่งอาจสมรู้ร่วมคิดกัน) ผู้โจมตีซึ่งมีข้อมูลทั้งหมดนอกขอบเขตความน่าเชื่อถือ (เช่น โมเดลที่เผยแพร่) ข้อมูลเสริมเกี่ยวกับผู้ใช้ และทรัพยากรไม่จำกัด จะไม่สามารถอนุมานข้อมูลส่วนตัวเพิ่มเติมเกี่ยวกับผู้ใช้ (นอกเหนือจากข้อมูลที่มีอยู่แล้วในข้อมูลเสริม) ได้ โดยมีโอกาสสูงสุดตามที่งบประมาณความเป็นส่วนตัวกำหนด โดยเฉพาะอย่างยิ่ง ซึ่งหมายถึงการคุ้มครองความเป็นส่วนตัวแบบ Differential Privacy อย่างเต็มรูปแบบสำหรับนักพัฒนาแอป ข้อมูลใดๆ ที่เผยแพร่แก่นักพัฒนาแอป (เช่น พารามิเตอร์ของโมเดลที่ฝึกแล้วหรือการอนุมานแบบรวม) จะได้รับการคุ้มครองความเป็นส่วนตัวเชิงแตกต่าง
พารามิเตอร์โมเดลในเครื่อง
ความหมายด้านความเป็นส่วนตัวก่อนหน้านี้รองรับกรณีที่พารามิเตอร์โมเดลบางส่วนอยู่ในอุปกรณ์ (เช่น โมเดลที่มีการฝังผู้ใช้ที่เฉพาะเจาะจงสำหรับผู้ใช้แต่ละราย และไม่ได้แชร์ในหมู่ผู้ใช้) สำหรับโมเดลดังกล่าว พารามิเตอร์ในเครื่องเหล่านี้จะยังคงอยู่ภายในขอบเขตความน่าเชื่อถือ (ไม่ได้เผยแพร่) และไม่จำเป็นต้องมีการป้องกัน ในขณะที่พารามิเตอร์โมเดลที่แชร์จะได้รับการเผยแพร่ (และได้รับการปกป้องโดยความเป็นส่วนตัวเชิงแตกต่าง) บางครั้งเรียกว่าโมเดลความเป็นส่วนตัวแบบป้ายโฆษณา 4
ฟีเจอร์สาธารณะ
ในบางแอปพลิเคชัน ฟีเจอร์บางอย่างจะเป็นแบบสาธารณะ ตัวอย่างเช่น ในปัญหาการแนะนำภาพยนตร์ ฟีเจอร์ของภาพยนตร์ (ผู้กำกับ ประเภท หรือปีที่ภาพยนตร์ออกฉาย) เป็นข้อมูลสาธารณะและไม่จำเป็นต้องได้รับการปกป้อง ในขณะที่ฟีเจอร์ที่เกี่ยวข้องกับผู้ใช้ (เช่น ข้อมูลประชากรหรือภาพยนตร์ที่ผู้ใช้ดู) เป็นข้อมูลส่วนตัวและจำเป็นต้องได้รับการปกป้อง
ข้อมูลสาธารณะจะได้รับการจัดรูปแบบเป็นเมทริกซ์ฟีเจอร์สาธารณะ (ในตัวอย่างก่อนหน้า เมทริกซ์นี้จะมี 1 แถวต่อภาพยนตร์ 1 เรื่อง และ 1 คอลัมน์ต่อฟีเจอร์ภาพยนตร์ 1 รายการ) ซึ่งพร้อมให้ทุกฝ่ายใช้งาน อัลกอริทึมการฝึกแบบ Differential Privacy สามารถใช้เมทริกซ์นี้ได้โดยไม่ต้องปกป้อง ดูตัวอย่างได้ที่ 5 แพลตฟอร์ม ODP วางแผนที่จะใช้อัลกอริทึมดังกล่าว
