
En esta página, se describe cómo trabajar con las APIs de Federated Learning que proporciona On-Device Personalization para entrenar un modelo con un proceso de aprendizaje de promediado federado y ruido gaussiano fijo.
Antes de comenzar
Antes de comenzar, completa los siguientes pasos en tu dispositivo de prueba:
Asegúrate de que el módulo OnDevicePersonalization esté instalado. El módulo estuvo disponible como actualización automática en abril de 2024.
# List the modules installed on the device adb shell pm list packages --apex-only --show-versioncodeAsegúrate de que el siguiente módulo aparezca con un código de versión 341717000 o posterior:
package:com.google.android.ondevicepersonalization versionCode:341717000Si ese módulo no aparece en la lista, ve a Configuración > Seguridad y privacidad > Actualizaciones > Actualización del sistema de Google Play para asegurarte de que tu dispositivo esté actualizado. Selecciona Actualizar si es necesario.
Habilita todas las funciones nuevas relacionadas con el aprendizaje federado.
# Enable On-Device Personalization apk. adb shell device_config put on_device_personalization global_kill_switch false # Enable On-Device Personalization APIs. adb shell device_config put on_device_personalization enable_ondevicepersonalization_apis true # Enable On-Device Personalization overriding. adb shell device_config put on_device_personalization enable_personalization_status_override true adb shell device_config put on_device_personalization personalization_status_override_value true # Enable Federated Compute apk. adb shell device_config put on_device_personalization federated_compute_kill_switch false
Crea una tarea de aprendizaje federado

Los números del diagrama se explican con más detalle en los siguientes ocho pasos.
Configura un servidor de procesamiento federado
El aprendizaje federado es un proceso de MapReduce que se ejecuta en el servidor de procesamiento federado (el reductor) y en un conjunto de clientes (los asignadores). El servidor de Federated Compute mantiene los metadatos en ejecución y la información del modelo de cada tarea de aprendizaje federado. En un nivel alto, haz lo siguiente:
- Un desarrollador de aprendizaje federado crea una tarea nueva y sube al servidor los metadatos de ejecución de la tarea y la información del modelo.
- Cuando un cliente de Federated Compute inicia una nueva solicitud de asignación de tareas al servidor, este verifica la elegibilidad de la tarea y devuelve la información de las tareas aptas.
- Una vez que un cliente de Federated Compute finaliza los cálculos locales, envía los resultados al servidor. Luego, el servidor realiza la agregación y la adición de ruido en estos resultados de cálculo, y aplica el resultado al modelo final.
Para obtener más información sobre estos conceptos, consulta los siguientes recursos:
- Federated Learning: Collaborative Machine Learning without Centralized Training Data (Aprendizaje federado: Aprendizaje automático colaborativo sin datos de entrenamiento centralizados)
- Towards Federated Learning at Scale: System Design (SysML 2019)
La ODP usa una versión mejorada del aprendizaje federado, en la que se aplica ruido calibrado (centralizado) a los agregados antes de aplicarlos al modelo. La escala del ruido garantiza que los agregados conserven la privacidad diferencial.
Paso 1: Crea un servidor de procesamiento federado
Sigue las instrucciones del proyecto de Federated Compute para configurar tu propio servidor de Federated Compute.
Paso 2: Prepara un modelo funcional guardado
Prepara un archivo "FunctionalModel" guardado. Puedes usar 'functional_model_from_keras' para convertir un 'Model' en 'FunctionalModel' y usar 'save_functional_model' para serializar este 'FunctionalModel' como un 'SavedModel'.
functional_model = tff.learning.models.functional_model_from_keras(keras_model=model)
tff.learning.models.save_functional_model(functional_model, saved_model_path)
Paso 3: Crea una configuración del servidor de procesamiento federado
Prepara un objeto fcp_server_config.json que incluya políticas, configuración del aprendizaje federado y configuración de la privacidad diferencial. Ejemplo:
# Identifies the set of client devices that will participate.
population_name: "my_new_population"
