
This document summarizes the privacy approach for On-Device Personalization (ODP) specifically in the context of differential privacy. Other privacy implications and design decisions such as data minimization are intentionally left out to keep this document focussed.
Differential privacy
Differential privacy 1 is a widely adopted standard of privacy protection in statistical data analysis and machine learning 2 3. Informally, it says that an adversary learns almost the same thing about a user from the output of a differentially private algorithm whether or not their record appears in the underlying dataset. This implies strong protections for individuals: any inferences made about a person can only be due to aggregate properties of the dataset that would hold with or without that person's record.
In the context of machine learning, the output of the algorithm should be thought of as the trained model parameters. The phrase almost the same thing is mathematically quantified by two parameters (ε, δ), where ε is typically chosen to be a small constant, and δ≪1/(number of users).
Privacy semantics
The ODP design seeks to ensure each training run is (ε,δ)-user level differentially private. The following outlines our approach to reach this semantic.
Threat model
We define the different parties, and state assumptions about each:
- User: The user who owns the device, and are consumers of products or services provided by the developer. Their private information is fully available to themselves.
- Trusted execution environment (TEE): Data and trusted computations that occur within TEEs are protected from attackers using a variety of technologies. Therefore, the computation and data require no additional protection. Existing TEEs may allow its project admins to access the information inside. We propose custom capabilities to disallow and validate that access is unavailable to an administrator.
- The attacker: May have side information about the user and has full access to any information leaving the TEE (such as the published model parameters).
- Developer: One who defines and trains the model. Is considered untrusted (and has the full extent of an attacker's ability).
We seek to design ODP with the following semantics of differential privacy:
- Trust boundary: From the perspective of one user, the trust boundary consists of the user's own device along with the TEE. Any information that leaves this trust boundary should be protected by differential privacy.
- Attacker: Full differential privacy protection with respect to the attacker. Any entity outside the trust boundary can be an attacker (this includes the developer and other users, all potentially colluding). The attacker, given all information outside the trust boundary (for example, the published model), any side information about the user, and infinite resources, is not able to infer additional private data about the user (beyond those already in the side information), up to the odds given by the privacy budget. In particular, this implies a full differential privacy protection with respect to the developer. Any information released to the developer (such as trained model parameters or aggregate inferences) are differential privacy-protected.
Local model parameters
The previous privacy semantics accommodates the case where some of the model parameters are local to the device (for example a model that contains a user embedding specific to each user, and not shared across users). For such models, these local parameters remain within the trust boundary (they are not published) and require no protection, while shared model parameters are published (and are protected by differential privacy). This is sometimes referred to as the billboard privacy model 4.
Public features
In certain applications, some of the features are public. For example, in a movie recommendation problem, a movie's features (the director, genre, or release year of the movie) are public information and don't require protection, while features related to the user (such as demographic information or which movies the user watched) are private data and require protection.
The public information is formalized as a public feature matrix (in the previous example, this matrix would contain one row per movie and one column per movie feature), that is available to all parties. The differentially private training algorithm can make use of this matrix without the need to protect it, see for example 5. The ODP platform plans to implement such algorithms.
An approach towards privacy during prediction or inference
Inferences are based on the model parameters and on input features. The model parameters are trained with differential privacy semantics. Here, the role of input features is discussed.