แนวทางด้านความเป็นส่วนตัวในระหว่างการคาดการณ์หรือการอนุมาน
การอนุมานจะอิงตามพารามิเตอร์ของโมเดลและฟีเจอร์อินพุต พารามิเตอร์โมเดลได้รับการฝึกด้วยความหมายของ Differential Privacy ในส่วนนี้จะกล่าวถึงบทบาทของฟีเจอร์อินพุต
ในกรณีการใช้งานบางอย่าง เมื่อนักพัฒนาแอปมีสิทธิ์เข้าถึงฟีเจอร์ที่ใช้ในการอนุมานอย่างเต็มรูปแบบอยู่แล้ว ก็จะไม่มีข้อกังวลด้านความเป็นส่วนตัวจากการอนุมาน และนักพัฒนาแอปอาจเห็นผลลัพธ์การอนุมาน
ในกรณีอื่นๆ (เมื่อฟีเจอร์ที่ใช้ในการอนุมานเป็นแบบส่วนตัวและนักพัฒนาแอปเข้าถึงไม่ได้) ระบบอาจซ่อนผลการอนุมานจากนักพัฒนาแอป เช่น โดยการอนุมาน (และกระบวนการดาวน์สตรีมใดๆ ที่ใช้ผลการอนุมาน) ให้ทำงานในอุปกรณ์ ในกระบวนการและพื้นที่แสดงผลที่ระบบปฏิบัติการเป็นเจ้าของ โดยมีการจำกัดการสื่อสารภายนอกกระบวนการนั้น
ขั้นตอนการฝึก
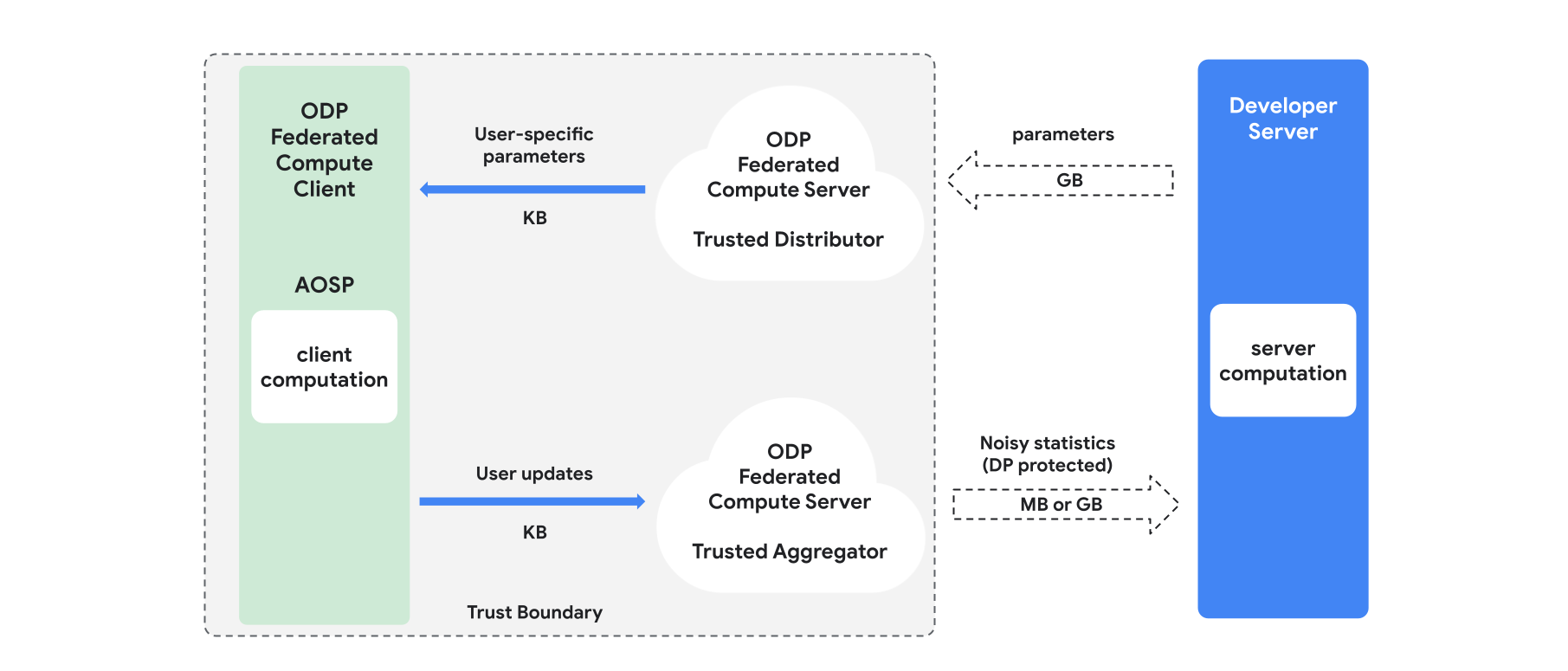
ภาพรวม
ส่วนนี้จะแสดงภาพรวมของสถาปัตยกรรมและวิธีดำเนินการฝึกอบรม ดังแสดงในรูปที่ 1 ODP ใช้คอมโพเนนต์ต่อไปนี้
ผู้จัดจำหน่ายที่เชื่อถือได้ เช่น Federated Select, Trusted Download หรือ Private Information Retrieval ซึ่งมีบทบาทเป็นพารามิเตอร์โมเดลการออกอากาศ ระบบจะถือว่าผู้จัดจำหน่ายที่เชื่อถือได้สามารถส่งชุดย่อยของพารามิเตอร์ไปยังไคลเอ็นต์แต่ละรายได้โดยไม่ต้องเปิดเผยว่าไคลเอ็นต์รายใดดาวน์โหลดพารามิเตอร์ใด "การออกอากาศบางส่วน" นี้ช่วยให้ระบบลดร่องรอยในอุปกรณ์ของผู้ใช้ปลายทางได้ โดยจะส่งเฉพาะพารามิเตอร์บางส่วนของโมเดลไปยังผู้ใช้ที่กำหนด แทนที่จะส่งสำเนาโมเดลทั้งหมด
ผู้รวบรวมข้อมูลที่เชื่อถือได้ ซึ่งรวบรวมข้อมูลจากไคลเอ็นต์หลายราย (เช่น การไล่ระดับสีหรือสถิติอื่นๆ) เพิ่มสัญญาณรบกวน และส่งผลลัพธ์ไปยังเซิร์ฟเวอร์ โดยสมมติว่ามีช่องทางที่เชื่อถือได้ระหว่างไคลเอ็นต์กับผู้รวบรวม และระหว่างไคลเอ็นต์กับผู้จัดจำหน่าย