# Options you can choose:
# * TRAINING_ONLY: Only one training task will be generated under this
# population.
# * TRAINING_AND_EVAL: One training task and one evaluation task will be
# generated under this population.
# * EVAL_ONLY: Only one evaluation task will be generated under this
# population.
mode: TRAINING_AND_EVAL
policies {
# Policy for sampling on-device examples. It is checked every time a
# device attempts to start a new training.
min_separation_policy {
# The minimum number of rounds before the same client participated.
minimum_separation: 3
}
# Policy for releasing training results to developers. It is checked
# when uploading a new task to the Federated Compute Server.
model_release_policy {
# Server stops training when number of training rounds reaches this
# number.
num_max_training_rounds: 1000
}
}
# Federated learning setups. They are applied inside Task Builder.
federated_learning {
learning_process {
# Use FED_AVG to build federated learning process. Options you can
# choose:
# * FED_AVG: Federated Averaging algorithm
# (https://arxiv.org/abs/2003.00295)
# * FED_SDG: Federated SGD algorithm
# (https://arxiv.org/abs/1602.05629)
type: FED_AVG
# Optimizer used at client side training. Options you can choose:
# * ADAM
# * SGD
client_optimizer: SGD
# Learning rate used at client side training.
client_learning_rate: 0.01
# Optimizer used at server side training. Options you can choose:
# * ADAM
# * SGD
server_optimizer: ADAM
# Learning rate used at server side training.
sever_learning_rate: 1
runtime_config {
# Number of participating devices for each round of training.
report_goal: 2000
}
# List of metrics to be evaluated by the model during training and
# evaluation. Federated Compute Server provides a list of allowed
# metrics.
metrics {
name: "auc-roc"
}
metrics {
name: "binary_accuracy"
}
}
# Whether or not to generate a corresponding evaluation task under the same
# population. If this field isn't set, only one training task is
# generated under this population.
evaluation {
# The task id under the same population of the source training task that
# this evaluation task evaluates.
source_training_task_id: 1
# Decides how checkpoints from the training task are chosen for
# evaluation.
# * every_k_round: the evaluation task randomly picks one checkpoint
# from the past k rounds of training task checkpoints.
# * every_k_hour: the evaluation task randomly picks one checkpoint
# from the past k hours of training task checkpoints.
checkpoint_selector: "every_1_round"
# The traffic of this evaluation task in this population.
evaluation_traffic: 0.1
# Number of participating devices for each round of evaluation.
report_goal: 200
}
}
# Differential Privacy setups. They are applied inside the Task Builder.
differential_privacy {
# The DP aggregation algorithm you want to use. Options you can choose:
# * FIXED_GAUSSIAN: Federated Learning DP-SGD with fixed clipping norm
# described in "Learning Differentially Private Recurrent
# Language Models" (https://arxiv.org/abs/1710.06963).
# * ADAPTIVE_GAUSSIAN: Federated Learning DP-SGD with quantile-based clip
# norm estimation described in "Differentially Private
# Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
# * TREE: DP-FTRL algorithm described in "Practical and Private (Deep)
# Learning without Sampling or Shuffling"
# (https://arxiv.org/abs/2103.00039).
# * ADADPTIVE_TREE: DP-FTRL with adaptive clipping norm descirbed in
# "Differentially Private Learning with Adaptive Clipping"
# (https://arxiv.org/abs/1905.03871).
type: FIXED_GAUSSIAN
# Noise multiplier for the Gaussian noise.
noise_multiplier: 0.1
# The value of the clipping norm.
clip_norm: 0.1
}
Paso 4: Envía la configuración zip al servidor de Federated Compute.
Envía el archivo ZIP y fcp_server_config.json al servidor de Federated Compute.
task_builder_client --task_builder_server='http://{federated_compute_server_endpoint}' --saved_model='saved_model' --task_config='fcp_server_config.json'
El extremo del servidor de procesamiento federado es el servidor que configuraste en el paso 1.
La biblioteca de operadores integrados de LiteRT solo admite una cantidad limitada de operadores de TensorFlow (selecciona operadores de TensorFlow). El conjunto de operadores admitidos puede variar entre las diferentes versiones del módulo OnDevicePersonalization. Para garantizar la compatibilidad, se lleva a cabo un proceso de verificación del operador en el compilador de tareas durante la creación de la tarea.
La versión mínima compatible del módulo OnDevicePersonalization se incluirá en los metadatos de la tarea. Puedes encontrar esta información en el mensaje informativo del compilador de tareas.
I1023 22:16:53.058027 139653371516736 task_builder_client.py:109] Success! Tasks are built, and artifacts are uploaded to the cloud. I1023 22:16:53.058399 139653371516736 task_builder_client.py:112] applied_algorithms { learning_algo: FED_AVG client_optimizer: SGD server_optimizer: SGD dp_aggregator: FIXED_GAUSSIAN } metric_results { accepted_metrics: "binary_accuracy, binary_crossentropy, recall, precision, auc-roc, auc-pr" } dp_hyperparameters { dp_delta: 0.000001 dp_epsilon: 6.4 noise_multiplier: 1.0 dp_clip_norm: 1.0 num_training_rounds: 10000 } I1023 22:16:53.058594 139653371516736 task_builder_client.py:113] training_task { min_client_version: "341912000" } eval_task { min_client_version: "341812000" }El servidor de Federated Compute asignará esta tarea a todos los dispositivos equipados con un módulo de OnDevicePersonalization con una versión superior a 341812000.
