
En este documento, se resume el enfoque de privacidad de la Personalización en el dispositivo (ODP), específicamente en el contexto de la privacidad diferencial. Otras implicaciones de privacidad y decisiones de diseño, como la minimización de datos, se omiten intencionalmente para mantener el enfoque de este documento.
Privacidad diferencial
La privacidad diferencial 1 es un estándar de protección de la privacidad ampliamente adoptado en el análisis de datos estadísticos y el aprendizaje automático 2 3. De manera informal, indica que un adversario aprende casi lo mismo sobre un usuario a partir del resultado de un algoritmo con privacidad diferencial, independientemente de que su registro aparezca o no en el conjunto de datos subyacente. Esto implica protecciones sólidas para las personas: cualquier inferencia que se haga sobre una persona solo puede deberse a las propiedades agregadas del conjunto de datos que se mantendrían con o sin el registro de esa persona.
En el contexto del aprendizaje automático, el resultado del algoritmo debe considerarse como los parámetros del modelo entrenado. La frase casi lo mismo se cuantifica matemáticamente con dos parámetros (ε, δ), donde ε suele elegirse como una constante pequeña y δ≪1/(cantidad de usuarios).
Semántica de privacidad
El diseño de la ODP busca garantizar que cada ejecución de entrenamiento tenga privacidad diferencial a nivel del usuario (ε,δ). A continuación, se describe nuestro enfoque para alcanzar esta semántica.
Modelo de amenaza
Definimos las diferentes partes y establecemos suposiciones sobre cada una de ellas:
- Usuario: Es el usuario propietario del dispositivo y consumidor de los productos o servicios que proporciona el desarrollador. Su información privada está completamente disponible para ellos.
- Entorno de ejecución confiable (TEE): Los datos y los cálculos confiables que se producen dentro de los TEE están protegidos de los atacantes con una variedad de tecnologías. Por lo tanto, el cálculo y los datos no requieren protección adicional. Los TEE existentes pueden permitir que los administradores de proyectos accedan a la información que contienen. Proponemos capacidades personalizadas para rechazar y validar que el acceso no esté disponible para un administrador.
- El atacante: Puede tener información adicional sobre el usuario y tiene acceso completo a cualquier información que salga del TEE (como los parámetros del modelo publicados).
- Desarrollador: Es quien define y entrena el modelo. Se considera no confiable (y tiene el alcance completo de la capacidad de un atacante).
Buscamos diseñar la ODP con la siguiente semántica de privacidad diferencial:
- Límite de confianza: Desde la perspectiva de un usuario, el límite de confianza consta del dispositivo del usuario junto con el TEE. Toda la información que salga de este límite de confianza debe estar protegida por la privacidad diferencial.
- Atacante: Protección completa de privacidad diferencial con respecto al atacante. Cualquier entidad fuera del límite de confianza puede ser un atacante (esto incluye al desarrollador y a otros usuarios, todos potencialmente en colusión). El atacante, con toda la información fuera del límite de confianza (por ejemplo, el modelo publicado), cualquier información complementaria sobre el usuario y recursos infinitos, no puede inferir datos privados adicionales sobre el usuario (más allá de los que ya están en la información complementaria), hasta las probabilidades que proporciona el presupuesto de privacidad. En particular, esto implica una protección completa de la privacidad diferencial con respecto al desarrollador. Toda la información que se divulga al desarrollador (como los parámetros del modelo entrenado o las inferencias agregadas) está protegida por privacidad diferencial.
Parámetros del modelo local
La semántica de privacidad anterior admite el caso en el que algunos de los parámetros del modelo son locales para el dispositivo (por ejemplo, un modelo que contiene una incorporación del usuario específica para cada usuario y que no se comparte entre los usuarios). En el caso de estos modelos, los parámetros locales permanecen dentro del límite de confianza (no se publican) y no requieren protección, mientras que los parámetros del modelo compartido se publican (y están protegidos por la privacidad diferencial). A veces, esto se conoce como el modelo de privacidad de vallas publicitarias 4.
Características públicas
En algunas aplicaciones, ciertas funciones son públicas. Por ejemplo, en un problema de recomendación de películas, las características de una película (el director, el género o el año de lanzamiento) son información pública y no requieren protección, mientras que las características relacionadas con el usuario (como la información demográfica o las películas que miró) son datos privados y requieren protección.
La información pública se formaliza como una matriz de características públicas (en el ejemplo anterior, esta matriz contendría una fila por película y una columna por característica de la película) que está disponible para todas las partes. El algoritmo de entrenamiento con privacidad diferencial puede usar esta matriz sin necesidad de protegerla (consulta, por ejemplo, 5). La plataforma de ODP planea implementar este tipo de algoritmos.