อัลกอริทึมการฝึก DP ที่ทำงานบนโครงสร้างพื้นฐานนี้ อัลกอริทึมการฝึกแต่ละรายการประกอบด้วยการคำนวณที่แตกต่างกันซึ่งทำงานในคอมโพเนนต์ต่างๆ (เซิร์ฟเวอร์ ไคลเอ็นต์ ตัวรวบรวม ผู้จัดจำหน่าย)
การฝึกอบรมโดยทั่วไปมีขั้นตอนดังนี้
- เซิร์ฟเวอร์จะออกอากาศพารามิเตอร์ของโมเดลไปยังผู้จัดจำหน่ายที่เชื่อถือได้
- การคำนวณฝั่งไคลเอ็นต์
- อุปกรณ์ไคลเอ็นต์แต่ละเครื่องจะได้รับโมเดลการออกอากาศ (หรือชุดย่อยของพารามิเตอร์ที่เกี่ยวข้องกับผู้ใช้)
- ไคลเอ็นต์แต่ละรายจะทำการคำนวณบางอย่าง (เช่น การคำนวณการไล่ระดับสีหรือสถิติอื่นๆ ที่เพียงพอ)
- ไคลเอ็นต์แต่ละรายจะส่งผลลัพธ์ของการคำนวณไปยังผู้รวบรวมข้อมูลที่เชื่อถือได้
- ผู้รวบรวมข้อมูลที่เชื่อถือได้จะรวบรวม รวบรวม และปกป้องสถิติจากไคลเอ็นต์โดยใช้กลไก Differential Privacy ที่เหมาะสม จากนั้นจะส่งผลลัพธ์ไปยังเซิร์ฟเวอร์
- การคำนวณฝั่งเซิร์ฟเวอร์
- เซิร์ฟเวอร์ (ไม่น่าเชื่อถือ) จะเรียกใช้การคำนวณสถิติที่ได้รับการปกป้องความเป็นส่วนตัวเชิงแตกต่าง (เช่น ใช้การไล่ระดับสีแบบรวมที่ได้รับการปกป้องความเป็นส่วนตัวเชิงแตกต่างเพื่ออัปเดตพารามิเตอร์ของโมเดล)
โมเดลที่แยกตัวประกอบและ Differentially Private Alternating Minimization
แพลตฟอร์ม ODP วางแผนที่จะจัดเตรียมอัลกอริทึมการฝึกแบบส่วนตัวเชิงอนุพันธ์อเนกประสงค์ที่ใช้ได้กับสถาปัตยกรรมโมเดลใดก็ได้ (เช่น DP-SGD 6 7 8 หรือ DP-FTRL 9 10 รวมถึงอัลกอริทึมที่เชี่ยวชาญสำหรับโมเดลแบบแยกตัวประกอบ)
โมเดลที่แยกตัวประกอบได้คือโมเดลที่สามารถแยกย่อยเป็นโมเดลย่อย (เรียกว่าตัวเข้ารหัสหรือทาวเวอร์) ตัวอย่างเช่น พิจารณารูปแบบโมเดล f(u(θu, xu), v(θv, xv)) โดยที่ u() จะเข้ารหัสฟีเจอร์ผู้ใช้ xu (และมีพารามิเตอร์ θu) และ v() จะเข้ารหัสฟีเจอร์ที่ไม่ใช่ผู้ใช้ xv (และมีพารามิเตอร์ θv) จากนั้นจะรวมการเข้ารหัสทั้ง 2 รายการโดยใช้ f() เพื่อสร้างการคาดการณ์โมเดลขั้นสุดท้าย ตัวอย่างเช่น ในโมเดลการแนะนำภาพยนตร์ xu คือฟีเจอร์ของผู้ใช้ และ xv คือฟีเจอร์ของภาพยนตร์