Si tu modelo incluye operaciones que no son compatibles con ningún módulo de OnDevicePersonalization, se generará un mensaje de error durante la creación de la tarea.
common.TaskBuilderException: Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {'L2Loss': 'L2LossOp<CPUDevice, float>'} . Stop building remaining artifacts.Puedes encontrar una lista detallada de las operaciones flexibles admitidas en GitHub.
Crea un APK de Federated Compute para Android
Para crear un APK de Federated Compute de Android, debes especificar el extremo de URL del servidor de Federated Compute en tu AndroidManifest.xml, al que se conecta tu cliente de Federated Compute.
Paso 5: Especifica el extremo de URL del servidor de Federated Compute
Especifica la URL del extremo del servidor de Federated Compute (que configuraste en el paso 1) en tu AndroidManifest.xml, al que se conecta tu cliente de Federated Compute.
<!-- Contents of AndroidManifest.xml -->
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.example.odpsample" >
<application android:label="OdpSample">
<!-- XML resource that contains other ODP settings. -->
<property android:name="android.ondevicepersonalization.ON_DEVICE_PERSONALIZATION_CONFIG"
android:resource="@xml/OdpSettings"></property>
<!-- The service that ODP will bind to. -->
<service android:name="com.example.odpsample.SampleService"
android:exported="true" android:isolatedProcess="true" />
</application>
</manifest>
El archivo de recursos XML especificado en la etiqueta <property> también debe declarar la clase de servicio en una etiqueta <service> y especificar el extremo de URL del servidor de Federated Compute al que se conectará el cliente de Federated Compute:
<!-- Contents of res/xml/OdpSettings.xml -->
<on-device-personalization>
<!-- Name of the service subclass -->
<service name="com.example.odpsample.SampleService">
<!-- If you want to use federated compute feature to train a model,
specify this tag. -->
<federated-compute-settings url="https://fcpserver.com/" />
</service>
</on-device-personalization>
Paso 6: Implementa la API de IsolatedWorker#onTrainingExample
Implementa la API pública de On-Device Personalization IsolatedWorker#onTrainingExample para generar datos de entrenamiento.
El código que se ejecuta en IsolatedProcess no tiene acceso directo a la red, los discos locales ni otros servicios que se ejecutan en el dispositivo. Sin embargo, las siguientes APIs están disponibles:
- "getRemoteData": Son datos inmutables de clave-valor descargados de back-ends remotos operados por el desarrollador, si corresponde.
- "getLocalData": Datos de clave-valor mutables que los desarrolladores conservan de forma local, si corresponde.
- "UserData": Son los datos del usuario que proporciona la plataforma.
- "getLogReader": Devuelve un DAO para las tablas REQUESTS y EVENTS.
Ejemplo:
@Override public void onTrainingExample(
@NonNull TrainingExampleInput input,
@NonNull Consumer<TrainingExampleOutput> consumer) {
// Check if the incoming training task is the task we want.
if (input.getPopulationName() == "my_new_population") {
TrainingExampleOutput result = new TrainingExampleOutput.Builder():
RequestLogRecord record = this.getLogReader().getRequestLogRecord(1);
int count = 1;
// Iterate logging event table.
for (ContentValues contentValues: record.rows()) {
Features features = Features.newBuilder()
// Retrieve carrier from user info.
.putFeature("carrier", buildFeature(mUserData.getCarrier()))
// Retrieve features from logging info.
.putFeature("int_feature_1",
buildFeature(contentValues.get("int_feature_1")
result.addTrainingExample(
Example.newBuilder()
.setFeatures(features).build().toByteArray())
.addResumptionToken(
String.format("token%d", count).getBytes()))
.build();
count++;
}
consumer.accept(result.build());
}
}
Paso 7: Programa una tarea de entrenamiento recurrente.
La personalización integrada en el dispositivo proporciona un FederatedComputeScheduler para que los desarrolladores programen o cancelen trabajos de procesamiento federado. Existen diferentes opciones para llamarlo a través de IsolatedWorker, ya sea según una programación o cuando se completa una descarga asíncrona. A continuación, se muestran ejemplos de ambos casos.
Opción basada en la programación. Llama a
FederatedComputeScheduler#scheduleenIsolatedWorker#onExecute.@Override public void onExecute( @NonNull ExecuteInput input, @NonNull Consumer<ExecuteOutput> consumer ) { if (input != null && input.getAppParams() != null && input.getAppParams().getString("schedule_training") != null) { if (input.getAppParams().getString("schedule_training").isEmpty()) { consumer.accept(null); return; } TrainingInterval interval = new TrainingInterval.Builder() .setMinimumInterval(Duration.ofSeconds(10)) .setSchedulingMode(2) .build(); FederatedComputeScheduler.Params params = new FederatedComputeScheduler .Params(interval); FederatedComputeInput fcInput = new FederatedComputeInput.Builder() .setPopulationName( input.getAppParams().getString("schedule_training")).build(); mFCScheduler.schedule(params, fcInput); ExecuteOutput result = new ExecuteOutput.Builder().build(); consumer.accept(result); } }Opción de descarga completa. Llama a
FederatedComputeScheduler#scheduleenIsolatedWorker#onDownloadCompletedsi la programación de una tarea de entrenamiento depende de algún proceso o dato asíncrono.