In some use cases, when the developer already has full access to the features used in inference, there is no privacy concern from inference and the inference result may be visible to the developer.
In other cases (when features used in inference are private and not accessible to the developer), the inference result may be hidden from the developer, for example, by having the inference (and any downstream process that uses the inference result) run on-device, in an OS-owned process and display area, with restricted communication outside that process.
Training procedure
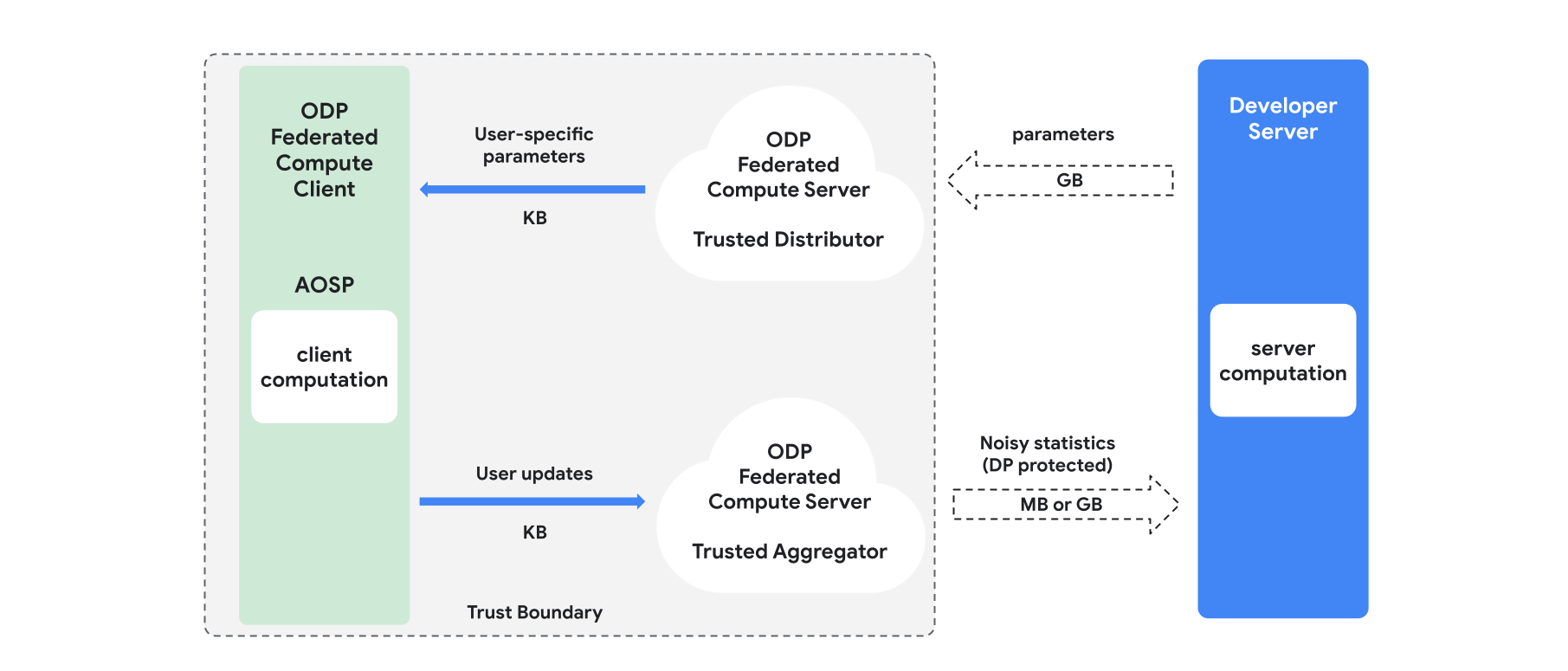
Overview
This section gives an overview of the architecture, and how training proceeds, see Figure 1. ODP implements the following components:
A trusted distributor, such as federated select, trusted download or private information retrieval, which plays the role of broadcasting model parameters. It is assumed that the trusted distributor can send a subset of parameters to each client, without revealing what parameters were downloaded by what client. This "partial broadcast" allows the system to minimize the footprint on the end-user device: instead of sending a full copy of the model, only a fraction of the model parameters is sent to any given user.
A trusted aggregator, which aggregates information from multiple clients (e.g. gradients, or other statistics), adds noise, and sends the result to the server. The assumption is that there are trusted channels between the client and aggregator, and between the client and distributor.
DP training algorithms that run on this infrastructure. Each training algorithm consists of different computations running on the different components (server, client, aggregator, distributor).
A typical round of training consists of the following steps:
- The server broadcasts model parameters to the trusted distributor.
- Client computation
- Each client device receives the broadcast model (or the subset of parameters relevant to the user).
- Each client performs some computation (for example computing gradients or other sufficient statistics).
- Each client sends the result of the computation to the trusted aggregator.
- The trusted aggregator collects, aggregates, and protects using proper differential privacy mechanisms the statistics from clients, then sends the result to the server.
- Server computation
- The (untrusted) server runs computations on the differentially privacy protected statistics (for example uses differentially private aggregated gradients to update the model parameters).
Factorized Models and Differentially Private Alternating Minimization
The ODP platform plans to provide general-purpose differentially private training algorithms that can be applied to any model architecture (such as DP-SGD 6 7 8 or DP-FTRL 9 10, as well as algorithms specialized to factorized models.
Factorized models are models that can be decomposed into sub-models (called encoders, or towers). For example, consider a model of the form f(u(θu, xu), v(θv, xv)), where u() encodes user features xu (and has parameters θu), and v() encodes non-user features xv (and has parameters θv). The two encodings are combined using f() to produce the final model prediction. For example, in a movie recommendation model, xu are the user features and xv are the movie features.
Such models are well-suited to the aforementioned distributed system architecture (since they separate the user and non-user features).
Factorized models will be trained using Differentially Private Alternating Minimization (DPAM), which alternates between optimizing the parameters θu (while θv is fixed) and vice-versa. DPAM algorithms have been shown to achieve better utility in a variety of settings 4 11, in particular in the presence of public features.
References
- 1: Dwork et al. Calibrating Noise to Sensitivity in Private Data Analysis, TCC'06
- 2: US Census Bureau. Understanding Differential Privacy, 2020
- 3: Federated Learning with Formal Differential Privacy Guarantees, Google AI Blog Post, 2020
- 4: Jain et al. Differentially Private Model Personalization, NeurIPS'21
- 5: Krichene et al. Private Learning with Public Features, 2023
- 6: Song et al. Stochastic gradient descent with differentially private updates, GlobalSIP'13
- 7: Differentially Private Empirical Risk Minimization: Efficient Algorithms and Tight Error Bounds, FOCS'14
- 8: Abadi et al. Deep Learning with Differential Privacy, CCS '16
- 9: Smith et al. (Nearly) Optimal Algorithms for Private Online Learning in Full-information and Bandit Settings, NeurIPS'13
- 10: Kairouz et al., Practical and Private (Deep) Learning without Sampling or Shuffling, ICML'21
- 11: Chien et al. Private Alternating Least Squares, ICML'21