โมเดลดังกล่าวเหมาะกับสถาปัตยกรรมระบบแบบกระจายที่กล่าวถึงข้างต้น (เนื่องจากแยกฟีเจอร์ของผู้ใช้และผู้ที่ไม่ได้เป็นผู้ใช้)
ระบบจะฝึกโมเดลที่แยกตัวประกอบโดยใช้ Differentially Private Alternating Minimization (DPAM) ซึ่งจะสลับระหว่างการเพิ่มประสิทธิภาพพารามิเตอร์ θu (ขณะที่ θv คงที่) และในทางกลับกัน อัลกอริทึม DPAM แสดงให้เห็นว่ามีประโยชน์มากขึ้นในการตั้งค่าต่างๆ 4 11 โดยเฉพาะอย่างยิ่งเมื่อมีฟีเจอร์สาธารณะ
ข้อมูลอ้างอิง
- 1: Dwork et al. Calibrating Noise to Sensitivity in Private Data Analysis, TCC'06
- 2: สำนักงานสำรวจสำมะโนประชากรของสหรัฐอเมริกา ทำความเข้าใจ Differential Privacy, 2020
- 3: Federated Learning with Formal Differential Privacy Guarantees, Google AI Blog Post, 2020
- 4: Jain et al. Differentially Private Model Personalization, NeurIPS'21
- 5: Krichene et al. Private Learning with Public Features, 2023
- 6: Song et al. Stochastic gradient descent with differentially private updates, GlobalSIP'13
- 7: Differentially Private Empirical Risk Minimization: Efficient Algorithms and Tight Error Bounds, FOCS'14
- 8: Abadi et al. Deep Learning with Differential Privacy, CCS '16
- 9: Smith et al. (Nearly) Optimal Algorithms for Private Online Learning in Full-information and Bandit Settings, NeurIPS'13
- 10: Kairouz และคณะ Practical and Private (Deep) Learning without Sampling or Shuffling, ICML'21
- 11: Chien et al. Private Alternating Least Squares, ICML'21