Validación
En los siguientes pasos, se describe cómo validar si la tarea de aprendizaje federado se ejecuta correctamente.
Paso 8: Valida si la tarea de aprendizaje federado se ejecuta correctamente.
En cada ronda de agregación del servidor, se generan un nuevo punto de control del modelo y un nuevo archivo de métricas.
Las métricas se encuentran en un archivo con formato JSON de pares clave-valor. El archivo se genera a partir de la lista de Metrics que definiste en el paso 3. A continuación, se muestra un ejemplo de un archivo JSON de métricas representativas:
{"server/client_work/train/binary_accuracy":0.5384615659713745, "server/client_work/train/binary_crossentropy":0.694046676158905, "server/client_work/train/recall":0.20000000298023224, "server/client_work/train/precision":0.3333333432674408, "server/client_work/train/auc-roc":0.3500000238418579, "server/client_work/train/auc-pr":0.44386863708496094, "server/finalizer/update_non_finite":0.0}
Puedes usar algo similar a la siguiente secuencia de comandos para obtener métricas del modelo y supervisar el rendimiento del entrenamiento:
import collections
import json
import matplotlib.pyplot as plt
from google.cloud import storage
# The population_name you set in fcp_server_config.json in Step 3.
POPULATION_NAME = 'my_new_population'
# The Google Cloud storage you set in Step 1.
GCS_BUCKET_NAME = 'fcp-gcs'
NUM_TRAINING_ROUND = 1000
storage_client = storage.Client()
bucket = storage_client.bucket(GCS_BUCKET_NAME)
metrics = collections.defaultdict(list)
for i in range(NUM_TRAINING_ROUND):
blob = bucket.blob('{}/{}/1/{}/s/0/metrics'.format(GCS_BUCKET_NAME, POPULATION_NAME, i+1))
with blob.open("r") as f:
metric = json.loads(f.read())
for metric_name in metric.keys():
metrics[metric_name].append(metric[metric_name])
for metric_name in metrics:
print(metric_name)
plt.plot(metrics[metric_name])
plt.show()
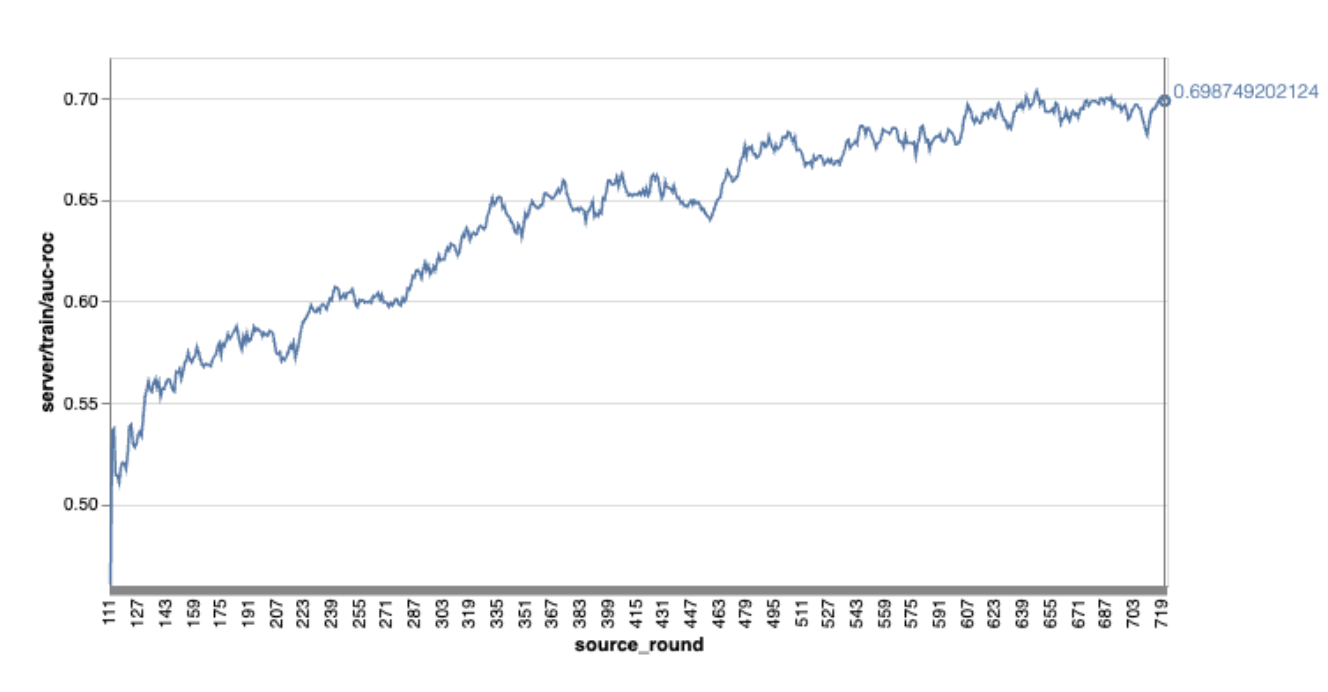
Ten en cuenta que, en el gráfico de ejemplo anterior, sucede lo siguiente:
- El eje X representa la cantidad de rondas de entrenamiento.