Un enfoque hacia la privacidad durante la predicción o la inferencia
Las inferencias se basan en los parámetros del modelo y en las características de entrada. Los parámetros del modelo se entrenan con semántica de privacidad diferencial. Aquí se analiza el rol de los atributos de entrada.
En algunos casos de uso, cuando el desarrollador ya tiene acceso completo a las funciones que se usan en la inferencia, no hay problemas de privacidad relacionados con la inferencia, y el desarrollador puede ver el resultado de la inferencia.
En otros casos (cuando las funciones que se usan en la inferencia son privadas y el desarrollador no puede acceder a ellas), el resultado de la inferencia puede ocultarse al desarrollador, por ejemplo, haciendo que la inferencia (y cualquier proceso posterior que use el resultado de la inferencia) se ejecute en el dispositivo, en un proceso y área de visualización propiedad del SO, con comunicación restringida fuera de ese proceso.
Procedimiento de entrenamiento
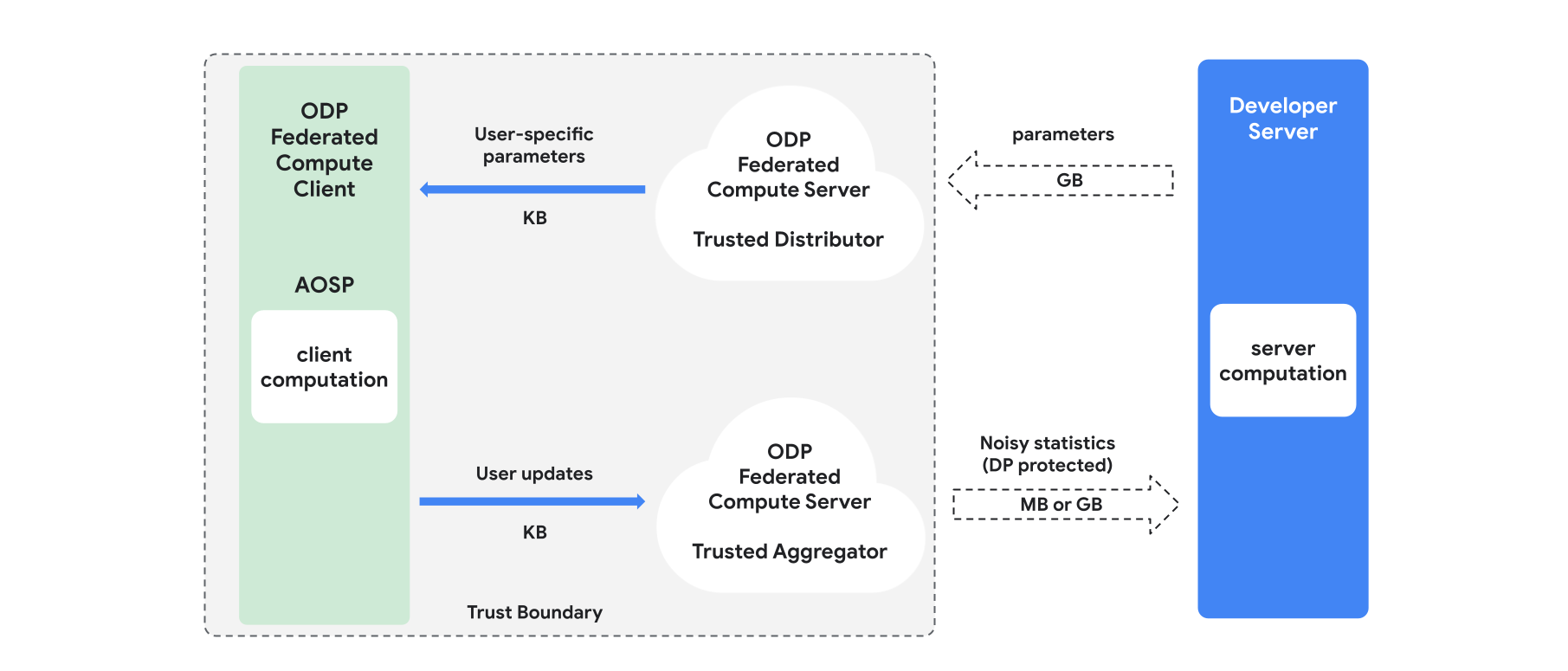
Descripción general
En esta sección, se proporciona una descripción general de la arquitectura y de cómo se lleva a cabo el entrenamiento (consulta la Figura 1). La ODP implementa los siguientes componentes:
Un distribuidor de confianza, como la selección federada, la descarga de confianza o la recuperación de información privada, que desempeña el rol de parámetros de transmisión del modelo. Se supone que el distribuidor de confianza puede enviar un subconjunto de parámetros a cada cliente sin revelar qué parámetros descargó cada cliente. Esta "transmisión parcial" permite que el sistema minimice la huella en el dispositivo del usuario final: en lugar de enviar una copia completa del modelo, solo se envía una fracción de los parámetros del modelo a cada usuario.