- El eje Y representa el valor del AUC-ROC de cada ronda.
Cómo entrenar un modelo de clasificación de imágenes en la personalización integrada en el dispositivo
En este instructivo, se usa el conjunto de datos EMNIST para demostrar cómo ejecutar una tarea de aprendizaje federado en ODP.
Paso 1: Crea un tff.learning.models.FunctionalModel
def get_image_classification_input_spec():
return (
tf.TensorSpec([None, 28, 28, 1], tf.float32),
tf.TensorSpec([None, 1], tf.int64),
)
def create_and_save_image_classification_functional_model(
model_path: str,
) -> None:
keras_model = emnist_models.create_original_fedavg_cnn_model(
only_digits=True
)
functional_model = tff.learning.models.functional_model_from_keras(
keras_model=keras_model,
input_spec=get_image_classification_input_spec(),
loss_fn=tf.keras.losses.SparseCategoricalCrossentropy(),
)
tff.learning.models.save_functional_model(functional_model, model_path)
- Puedes encontrar los detalles del modelo de Keras de EMNIST en emnist_models.
- TfLite aún no admite bien tf.sparse.SparseTensor ni tf.RaggedTensor. Intenta usar tf.Tensor tanto como sea posible cuando compiles el modelo.
- El ODP Task Builder sobrescribirá todas las métricas cuando compile el proceso de aprendizaje, por lo que no es necesario especificar ninguna métrica. Este tema se abordará más en el paso 2. Crea la configuración del compilador de tareas.
Se admiten dos tipos de entradas de modelos:
Tipo 1 Una tupla(tensor_de_atributos, tensor_de_etiquetas).
- Cuando se crea el modelo, el input_spec se ve de la siguiente manera:
def get_input_spec(): return ( tf.TensorSpec([None, 28, 28, 1], tf.float32), tf.TensorSpec([None, 1], tf.int64), )- Combina lo anterior con la siguiente implementación de la API pública de ODP IsolatedWorker#onTrainingExamples para generar datos de entrenamiento en el dispositivo:
return tf.train.Example( features=tf.train.Features( feature={ 'x': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0] * 784) ), 'y': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()Tipo 2. A
Tuple(Dict[feature_name, feature_tensor], label_tensor)- Cuando se crea el modelo, el input_spec se ve de la siguiente manera:
def get_input_spec() -> ( Tuple[collections.OrderedDict[str, tf.TensorSpec], tf.TensorSpec] ): return ( collections.OrderedDict( [('feature-1', tf.TensorSpec([None, 1], tf.float32)), ('feature-2', tf.TensorSpec([None, 1], tf.float32))] ), tf.TensorSpec([None, 1], tf.int64), )- Combina lo anterior con la siguiente implementación de la API pública de ODP IsolatedWorker#onTrainingExamples para generar datos de entrenamiento:
return tf.train.Example( features=tf.train.Features( feature={ 'feature-1': tf.train.Feature( float_list=tf.train.FloatList(value=[1.0]) ), 'feature-2': tf.train.Feature( float_list=tf.train.FloatList(value=[2.0]) ), 'my_label': tf.train.Feature( int64_list=tf.train.Int64List( value=[1] ) ), } ) ).SerializeToString()- No olvides registrar el label_name en la configuración del compilador de tareas.
mode: TRAINING_AND_EVAL # Task execution mode population_name: "my_example_model" label_name: "my_label"
ODP controla la DP automáticamente cuando se crea el proceso de aprendizaje. Por lo tanto, no es necesario agregar ruido cuando se crea el modelo funcional.
El resultado de este modelo funcional guardado debería verse como la muestra en nuestro repositorio de GitHub.
Paso 2: Crea la configuración del compilador de tareas
Puedes encontrar ejemplos de configuración del compilador de tareas en nuestro repositorio de GitHub.
Métricas de entrenamiento y evaluación
Dado que las métricas pueden filtrar datos del usuario, el Task Builder tendrá una lista de métricas que el proceso de aprendizaje puede generar y publicar. Puedes encontrar la lista completa en nuestro repositorio de GitHub.
Esta es una lista de métricas de ejemplo cuando se crea una nueva configuración del compilador de tareas:
federated_learning { learning_process { metrics { name: "binary_accuracy" } metrics { name: "binary_crossentropy" } metrics { name: "recall" } metrics { name: "precision" } metrics { name: "auc-roc" } metrics { name: "auc-pr" } } }
Si las métricas que te interesan no están en la lista, comunícate con nosotros.
Configuración de DP
Hay algunos parámetros de configuración relacionados con el DP que se deben especificar:
policies { min_separation_policy { minimum_separation: 1 } model_release_policy { num_max_training_rounds: 1000 dp_target_epsilon: 10 dp_delta: 0.000001 } } differential_privacy { type: FIXED_GAUSSIAN clip_norm: 0.1 noise_multiplier: 0.1 }- Debe estar presente
dp_target_epsilononoise_mulitipilerpara aprobar la validación: (noise_to_epsilonepislon_to_noise). - Puedes encontrar estos parámetros de configuración predeterminados en nuestro repositorio de GitHub.
- Debe estar presente
Paso 3: Sube el modelo guardado y la configuración del compilador de tareas al almacenamiento en la nube de cualquier desarrollador.
Recuerda actualizar los campos de artifact_building cuando subas la configuración del compilador de tareas.
Paso 4: (Opcional) Prueba la compilación de artefactos sin crear una tarea nueva
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint}
El modelo de muestra se valida a través de la verificación de operaciones flexibles y la verificación de DP. Puedes agregar skip_flex_ops_check y skip_dp_check para omitir la validación (este modelo no se puede implementar en la versión actual del cliente de ODP debido a que faltan algunas operaciones flexibles).
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --task_builder_server=${task_builder_server_endpoint} --skip_flex_ops_check=True --skip_dp_check=True
flex_ops_check: La biblioteca de operadores integrados de TensorFlow Lite solo admite una cantidad limitada de operadores de TensorFlow (compatibilidad de operadores de TensorFlow Lite y TensorFlow). Todas las operaciones de TensorFlow incompatibles deben instalarse con el delegado de Flex (Android.bp). Si un modelo contiene operaciones no admitidas, comunícate con nosotros para registrarlas:
Cannot build the ClientOnlyPlan: Please contact Google to register these ops: {...}La mejor manera de depurar un compilador de tareas es iniciar uno de forma local:
# Starts a server at localhost:5000 bazel run //python/taskbuilder:task_builder # Links to a server at localhost:5000 by removing task_builder_server flag bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config_build_artifact_only.pbtxt --build_artifact_only=true --skip_flex_ops_check=True --skip_dp_check=True
Puedes encontrar los artefactos resultantes en el almacenamiento en la nube especificado en la configuración. Debe ser algo similar al ejemplo de nuestro repositorio de GitHub.
Paso 5: Compila artefactos y crea un nuevo par de tareas de entrenamiento y evaluación en el servidor de FCP.
Quita la marca build_artifact_only y los artefactos compilados se subirán al servidor de FCP. Debes verificar que se haya creado correctamente un par de tareas de entrenamiento y evaluación.
cd ${odp_fcp_github_repo}/python
bazel run //python/taskbuilder:task_builder_client -- --saved_model=${path_of_cloud_storage}/mnist_model/ --task_config=${path_of_cloud_storage}/mnist_cnn_task_config.pbtxt --task_builder_server=${task_builder_server_endpoint}
Paso 6: Prepara el cliente para el FCP
- Implementa la API pública de ODP
IsolatedWorker#onTrainingExamplespara generar datos de entrenamiento. - Llama a
FederatedComputeScheduler#schedule. - Encontrarás algunos ejemplos en nuestro repositorio de código fuente de Android.
Paso 7: Supervisión
Métricas del servidor
Encuentra las instrucciones de configuración en nuestro repositorio de GitHub.