Un agregador de confianza que agrega información de varios clientes (p.ej., gradientes o estadísticas), agrega ruido y envía el resultado al servidor. Se supone que existen canales de confianza entre el cliente y el agregador, y entre el cliente y el distribuidor.
Son algoritmos de entrenamiento de DP que se ejecutan en esta infraestructura. Cada algoritmo de entrenamiento consta de diferentes cálculos que se ejecutan en los diferentes componentes (servidor, cliente, agregador, distribuidor).
Una ronda de entrenamiento típica consta de los siguientes pasos:
- El servidor transmite los parámetros del modelo al distribuidor de confianza.
- Cálculo del cliente
- Cada dispositivo cliente recibe el modelo de transmisión (o el subconjunto de parámetros relevantes para el usuario).
- Cada cliente realiza algún cálculo (por ejemplo, calcula gradientes o alguna otra estadística suficiente).
- Cada cliente envía el resultado del cálculo al agregador de confianza.
- El agregador de confianza recopila, agrega y protege las estadísticas de los clientes con los mecanismos de privacidad diferencial adecuados y, luego, envía el resultado al servidor.
- Cálculo del servidor
- El servidor (no confiable) ejecuta cálculos sobre las estadísticas protegidas con privacidad diferencial (por ejemplo, usa gradientes agregados con privacidad diferencial para actualizar los parámetros del modelo).
Modelos factorizados y minimización alternada con privacidad diferencial
La plataforma de ODP planea proporcionar algoritmos de entrenamiento con privacidad diferencial de propósito general que se puedan aplicar a cualquier arquitectura de modelo (como DP-SGD 6 7 8 o DP-FTRL 9 10, así como algoritmos especializados para modelos factorizados).
Los modelos factorizados son modelos que se pueden descomponer en submodelos (llamados codificadores o torres). Por ejemplo, considera un modelo de la forma f(u(θu, xu), v(θv, xv)), en el que u() codifica las características del usuario xu (y tiene parámetros θu), y v() codifica las características que no son del usuario xv (y tiene parámetros θv). Las dos codificaciones se combinan con f() para producir la predicción final del modelo. Por ejemplo, en un modelo de recomendación de películas, xu son los atributos del usuario y xv son los atributos de la película.
Estos modelos son adecuados para la arquitectura de sistemas distribuidos mencionada anteriormente (ya que separan las características del usuario y las que no son del usuario).
Los modelos factorizados se entrenarán con la minimización alternada con privacidad diferencial (DPAM), que alterna la optimización de los parámetros θu (mientras que θv permanece fijo) y viceversa. Se demostró que los algoritmos de DPAM logran una mejor utilidad en una variedad de parámetros de configuración 4 11, en particular, en presencia de funciones públicas.
Referencias
- 1: Dwork et al. Calibrating Noise to Sensitivity in Private Data Analysis, TCC'06
- 2: Oficina del Censo de EE.UU. Understanding Differential Privacy, 2020
- 3: Federated Learning with Formal Differential Privacy Guarantees, Google AI Blog Post, 2020 (Aprendizaje federado con garantías formales de privacidad diferencial, entrada de blog de Google AI, 2020)
- 4: Jain et al. Differentially Private Model Personalization, NeurIPS'21
- 5: Krichene et al., Private Learning with Public Features, 2023
- 6: Song et al. Stochastic gradient descent with differentially private updates, GlobalSIP'13
- 7: Differentially Private Empirical Risk Minimization: Efficient Algorithms and Tight Error Bounds, FOCS'14
- 8: Abadi et al. Deep Learning with Differential Privacy, CCS '16
- 9: Smith et al. (Nearly) Optimal Algorithms for Private Online Learning in Full-information and Bandit Settings, NeurIPS'13
- 10: Kairouz et al., Practical and Private (Deep) Learning without Sampling or Shuffling, ICML'21
- 11: Chien et al., Private Alternating Least Squares, ICML'21