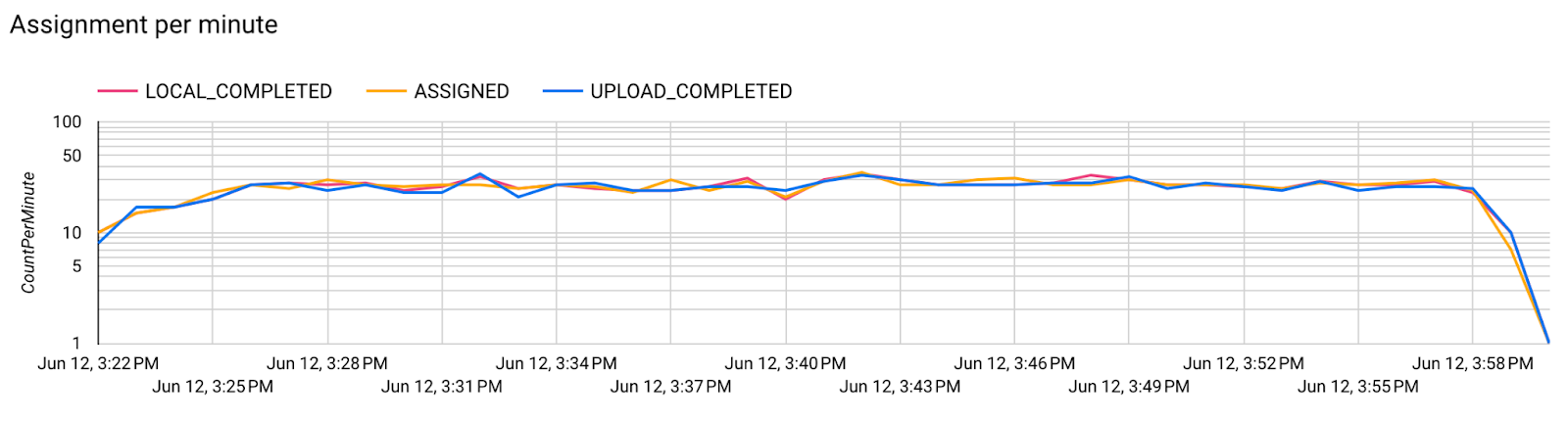
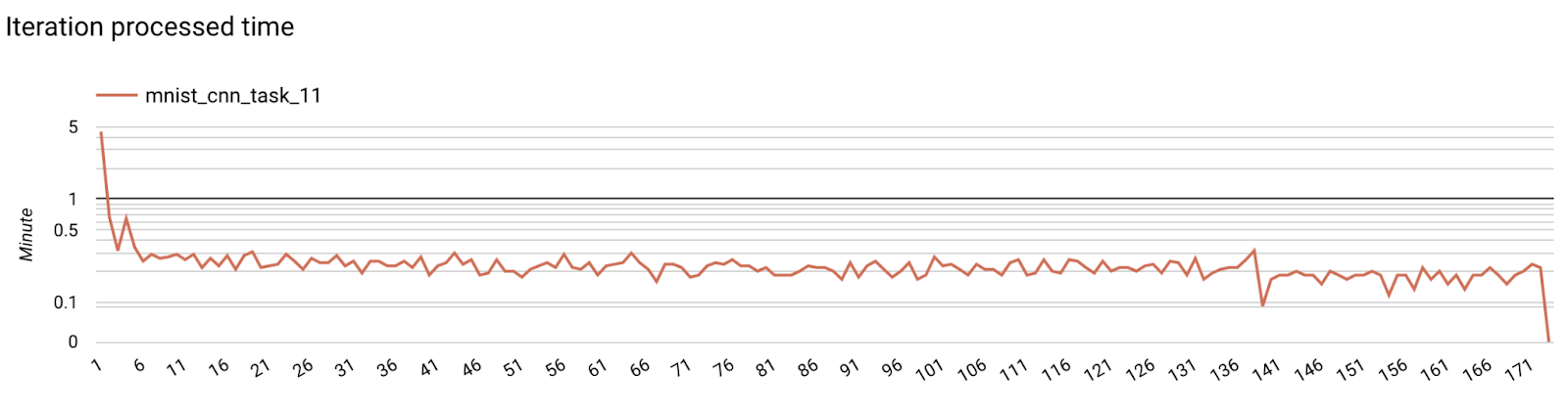
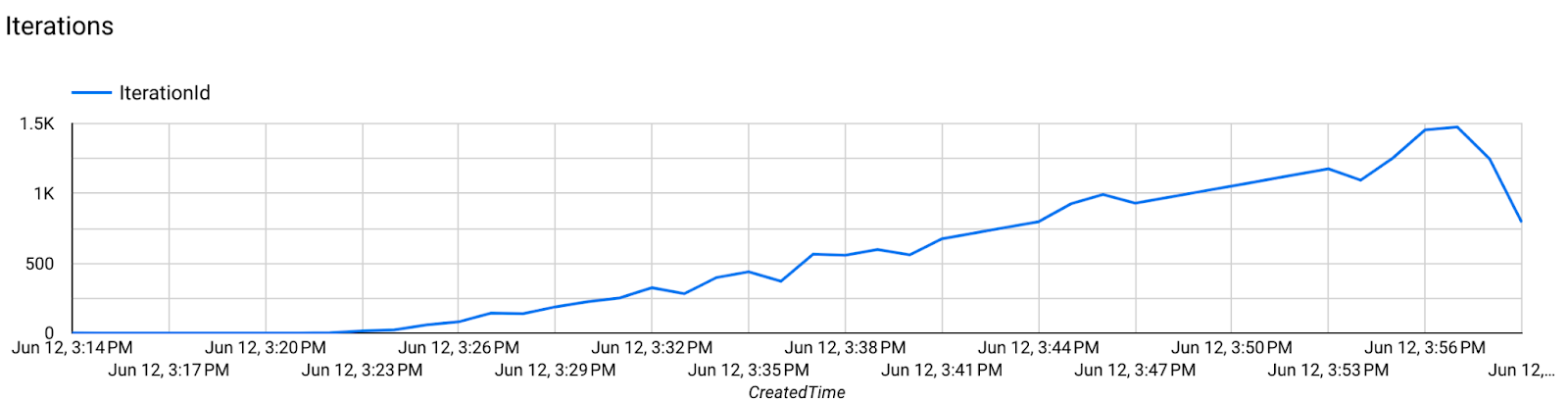
- Métricas del modelo
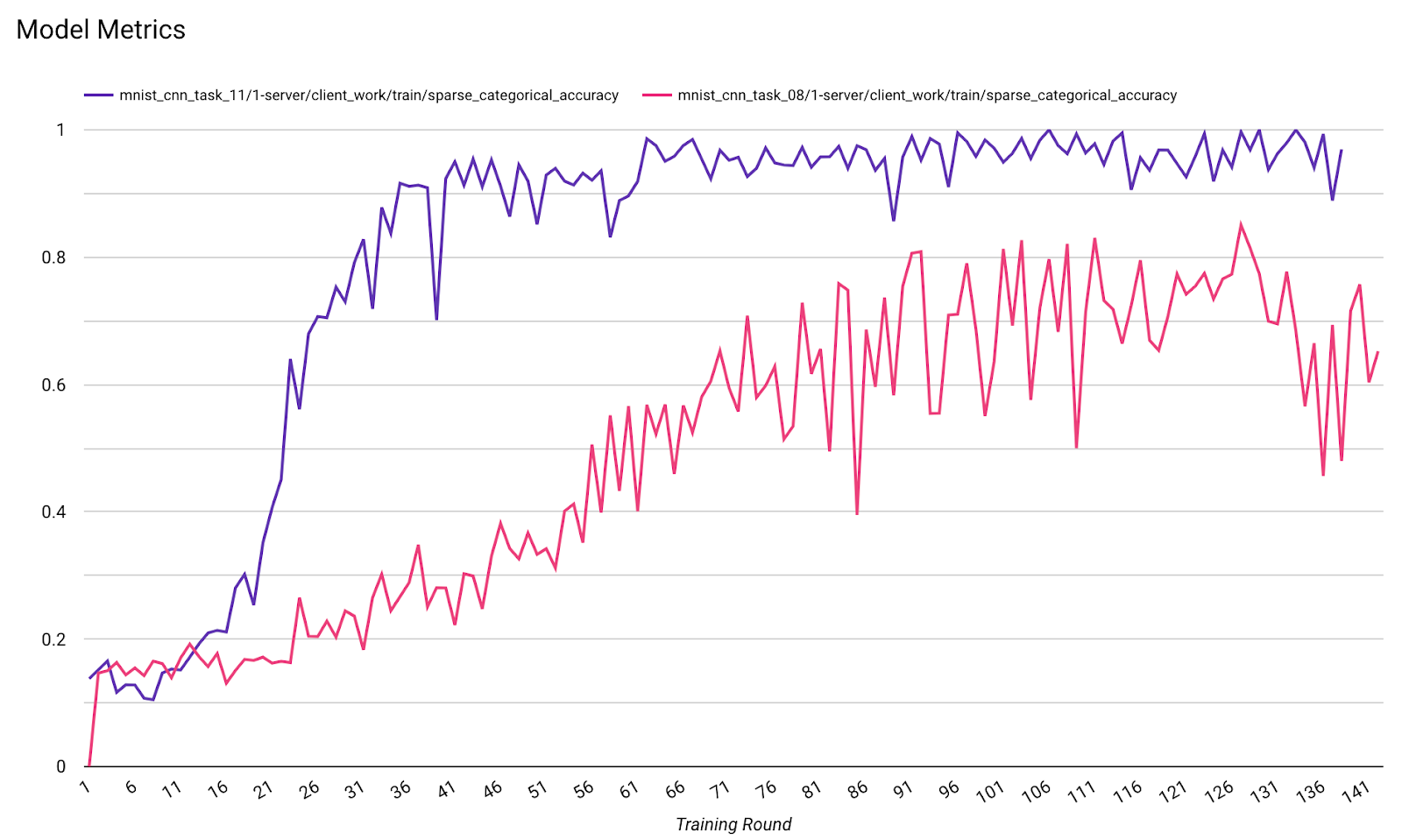
Es posible comparar métricas de diferentes ejecuciones en un solo diagrama. Por ejemplo:
- La línea morada es con
noise_multiplier0.1. - La línea rosa es con
noise_multipiler0.3.